文章目录
- 准备工作
- 创建项目:
- 设置(settings)
- 主程序入口meinv.py
- 思路
- 源代码
- items 配置
- 管道pipelines
- 源代码
- 效果图
- 总结
准备工作
创建项目:
scraoy startproject bizhi
cd bizhi
scrapy genspider meinv bizhi360.com
设置(settings)
在里面添加这些参数
LOG_LEVEL = "ERROR" #设置允许显示的日志
IMAGES_STORE = "./meinvtupian" #创建本地保存图片的地址
在设置里开启并添加管道
ITEM_PIPELINES = {
"bizhi.pipelines.BizhiPipeline": 303, #管道的优先级,越小越优先
"bizhi.pipelines.MeinvPipeline": 301,
}
主程序入口meinv.py
思路
分析网站原码可以看到图片在一个个li标签里面,点进去才是我们需要的大图,OK,思路有了,拿小图—>得到大图地址–>再次请求大图–>保存
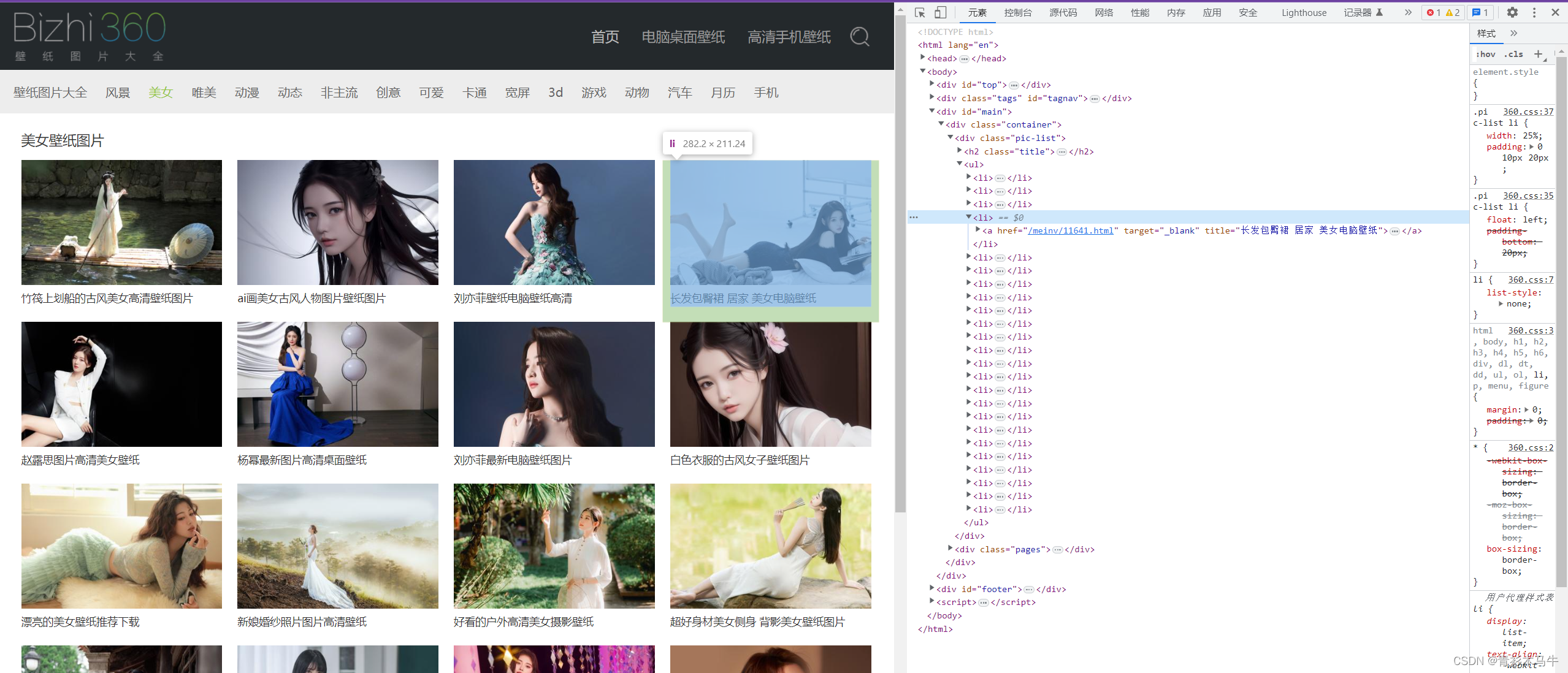
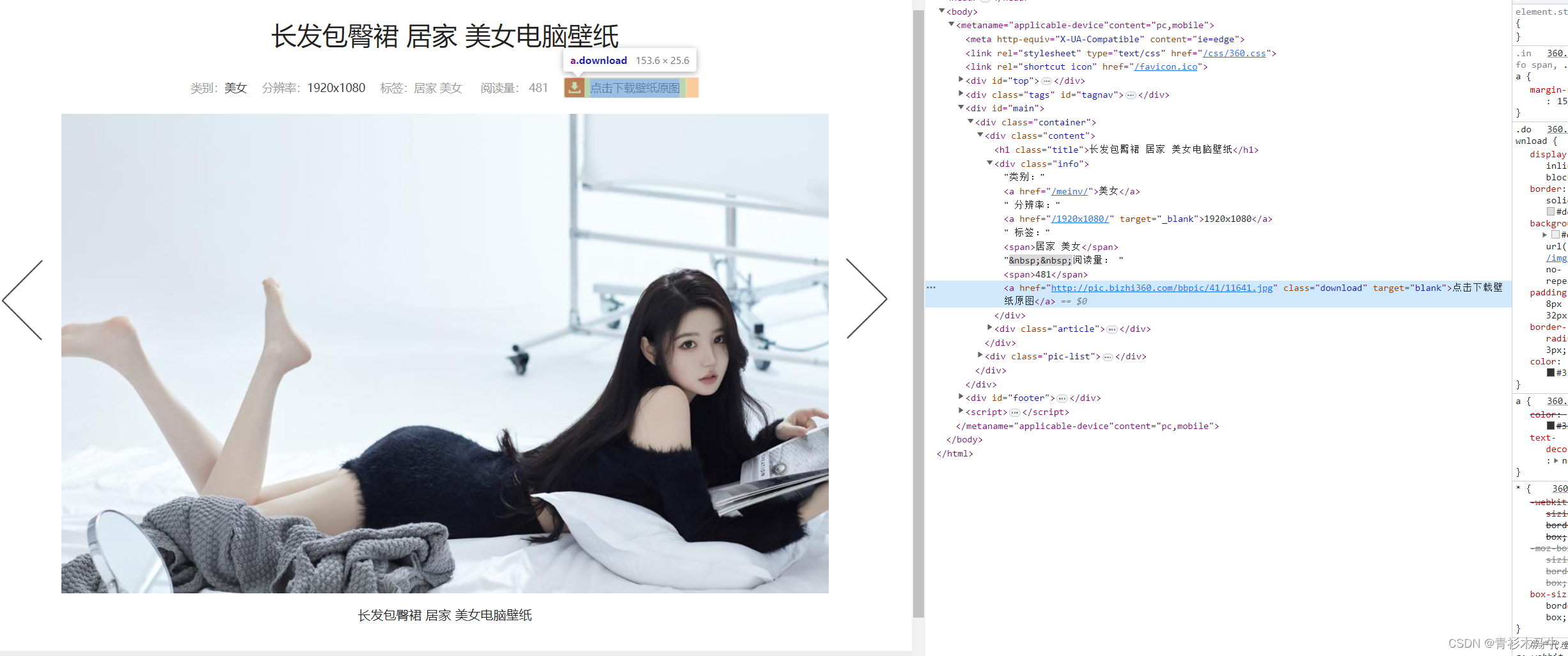
源代码
import scrapy
from bizhi.items import BizhiItem
class MeinvSpider(scrapy.Spider):
name = "meinv"
allowed_domains = ["www.bizhi360.com"]
start_urls = ["http://www.bizhi360.com/meinv/", "http://www.bizhi360.com/dongman/"]
