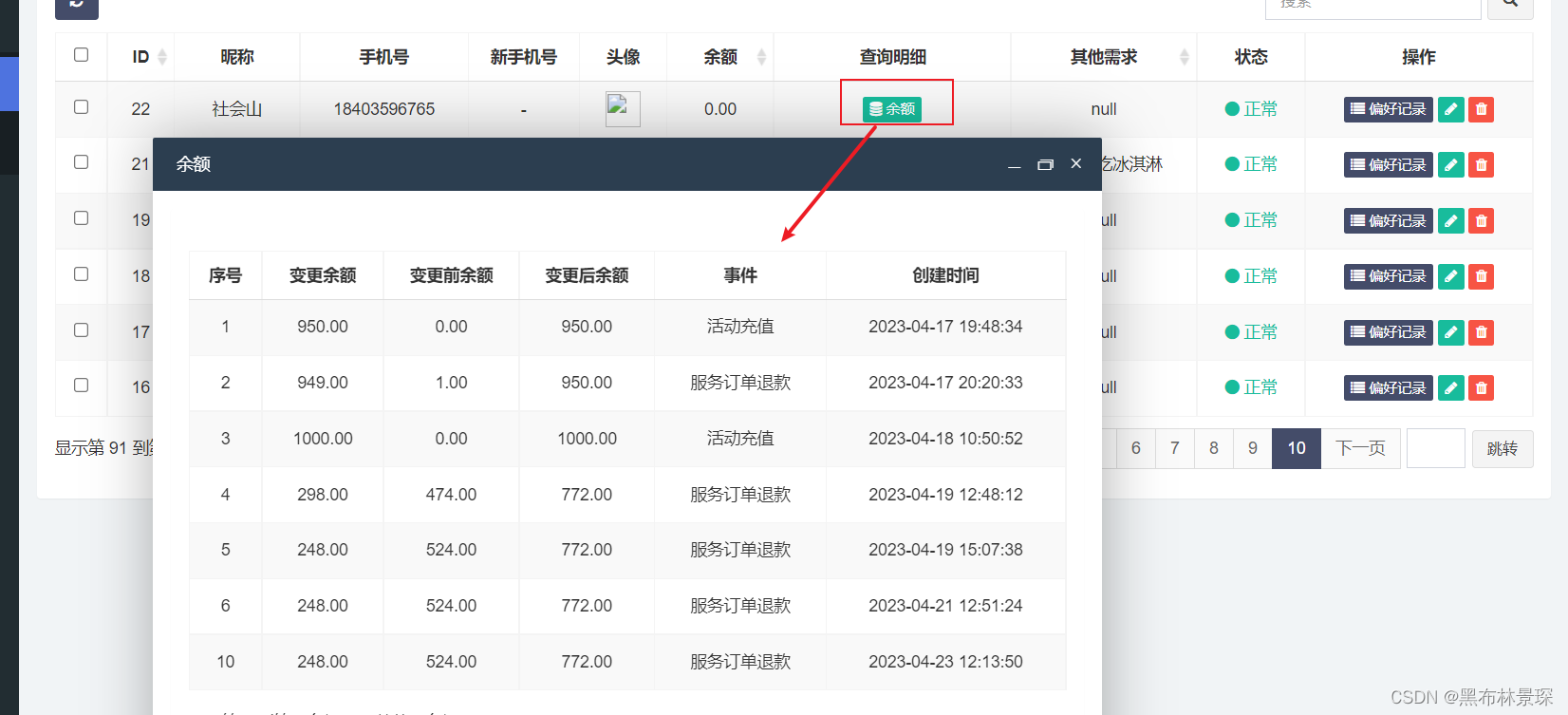
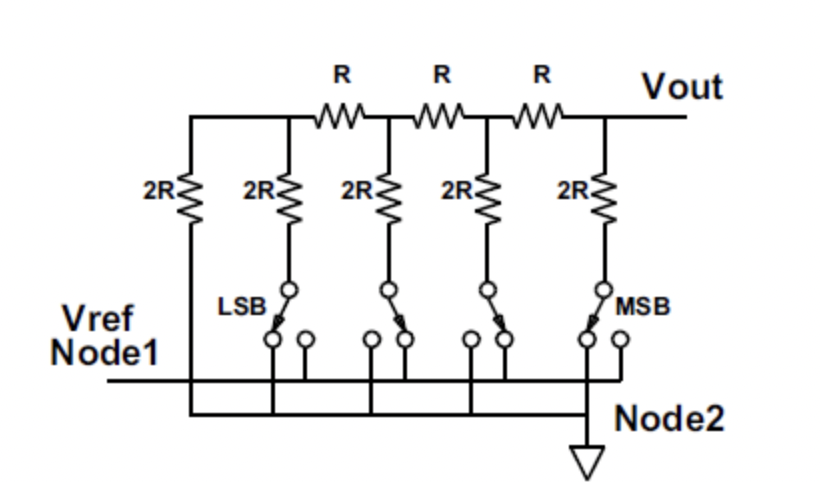
课件网址:
【機器學習2021】自注意力機制 (Self-attention) (上) - YouTube
【機器學習2021】自注意力機制 (Self-attention) (下) - YouTube
这两章课程主要在讲self-attention是怎么做的,对应的矩阵操作是什么,以及为什么要这样处理。
目录
自注意力机制base
适用的输入
可能的输出
结构
并行化操作
Multi-head Self-attention
位置信息
大量参数
与其他方法对比
图的处理
各式各样的self attention
英文单词
自注意力机制base
自注意力机制适用的输入
