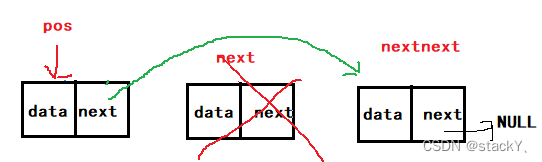
判断一个数是否是2的N次方?
N & (N-1) == 0 (N > 0)
算题:
- 力扣 https://leetcode.cn/
- POJ http://poj.org/
算法
算法概念
算法代表: 高效率和低存储 内存占用小、CPU占用小、运算速度快
算法的高效率与低存储:内存 + CPU
评价算法的两个指标
- 时间复杂度: 运行一个程序所花费的时间 O()
- 空间复杂度: 运行程序所需要的内存 OOM
时间复杂度 O(1,logn,n,nlogn,n^2,n^x)
- 常数:O(1) 1 表示是常数,所有能确定的数字我们都用O(1),O(10000)=>O(1)
- 对数: O(logn), O(nlogn)
- 线性: O(N) n一定是未知的; 如果n是已知的O(1)
- 线性对数: O(nlogn)
- 平方: O(n^2)
- N次方: O(n^n)
如何找时间复杂度
- 有循坏的地方
- 有网络请求的地方 (RPC、远程调用、分布式、数据库)
测试时间打印log
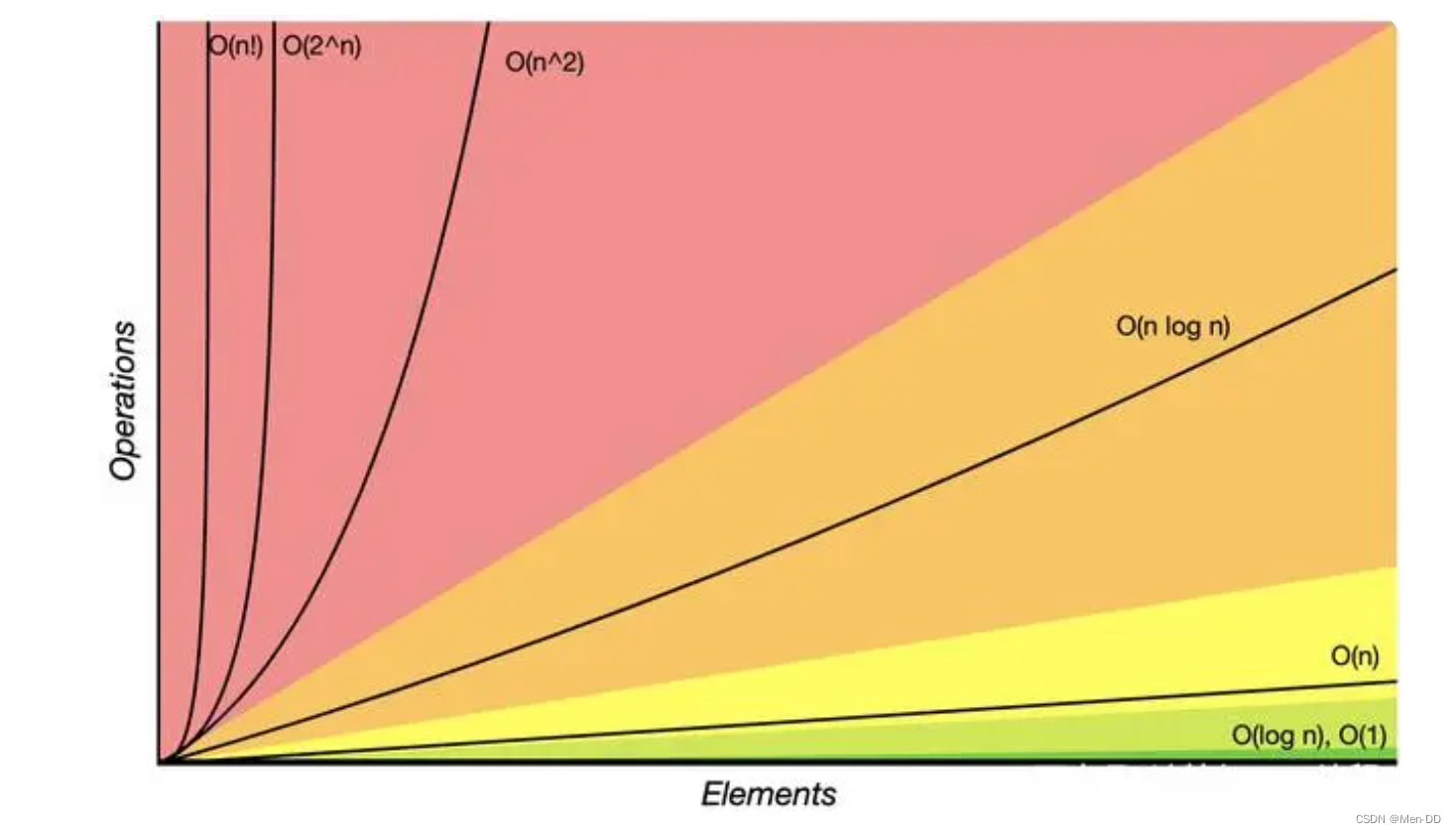
O(1) > O(logn) > O(n) > O(nlogn) > O(n^2) > O(n^n)
越接近O(1)时间复杂度越低
常数:O(1)
int a = 1; // 1次O(1)
for(int i = 0; i < 3; i++) { //这里运行4次
a = a + 1; //这里运行3次
}
对数: O(logn), O(nlogn)
//对数 2^x=n x就是我们运行的次数 => 对数 x=log2(n) = log2n = 计算机忽略常数 => logn => O(logn)
int n = Integer.MAX_VALUE;
int i = 1;
//O(logn)
while (i <= n) {
i = i * 2;
}
//O(nlogn)
for (int j = 0; j < n; j++) {
while (i <= n) {
i = i * 3;