def parse(self, response):
# print(response.text)
# 通过xpath得到所有的li标签
li_s = response.xpath('//*[@id="main"]/div/div[1]/ul/li')
for li in li_s:
# 遍历li拿到里面所有的大图地址
href = li.xpath('./a/@href').extract_first()
# print(response.urljoin(href))
# 请求刚才得到的大图地址
yield scrapy.Request(
url=response.urljoin(href),
method='get',
callback=self.two_parse # 回调函数,当响应回馈之后,如何处理
)
# break
def two_parse(self, response):
# 接收上面返回的数据,拿到图片的名字,地址
names = response.xpath('//h1/text()').extract_first().strip() + '.jpg'
hrefs = response.xpath('//*[@id="main"]/div/div[1]/div[2]/figure/a/@href').extract_first()
print(names, hrefs)
# 提前定义好BizhiItem并调用
item = BizhiItem()
item['name'] = names
item['img_src'] = hrefs
# 必须要有返回值,不然第二个管道收不到数据
yield item
items 配置
import scrapy
class BizhiItem(scrapy.Item):
name = scrapy.Field() # 图片名字
img_src = scrapy.Field() # 图片地址
local_src = scrapy.Field() # 图片保存在本地的地址
管道pipelines
这里要创建两个存储管道,一个是本地,一个是MySQL
源代码
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import pymysql
from bizhi.items import BizhiItem
# 数据库存储管道
class BizhiPipeline:
# open_spider是scrapy内置,声明在程序开始做些什么,这里我们连接本地的mysql数据库
def open_spider(self, spider):
self.conn = pymysql.connect(
host='localhost',
user='root',
password='root',
database='spider',
port=3306
)
# 同样为scraoy内置,程序结束之后关闭数据库连接
def close_spider(self, spider):
if self.conn:
self.conn.close()
def process_item(self, item, spider):
# print(item)
# 创建游标
cursor = self.conn.cursor()
# 执行SQL语句进行保存
sql = "INSERT INTO spider.picture(name, img_src, local_src) VALUES (%s, %s, %s)"
