11. 图的入门
11.1 图的实际应用:
在现实生活中,有许多应用场景会包含很多点以及点点之间的连接,而这些应用场景我们都可以用即将要学习的图这种数据结构去解决。
地图:
我们生活中经常使用的地图,基本上是由城市以及连接城市的道路组成,如果我们把城市看做是一个一个的点,把道路看做是一条一条的连接,那么地图就是我们将要学习的图这种数据结构。

电路图:
下面是一个我们生活中经常见到的集成电路板,它其实就是由一个一个触点组成,并把触点与触点之间通过线进行连接,这也是我们即将要学习的图这种数据结构的应用场景。

11.2 图的定义及分类
**定义:**图是由一组顶点和一组能够将两个顶点相连的边组成的

特殊的图:
-
自环:即一条连接一个顶点和其自身的边;
-
平行边:连接同一对顶点的两条边;

图的分类:
按照连接两个顶点的边的不同,可以把图分为以下两种:
无向图:边仅仅连接两个顶点,没有其他含义;
有向图:边不仅连接两个顶点,并且具有方向;
11.3 无向图
11.3.1 图的相关术语
相邻顶点:
当两个顶点通过一条边相连时,我们称这两个顶点是相邻的,并且称这条边依附于这两个顶点。
度:
某个顶点的度就是依附于该顶点的边的个数。
子图:
是一幅图的所有边的子集(包含这些边依附的顶点)组成的图;
路径:
是由边顺序连接的一系列的顶点组成
环:
是一条至少含有一条边且终点和起点相同的路径
连通图:
如果图中任意一个顶点都存在一条路径到达另外一个顶点,那么这幅图就称之为连通图
连通子图:
一个非连通图由若干连通的部分组成,每一个连通的部分都可以称为该图的连通子图

11.3.2 图的存储结构
要表示一幅图,只需要表示清楚以下两部分内容即可:
-
图中所有的顶点;
-
所有连接顶点的边;
常见的图的存储结构有两种:邻接矩阵和邻接表
11.3.2.1 邻接矩阵
-
使用一个V*V的二维数组
int[V][V] adj,把索引的值看做是顶点; -
如果顶点v和顶点w相连,我们只需要将
adj[v][w]和adj[w][v]的值设置为1,否则设置为0即可。

很明显,邻接矩阵这种存储方式的空间复杂度是V^2的,如果我们处理的问题规模比较大的话,内存空间极有可能不够用。
11.3.2.2 邻接表
-
使用一个大小为V的队列数组
Queue[V] adj,把索引看做是顶点; -
每个索引处
adj[v]存储了一个队列,该队列中存储的是所有与该顶点相邻的其他顶点。

很明显,邻接表的空间是线性级别的,所以后面我们一直采用邻接表这种存储形式来表示图。
11.3.3 图的实现(邻接表实现)
11.3.3.1 图的API设计

package com.ynu.Java版算法.U11_图的入门.T1_无向图.S1_图的实现;
import java.util.LinkedList;
import java.util.Queue;
public class Graph {
// 顶点数目
private final int V;
// 边的数目
private int E;
// 邻接表
private Queue<Integer>[] adj;
public Graph(int v) {
// 初始化顶点的数量
this.V = v;
// 初始化边的数量
E = 0;
// 初始化邻接表
adj = new Queue[V];
for (int i = 0; i < adj.length; i++) {
adj[i] = new LinkedList<Integer>();
}
}
//获取顶点数目
public int getV(){
return V;
}
//获取边的数目
public int getE(){
return E;
}
// 向图中添加一条边 v-w 连接v,w顶点
// v顶点的链表上添加w w的顶点上添加v
public void addEdge(int v,int w){
// 把w添加到v的链表中,这样顶点v就多了一个相邻点w
adj[v].offer(w);
//把v添加到w的链表中,这样顶点w就多了一个相邻点v
adj[w].offer(v);
//边的数目自增1
E++;
}
//获取和顶点v相邻的所有顶点
public Queue<Integer> adj(int v){
return adj[v];
}
}
11.3.4 图的搜索
在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某
个顶点与指定顶点是否相通,是非常常见的需求。
有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法。
11.3.4.1 深度优先搜索(DFS)
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找子结点,然后找
兄弟结点。