长度会改变的向量,或者是一堆向量,例如文本[涉及到word embedding],声音向量,graph中每个node可以看做一个向量,它的连接性可以看做one-hot。
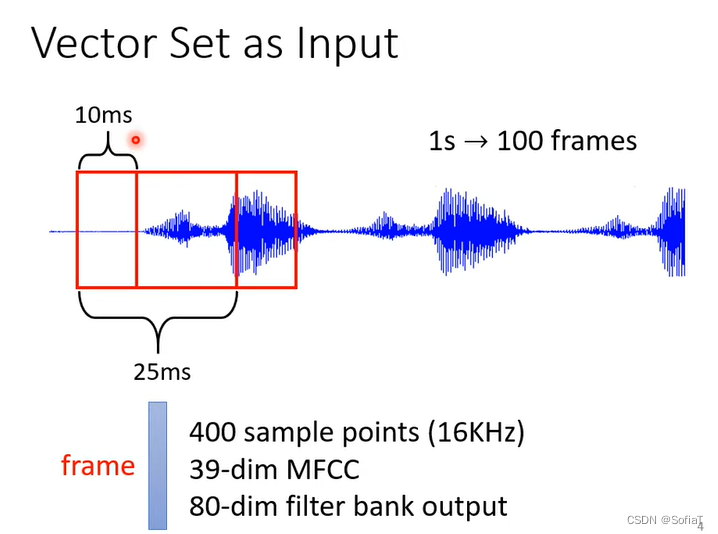 (起始为25ms,然后以10ms移动。)
(起始为25ms,然后以10ms移动。)
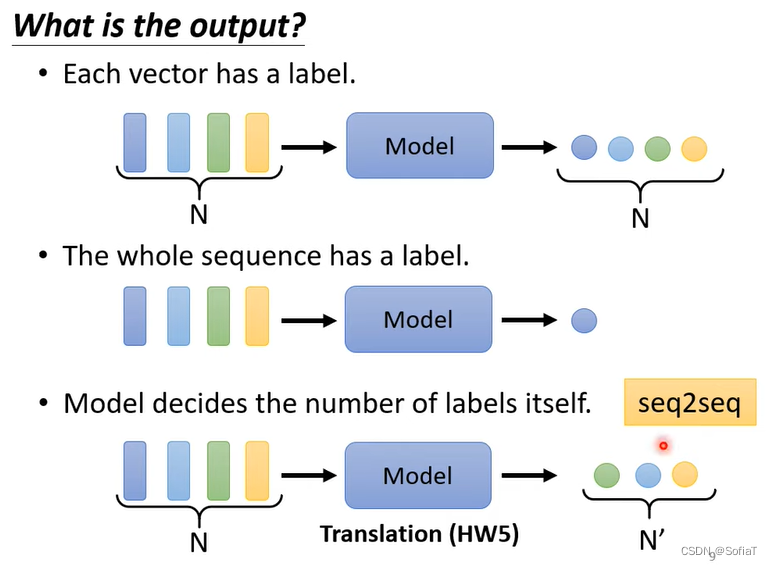
可能的输出
每个词向量都有 一个label。整个句子有一个label。机器自己决定有多少个label。
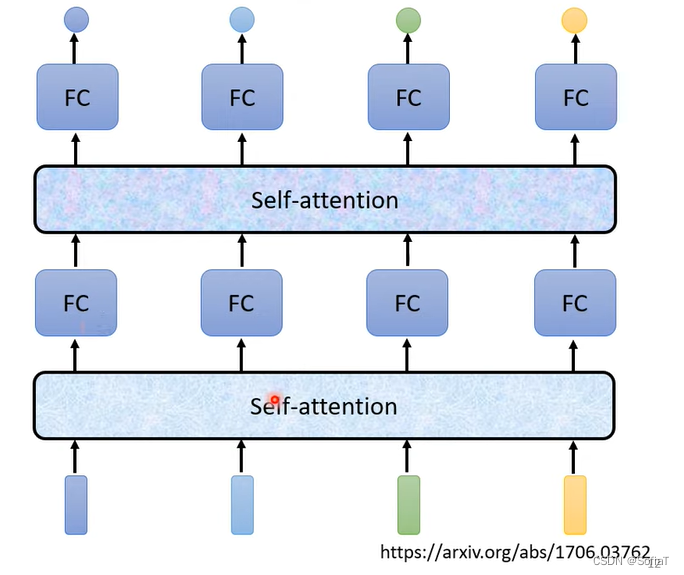
结构
-
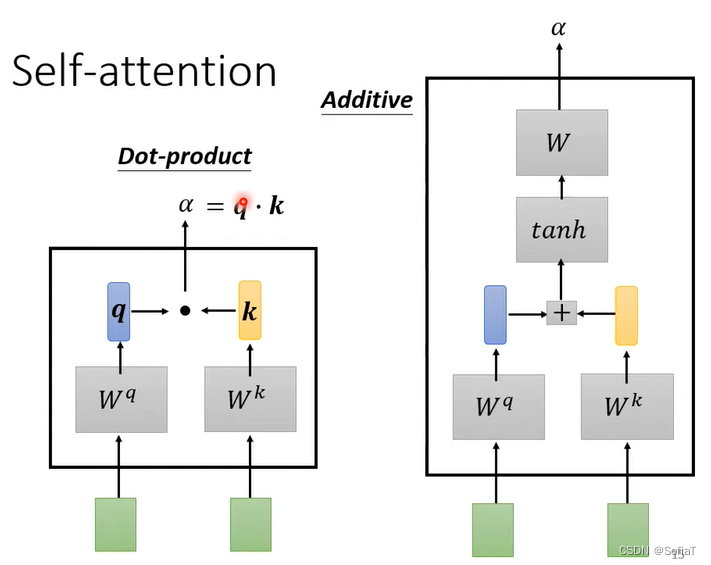
找到a1的关联程度α(一般用q、k、点乘),自己得到q,自己和其他是k。
-
用soft-max处理(这里也可以用relu或者别的处理)
-
得到v向量,乘上attention score,然后加在一起得到b。
