朋友们、伙计们,我们又见面了,本期来给大家解读一下数据结构方面有关链表的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C语言专栏:C语言:从入门到精通
数据结构专栏:数据结构
个人主页:stackY、
我们承接上篇数据结构:顺序表 中存在的问题:
1. 中间/头部的插入删除,时间复杂度为O(N)。
2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
要解决这些问题就需要用到链表了,那么在本期我们就来一起看一看数据结构中的链表。
链表可以解决:
1.不需要扩容
2.按照需要进行申请和是否内存
3.解决头部/中间插入、删除数据时需要挪动数据的问题。
目录
1.链表的概念及结构
2.链表的实现
2.1链表的创建
2.2结点的创建
2.3从头部插入数据
2.4链表的打印
2.5从尾部插入数据
2.6从尾部删除数据
2.7从头部删除数据
2.8在链表中查找数据
2.9修改链表中的数据
2.10在单链表中的pos之前插入数据
2.11在单链表中的pos之后插入数据
2.12在单链表中的pos之前删除数据
2.13在单链表中的pos之后删除数据
3.完整代码
1.链表的概念及结构
概念:
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的 。
类似于火车:逻辑结构:
物理结构:
前一个节点的next存放的是下一个结点的地址。
注意:
1.链表在逻辑上是连续的,但是在物理上不一定连续。
2.链表中的结点都是动态开辟出来的,按需申请,按需释放。
3.从堆上申请的节点是按照一定的策略来分配的,所以两次申请的空间有可能一样,也有可能不一样。



链表有单向、双向、带哨兵位,不带哨兵位、循环和非循环 这几种,那么组合起来一共有8中链表结构,往往我们最常使用的就是无头单向非循环链表和带头双向循环链表,那么本篇我们来看看无头单向非循环链表。
2.链表的实现
在链表中有两部分:
1.存放数据。
2.指向下一个结点。
3.最后一个结点是指向NULL指针。
在链表中要注意的几个点:
1.在插入和删除时是要传址调用还是传值调用。
2.链表需不需要初始化?
3.删除数据时链表为空怎么处理。
2.1链表的创建
链表的实现还是和顺序表的实现一样分模块来写, 当然也是可以在一个源文件中完成的,我们这里创建两个源文件:Test.c和SList.c,再创建一个头文件:SList.h,这里的文件命名不做要求,表示的有意义就行。同样的我们在Test.c中实现基本逻辑,在SLits.c中实现顺序表的细节,在SList.h中进行函数声明和头文件包含等,话不多说,我们直接开始:
头文件:SList.h
#pragma once typedef int SLTDataType; typedef struct SLTNode { SLTDataType data; //存放的数据 struct SLTNode* next; //指向下一个结点 }SLTNode;在进阶C语言:自定义类型中我们有提到过结构体的自引用,如果不理解可以去看一看喔。
2.2结点的创建
在链表中我们是不需要进行初始化的,因为每一个结点都是按需申请,按需释放,如果需要就使用malloc开辟一个结点,不用了之后就直接free掉 。申请的结点中的data是存放的元素,还有一个是指向下一个结点的指针:
头文件:SList.h
//创建节点 SLTNode* BuySLTNode(SLTDataType x);源文件:SList.c
//创建节点 SLTNode* BuySLTNode(SLTDataType x) { SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); //动态开辟一块空间 if (newnode == NULL) { perror("malloc fail"); return NULL; } newnode->data = x; //存放的数据 newnode->next = NULL; //指向下一个结点的指针 return newnode; }
2.3从头部插入数据
在链表的头部插入数据时,并不需要对链表进行断言,因为这个链表中有没有结点都无所谓,所以呢可以直接进行从头部插入数据:
这里要注意,在进行传头部插入的时候我们需要通过函数来改变链表,所以要进行传址调用,因为链表本身就是一个结构体指针,所以我们要使用二级指针来接受,在进行头部插入数据时我们需要将要插入的结点的next指向单链表头部的结点,然后将链表头部的指针移向新插入的结点,将其连接在头部就完成了头插:
头文件:SList.h
//头插 void SLPushFront(SLTNode** pphead, SLTDataType x);源文件:SList.c
