并发编程常见问题复盘
大家好,我是易安!
并发编程在计算机科学领域占有举足轻重的地位,它使得程序能够在多个处理器核心上同时执行,从而显著提升程序的性能。然而,并发编程也伴随着许多挑战和问题。这些年来,我们的CPU、内存、I/O设备在技术上不断迭代,朝着更高速度的方向发展。尽管如此,在这个快速演进的过程中,三者之间的速度差异一直是一个核心矛盾。
可以形象地将CPU和内存的速度差异比喻为:“CPU是天上一天,内存是地上一年”。换句话说,假设CPU执行一条普通指令需要一天,那么在CPU读写内存时,需要等待相当于一年的时间。而内存和I/O设备之间的速度差异更为明显,类似于“内存是天上一天,I/O设备是地上十年”。
由于程序中的大部分语句都需要访问内存,且部分语句还需访问I/O设备,根据木桶原理(一只水桶能装多少水取决于它最短的那块木板),程序整体性能受制于最慢的操作——读写I/O设备。这意味着仅提高CPU性能是无法显著改善程序性能的。
为解决这个核心矛盾,研究人员和工程师们采用多种并发编程技术和策略,如多线程、异步I/O、消息传递和任务并行等。通过这些技术,程序可以在等待I/O操作时执行其他任务,以提高资源利用率和性能。此外,现代操作系统也采用了诸如页缓存、预读取等策略,以缓解内存与I/O设备之间的速度差异。同时,硬件制造商也在探索更高效的内存和I/O技术,如高速缓存、固态硬盘等,以减小这些速度差异带来的性能影响。总之,通过多方面的努力,我们可以在一定程度上克服这些挑战,实现更高性能的并发程序。
当然,为了合理利用CPU的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都进行了不断迭代,主要体现为:
-
CPU增加了缓存,以均衡与内存的速度差异; -
操作系统增加了进程、线程,以分时复用CPU,进而均衡CPU与I/O设备的速度差异; -
编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
现在我们几乎所有的程序都默默地享受着这些成果,但是天下没有免费的午餐,并发程序很多诡异问题的原因也在这里。
那么,今天我们来聊一下并发编程重较为常见的几个问题。