-
b的产生不需要按照序列逐个输出,按照他的流程其实是可以并行化的。
keep in mind:
-
q为query,k为key,v为value 。q负责处理相关性。
-
没有向量的位置信息,可以通过加上ei来解决。
并行化操作
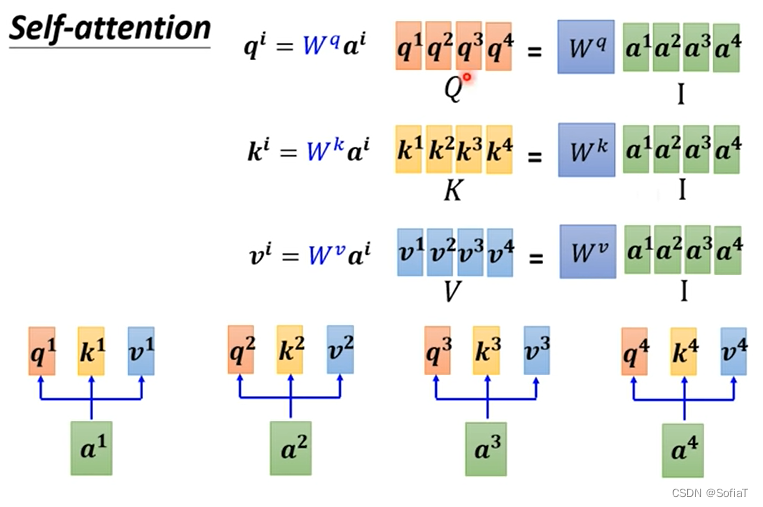
一连串的矩阵乘法,发现Wq、Wk、Wv是所有我们需要训练的参数。
 Multi-head Self-attention
Multi-head Self-attention
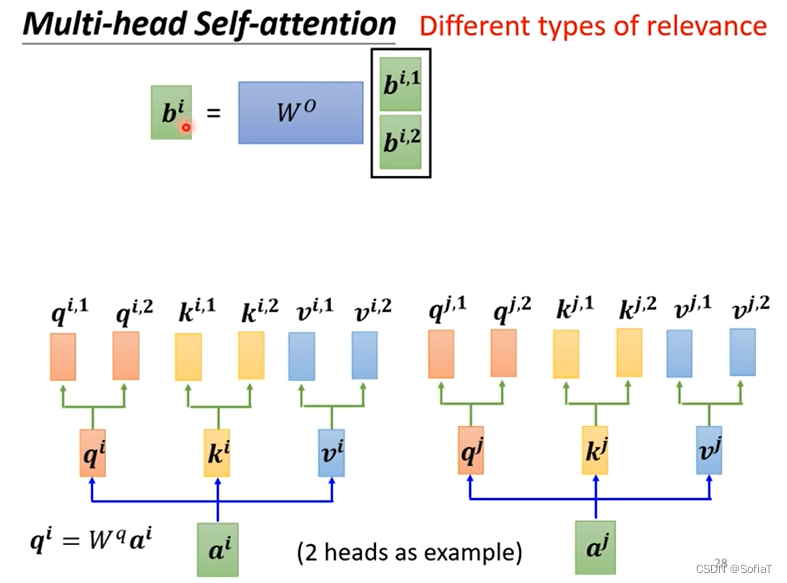 产生不同的参数向量Wq/Wk/Wv,由此得到不同的b,然后通过WO融合成一个新的b。
产生不同的参数向量Wq/Wk/Wv,由此得到不同的b,然后通过WO融合成一个新的b。