//头插 void SLPushFront(SLTNode** pphead, SLTDataType x) { assert(pphead); //防止传参错误导致空指针 SLTNode* newnode = BuySLTNode(x); //创建要插入的结点 newnode->next = *pphead; //改变新节点的下一个指向 *pphead = newnode; //改变头指针的指向 }源文件:Test.c
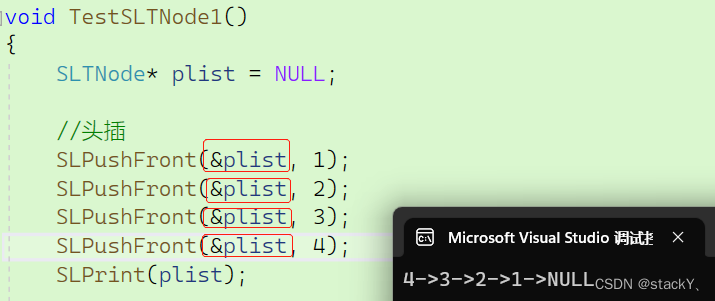
//数据结构: 单链表 #include "SList.h" void TestSLTNode1() { SLTNode* plist = NULL; //链表 SLPushFront(&plist, 1); //头插 SLPushFront(&plist, 2); SLPushFront(&plist, 3); SLPushFront(&plist, 4); } int main() { TestSLTNode1(); return 0; }

2.4链表的打印
要实现链表的打印,就得遍历一遍链表,在打印顺序表的时候我们是用顺序表中的有效元素个数来控制循环打印顺序表,在链表中我们可以发现最后一个结点的next是指向NULL,所以我们就可以以NULL为界限,每打印一个结点中的data,然后指向下一个结点,直到打印到NULL指针的位置。
头文件:SList.h
//打印链表 void SLPrint(SLTNode* phead);源文件:SList.c
//打印 void SLPrint(SLTNode* phead) { SLTNode* cur = phead; while (cur) //判断是否为NULL { printf("%d->", cur->data); cur = cur->next; //指向下一个结点 } printf("NULL\n"); }源文件:Test.c
//数据结构: 单链表 #include "SList.h" void TestSLTNode1() { SLTNode* plist = NULL; //头插 SLPushFront(&plist, 1); SLPushFront(&plist, 2); SLPushFront(&plist, 3); SLPushFront(&plist, 4); //打印 SLPrint(plist); } int main() { TestSLTNode1(); return 0; }
2.5从尾部插入数据
从尾部插入数据要先找到尾,怎么找到尾呢?是尾的那个结点的next是指向NULL的,所以可以根据结点next的指向来找到尾结点,要注意如果链表为空,那么就会造成对NULL指针的解引用,所以要分成两种情况,链表不为空,找尾结点的位置,然后将尾结点的next指向要插入的结点,如果链表为空,直接将头指针指向要插入的结点。
注意:
在进行尾插的时候如果链表里面原本就存在数据,那么在调用尾插函数的时候进行传值调用也可以进行插入,因为尾插是将链表中的尾节点中next的指向新节点,改变的是结构体的成员,需要使用结构体指针,但是如果链表为空,这时我们尾插需要改变的是整个结构体指针,所以需要使用结构体指针的地址,因此我们这里统一都来使用传址调用。
头文件:SList.h
//尾插 void SLPushBack(SLTNode** pphead, SLTDataType x);源文件:SList.c
//尾插 void SLPushBack(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = BuySLTNode(x); //创建结点 if (*pphead == NULL) //判断链表是否为空 { *pphead = newnode; //若为空直接进行插入 } else { SLTNode* tail = *pphead; //找尾结点 while (tail->next) { tail = tail->next; } tail->next = newnode; //改变尾结点的指向 } }
2.6从尾部删除数据
尾删数据也是通过传址调用的方式来进行删除,如果链表尾空,直接断言,如果只有一个结点,直接将这个结点进行释放,如果有多个结点就释放最后一个,尾删数据在这里有两种方法:
一、使用一个指针记录尾结点的上一个结点,然后将这个结点指向的空间释放。
二、直接通过上一个结点的next指向的结点的next来释放。
头文件:SList.h
//尾删 void SLPopBack(SLTNode** pphead);源文件:SList.c
方法一:
尾删 //方法一:记录尾节点的上一个节点 void SLPopBack(SLTNode** pphead) { //为空 assert(pphead); assert(*pphead); //只有一个节点 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* tail = *pphead; //尾结点 SLTNode* Prev = *pphead; //尾结点的上一个结点 while (tail->next) //找到尾结点的上一个结点 { Prev = tail; tail = tail->next; } free(Prev->next); //释放 Prev->next = NULL; } }方法二:
//方法二:直接通过next指向的next来释放 void SLPopBack(SLTNode** pphead) { //为空 assert(*pphead); assert(pphead); //只有一个节点 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* tail = *pphead; while (tail->next->next) { tail = tail->next; } free(tail->next); tail->next = NULL; } }两种方法都是可取的,想用哪种用哪种。
2.7从头部删除数据
从头部删除数据时也可以分为三种情况:链表为空,断言,链表只有一个结点,直接释放,链表有多个结点,释放掉第一个结点,那怎么释放第一个结点呢?需要将头结点存起来,然后将头节点指向下一个结点,然后将刚刚存起来的头结点释放掉。
头文件:SList.h
//头删 void SLPopFront(SLTNode** pphead);源文件:SList.c
//头删 void SLPopFront(SLTNode** pphead) { //为空 assert(*pphead); assert(pphead); //只有一个节点 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* Del = *pphead; //将第一个结点存起来 *pphead = (*pphead)->next; //改变第一个结点的指向,指向下一个结点 free(Del); Del = NULL; } }如果我们仔细观察可以发现只有一个结点和有多个结点做着同样的事情,所以我们可以将他们合并在一起。
优化代码:
//头删 void SLPopFront(SLTNode** pphead) { //为空 assert(*pphead); assert(pphead); //只有一个或多个结点 //优化 SLTNode* Del = *pphead; *pphead = (*pphead)->next; free(Del); Del = NULL; }
2.8在链表中查找数据
查找数据就比较简单了,遍历整个链表,找到了返回该节点的地址,没找到就返回NULL。
源文件:SList.h
//查找 SLTNode* SLFindNode(SLTNode* phead, SLTDataType x);源文件:SList.c
//查找 SLTNode* SLFindNode(SLTNode* phead, SLTDataType x) { SLTNode* cur = phead; while (cur) { if (cur->data == x) { return cur; } cur = cur->next; } return NULL; }
2.9修改链表中的数据
要修改链表中的数据,这时就要借助于查找函数了,因为查找函数返回的是一个地址,那么我们就可以通过这个地址来找到这块空间,然后对里面的值进行修改。
源文件:Test.c
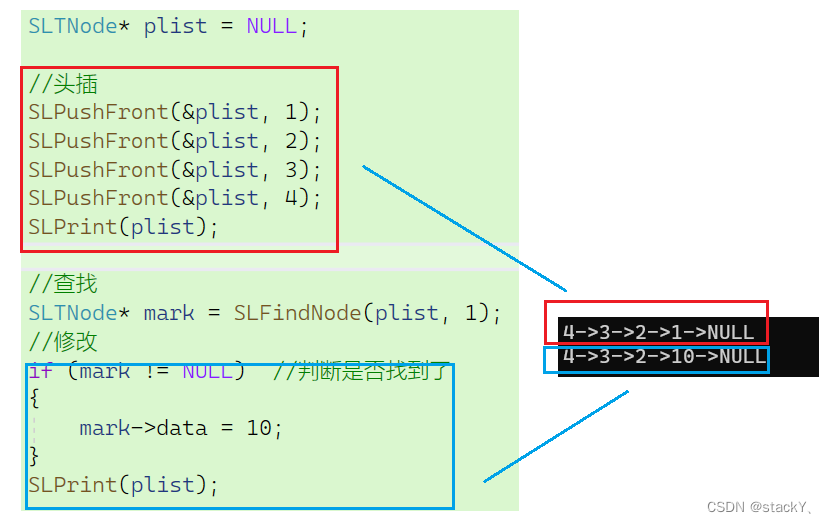
#include "SList.h" void TestSLTNode1() { SLTNode* plist = NULL; //头插 SLPushFront(&plist, 1); SLPushFront(&plist, 2); SLPushFront(&plist, 3); SLPushFront(&plist, 4); SLPrint(plist); //查找 SLTNode* mark = SLFindNode(plist, 1); //修改 if (mark != NULL) //判断是否找到了 { mark->data = 10; } SLPrint(plist); } int main() { TestSLTNode1(); return 0; }
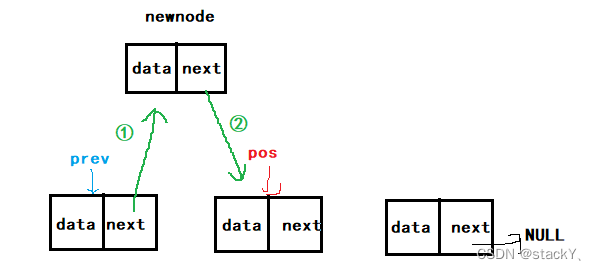
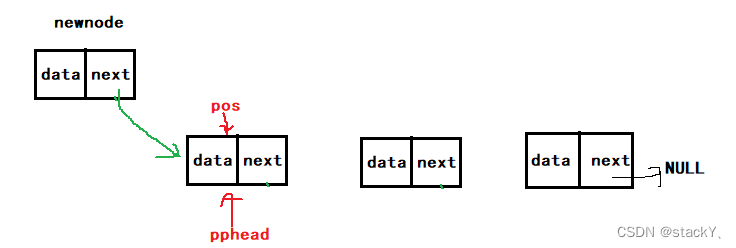
2.10在单链表中的pos之前插入数据
要在pos位置之前插入数据,首先得找到pos位置之前的那个结点,然后改变指向,但是这里有一个要注意的点,如果pos的位置刚刚实在头指针的位置,那还怎么找前一个位置呢?这里就不需要找了,如果pos等于头指针,这里的意思就表示头插入,再调用一下头插就行:
头文件:SLits.h
//单链表在pos之前插入数据 void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);源文件:SList.c
//单链表在pos之前插入数据 void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) { assert(pos); assert(pphead); SLTNode* prev = *pphead; //记录前一个结点 SLTNode* newnode = BuySLTNode(x); //创建结点 //如果pos就在头指针的位置,那么就是进行头插的过程 if (*pphead == pos) { SLPushFront(pphead, x); } else { while (prev->next != pos) //找到前一个结点 { prev = prev->next; } prev->next = newnode; //改变指向 newnode->next = pos; } }
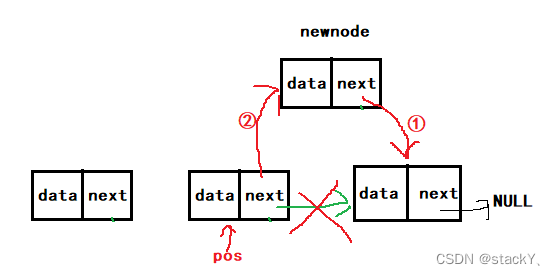
2.11在单链表中的pos之后插入数据
在pos的后面插入数据相对比较简单,直接改变结点的指向就可以,但是这里要注意先后问题,得先让新节点的next指向pos的下一个结点,然后再将pos的next指向新节点:
头文件:SList.h
// 单链表在pos位置之后插入x void SLInsertAfter(SLTNode* pos, SLTDataType x);源文件:SList.c
//在pos后面的位置插入数据 void SLInsertAfter(SLTNode* pos, SLTDataType x) { assert(pos); SLTNode* newnode = BuySLTNode(x); newnode->next = pos->next; pos->next = newnode; }
2.12在单链表中的pos之前删除数据
要删除pos之前的数据首先得找到pos之前的这个结点,然后将prev这个结点的next指向pos的next,然后将pos这个结点释放:
头文件:SList.h
// 单链表在pos位置之前删除 void SLErase(SLTNode** pphead, SLTNode* pos);源文件:SList.c
// 单链表在pos位置之前删除 void SLErase(SLTNode** pphead, SLTNode* pos) { assert(pos); assert(pphead); if (pos == *pphead) { SLPopFront(pphead); } else { SLTNode* prev = *pphead; //记录前一个结点 while (prev->next != pos) //找到前一个结点 { prev = prev->next; } prev->next = pos->next; free(pos); pos = NULL; } }
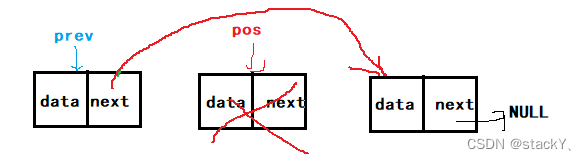
2.13在单链表中的pos之后删除数据
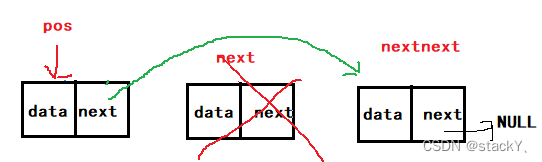
删除pos后面的位置,这里有一个简便的方法,记录pos下一个结点的位置,再记录pos的下下一个结点的位置,然后将pos的next指向pos的下下个结点的位置,再将pos的下一个位置的结点释放:
头文件:SList.h
// 单链表在pos位置之后删除 void SLEraseAfter(SLTNode* pos);源文件:SList.c
// 单链表在pos位置之后删除 void SLEraseAfter(SLTNode* pos) { assert(pos); if (pos->next) { SLTNode* next = pos->next; SLTNode* nextnext = next->next; pos->next = nextnext; free(next); next = NULL; } }
3.完整代码
头文件:SList.h
#pragma once
// 头文件的包含
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//链表的创建
typedef int SLTDataType;
typedef struct SLTNode
{
SLTDataType data;
struct SLTNode* next;
}SLTNode;
//函数的声明
//打印链表
void SLPrint(SLTNode* phead);
//创建节点
SLTNode* BuySLTNode(SLTDataType x);