cursor.execute(sql, (item['name'], item['img_src'], item['local_src'],))
# self.conn.commit()
return item
# 本地存储管道
class MeinvPipeline(ImagesPipeline):
def get_media_requests(self, item, info): # 负责下载
return scrapy.Request(item['img_src']) # 直接返回一个请求
def file_path(self, request, response=None, info=None, item=BizhiItem): # 准备文件路径
# file_name = request.url.split('/')[-1]
file_name = item['name']
return f"img/{file_name}"
def item_completed(self, results, item, info): # 返回文件的详细信息
print(results[0][1]['path'])
# print(info)
item['local_src'] = results[0][1]['path'] # 从返回的文件信息里拿到图片的本地地址
return item
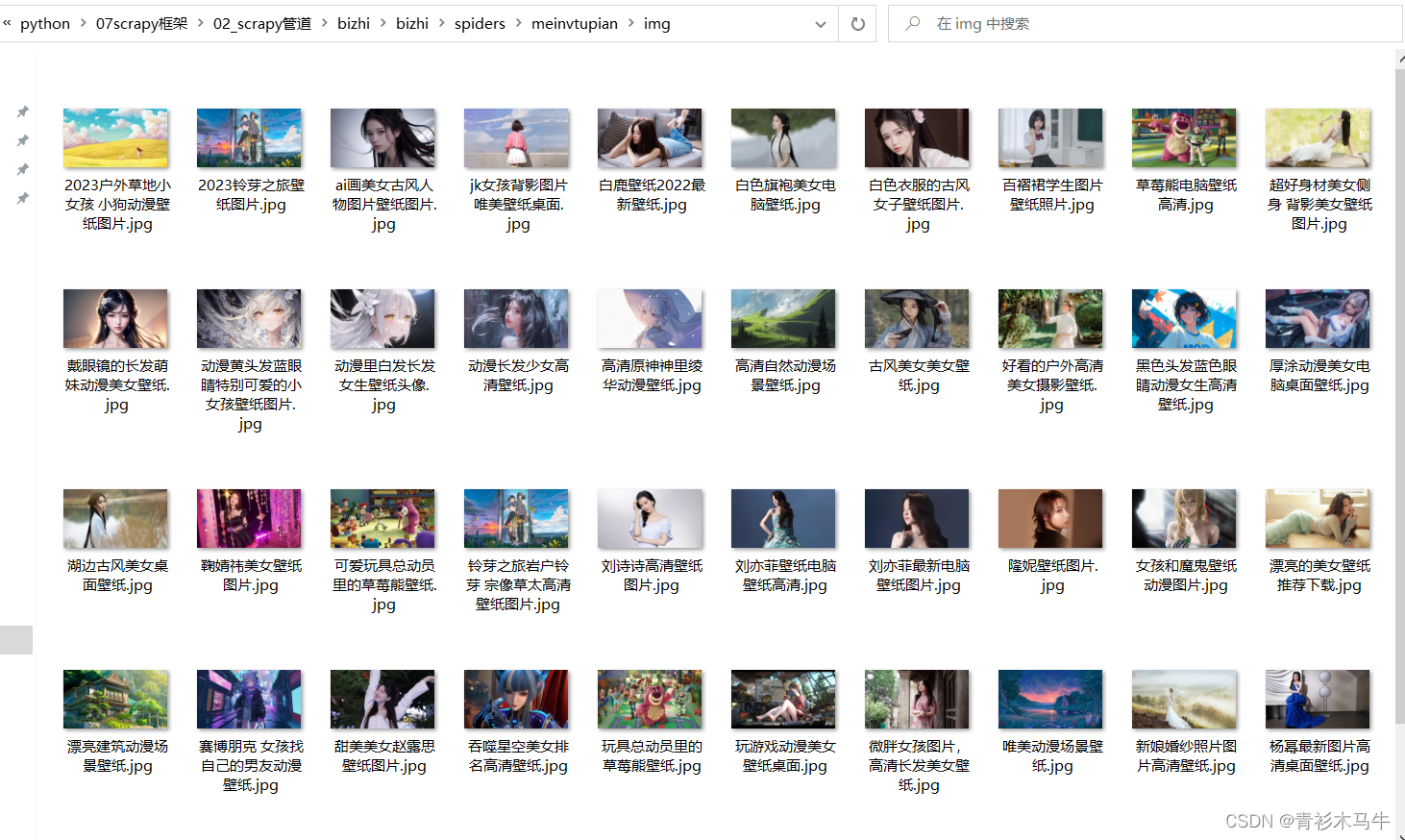
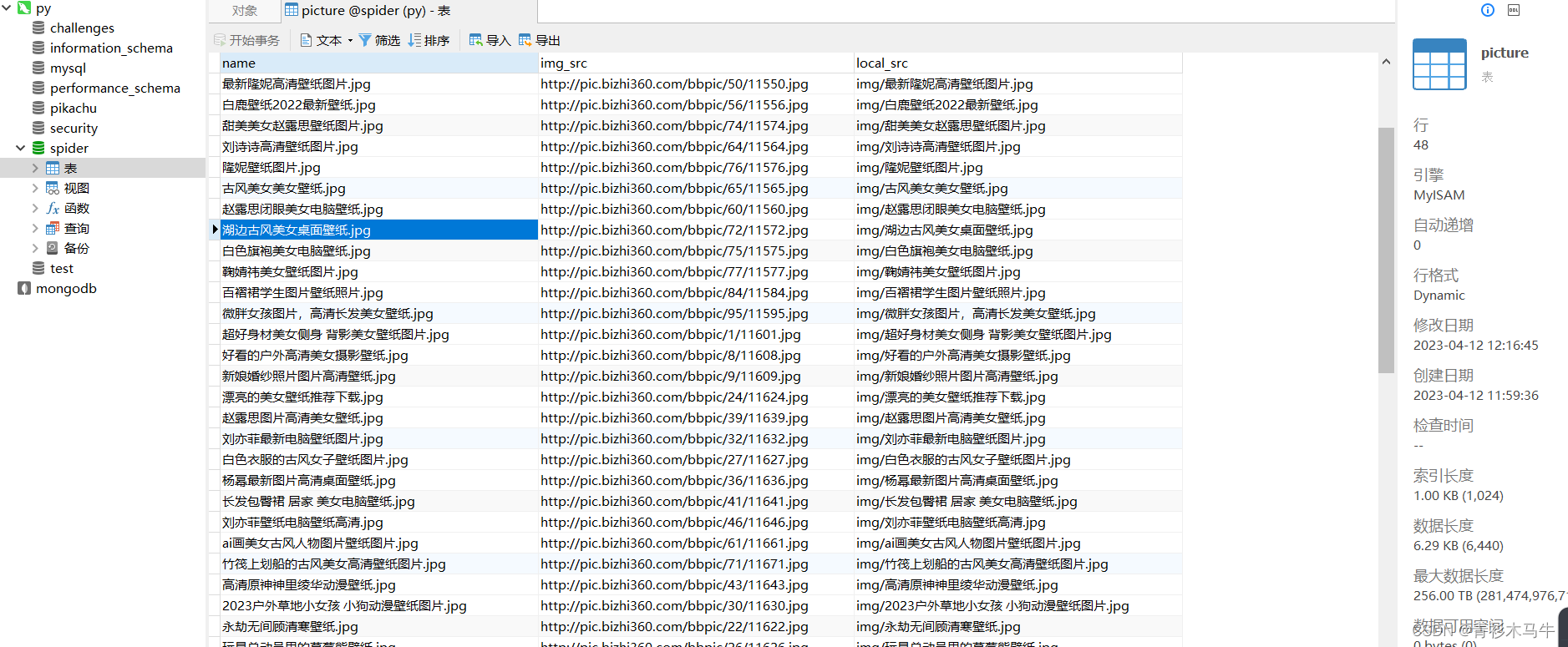
效果图
本地:
数据库:
总结
完美运行,跑了两页,下载更多主程序搞个循环就好,数据库存储过程中,数据库,表,记得提前创建,我没有用代码创建,程序还有很多可以改进的地方,就这样吧