问题一:缓存导致的可见性问题
在单核时代,所有线程都在一颗CPU上执行,CPU缓存与内存的数据一致性相对容易维护。这是因为所有线程都操作同一个CPU的缓存,一个线程对缓存的写操作对其他线程来说是可见的。如下图所示,线程A和线程B都操作同一个CPU里的缓存。当线程A更新变量V的值时,线程B随后访问变量V将获得V的最新值(即线程A更新过的值)。
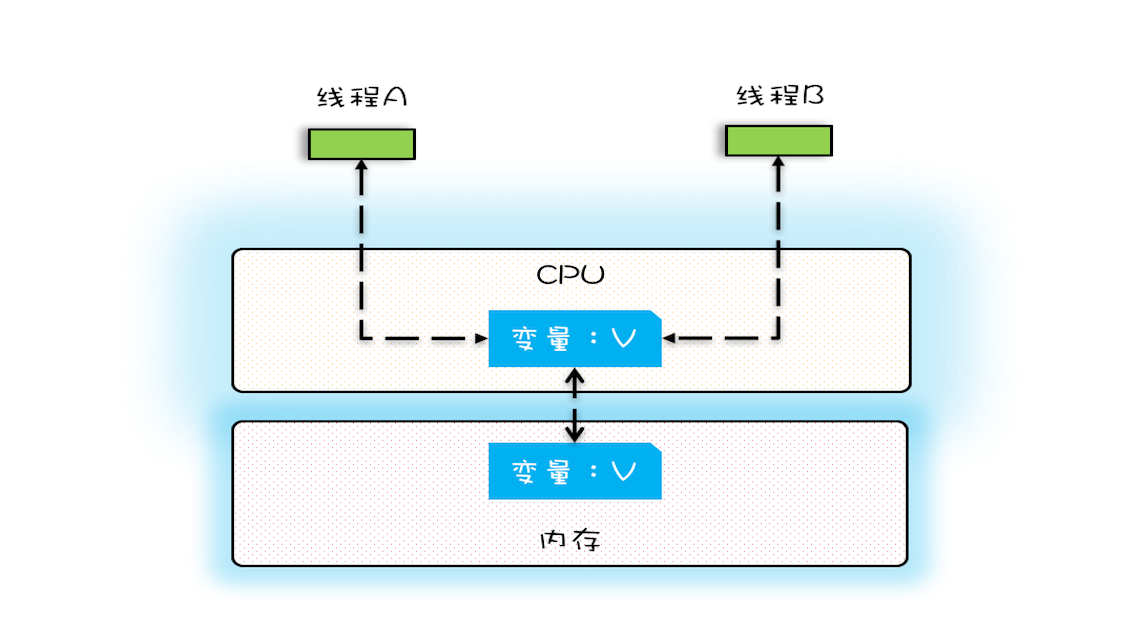
然而,随着多核处理器的普及,数据一致性问题变得更加复杂。多核处理器中的每个核心都有自己的缓存,不同线程可能在不同核心上执行。因此,多核环境下,一个线程对某个核心缓存的写操作可能对在其他核心上运行的线程是不可见的。这可能导致不同线程访问的变量值不一致,从而引发潜在的并发问题。为解决多核环境下的数据一致性问题,研究人员和工程师们采用了多种同步和一致性机制。例如,内存屏障(memory barrier)和缓存一致性协议(如MESI协议)可以确保多核处理器中的各个核心缓存保持一致。此外,多线程编程模型和原语(如互斥锁、信号量等)也被广泛应用于保证线程间的数据一致性和同步。
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为 可见性。
多核时代,每颗CPU都有自己的缓存,这时CPU缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的CPU上执行时,这些线程操作的是不同的CPU缓存。比如下图中,线程A操作的是CPU-1上的缓存,而线程B操作的是CPU-2上的缓存,很明显,这个时候线程A对变量V的操作对于线程B而言就不具备可见性了。这个就属于硬件程序员给软件程序员挖的“坑”。
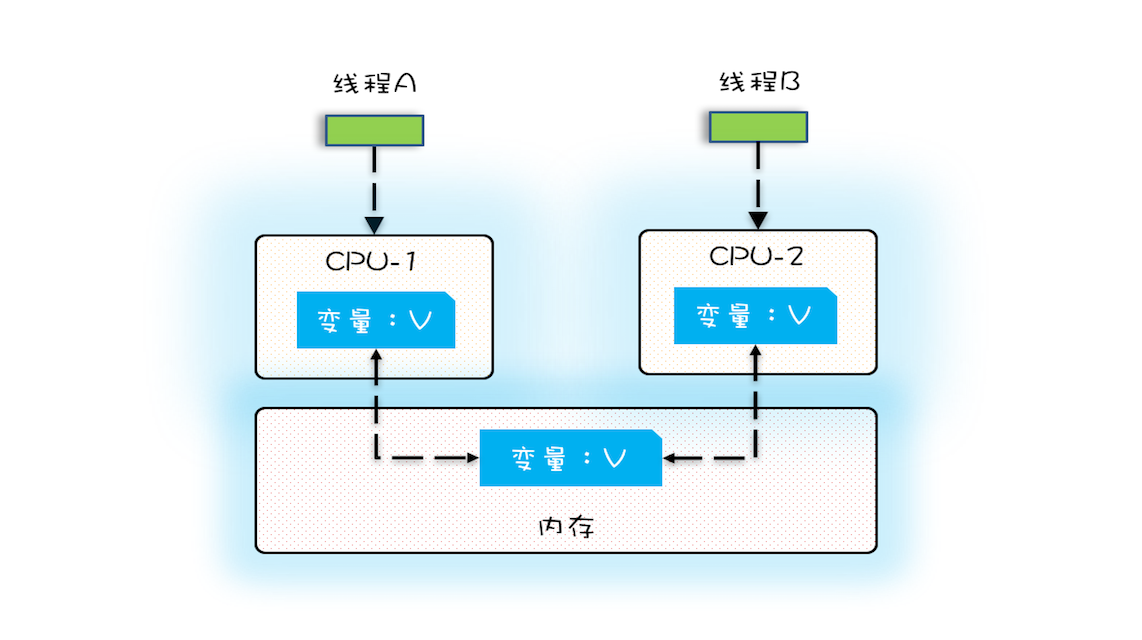
下面我们再用一段代码来验证一下多核场景下的可见性问题。下面的代码,每执行一次add10K()方法,都会循环10000次count+=1操作。在calc()方法中我们创建了两个线程,每个线程调用一次add10K()方法,我们来想一想执行calc()方法得到的结果应该是多少呢?