package com.ynu.Java版算法.U11_图的入门.T1_无向图.S2_图的搜索.A1_深度优先搜索;
import java.util.LinkedList;
import java.util.Queue;
public class DepthFirstSearch {
// 标记数组。 索引代表顶点,值表示当前顶点是否已经被搜索过
private boolean[] marked;
// 记录有多少个顶点与s顶点相通
private int count;
// 记录遍历的结果
private Queue<Integer> list = new LinkedList<>();
public DepthFirstSearch(Graph graph) {
marked = new boolean[graph.V()];
}
// 构造深度优先搜索对象,使用深度优先搜索找出G图中与s顶点相通的所有顶点。从s节点开始遍历整个图。
public DepthFirstSearch(Graph graph,int s) {
marked = new boolean[graph.V()];
// 深度优先遍历
dfs(graph,s);
// 如果遍历完,marked全部为true。说明是graph是一个连通图
}
// 使用深度优先搜索找出G图中与v顶点相通的所有顶点
public void dfs(Graph graph,int v){
list.offer(v);
marked[v] = true; // v访问过,同时也表明s与v是相通的
//获取顶点v的领接表
Queue<Integer> adjV = graph.adj(v);
//遍历顶点v的领接表,往下搜索 一个节点领接表上的所有节点就算是兄弟节点
for (Integer w : adjV) {
if (!marked[w])
dfs(graph,w);
}
// 能连通的节点数加1
count++;
}
// 判断顶点w与顶点s是否相通
public boolean marked(int w){
return marked[w];
}
// 判断是否是连通图
public boolean isLianTong(){
for (boolean b : marked) {
if (b==false){
return false;
}
}
return true;
}
// 获取遍历结果
public void printGraph(){
while (!list.isEmpty()){
System.out.print(list.peek() + " ");
marked[list.poll()] = false;
}
}
}
package com.ynu.Java版算法.U11_图的入门.T1_无向图.S2_图的搜索.A1_深度优先搜索;
public class Main {
public static void main(String[] args) {
// 创建有10个节点的图
Graph g = new Graph(10);
g.addEdge(0,1);
g.addEdge(1,2);
g.addEdge(2,3);
g.addEdge(3,4);
g.addEdge(4,5);
g.addEdge(5,6);
g.addEdge(6,7);
g.addEdge(7,8);
g.addEdge(8,9);
g.addEdge(9,1);
// 输出边的个数 10
System.out.println(g.E());
// 从1节点开始遍历图
DepthFirstSearch depthFirstSearch = new DepthFirstSearch(g);
depthFirstSearch.dfs(g,0);
depthFirstSearch.printGraph();
System.out.println();
// 从0开始深度遍历图
depthFirstSearch.dfs(g,0);
depthFirstSearch.printGraph();
System.out.println();
// 从3开始遍历图
depthFirstSearch.dfs(g,3);
depthFirstSearch.printGraph();
}
}
11.3.4.2 广度优先搜索(BFS)
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找兄弟结点,然后
找子结点。