}
}
线性: O(N)
//线性: O(N) n一定是未知的; 如果n是已知的O(1)
for (i = 0; i < n; i++) {
a = a + 1;
}
平方: O(n^2)
for (i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
a = a + 1; // O(n^2) n*(n+1)/2 => O(n^2) = 1+2+3+4+..+n=n*(n+1)/2
}
}
调优
列表排序 冒泡排序 < 快速排序 归并排序 堆排序
经典:链表、排序算法、二叉树、红黑树、B-Tree、B+Tree
进阶:数论、图论
数据结构
数组
面试题:
- 问题1:给你一个文件包含全国14亿人口年龄数据(0~180),让你统计每一个年龄有多少人?
限定机器单台2G + 2G内存,不得使用现成的容器,比如map等
int age[] = new int[180];
a[0]++; // 0表示0岁
利用数组下标,也可以利用下标随机定位到数组中的某一个数据
- 问题2:为什么数值的下标是从0开始的,数组的特点是一段连续的内存地址
int arr[] = new int[5];
申请到内存地址例如是:10001,10002,10003,10004,10005
保存数据:a[0] => 10001 ===> 10001 + 0
保存数据:a[1] => 10002 ===> 10001 + 1
保存数据:a[2] => 10003 ===> 10001 + 2
保存数据:a[3] => 10004 ===> 10001 + 3
保存数据:a[4] => 10005 ===> 10001 + 4
- 问题3:二维数组的内存地址是怎么样的?
1 2 3
4 5 6 => 1 2 3 4 5 6 => i*n + j (i是一维数组的长度、j是在列的位置) => 4 => 1*3 + 0 = 3
ArrayList 和 数组 如何选择
- ArrayList是JDK封装好的,不需要管扩容
- 数组删除添加慢O(n),修改获取快O(1)
- 随机访问
- 下标
如何选择?
