作者:vivo 互联网服务器团队- Jiang Ye
本文详细的记录了一次0点接口严重超时的问题排查经历。本文以作者自身视角极具代入感的描绘了从问题定位到具体的问题排查过程,并通过根因分析并最终解决问题。整个过程需要清晰的问题排查思路和丰富的问题处理经验,也离不开公司强大的调用链、和全方位的系统监控等基础设施。
一、问题发现
我所负责的商城活动系统用于承接公司线上官方商城的营销活动,最近突然收到凌晨0点的服务超时告警。
营销活动类的系统有如下特点:
-
营销活动一般会0点开始,如红包雨、大额优惠券抢券等。
-
日常营销活动的机会刷新,如每日任务,每日签到,每日抽奖机会的刷新等。
营销活动的利益刺激会吸引大量真实用户及黑产前来参与活动,所以流量在0点会迎来一波小高峰,也正因如此线上偶现的服务超时告警起初并未引起我的注意。但是接下来的几天,每天的凌晨0点都会收到服务超时告警,这引起了我的警惕,决定一探究竟。
二、问题排查
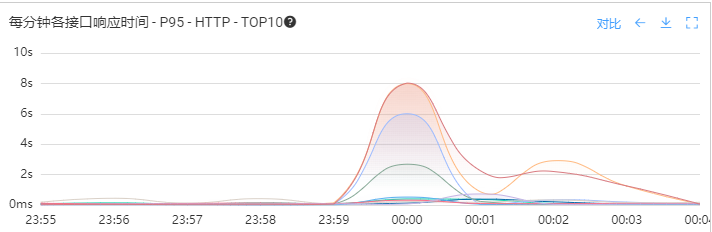
首先通过公司的应用监控系统查看了0点前后每分钟各接口的P95响应时间。如下图所示,接口响应时间在0点时刻最高达到了8s。继续查看锁定耗时最高的接口为商品列表接口,下面就针对这个接口展开具体的排查。
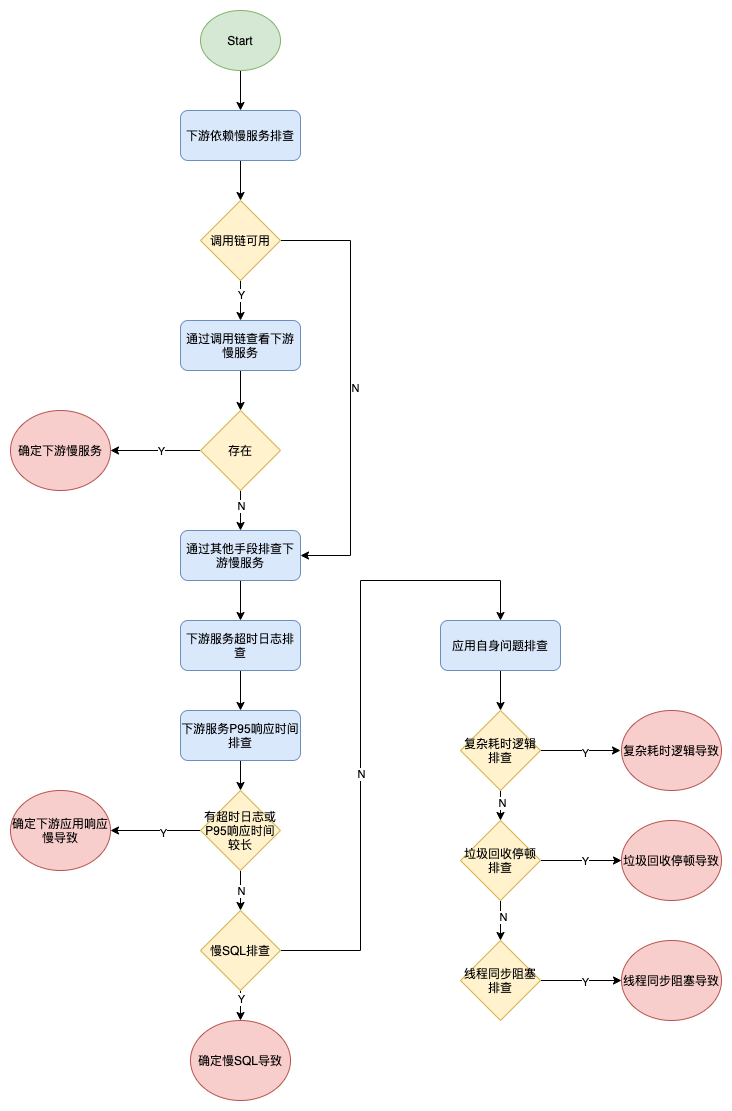
2.1 排查思路
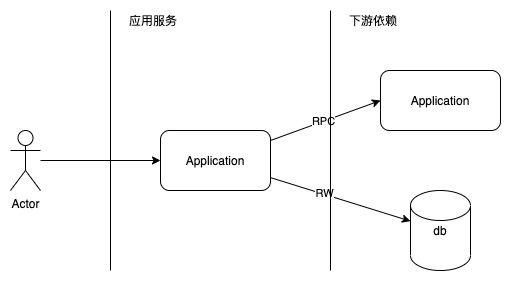
正式排查之前,先和大家分享下我对接口超时问题的排查思路。下图是一个简化的请求流程。
-
用户向应用发起请求
-
应用服务进行逻辑处理
-
应用服务通过RPC调用下游应用以及进行数据库的读写操作
服务超时可能是应用服务自身慢导致,也可能下游依赖响应慢导致。具体排查思路如下:
2.1.1 下游依赖慢服务排查
(1)通过调用链技术定位下游依赖中的慢服务
调用链技术是实现系统可观测性的重要保障,常见的开源方案有ziplin、pinpoint等。完整的调用链可以按时间正序记录每一次下游依赖调用的耗时,如rpc服务调用、sql执行耗时、redis访问耗时等。因此使用调用链技术可以迅速定位到下游依赖的慢服务,如dubbo接口访问超时、慢SQL等。但理想很丰满,现实很骨感。由于调用链路信息的数量过大,想要收集全量的链路信息需要较高的存储成本和计算资源。因此在技术落地时,通常都会采用抽样的策略来收集链路信息。抽样带来的问题是请求链路信息的丢失或不完整。
(2)无调用链时的慢服务排查
如果调用链丢失或不完整,我们就要再结合其它手段进行综合定位了。
下游RPC服务响应超时:如果是用Dubbo框架,在provider响应超时时会打印timeout相关日志;如果公司提供应用监控,还可以查看下游服务P95响应时间综合判断。