//头插
void SLPushFront(SLTNode** pphead, SLTDataType x);
//尾插
void SLPushBack(SLTNode** pphead, SLTDataType x);
//尾删
void SLPopBack(SLTNode** pphead);
//头删
void SLPopFront(SLTNode** pphead);
//查找
SLTNode* SLFindNode(SLTNode* phead, SLTDataType x);
//单链表在pos之前插入数据
void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
// 单链表在pos位置之后插入x
void SLInsertAfter(SLTNode* pos, SLTDataType x);
// 单链表在pos位置之前删除
void SLErase(SLTNode** pphead, SLTNode* pos);
// 单链表在pos位置之后删除
void SLEraseAfter(SLTNode* pos);
源文件:SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "SList.h"
//打印
void SLPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur) //判断是否为NULL
{
printf("%d->", cur->data);
cur = cur->next; //指向下一个结点
}
printf("NULL\n");
}
//创建节点
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//头插
void SLPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead); //防止传参错误导致空指针
SLTNode* newnode = BuySLTNode(x); //创建要插入的结点
newnode->next = *pphead; //改变新节点的下一个指向
*pphead = newnode; //改变头指针的指向
}
//尾插
void SLPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySLTNode(x); //创建结点
if (*pphead == NULL) //判断链表是否为空
{
*pphead = newnode; //若为空直接进行插入
}
else
{
SLTNode* tail = *pphead; //找尾结点
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode; //改变尾结点的指向
}
}
//尾删
方法一:记录尾节点的上一个节点
//void SLPopBack(SLTNode** pphead)
//{
// //为空
// assert(pphead);
// assert(*pphead);
// //只有一个节点
// if ((*pphead)->next == NULL)
// {
// free(*pphead);
// *pphead = NULL;
// }
// else
// {
// SLTNode* tail = *pphead;
// SLTNode* Prev = *pphead;
// while (tail->next)
// {
// Prev = tail;
// tail = tail->next;
// }
// free(Prev->next);
// Prev->next = NULL;
// }
//}
//方法二:直接通过next指向的next来释放
void SLPopBack(SLTNode** pphead)
{
//为空
assert(*pphead);
assert(pphead);
//只有一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
//头删
void SLPopFront(SLTNode** pphead)
{
//为空
assert(*pphead);
assert(pphead);
只有一个节点
//if ((*pphead)->next == NULL)
//{
// free(*pphead);
// *pphead = NULL;
//}
//else
//{
// SLTNode* Del = *pphead;
// *pphead = (*pphead)->next;
// free(Del);
// Del = NULL;
//}
//优化
SLTNode* Del = *pphead;