package com.ynu.Java版算法.U11_图的入门.T1_无向图.S2_图的搜索.A2_广度优先搜索;
import java.util.LinkedList;
import java.util.Queue;
public class BreadthFirthSearch {
// 标记数组 标记是否遍历过该节点
private boolean[] marked;
// 存储结果的队列
private Queue<Integer> res = new LinkedList<>();
// 辅助队列:等待遍历的队列。 类似二叉树的层序遍历,需要一个队列就行帮助。
private Queue<Integer> waitSearch;
//记录有多少个顶点与s顶点相通
private int count;
public BreadthFirthSearch(Graph graph) {
marked = new boolean[graph.V()];
waitSearch = new LinkedList<>();
}
public BreadthFirthSearch(Graph graph, int s) {
waitSearch = new LinkedList<>();
bfs(graph,s);
}
public void bfs(Graph graph,int s){
waitSearch.offer(s);
while (!waitSearch.isEmpty()){
Integer w = waitSearch.poll();
res.offer(w); // 访问该节点
marked[w] = true;
// 获取w的邻接表
Queue<Integer> adjW = graph.adj(w);
for (Integer i : adjW) {
if (!marked[i])
waitSearch.offer(i); // 放进辅助队列
}
}
}
// 判断顶点w与顶点s是否相通
public boolean marked(int w){
return marked[w];
}
// 判断是否是连通图
public boolean isLianTong(){
for (boolean b : marked) {
if (b==false){
return false;
}
}
return true;
}
// 获取遍历结果
public void printGraph(){
while (!res.isEmpty()){
System.out.print(res.peek() + " ");
marked[res.poll()] = false;
}
}
}
11.3.5 案例-畅通工程续1
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。目前的道路状况,9号城市和10号城市是否相通?9号城市和8号城市是否相通?
下面是对数据的解释:

package com.ynu.Java版算法.U11_图的入门.T1_无向图.S2_图的搜索.畅通工程;
import org.junit.Test;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
public class Main {
@Test
public void test(){
List<List<Integer>> paths = new ArrayList<>();
paths.add(Arrays.asList(0,1)); // 连通0,1
paths.add(Arrays.asList(6,9));
paths.add(Arrays.asList(3,8));
paths.add(Arrays.asList(5,11));
paths.add(Arrays.asList(2,12));
paths.add(Arrays.asList(6,10));
paths.add(Arrays.asList(4,8));
// 9号和10号城市是否相通
System.out.println(isConnected(20,paths,9,10));
System.out.println(isConnected1(20,paths,9,10));
// 9号和8号城市是否相通
System.out.println(isConnected(20,paths,9,8));
System.out.println(isConnected1(20,paths,9,8));
// 5号和11号城市是否相通
System.out.println(isConnected(20,paths,5,11));
System.out.println(isConnected1(20,paths,5,11));
}
// 1.使用深度优先遍历
public boolean isConnected(int nums,List<List<Integer>> paths,int i,int j){
// 构建大小为20的图 表示20个城市 0-19号城市
Graph graph = new Graph(20);
boolean[] marked = new boolean[20];
// 加边
for (List<Integer> path : paths) {
Integer v = path.get(0);
Integer w = path.get(1);
graph.addEdge(v,w);
}
// 深度优先遍历
// i号城市对应的索引为i-1
// j城市对应的索引为j-1
dfs(graph,i,marked);
return marked[j];
}
// 从v节点开始深度优先搜索
public void dfs(Graph graph,int v,boolean[] marked){
marked[v] = true;
// 获取v节点的邻接表
Queue<Integer> adjV = graph.adj(v);
for (Integer i : adjV) {
if (!marked[i]){
dfs(graph,i,marked);
}
}
}
// 2.使用广度优先遍历
public boolean isConnected1(int nums,List<List<Integer>> paths,int i,int j){
// 构建大小为20的图 表示20个城市 0-19号城市
Graph graph = new Graph(20);
boolean[] marked = new boolean[20];
// 加边
for (List<Integer> path : paths) {
Integer v = path.get(0);
Integer w = path.get(1);
graph.addEdge(v,w);
}
bfs(graph,i,marked);
return marked[j];
}
// 从v节点开始深度优先搜索
public void bfs(Graph graph,int v,boolean[] marked){
// 辅助队列
Queue<Integer> queue = new LinkedList<>();
queue.offer(v);
while (!queue.isEmpty()){
Integer top = queue.poll();
marked[top] = true;
// 获取邻接表
Queue<Integer> adj = graph.adj(top);
for (Integer i : adj) {
if (!marked[i]){
queue.offer(i);
}
}
}
}
}
11.3.6 路径查找
在实际生活中,地图是我们经常使用的一种工具,通常我们会用它进行导航,输入一个出发城市,输入一个目的地城市,就可以把路线规划好,而在规划好的这个路线上,会路过很多中间的城市。这类问题翻译成专业问题就是:
从s顶点到v顶点是否存在一条路径?如果存在,请找出这条路径。