public class Test {
private long count = 0;
private void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
public static long calc() {
final Test test = new Test();
// 创建两个线程,执行add()操作
Thread th1 = new Thread(()->{
test.add10K();
});
Thread th2 = new Thread(()->{
test.add10K();
});
// 启动两个线程
th1.start();
th2.start();
// 等待两个线程执行结束
th1.join();
th2.join();
return count;
}
}
直觉告诉我们应该是20000,因为在单线程里调用两次add10K()方法,count的值就是20000,但实际上calc()的执行结果是个10000到20000之间的随机数。为什么呢?
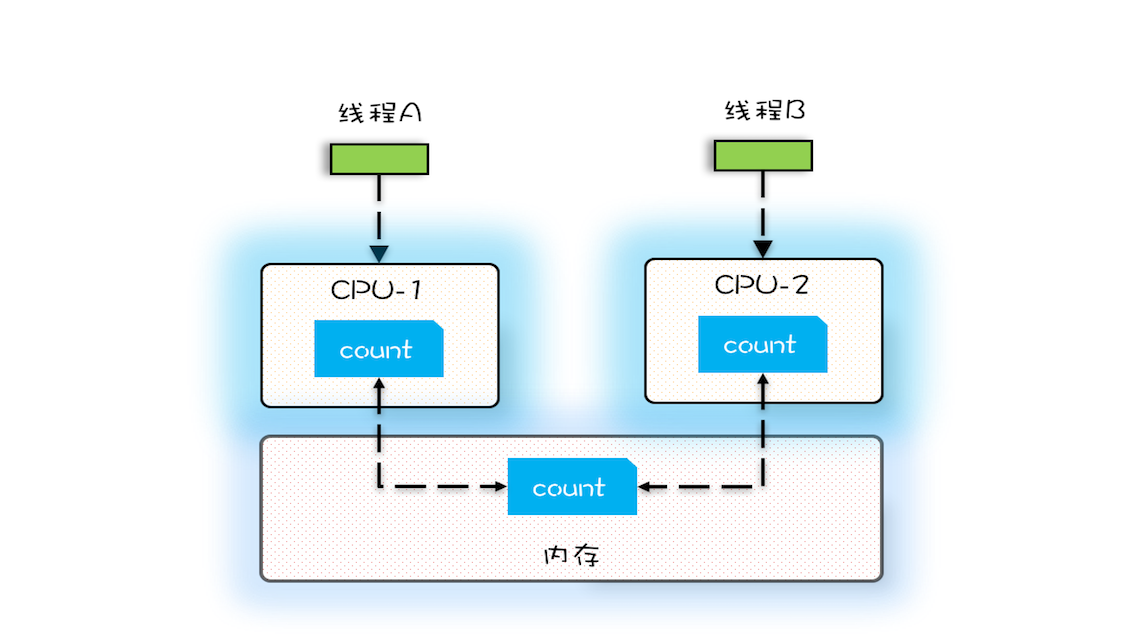
我们假设线程A和线程B同时开始执行,那么第一次都会将 count=0 读到各自的CPU缓存里,执行完 count+=1 之后,各自CPU缓存里的值都是1,同时写入内存后,我们会发现内存中是1,而不是我们期望的2。之后由于各自的CPU缓存里都有了count的值,两个线程都是基于CPU缓存里的 count 值来计算,所以导致最终count的值都是小于20000的。这就是缓存的可见性问题。
循环10000次count+=1操作如果改为循环1亿次,你会发现效果更明显,最终count的值接近1亿,而不是2亿。如果循环10000次,count的值接近20000,原因是两个线程不是同时启动的,有一个时差。
问题二:线程切换带来的原子性问题
由于IO太慢,早期的操作系统就发明了多进程,即便在单核的CPU上我们也可以一边听着歌,一边写Bug,这个就是多进程的功劳。
操作系统允许某个进程执行一小段时间,例如50毫秒,过了50毫秒操作系统就会重新选择一个进程来执行(我们称为“任务切换”),这个50毫秒称为“ 时间片”。
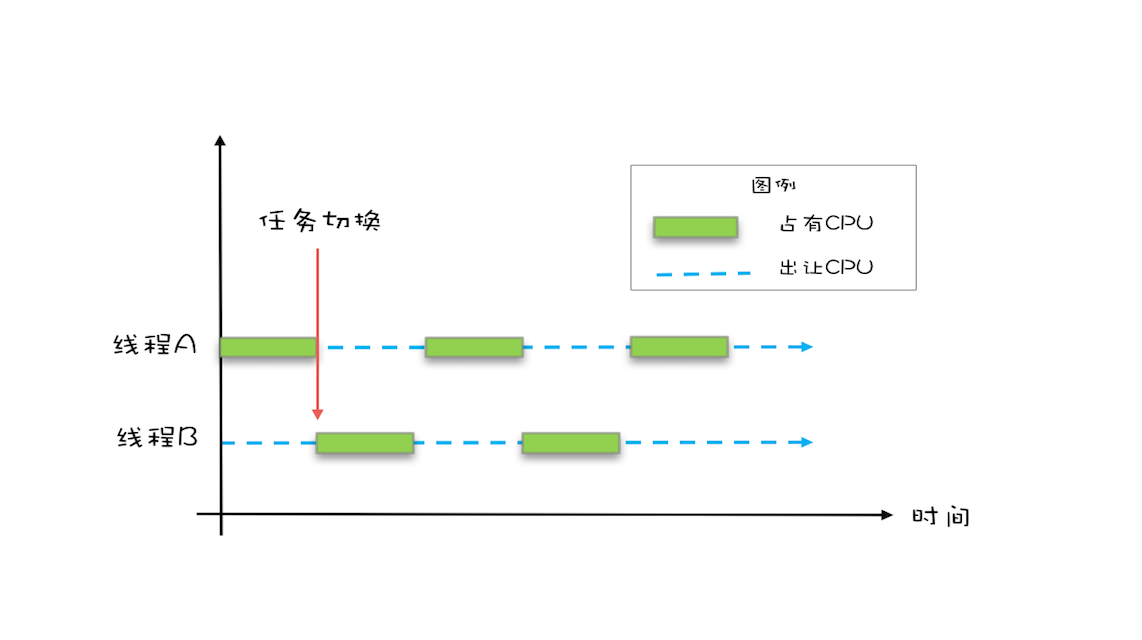