為什麼不直接從ai 得到 (qi,1), (qi,2),而是先得到qi再去得到後面兩個向量 (qi,1), (qi,2):①直接做减小了模型的弹性,不直接做相当于是增加了网络的深度,类似于在CNN或FC中增加了一层。②我看pytorch的multi head attention的doc是將qkv的W矩陣先分成n_head份,我推測是將sequence embedding與分成n_head份的qkv dot product後分別得到n_head份的qkv,或許不是得到qi再乘兩個矩陣。
位置信息
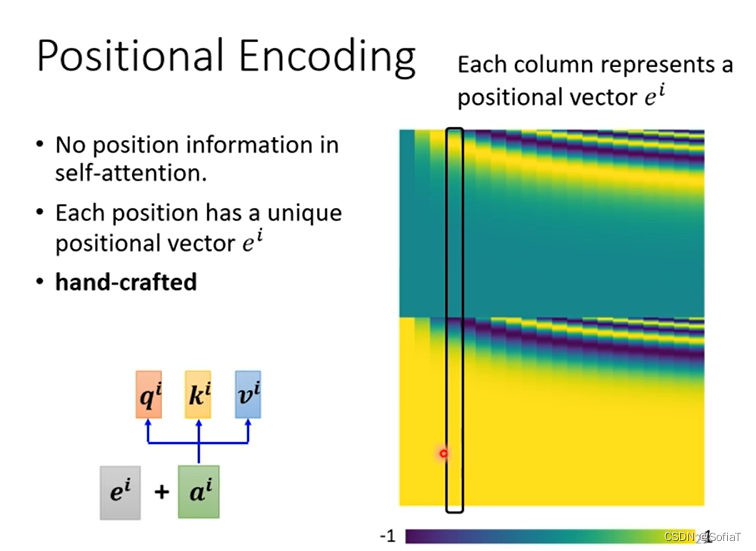 通过sin/cos的函数产生,也可以有新的方法或者训练得到。
通过sin/cos的函数产生,也可以有新的方法或者训练得到。
大量参数
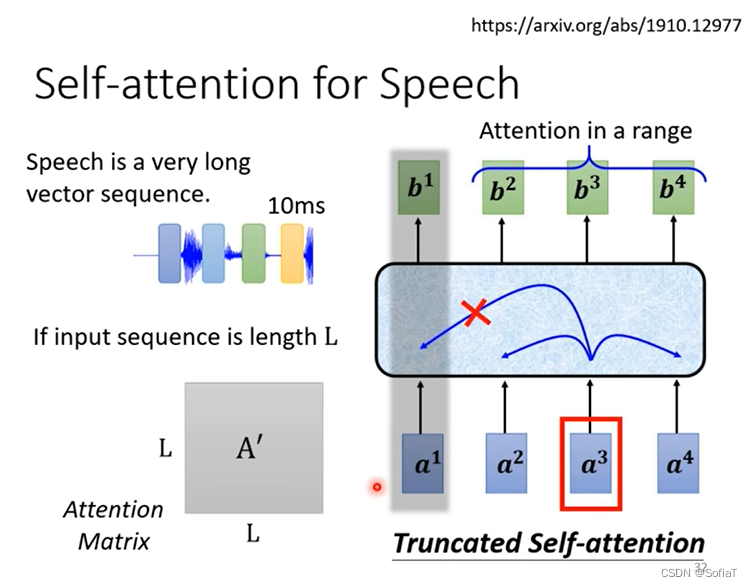 当输入向量过多时,L会很大,导致训练参数过大,这里就只看向量附近的局部向量。