慢SQL:MySQL支持设置慢SQL阈值,超过该阈值会记录下慢SQL;像我们常用的数据库连接池Druid也可以通过配置打印慢SQL日志。如果确认请求链路中存在慢SQL可以进一步分析该SQL的执行计划,如果执行计划也没有问题,再去确认在慢SQL产生时mysql主机的系统负载。
下游依赖包含Redis、ES、Mongo等存储服务时,慢服务的排查思路和慢SQL排查相似,在此不再赘述。
2.1.2 应用自身问题排查
(1)应用逻辑耗时多
应用逻辑耗时多比较常见,比如大量对象的序列化和反序列化,大量的反射应用等。这类问题的排查通常要从分析源码入手,编码时应该尽量避免。
(2)垃圾回收导致的停顿(stop the world)
垃圾回收会导致应用的停顿,特别是发生Old GC或Full GC时,停顿明显。不过也要看应用选配的垃圾回收器和垃圾回收相关的配合,像CMS垃圾回收器通常可以保证较短的时间停顿,而Parallel Scavenge垃圾回收器则是追求更高的吞吐量,停顿时间会相对长一些。
通过JVM启动参数-XX:+PrintGCDetails,我们可以打印详细的GC日志,借此可以观察到GC的类型、频次和耗时。
(3)线程同步阻塞
线程同步,如果当前持有锁的线程长时间持有锁,排队的线程将一直处于blocked状态,造成服务响应超时。可以通过jstack工具打印线程堆栈,查找是否有处于block状态的线程。当然jstack工具只能采集实时的线程堆栈信息,如果想要查看历史堆栈信息一般需要通过Prometheus进行收集处理。
2.2 排查过程
下面按照这个排查思路进行排查。
2.2.1 下游依赖慢服务排查
(1)通过调用链查看下游慢服务
首先到公司的应用监控平台上,筛选出0点前后5min的调用链列表,然后按照链路耗时逆序排列,发现最大接口耗时7399ms。查看调用链详情,发现下游依赖耗时都是ms级别。调用链因为是抽样采集,可能存在链路信息丢失的情况,因此需要其他手段进一步排查下游依赖服务。

(2)通过其他手段排查下游慢服务
接着我查看了0点前后的系统日志,并没有发现dubbo调用超时的情况。然后通过公司的应用监控查看下游应用P95响应时间,如下图,在0点时刻,下游的一些服务响应时长确实会慢一些,最高的达到了1.45s,虽然对上游有一定影响,但不至于影响这么大。
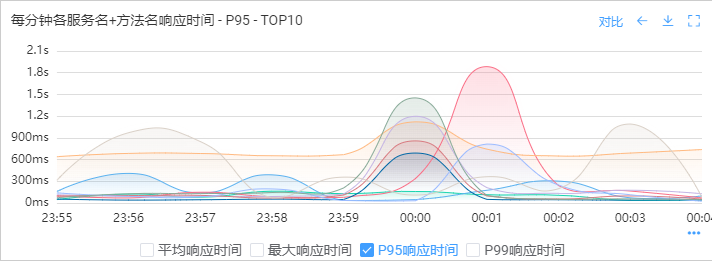
(3)慢SQL排查
接下来是慢SQL的排查,我们系统的连接池使用的是阿里开源的druid,SQL执行超过1s会打印慢SQL日志,查看日志中心也没有发现慢SQL的踪迹。
到现在,可以初步排除因下游依赖慢导致服务超时,我们继续排查应用自身问题。
2.2.2 应用自身问题排查
(1)复杂耗时逻辑排查