在一个时间片内,假设一个进程执行I/O操作,如读取文件。此时,该进程可以将自己标记为“休眠状态”,并主动释放CPU使用权。当文件读取完毕并加载到内存后,操作系统会唤醒处于休眠状态的进程,使其有机会重新获得CPU使用权。
进程在等待I/O操作完成期间释放CPU使用权的目的是充分利用CPU资源。这样,CPU可以在等待期间执行其他任务,从而提高使用率。此外,如果有其他进程同时进行I/O操作,这些操作将排队等待。磁盘驱动器在完成一个进程的读取操作后,会立即开始下一个排队的任务,从而提高I/O使用率。
尽管看似简单,但支持多进程分时复用在操作系统发展史上具有重要意义。例如,Unix操作系统因解决这一问题而广受赞誉。
早期操作系统依赖进程进行CPU调度。不同进程间不共享内存空间,因此进程切换时需切换内存映射地址。相反,一个进程创建的所有线程共享相同的内存空间,因此线程切换成本较低。现代操作系统主要基于更轻量级的线程进行调度。因此,当我们提到“任务切换”时,实际上是指“线程切换”。
线程之间共享内存空间的优点是提高了任务切换的效率,但同时也带来了潜在的竞争条件和数据不一致问题。为解决这些问题,研究人员开发了各种同步原语,如互斥锁、信号量等。这些同步原语可以确保线程间正确地访问共享数据,避免竞争条件的发生。
在现代操作系统中,线程作为轻量级调度单元,在提高系统性能和资源利用率方面发挥了重要作用。然而,线程调度和同步仍然面临挑战,需要程序员深入理解并发编程模型、同步机制和一致性策略,以编写出高性能且正确的多线程程序。
以Java并发来讲,程序都是基于多线程的,自然也会涉及到任务切换,也许你想不到,任务切换竟然也是并发编程里诡异Bug的源头之一。任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条CPU指令完成,例如上面代码中的 count += 1,至少需要三条CPU指令。
-
指令1:首先,需要把变量count从内存加载到CPU的寄存器; -
指令2:之后,在寄存器中执行+1操作; -