- 如果不知道数据大小选择ArrayList
- 如果知道数据的大小而且又非常关注性能选择数组;需要注意越界(头和尾)
Java 内存分为堆内存和栈内存
堆内存:存放new对象和数组
栈内存:引用变量
堆和栈都是用来存数据的地方
堆栈区别:
- 栈的速度更快
- 栈的内存数据可以共享,主要存一些基本数据类型
int a = 3; 在栈中创建变量a, 然后给a赋值,先不会创建一个3而是先在栈中找有没有3
String s1 = "ja";
String s2 = "va";
String s3 = "java";
String s4 = s1 + s2; // java 里面重装了+, 其实调用了 stringBuild, 会new对象
System.out.println(s3 == s4); //false
System.out.println(s3.equals(s4)); //true
链表
链表面试题:
- 如何设计一个LRU缓存淘汰算法(链表)
- 约瑟夫问题(循环链表):N个人围成一圈,从第一个开始报数,第M个将被淘汰,最后剩下一个人,其余人都将被杀掉。例如N=6,M=5,被杀掉的顺序是5,4,6,2,3,1
链表特点
- 不需要连续的内存空间
- 有指针引用
- 常见链表结构:单链表、双链表、循环链表
单链表 LinkList
查询 O(n)
插入删除 O(1)
双链表
B+树 Mysql 叶子节点就是双向链表
跳表和Mysql B+树很像
循环链表
循环链表是一种特殊的单链表,他和单链表唯一区别是尾结点
单链表的尾结点是空地址
循环链表的尾结点是头节点
链表和数组对比
查询
数组
- O(1)
链表
- O(n)
插入/删除
数组插入
- 尾部O(1)
- 头部O(n)
链表插入
- 头部O(1)
- 尾部O(1)
- 中间O(1*2)
重要区别:
- 数组简单易用,在实现上使用的是连续的内存空间,可以借助CPU的缓存机制,预读数组中的数据,所以访问效率更高。
- 链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法有效预读。
- 数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,
导致“内存不足(out ofmemory)”。如果声明的数组过小,则可能出现不够用的情况。 - 动态扩容:数组需再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容。
栈—后进先出–LILO
面试题:
- 如何设计一个括号匹配的功能?栈
- 如何设计一个浏览器前进和后退功能?(两个栈一个前进、一个后退)
- 如何实现四则数字运算公式比如 3+2*5-3 ?(两个栈一个数字、一个符号)
- 代码函数调用顺序
栈特点
栈是一个限定仅在表尾插入和删除操作的线性表,被称为栈顶、另一端为栈底
向一个栈插入新元素称为进栈、入栈、压栈
删除元素称为出栈、退栈
栈其实是一种特殊的链表或数组,数组链表暴露太多接口,容易出错
public class KuoHaoStack {
public static boolean isOk(String s) {
MyStack<Character> brackets = new ArrayStack<>(20);
char c[] = s.toCharArray();
Character top = null;
for (char x : c) {
switch (x) {
case '{':
case '(':
case '[':
brackets.push(x);
break;
case '}':
top = brackets.pop();