首先查看了接口的源码,整体逻辑比较简单,通过dubbo调用下游商品系统获取商品信息,本地再进行商品信息的排序等简单的处理。不存在复杂耗时逻辑问题。
(2)垃圾回收停顿排查
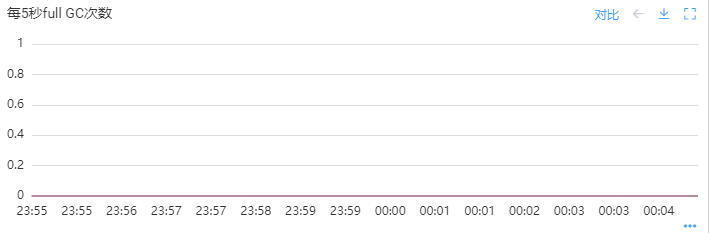
通过公司应用监控查看应用的GC情况,发现0点前后没有发生过full GC,也没有发生过Old GC。垃圾回收停顿的因素也被排除。
(3)线程同步阻塞排查
通过公司应用监控查看是否存在同步阻塞线程,如下图:
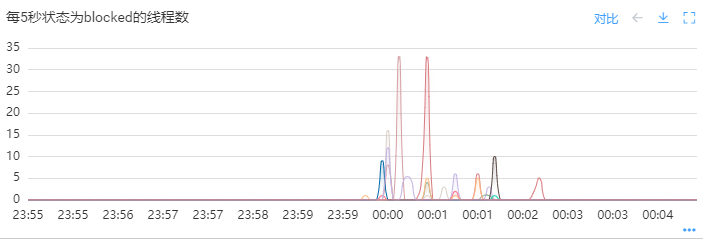
看到这里,终于有种天不负有心人的感觉了。从00:00:00开始一直到00:02:00,这两分钟里,出现了较多状态为BLOCKED的线程,超时的接口大概率和这些blocked线程相关。我们只需要进一步分析JVM堆栈信息即可真相大白。
我们随机选取一台比较有代表性的机器查看block堆栈信息,堆栈采集时间是2022-08-02 00:00:20。
// 日志打印操作,被线程catalina-exec-408阻塞
"catalina-exec-99" Id=506 BLOCKED on org.apache.log4j.spi.RootLogger@15f368fa owned by "catalina-exec-408" Id=55204
at org.apache.log4j.Category.callAppenders(Category.java:204)
- blocked on org.apache.log4j.spi.RootLogger@15f368fa
at org.apache.log4j.Category.forcedLog$original$mp4HwCYF(Category.java:391)
at org.apache.log4j.Category.forcedLog$original$mp4HwCYF$accessor$pRDvBPqB(Category.java)
at org.apache.log4j.Category$auxiliary$JhXHxvpc.call(Unknown Source)
at com.vivo.internet.trace.agent.plugin.interceptor.enhance.InstMethodsInter.intercept(InstMethodsInter.java:46)
at org.apache.log4j.Category.forcedLog(Category.java)
at org.apache.log4j.Category.log(Category.java:856)
at org.slf4j.impl.Log4jLoggerAdapter.info(Log4jLoggerAdapter.java:324)
...