*pphead = (*pphead)->next;
free(Del);
Del = NULL;
}
//查找
SLTNode* SLFindNode(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//单链表在pos之前插入数据
void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
assert(pphead);
SLTNode* prev = *pphead; //记录前一个结点
SLTNode* newnode = BuySLTNode(x); //创建结点
//如果pos就在头指针的位置,那么就是进行头插的过程
if (*pphead == pos)
{
SLPushFront(pphead, x);
}
else
{
while (prev->next != pos) //找到前一个结点
{
prev = prev->next;
}
prev->next = newnode; //改变指向
newnode->next = pos;
}
}
//在pos后面的位置插入数据
void SLInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
// 单链表在pos位置之前删除
void SLErase(SLTNode** pphead, SLTNode* pos)
{
assert(pos);
assert(pphead);
if (pos == *pphead)
{
SLPopFront(pphead);
}
else
{
SLTNode* prev = *pphead; //记录前一个结点
while (prev->next != pos) //找到前一个结点
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
// 单链表在pos位置之后删除
void SLEraseAfter(SLTNode* pos)
{
assert(pos);
if (pos->next)
{
SLTNode* next = pos->next;
SLTNode* nextnext = next->next;
pos->next = nextnext;
free(next);
next = NULL;
}
}
源文件:Test.c
#define _CRT_SECURE_NO_WARNINGS 1
//数据结构: 单链表
#include "SList.h"
void TestSLTNode1()
{
SLTNode* plist = NULL;
//头插
SLPushFront(&plist, 1);
SLPushFront(&plist, 2);
SLPrint(plist);
//尾插
SLPushBack(&plist, 0);
SLPushBack(&plist, -1);
SLPrint(plist);
//头删
SLPopFront(&plist);
SLPrint(plist);
//尾删
SLPopBack(&plist);
SLPrint(plist);
//查找
SLTNode* mark = SLFindNode(plist, 1);
//修改
if (mark != NULL) //判断是否找到了
{
mark->data = 10;
}
SLPrint(plist);
//在pos1之前插入数据
SLTNode* pos1 = SLFindNode(plist, 10);
if (pos1 != NULL)
{
SLInsert(&plist, pos1, 100);
}
SLPrint(plist);
//在pos2之后插入数据
SLTNode* pos2 = SLFindNode(plist, 10);
if (pos2 != NULL)
{
SLInsertAfter(pos2, 100);
}
SLPrint(plist);
//删除pos3之前的数据
SLTNode* pos3 = SLFindNode(plist, 10);
if (pos3 != NULL)
{
SLErase(&plist, pos3);
}
SLPrint(plist);
//删除pos4之后的数据
SLTNode* pos4 = SLFindNode(plist, 10);
if (pos4 != NULL)
{
SLEraseAfter(pos4);
}
SLPrint(plist);
}
int main()
{
TestSLTNode1();
return 0;
}
朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,欲知后事如何,请听下回分解~,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!