指令3:最后,将结果写入内存(缓存机制导致可能写入的是CPU缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条 CPU指令 执行完,是的,是CPU指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设count=0,如果线程A在指令1执行完后做线程切换,线程A和线程B按照下图的序列执行,那么我们会发现两个线程都执行了count+=1的操作,但是得到的结果不是我们期望的2,而是1。
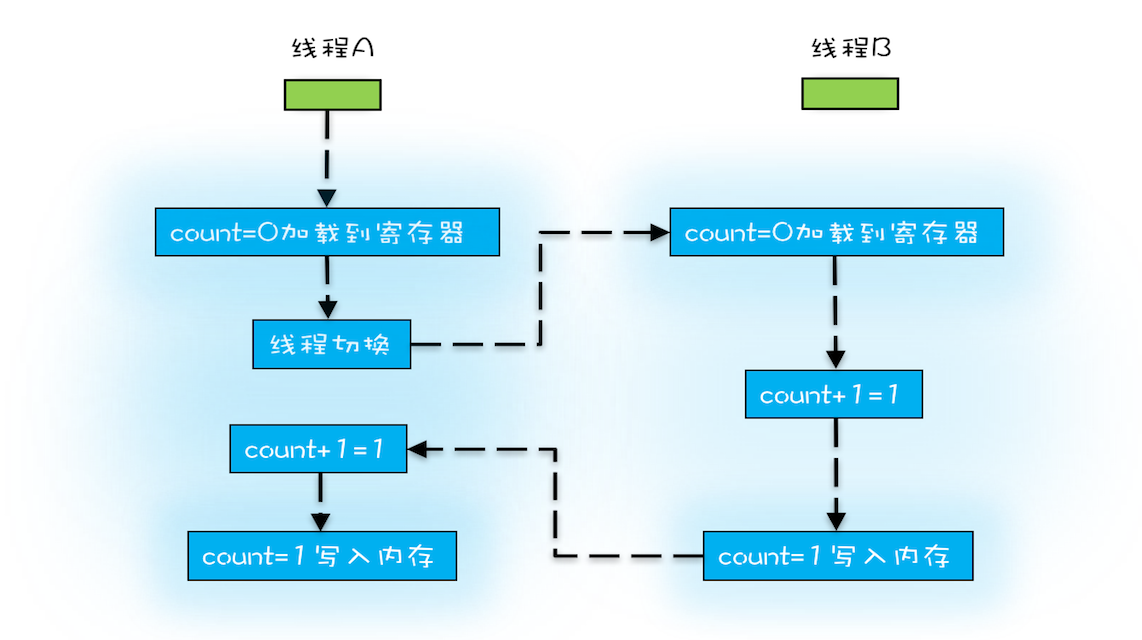
我们潜意识里面觉得count+=1这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在count+=1之前,也可以发生在count+=1之后,但就是不会发生在中间。 我们把一个或者多个操作在CPU执行的过程中不被中断的特性称为原子性。CPU能保证的原子操作是CPU指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
问题三:编译优化带来的有序性问题
在并发编程中,除了之前讨论的问题外,还有一个容易导致意外Bug的技术,即程序执行顺序。程序执行顺序通常按照代码的顺序进行,但为了优化性能,编译器可能会调整语句的执行顺序。例如,当程序包含“a=6;b=7;”,编译器优化后可能会调整为“b=7;a=6;”。尽管调整顺序在这种情况下不影响程序结果,但某些情况下编译器和解释器的优化可能导致预料之外的Bug。
Java编程领域中一个典型的案例便是通过双重检查锁(Double-Checked Locking)实现单例对象。在这个例子中,我们在获取实例的getInstance()方法中首先判断instance是否为空。若为空,则锁定Singleton.class并再次检查instance是否为空。如果仍为空,则创建一个Singleton实例。
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
然而,在多线程环境中,这种方法可能会出现问题。由于编译器优化和指令重排,instance = new Singleton();语句可能在对象初始化完成之前将对象引用分配给instance。因此,其他线程可能在对象完全初始化之前就获得了instance的引用,从而导致错误。