例如在上图上查找顶点0到顶点4的路径用红色标识出来,那么我们可以把该路径表示为 0-2-3-4。
我们实现路径查找,最基本的操作还是得遍历并搜索图,所以,我们的实现暂且基于深度优先搜索来完成。其搜索的过程是比较简单的。我们添加了edgeTo[]整型数组,这个整型数组会记录从每个顶点回到起点s的路径。 如果我们把顶点设定为0,那么它的搜索可以表示为下图:
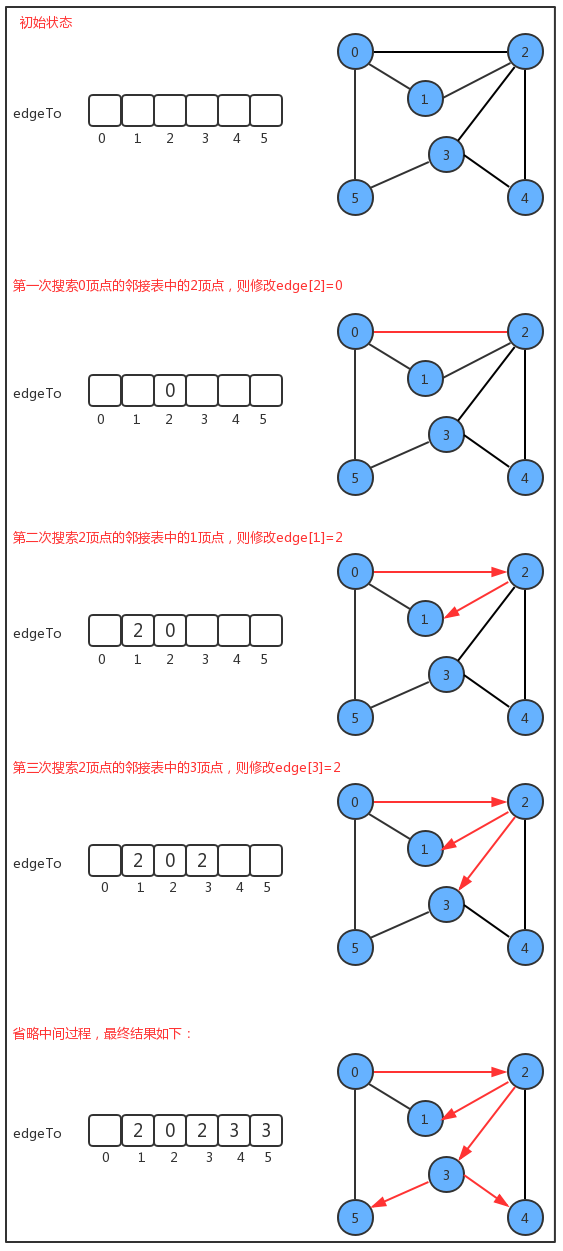
根据最终edgeTo的结果,我们很容易能够找到从起点0到任意顶点的路径; 只不过这个路径是反着的,需要再倒序遍历一下,可以借助栈。
代码:
package com.ynu.Java版算法.U11_图的入门.T1_无向图.S2_图的搜索.A4_路径查找;
import org.junit.Test;
import java.util.*;
public class Main {
@Test
public void test(){
List<List<Integer>> paths = new ArrayList<>();
paths.add(Arrays.asList(0,2)); // 连通0,1
paths.add(Arrays.asList(0,1));
paths.add(Arrays.asList(2,1));
paths.add(Arrays.asList(2,3));
paths.add(Arrays.asList(2,4));
paths.add(Arrays.asList(3,5));
paths.add(Arrays.asList(3,4));
paths.add(Arrays.asList(0,5));
// 从0-5的所有路径
System.out.println(findPath(6, paths, 0, 5));
// 从0-5的最短路径
System.out.println(findPath1(6, paths, 0, 5));
// 从1-5的所有路径
System.out.println(findPath(6, paths, 1, 5));
// 从1-5的最短路径
System.out.println(findPath1(6, paths, 1, 5));
}
// 1.使用深度优先遍历 -- 能查出所有路径
public List<List<Integer>> findPath(int nums,List<List<Integer>> paths,int i,int j){
List<List<Integer>> res = new ArrayList<>(); // 所有路径结果
LinkedList<Integer> tempPath = new LinkedList<>(); // 某一条路径
// 1. 构建大小为20的图 表示20个城市 0-19号城市
Graph graph = new Graph(20);
boolean[] marked = new boolean[20];
// 加边
for (List<Integer> path : paths) {
Integer v = path.get(0);
Integer w = path.get(1);
graph.addEdge(v,w);
}
// 2.深度优先遍历
marked[i] = true;
tempPath.add(i);
dfs(res,tempPath,graph,i,j,marked);
return res;
}
/**
*
* @param res
* @param path
* @param graph
* @param start 起点
* @param des 终点