// 日志打印操作,被线程catalina-exec-408阻塞
"catalina-exec-440" Id=55236 BLOCKED on org.apache.log4j.spi.RootLogger@15f368fa owned by "catalina-exec-408" Id=55204
at org.apache.log4j.Category.callAppenders(Category.java:204)
- blocked on org.apache.log4j.spi.RootLogger@15f368fa
at org.apache.log4j.Category.forcedLog$original$mp4HwCYF(Category.java:391)
at org.apache.log4j.Category.forcedLog$original$mp4HwCYF$accessor$pRDvBPqB(Category.java)
at org.apache.log4j.Category$auxiliary$JhXHxvpc.call(Unknown Source)
at com.vivo.internet.trace.agent.plugin.interceptor.enhance.InstMethodsInter.intercept(InstMethodsInter.java:46)
at org.apache.log4j.Category.forcedLog(Category.java)
at org.apache.log4j.Category.log(Category.java:856)
at org.slf4j.impl.Log4jLoggerAdapter.warn(Log4jLoggerAdapter.java:444)
...
// 日志打印操作,被线程catalina-exec-408阻塞
"catalina-exec-416" Id=55212 BLOCKED on org.apache.log4j.spi.RootLogger@15f368fa owned by "catalina-exec-408" Id=55204
at org.apache.log4j.Category.callAppenders(Category.java:204)
- blocked on org.apache.log4j.spi.RootLogger@15f368fa
at org.apache.log4j.Category.forcedLog$original$mp4HwCYF(Category.java:391)
at org.apache.log4j.Category.forcedLog$original$mp4HwCYF$accessor$pRDvBPqB(Category.java)
at org.apache.log4j.Category$auxiliary$JhXHxvpc.call(Unknown Source)
at com.vivo.internet.trace.agent.plugin.interceptor.enhance.InstMethodsInter.intercept(InstMethodsInter.java:46)
at org.apache.log4j.Category.forcedLog(Category.java)
at org.apache.log4j.Category.log(Category.java:856)
at org.slf4j.impl.Log4jLoggerAdapter.warn(Log4jLoggerAdapter.java:444)
...通过堆栈信息可以分析出2点:
-
处于blocked状态的线程都是日志打印
-
所有的线程都是被线程名为“catalina-exec-408”阻塞
追踪到这里,慢服务的表层原因就清楚了。被线程catalina-exec-408阻塞的线程,一直处于blocked状态,导致服务响应超时。
三、根因分析
表层原因找到以后,我们一起拨开层层迷雾,寻找真相背后的真相吧!
所有慢服务的线程都是在打印日志的时候被线程catalina-exec-408阻塞。那么线程catalina-exec-408在做什么呢?

可以发现,在00:00:18.858时刻,该线程在打印登录态校验失败的日志,也并无复杂的处理逻辑。难道是该线程打印日志慢,阻塞了其他线程吗?带着这个疑问,我开始深入日志框架的源码寻找答案。
我们的项目使用的日志框架是slf4j + log4j。根据被阻塞的线程栈信息我们定位到这段代码如下:
public
void callAppenders(LoggingEvent event) {
int writes = 0;
for(Category c = this; c != null; c=c.parent) {
// Protected against simultaneous call to addAppender, removeAppender,...
// 这是204行,加了sychronized
synchronized(c) {
if(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if(!c.additive) {
break;
}
}
}
if(writes == 0) {
repository.emitNoAppenderWarning(this);
}
}可以看到堆栈信息中的204行是synchronized代码块,对其它线程造成阻塞的这是这块代码。那么synchronized代码块内部逻辑是什么呢?为什么要执行很久呢?下面是synchronized代码块中的核心逻辑:
public
int appendLoopOnAppenders(LoggingEvent event) {
int size = 0;
Appender appender;
if(appenderList != null) {
size = appenderList.size();
for(int i = 0; i < size; i++) {
appender = (Appender) appenderList.elementAt(i);
appender.doAppend(event);
}
}
return size;
}可以看到,这块逻辑就是将日志写入所有配置的appender中。我们配置的appender有两个,一个是console appender,也就是输出到catalina.out文件。还有一个是按照公司日志中心采集要求,以Json格式输出的appender。这里可以做出推断,线程catalina-exec-408在将日志输出到appender时耗时较多。
我很自然的开始怀疑当时的机器负载,特别是IO负载可能会比较高,通过公司的机器监控,我们查看了下相关指标:

果然,从00:00:00开始,磁盘IO消耗持续彪高,到1分钟20秒第一波高峰才结束,在00:00:20时刻,IO消耗达到峰值99.63%,接近100%。难怪应用输出一条日志都这么难!