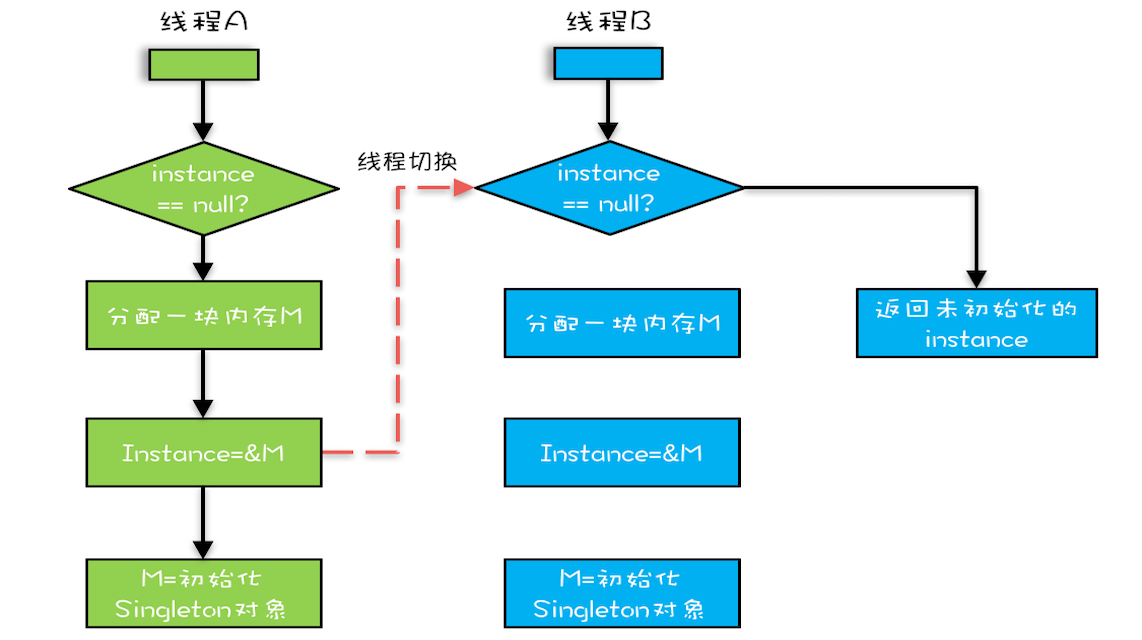
我举个例子假设有两个线程A、B同时调用getInstance()方法,他们会同时发现 instance == null ,于是同时对Singleton.class加锁,此时JVM保证只有一个线程能够加锁成功(假设是线程A),另外一个线程则会处于等待状态(假设是线程B);线程A会创建一个Singleton实例,之后释放锁,锁释放后,线程B被唤醒,线程B再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程B检查 instance == null 时会发现,已经创建过Singleton实例了,所以线程B不会再创建一个Singleton实例。
这看上去一切都很完美,无懈可击,但实际上这个getInstance()方法并不完美。问题出在哪里呢?出在new操作上,我们以为的new操作应该是:
-
分配一块内存M; -
在内存M上初始化Singleton对象; -
然后M的地址赋值给instance变量。
但是实际上优化后的执行路径却是这样的:
-
分配一块内存M; -
将M的地址赋值给instance变量; -
最后在内存M上初始化Singleton对象。
优化后会导致什么问题呢?我们假设线程A先执行getInstance()方法,当执行完指令2时恰好发生了线程切换,切换到了线程B上;如果此时线程B也执行getInstance()方法,那么线程B在执行第一个判断时会发现 instance != null ,所以直接返回instance,而此时的instance是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。
为了解决这个问题,Java提供了volatile关键字,volatile关键字在Java中用于确保共享变量在多线程环境中的可见性和禁止指令重排。那么volatile如何实现这两个目标的呢?有两个方面我详细描述下
-
可见性:
在多线程环境中,为了提高性能,每个线程可能会将共享变量缓存在其本地内存(例如CPU缓存)中。当一个线程修改了一个共享变量的值,其他线程可能无法立即看到这个变更,因为它们还在使用旧的缓存值。这就导致了可见性问题。