当输入向量过多时,L会很大,导致训练参数过大,这里就只看向量附近的局部向量。
与其他方法对比
-
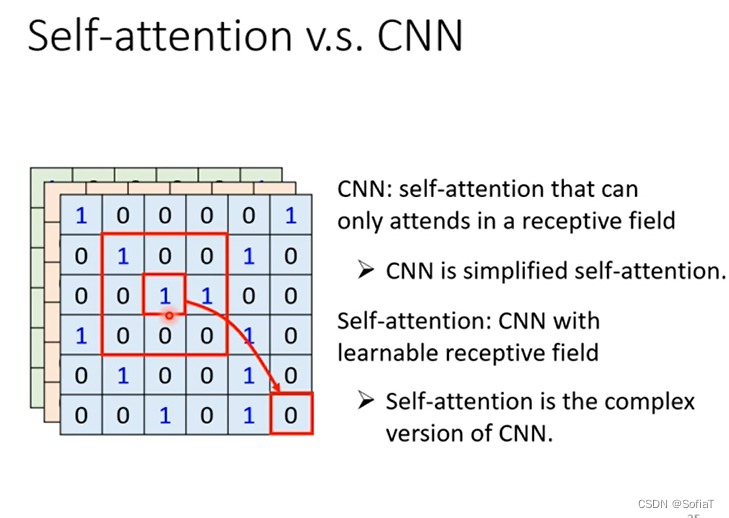
CNN相当于是局部的self-attention[on the relationship between self-attention and convolutional layers]
-
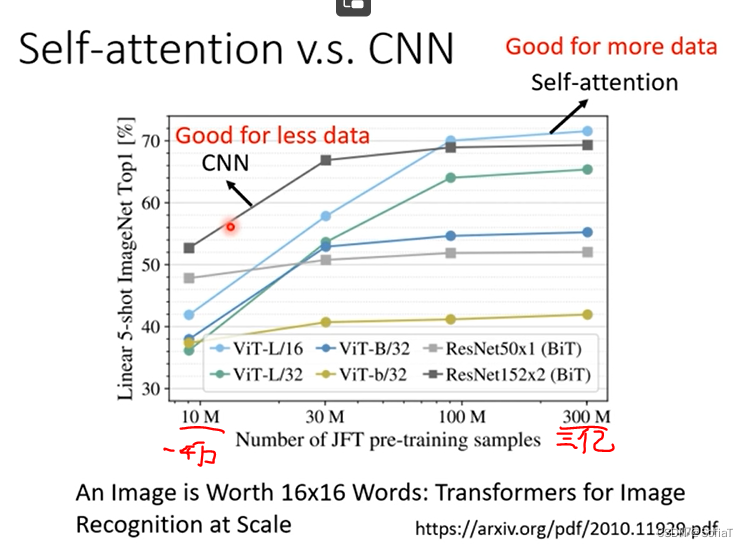
当数据量足够大的时候self-attention比较好,数据量比较小的时候transformer会欠拟合。self-attention的弹性比较大,会在数据量更大的时受益。
-
RNN所做的工作现在大部分都可以被self-attention取代。单向RNN只考虑新输入的,双向RNN能考虑但是距离非常的远。而且RNN不能并行化
