第三章(3):深入理解Spacy库基本使用方法
本章主要介绍了Spacy库的基本使用方法,包括安装、加载语言模型、分句、分词、词性标注、停用词识别、命名实体识别、依存分析和词性还原等内容。重点介绍了每个步骤的具体实现方式和应用场景,并给出了相关代码示例,(ง •_•)ง。
如果感觉有用,
不妨给博主来个一键三连,白天科研,深夜肝文,实属不易~ ~拜托了!

目录
- 第三章(3):深入理解Spacy库基本使用方法
- 前言
- 1. Spacy简介
- 1.1 背景
- 1.2 优势
- 1.3 应用领域
- 2 基本使用方法
- 2.1 安装
- 2.1.1 安装Spacy库
- 2.1.2 加载语言模型
- 2.2 分句
- 2.3 分词 (Tokenization)
- 2.4 词性标注
- 2.5 识别停用词
- 2.6 命名实体识别
- 2.7 依存分析
- 2.7.1 依存分析语义表达
- 2.7.2 依存关系可视化
- 2.8 词性还原
- 4. 总结
前言
Spacy是一个Python自然语言处理库,它被广泛应用于文本分类、命名实体识别、信息抽取、聊天机器人和垃圾邮件分类器等各种自然语言处理任务中。Spacy库以其高性能、易用性和可定制性而闻名,并已成为自然语言处理领域的领导者之一。本篇博客主要介绍Spacy库的基础使用方法,帮助读者了解Spacy的基本功能和使用方法。
1. Spacy简介
1.1 背景
Spacy是2014年由Matthew Honnibal创建的一个Python自然语言处理库。该库最初的目的是为了解决现有自然语言处理库的性能问题。目前,Spacy成为了业界受欢迎的自然语言处理库之一。

1.2 优势
- 高性能:Spacy是一个使用Cython编写的Python库,因此它的速度非常快。Spacy拥有多个组件,它们都是专门为高性能设计和优化的。
- 易用性:Spacy的API设计得非常简单明了,使得开发者可以轻松地使用Spacy进行自然语言处理。
- 可定制性:Spacy允许用户自定义模型,添加自己的语言模型和规则。这使得Spacy非常灵活。
1.3 应用领域
- 自然语言处理:Spacy是一种在自然语言处理领域中广泛使用的工具,能够自动完成例如分词、词性标注、依存解析、命名实体识别、情感分析、句法分析等各种基本的NLP任务。
- 实时文本分析:Spacy支持实时文本分析,并且可以快速地处理大量的文本数据。
- 语言学研究:Spacy还可以帮助语言学家解决语言学问题。
2 基本使用方法
2.1 安装
2.1.1 安装Spacy库
安装Spacy可以使用pip,在命令行中输入以下命令即可安装:
pip install -U spacy
2.1.2 加载语言模型
Spacy支持近50种不同的自然语言。要使用Spacy对特定语言进行处理,需要加载语言模型来指定其特征和属性。
Spacy提供了几个英文语言模型,其中最受欢迎的是en_core_web_sm模型。要加载该模型,请使用以下代码:
import spacy
nlp = spacy.load('en_core_web_sm')
不出意外的话,很多人会出现如下错误:
OSError: [E050] Can't find model 'en_core_web_sm'. It doesn't seem to be a Python package or a valid path to a data directory
解决方法,见文章:成功解决OSError: [E050] Can’t find model ‘en_core_web_sm’._安静到无声的博客-CSDN博客
2.2 分句
在SpaCy中,句子分割操作是由nlp对象的方法sentencizer完成的。默认情况下,nlp对象已经包含了sentencizer,因此我们只需要对文本使用nlp方法即可完成句子分割。下面是一个简单的示例:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence. This is another sentence.")
for sent in doc.sents:
print(sent.text)
实验结果:
This is a sentence.
This is another sentence.
可以看到,我们将两个句子作为一个字符串传递给nlp方法,然后迭代处理后的doc.sents属性,就可以得到两个独立的句子了。
tips:SpaCy的sentencizer不支持自定义句子分割规则。如果您需要使用特殊的分割规则,比如自己编写正则表达式进行分割,则需要使用其他库。
2.3 分词 (Tokenization)
在SpaCy中,分词是由nlp对象的核心组件中的tokenizer完成的。默认情况下,nlp对象已经包含了tokenizer,因此我们只需要对文本使用nlp方法即可完成分词。下面是一个简单的示例:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence.")
for token in doc:
print(token.text)
实验结果:
This
is
a
sentence
.