当将一个变量声明为volatile时,JVM会确保该变量在所有线程之间的可见性。这意味着当一个线程修改了volatile变量的值,修改会立即刷新到主内存,而其他线程在访问该变量时会从主内存读取最新值,而非从本地缓存。这样就保证了volatile变量在多线程环境中的可见性。
-
禁止指令重排:
指令重排是编译器和处理器为了提高程序执行效率而对原有代码顺序进行调整的过程。然而,在某些情况下,指令重排可能会导致预料之外的Bug,尤其是在并发编程中。
volatile关键字可以禁止对其修饰的变量进行指令重排。JVM会确保所有涉及volatile变量的操作严格按照代码的顺序执行。这样可以防止因指令重排导致的意想不到的问题。
在Java内存模型(JMM)中,volatile关键字为读/写操作提供了特殊的内存屏障(memory barrier)。当一个线程写入一个volatile变量时,会在写操作之后插入一个写内存屏障,确保写操作对其他线程立即可见。当一个线程读取一个volatile变量时,会在读操作之前插入一个读内存屏障,确保读取到的值是最新的。同时,这些内存屏障还会阻止编译器和处理器对涉及volatile变量的操作进行指令重排。
总结
为了编写出优秀的并发程序,我们首先需要明确并发程序可能存在的问题。只有明确了问题所在,我们才能有针对性地解决它们。实际上,并发程序中的奇怪问题看似离奇,但深入了解之后,很多问题都可以归结为我们的直觉被欺骗了。通过深入理解可见性、原子性和有序性在并发场景下的原理,我们可以更好地理解、诊断并解决许多并发Bug。
在介绍可见性、原子性和有序性时,我们特意强调了缓存导致的可见性问题、线程切换带来的原子性问题以及编译优化导致的有序性问题。实际上,缓存、线程和编译优化的目标与我们编写并发程序的目标一致,那就是提高程序性能。然而,技术在解决一个问题的同时,往往会带来另一个问题。因此,在采用某项技术时,我们必须清楚它可能带来的问题以及如何规避这些问题。
了解这些技术背后的原理并运用正确的方法来解决潜在的问题,将使我们能够更有效地编写并发程序。在实际应用中,我们需要密切关注每项技术所带来的潜在问题,并通过实践不断积累经验,以确保在提高程序性能的同时,也保证了程序的正确性和可靠性。
如果本文对你有帮助的话,欢迎点赞分享,这对我继续分享&创作优质文章非常重要。感谢 !
本文由 mdnice 多平台发布