if (top == null) return false;
if('{' == top) {
break;
} else {
return false;
}
case ')':
top = brackets.pop();
if (top == null) return false;
if('(' == top) {
break;
} else {
return false;
}
case ']':
top = brackets.pop();
if (top == null) return false;
if('[' == top) {
break;
} else {
return false;
}
default:
break;
}
}
return brackets.isEmpty();
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
System.out.println("S的输出结果:" + isOk(scanner.next()));
}
}
}
队列–先进先出–FIFO
问题
- 线程池里面当任务满时,此时又来一个新任务,线程池是如何处理的?具体有哪些策略?这些策略又是如何实现的呢?
- 排队:阻塞队列。有空闲的时候再拿,不就是那个take和put,如果是在公平的情况下,那肯定就是先进先出。这就是今天讲的队列。这时候我们就有两种方式,一个是无限的排队队列。(链表,千万别用。LinkedBlockingQueue,JDK的),还有一种就是有界(用数组来实现的),只处理我们开的空间大小,多了的继续抛出去。Integer.MAX=?2^32-1=21亿多,但是注意的是这个队列大小,别搞小了。就不够,大了就浪费。在一些小型系统,你知道数据请求量是不大的,可以用。
- 丢弃:不处理了,直接抛出去。
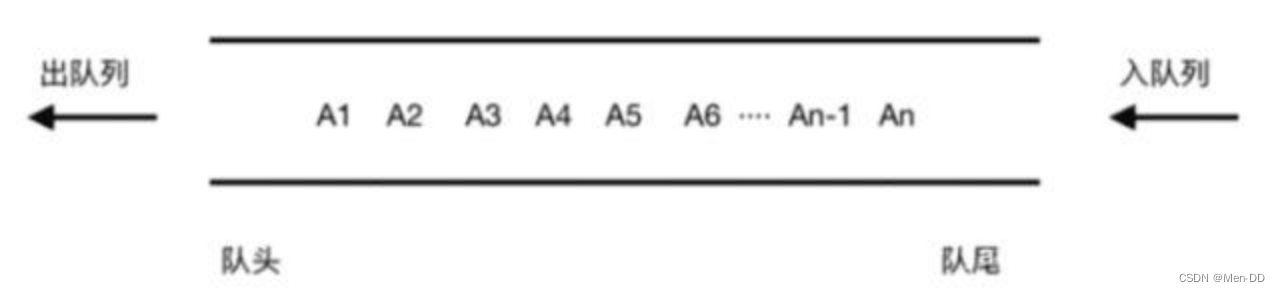
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端进行删除操作,在表的后端进行插入操作
队列分类
- 顺序(单向)队列:(Queue) 只能在一端插入数据,另一端删除数据
- 循环(双向)队列(Deque):每一端都可以进行插入数据和删除数据操作
判断是否已满
- 方式一:添加size
- 方式二:(tail+1)%n == head
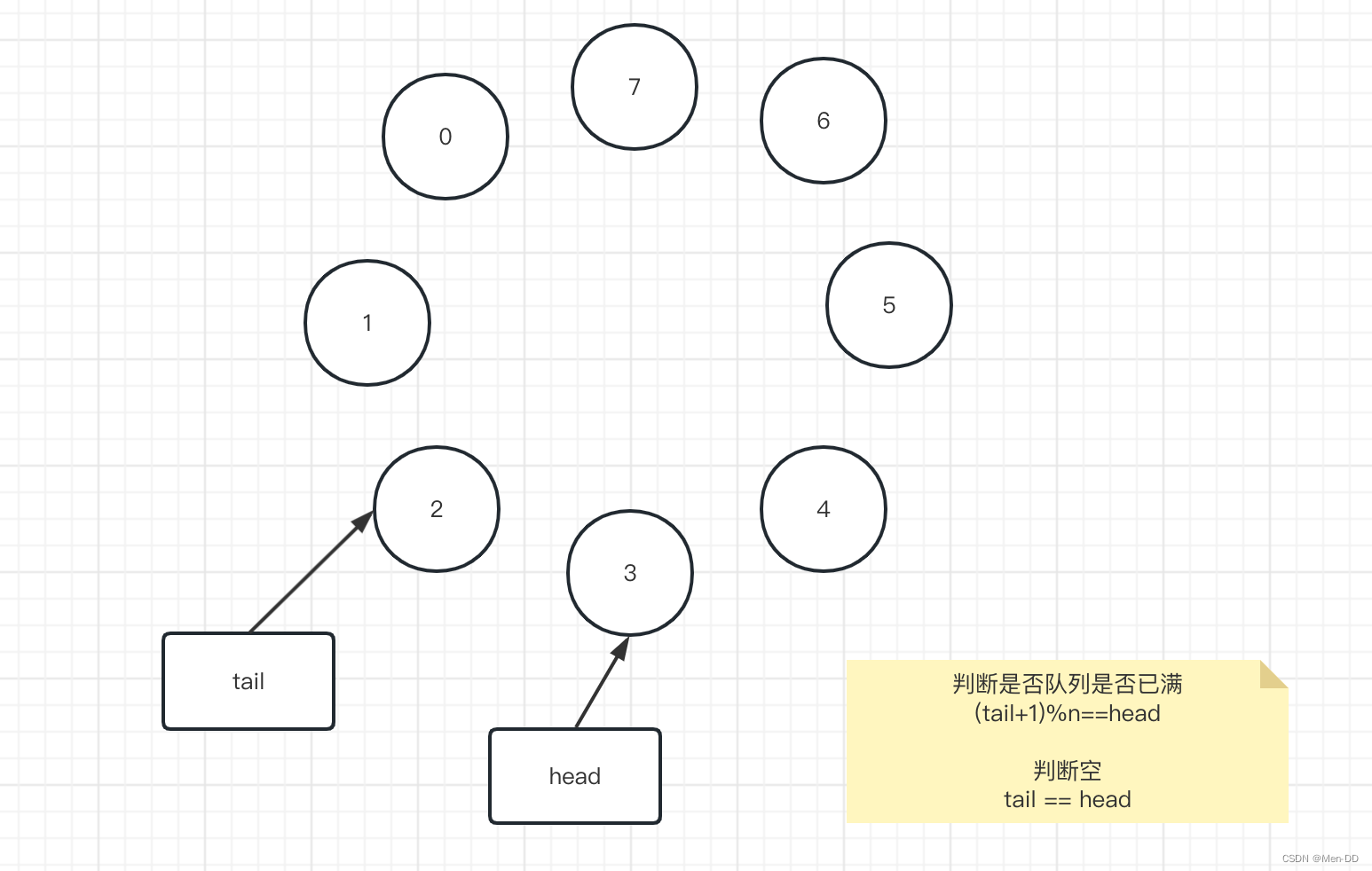
public class CircleArrayQueue<Item> {
private Item data[];
private int head = 0;
private int tail = 0;
private int n = 0; //数组最大空间
private int size; //当前队列已存个数
public CircleArrayQueue(int cap) {
data = (Item[]) new Object[cap];
n = cap;
}
public void push(Item item) {
if ((tail + 1)%n == head) return; //关键点
data[tail] = item;
tail = (tail + 1) % n; //关键点
}
public Item pop() {
if (isEmpty()) return null;
Item item = data[head];
head = (head + 1) % n;
return item;
}
public boolean isEmpty() {
return head == tail;
}
}