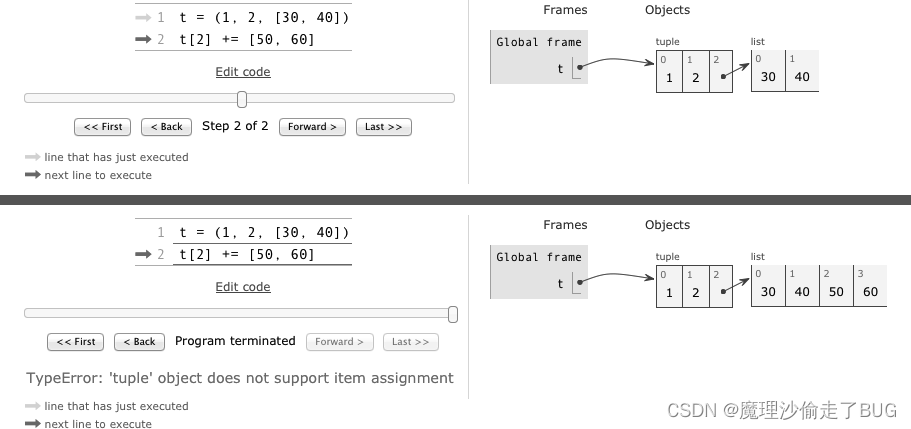
旧金山犯罪案件分类本质是一个文本的多分类任务,kaggle官网地址在这里,如下所示:
本文主要是以kaggle比赛数据集为基准,开发实践文本多分类任务。
比赛背景
从 1934 年到 1963 年,旧金山因高犯罪率而臭名昭著。时至今日,旧金山虽以高科技闻名于世,但随着财富不平等的加剧、住房短缺以及乘坐 BART 上班的人数激增,这座海湾城市的犯罪率仍然居高不下。
本次比赛数据集提供了旧金山所有社区近 12 年的犯罪报告。 给定时间和地点,需要我们做的是预测犯罪的类型。除外,比赛还鼓励我们探索数据集,比如可以通过犯罪地图可视化来了解这座城市的哪些信息?我们具体来看一下数据。数据描述


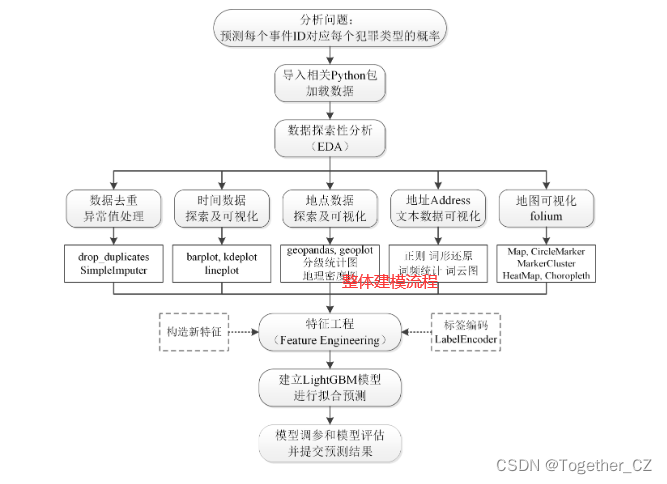
建模流程
数据处理
首先借助于pandas等工具包实现数据的加载处理
train = pd.read_csv("./train.csv", parse_dates=['Dates'])
test = pd.read_csv("./test.csv", parse_dates=['Dates'], index_col='Id')
print('训练集开始日期: ', str(train.Dates.describe()['first']))
print('训练集结束日期: ', str(train.Dates.describe()['last']))
print('测试集开始日期: ', str(test.Dates.describe()['first']))
print('测试集结束日期: ', str(test.Dates.describe()['last']))
print('训练集大小: ', train.shape)
print('测试集大小: ', test.shape)输出如下:
训练集开始日期: 2003-01-06 00:01:00
训练集结束日期: 2015-05-13 23:53:00
测试集开始日期: 2003-01-01 00:01:00
测试集结束日期: 2015-05-10 23:59:00
训练集大小: (878049, 9)
测试集大小: (884262, 6)数据概览如下:
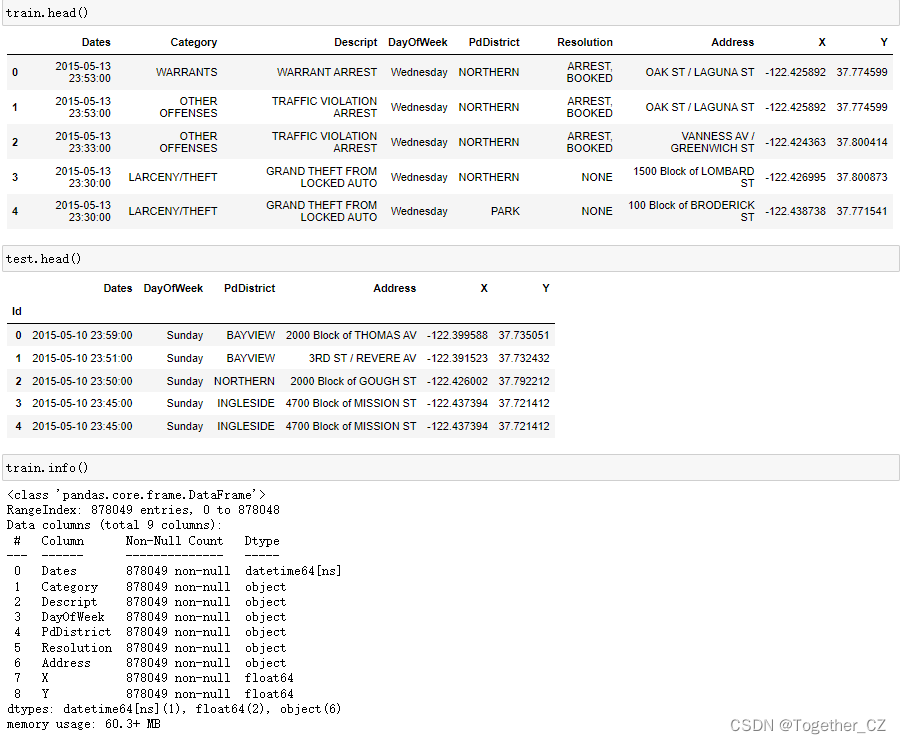
接下来对数据进行EDA探索分析
首先将经纬度转化为地理坐标如下:
train_gdf = create_gdf(train)world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres')) # shp文件
ax = world.plot(figsize=(6, 10), color='white', edgecolor='black')
train_gdf.plot(ax=ax, color='red')
plt.show()结果如下所示:
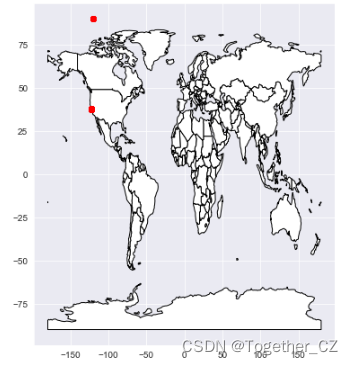
让我们具体来看看有多少点错位了,可以通过纬度大于 50 来检索。我们将使用它们所属区域的平均坐标替换错误的坐标。
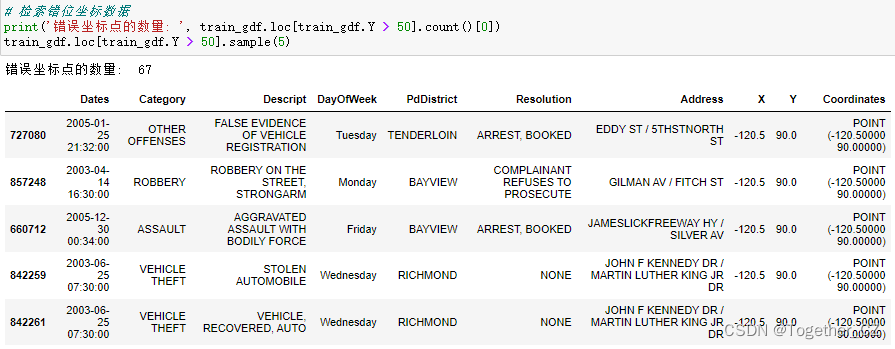
这里一个简单的修正方法就是使用错位坐标点所属区域的平均坐标将其替换,如下:
train.replace({'X': -120.5, 'Y': 90.0}, np.NaN, inplace=True)
test.replace({'X': -120.5, 'Y': 90.0}, np.NaN, inplace=True)
imp = SimpleImputer(strategy='mean')
for district in train['PdDistrict'].unique():
for df in [train, test]:
df.loc[df['PdDistrict'] == district, ['X', 'Y']] = imp.fit_transform(df.loc[df['PdDistrict'] == district, ['X', 'Y']])接下来逐一分析主要变量
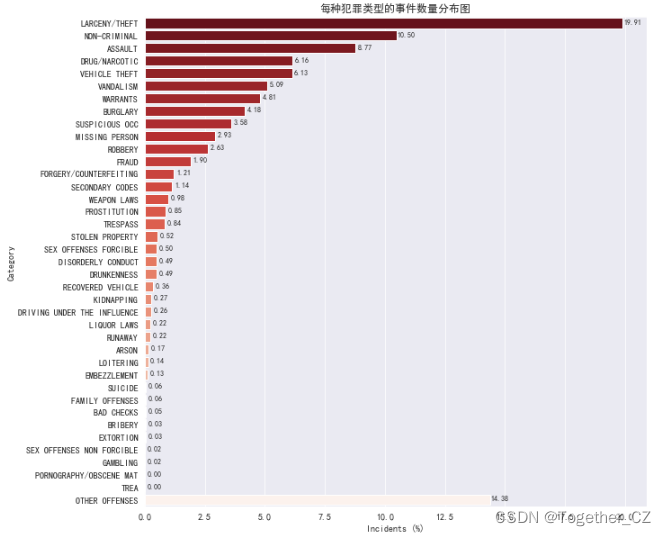
Category 有 39 个类别,最常见的事件是:Larceny/Theft 盗窃案/盗窃(19.91%)、Non-Criminal 非犯罪分子(10.50%)、Assault 袭击(8.77%),详情分布图如下所示:
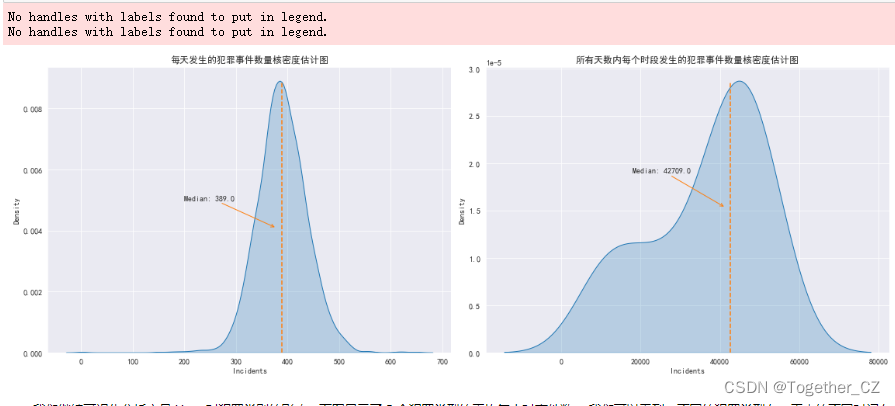
接下来绘制每天发生的犯罪事件数量的核密度估计图,并绘制中位数的垂直线,如下所示:
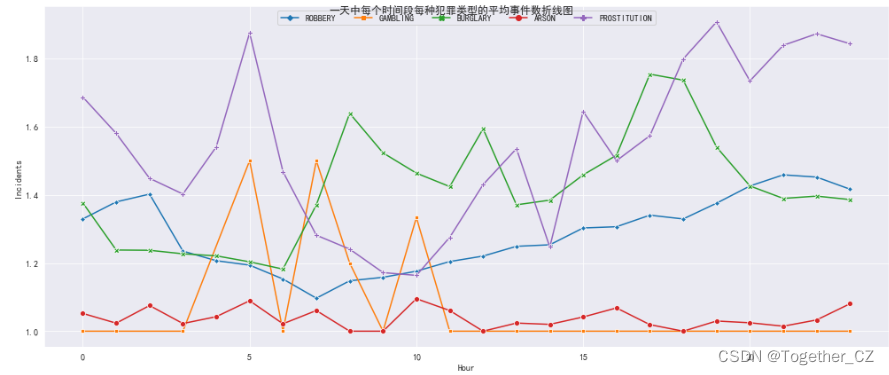
绘制5个犯罪类型的平均每小时事件数折线图,核心实现如下:
Category_5 = ['ROBBERY', 'GAMBLING', 'BURGLARY', 'ARSON', 'PROSTITUTION']
HourCategory_5 = HourCategory.loc[HourCategory['Category'].isin(Category_5)]
fig, ax = plt.subplots(figsize=(14, 6))
ax = sns.lineplot(x='Hour', y='Incidents', data=HourCategory_5,
hue='Category', hue_order=Category_5, style="Category", markers=True, dashes=False)
ax.legend(loc='upper center', ncol=5)
plt.suptitle('一天中每个时间段每种犯罪类型的平均事件数折线图')
fig.tight_layout()
plt.show()结果如下:
为了探索不同一周内不同日期下犯罪频率的波动,这里绘制对应的统计直方图,如下:

总体可见:犯罪波动与周几没有明显的联系。
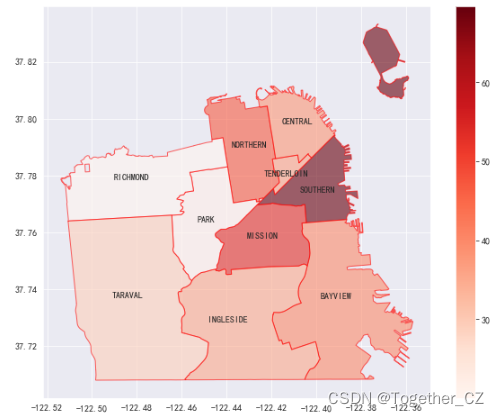
之后计算每个警察区区域平均一天中发生的犯罪频率并绘图,如下所示:
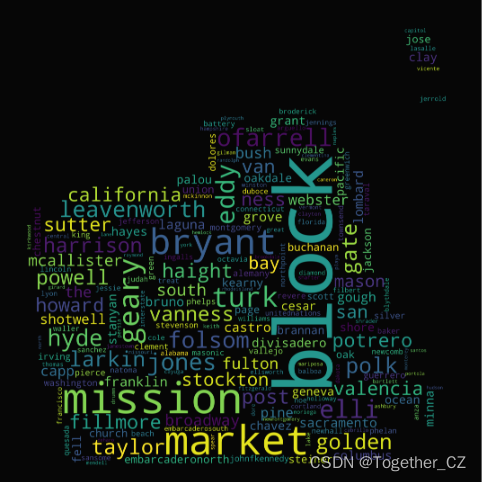
由于原始案件均为文本数据,这里对其进行预处理,并统计词频等信息,绘制词云图,如下:
# 应用函数并统计词频
text = ' '.join(train.Address.values)
words = tokenize(text)
word_counts = collections.Counter(words)
word_counts_top = word_counts.most_common(20) # 获取前20个最高频的词输出如下:
[('block', 615322),
('mission', 47947),
('market', 42333),
('bryant', 31772),
('geary', 20098),
('turk', 18645),
('eddy', 15377),
('elli', 14714),
('ofarrell', 13729),
('jones', 12754),
('hyde', 12513),
('folsom', 12032),
('leavenworth', 11616),
('polk', 10931),
('gate', 10716),
('golden', 10484),
('larkin', 10383),
('taylor', 9937),
('harrison', 9862),
('powell', 9619)]绘制词云图的代码在我之前的文章中都有,这里简单看下即可:
my_mask = np.array(Image.open('bg.png'))
plt.figure(figsize=(10, 10))
wc = WordCloud(width=1400, height=2200,
background_color='black',
mode='RGB',
mask=my_mask,
max_words=200,
random_state=50,
scale=2
).generate_from_frequencies(word_counts)
plt.axis('off')
plt.imshow(wc.recolor(colormap='viridis', random_state=17), alpha=0.98)如下所示:
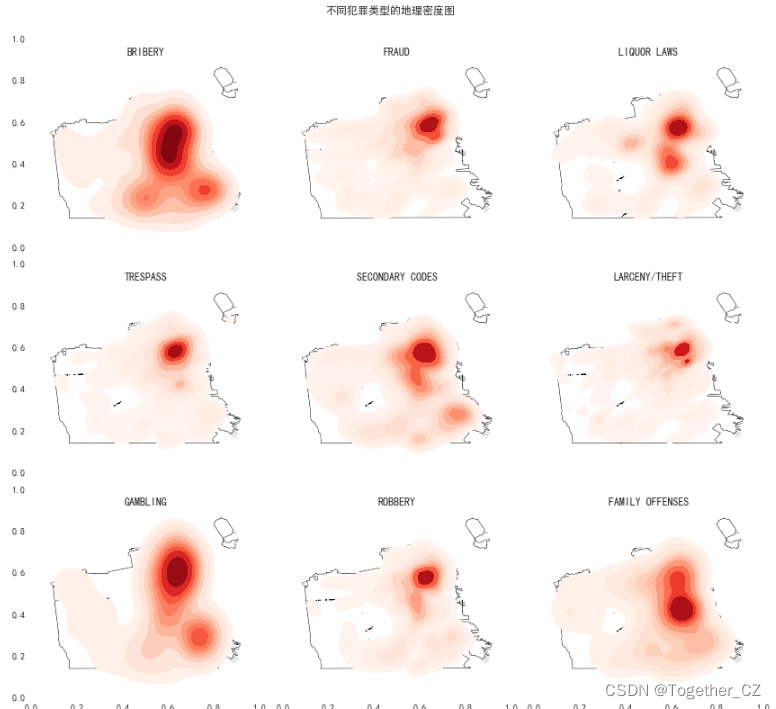
接下来绘制不同犯罪类型的地理密度图,如下所示:
完成数据的EDA之后就可以开始着手建模处理了。
特征工程
这里主要是构造相关时间特征和关键地址特征,如下:
train = feature_engineering(train)
train.drop(columns=['Descript', 'Resolution'], inplace=True)
test = feature_engineering(test)