到底是谁把IO资源消耗光了,消耗到几乎骨头都不剩?带着疑问,我进一步通过公司的机器监控查看了主机快照:

发现在00:00:20时刻,tomcat用户在执行脚本/bin/sh /scripts/cutlog.sh,脚本在执行命令cp catalina.out catalina.out-2022-08-02-00。IO消耗达到了109475612 bytes/s(约104MB/s) 。
事情就要水落石出了,我们继续掘地三尺。运维同学登陆到机器上,切换到tomcat用户,查看定时任务列表(执行crontab -l),得到结果如下:
00 00 * * * /bin/sh /scripts/cutlog.sh正是快照中的脚本/bin/sh /scripts/cutlog.sh,每天0点执行。具体的脚本内容如下:
$ cat /scripts/cutlog.sh
#!/bin/bash
files=(
xxx
)
time=$(date +%F-%H)
for file in ${files[@]}
do
dir=$(dirname ${file})
filename=$(echo "xxx"|awk -F'/' '{print $NF}')
# 归档catalina.out日志并清空catalina.out当前文件内容
cd ${dir} && cp ${filename} ${filename}-${time} && > ${filename}
done我们从脚本中找到了高IO消耗的元凶,就是这个copy命令,目的是将catalina.out日志归档并将catalina.out日志文件清空。
这个正常的运维脚本肯定是比较消耗 IO 资源的,执行的时长受文件大小影响。运维同学也帮忙看了下归档的日志大小:
[root@xxx:logdir]
# du -sh *
1.4G catalina.out
2.6G catalina.out-2022-08-02-00
归档的文件大小有2.6 G,按照104MB/s估算,需要耗时25秒。也就是00:00:00到00:00:25期间,业务日志输出都会比较缓慢,造成大量线程block,进而导致接口响应超时。
四、问题解决
定位到了问题的根因,就可以对症下药了。有几个方案可以选择:
4.1 生产环境不打印日志到console
消耗 IO资源的操作就是catalina.out日志的归档,如果不写日志到该文件,是可以解决日志打印IO等待的问题的。但是像本地调试、压测环境还是比较依赖console日志的,所以就需要根据不同环境来设置不同的console appender。目前logback、Log4j2已经支持根据Spring profile来区别配置,我们用的Log4j还不支持。切换日志底层框架的成本也比较高,另外早期的公司中间件与Log4j日志框架强耦合,无法简单切换,所以我们并没有采用这个方案。
4.2 配置日志异步打印
Log4j提供了AsyncAppender用于支持异步日志打印,异步日志可以解决同步日志打印IO等待的问题,不会阻塞业务线程。
异步日志的副作用:
异步日志是在日志打印时,将event加入到buffer队列中,buffer的大小默认是128,支持配置。关于buffer满了后有两种处理策略。
(1)阻塞
当属性blocking设置为true时,使用阻塞策略,默认是true。即buffer满了后,同步等待,此时线程会阻塞,退变成同步日志。
(2)丢弃
如果blocking设置为false,在buffer满了以后,会将该条日志丢弃。
4.3 最终方案
最终我们选择了方案2,即配置日志异步打印。buffer队列大小设置2048,考虑到部分日志丢失在业务上是可以接受的,因此牺牲了小部分可靠性换区更高的程序性能,将blocking设置为false。
4.4 小结
这次的问题排查经历,我收获了几点感悟,和大家分享一下:
1)要对线上告警保持敬畏之心
我们应该敬畏每一个线上告警,重视每一条错误日志。现实情况是大多数时候告警只是因为网络抖动,短暂的突发流量等,是可以自行恢复的,这就像狼来了的故事一样,让我们放松了警惕,导致我们可能会错过真正的问题,给系统带来严重灾难,给业务带来损失。
2)刨根问底
告警只是表象,我们需要搞清楚每个告警的表面原因和根本原因。比如这次的接口超时告警,只有分析出”copy文件耗尽磁盘IO,导致日志打印线程block“这个根本原因后,才能给出优雅合理的解决方案。说起来简单,实操起来可能会遇到很多困难,这要求我们有清晰的问题排查思路,有良好的的系统可观测性建设,有扎实的技术基本功和不找到”真凶“永不放弃的决心。
最后希望我的这次问题排查经历能够让你有所收获,有所启发。我也将本文用到的超时问题排查思路整理成了流程图,供大家参考。你有遇到过哪些线上故障呢?你的排查思路是怎样的呢?欢迎留言交流讨论。