 图的处理
图的处理
-
可以只计算有edge相连的node
-
是某种意义上的GNN。
各式各样的self attention
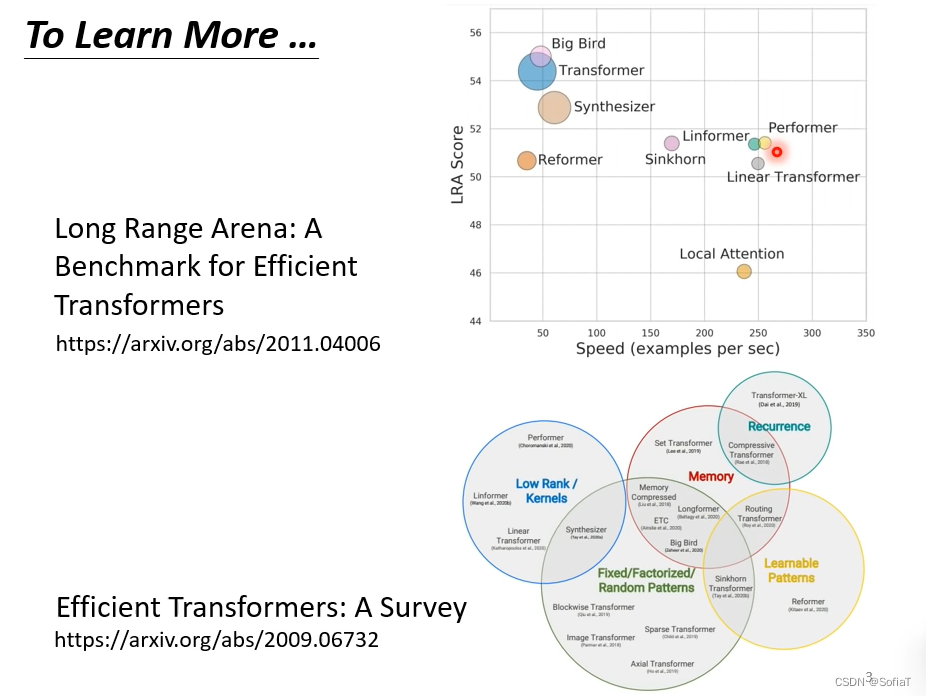 现在有各式各样self-attention的变体,一般以xxxformer为命名特点。
现在有各式各样self-attention的变体,一般以xxxformer为命名特点。
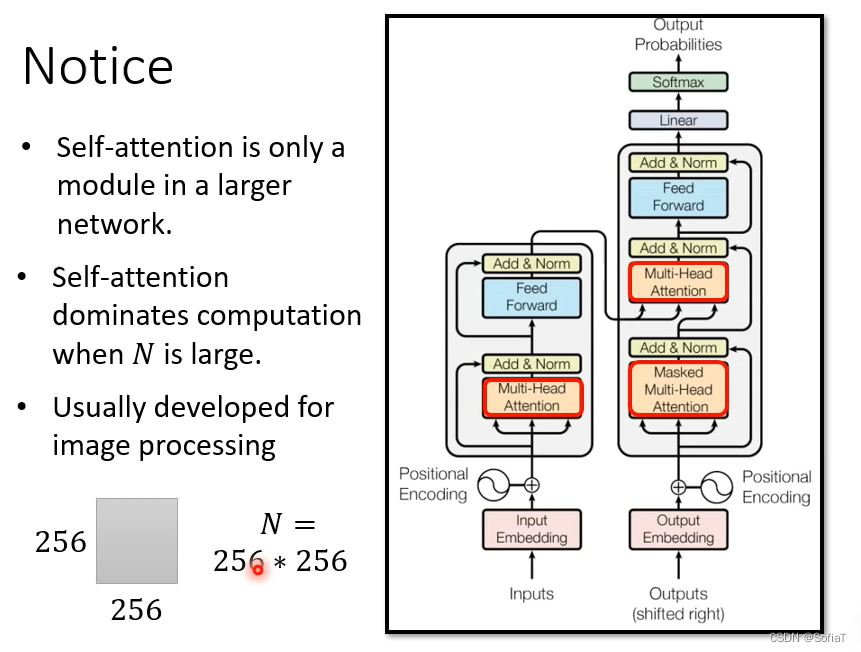
self-attention的痛点是矩阵运算量大。
但是这也是有前提的,当N偏小时,可能feed forward的部分就会占主导地位,所以优化self-attention对整个transformer意义不大。
英文单词
pos tagging:词性标注。
sequence labeling:有多少个向量就有多少个label。