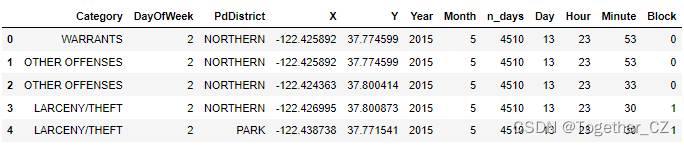
train.head()输出如下:
这里为了对不同模型进行对比分析,这里将数据存储为json文件方便重复加载,如下:
X_train, X_test, y_train, y_test = train_test_split(train, y, test_size=0.3)
dataset={}
dataset["X_train"]=X_train
dataset["y_train"]=y_train
dataset["X_test"]=X_test
dataset["y_test "]=y_test
with open("dataset.json","w") as f:
f.write(json.dumps(dataset))接下来就可以搭建模型了。
首先是决策树模型,如下:
model=DecisionTreeClassifier()之后是lightGBM模型,如下:
model_lgb = lgb.LGBMClassifier(boosting_type='gbdt',
objective='multiclass',
num_class=39,
max_delta_step=0.9,
min_data_in_leaf=21,
learning_rate=0.4,
max_bin=465,
num_leaves=41)之后是GBDT模型,如下:
model=GradientBoostingClassifier(n_estimators=100)然后是Adaboost模型,如下:
model=AdaBoostClassifier(n_estimators=100)还有随机森林模型,如下:
RandomForestClassifier(n_estimators=100)最后是SVM模型,如下:
model=SVC()考虑到时间问题,这里仅以决策树模型为例看下具体的结果:
【混淆矩阵】

详情结果如下:
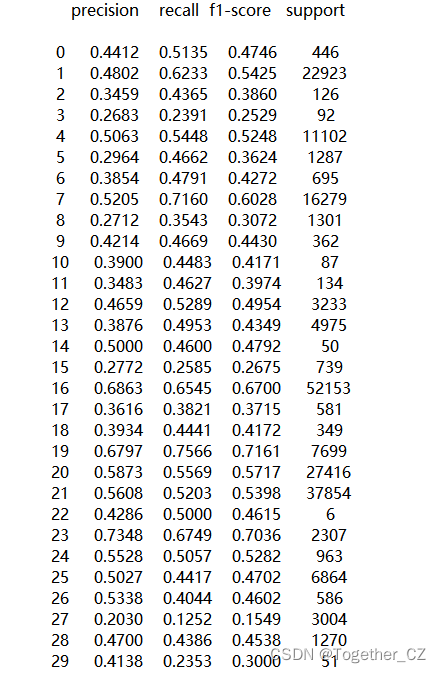
因为数据量非常大,模型的训练时间很久,我只好关掉了,这里决策树是比较轻量的模型了,所以仅以这个模型结果为例进行展示说明了,感兴趣的话可以自行尝试其他的模型。
当然了也可以自己做采样去缩减数据量都是可以的。