* @param marked
*/
public void dfs(List<List<Integer>> res,LinkedList<Integer> path,Graph graph, int start, int des,boolean[] marked){
// 到达目的地
if (!path.isEmpty() && path.getLast()==des){
res.add(new LinkedList<>(path));
return;
}
//获取v的邻接表
Queue<Integer> adjV = graph.adj(start);
for (Integer j : adjV) {
if (!marked[j]){
path.add(j);
marked[j] = true;
dfs(res, path, graph, j, des, marked);
// 回溯
path.removeLast();
marked[j] = false;
}
}
}
// 2.使用广优先遍历 一定是最短路径
public List<Integer> findPath1(int nums,List<List<Integer>> paths,int start,int des){
List<Integer> res = new ArrayList<>();
// 大小为nums的标记数组 记录是否遍历过
boolean[] marked = new boolean[nums];
// 构建图
Graph graph = new Graph(nums);
for (List<Integer> path : paths) {
Integer v = path.get(0);
Integer w = path.get(1);
graph.addEdge(v,w);
}
int[] edgeTo = new int[nums]; // edgeTo[]整型数组,这个整型数组会记录从每个顶点回到起点i的路径。很多地方是写为prev数组
// 比如edge[j] = i 表示要到j,前一个节点是i
Arrays.fill(edgeTo,-1);
bfs(graph,edgeTo,start,des,marked); // 广度优先遍历
// 去寻找到des要经过的路径
int j = des;
res.add(j);
while (edgeTo[j]!=-1 && edgeTo[j]!=des){
res.add(edgeTo[j]);
j = edgeTo[j];
}
//由于寻找是按照反着的顺序来的,所以需要把res倒序过来
Collections.reverse(res);
return res;
}
public void bfs(Graph graph,int[] edgeTo,int start,int end,boolean[] marked){
// 辅助队列
Queue<Integer> queue = new LinkedList<>();
queue.offer(start);
while (!queue.isEmpty()){
Integer top = queue.poll();
marked[top] = true;
if (top==end){
return;
}
// 获取邻接表
Queue<Integer> adjV = graph.adj(top);
for (int j : adjV) {
if (!marked[j]){
edgeTo[j] = top;
queue.offer(j);
}
}
}
}
}
11.3.7 路径查找——最短路径
在11.3.6遍历的时候使用广度优先遍历