从输出结果中可以看到,我们将一个字符串传递给nlp方法,然后迭代处理后的doc属性,就可以得到文本的分词结果了。每个单词、标点符号等被表示为一个Token对象,其中Token.text属性表示该对象对应的文本内容。
tips:SpaCy的分词器并不是简单地根据空格或者标点符号来进行分割。相反地,SpaCy使用更复杂的规则进行分割,例如处理缩写、连接后缀以及形成词组等。这种方法可以提高分词的准确性,避免许多常见错误。
2.4 词性标注
在SpaCy中,词性标注是由nlp对象的核心组件中的tagger完成的。默认情况下,nlp对象已经包含了tagger,因此我们只需要对文本使用nlp方法即可完成词性标注。下面是一个简单的示例:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence.")
for token in doc:
print(token.text, token.pos_)
实验 结果:
This DET
is AUX
a DET
sentence NOUN
. PUNCT
从输出结果中可以看到,我们将一个字符串传递给nlp方法,然后迭代处理后的doc属性,就可以得到文本的词性标注结果了。每个单词都被表示为一个Token对象,其中Token.pos_属性表示该对象对应的词性。
tips:SpaCy的词性标注器是根据句法结构来进行标注的。具体来说,它使用上下文信息、词汇表以及一些规则来确定每个单词的词性。这种方法可以提高词性标注的准确性,避免许多常见错误。
2.5 识别停用词
SpaCy提供了一个默认的停用词列表,可以通过调用nlp.vocab属性来获取。我们可以使用is_stop方法检查一个特定的单词是否是停用词,例如:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I want to publish a lot of SCI papers.")
for token in doc:
if token.is_stop:
print(token.text)
实验结果:
I
to
a
of
tips:停用词列表可能因语言而异。在使用SpaCy进行非英文文本处理时,需要手动指定相应的停用词列表或自己构建停用词列表。
在某些情况下,我们需要添加或删除停用词以满足特定的文本处理任务需求。我们可以通过修改nlp.vocab属性中的词汇表来自定义停用词列表。例如,我们可以通过以下代码将“hello”添加到停用词列表中:
nlp.vocab["hello"].is_stop = True
修改后的停用词列表在当前会话中有效,并不会影响SpaCy的全局配置。如果需要使用自定义停用词列表,则需要在每次使用SpaCy时手动加载相应的配置。
2.6 命名实体识别
命名实体识别(Named Entity Recognition,简称NER)是自然语言处理中的一个重要任务,它的目标是从文本中识别出具有特定意义的单词或短语,并将它们分类为预定义的实体类别,例如人名、地名、组织机构名等。命名实体识别在许多NLP应用中都有着广泛的应用,例如信息抽取、问答系统、机器翻译等。
SpaCy提供了高效准确的命名实体识别功能。在SpaCy中,命名实体识别是由nlp对象的核心组件中的ner进行的。默认情况下,nlp对象已经包括了ner组件,因此只需要对文本使用nlp方法即可完成命名实体识别。示例如下:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.label_)
实验结果:
Apple ORG
U.K. GPE
$1 billion MONEY
从输出结果中可以看到,我们将一个字符串传递给nlp方法,然后迭代处理后的doc属性,就可以得到文本中的命名实体结果了。每个命名实体都被表示为一个Span对象,其中Span.label_属性表示该实体对应的类别(例如ORG代表组织机构名,GPE代表地域名,MONEY代表货币量)。
2.7 依存分析
依存分析(Dependency Parsing)是自然语言处理中的一项任务,其目的是解析句子中单词之间的依存关系。依存关系描述的是在一个句子中,每个单词与其他单词之间的语法关系,例如主谓关系、动宾关系等等。依存分析是NLP中许多任务的基础,例如实体识别、句法分析、语义角色标注等。
2.7.1 依存分析语义表达
SpaCy提供了快速和可靠的依存分析功能。在SpaCy中,依存分析是由nlp对象的核心组件中的parser进行的。默认情况下,nlp对象已经包括了parser组件,因此只需要对文本使用nlp方法即可完成依存分析。示例如下:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.dep_, token.head.text, token.head.pos_)
实验结果:
Apple nsubj looking VERB
is aux looking VERB
looking ROOT looking VERB
at prep looking VERB
buying pcomp at ADP
U.K. compound startup NOUN
startup dobj buying VERB
for prep buying VERB
$ quantmod billion NUM
1 compound billion NUM
billion pobj for ADP
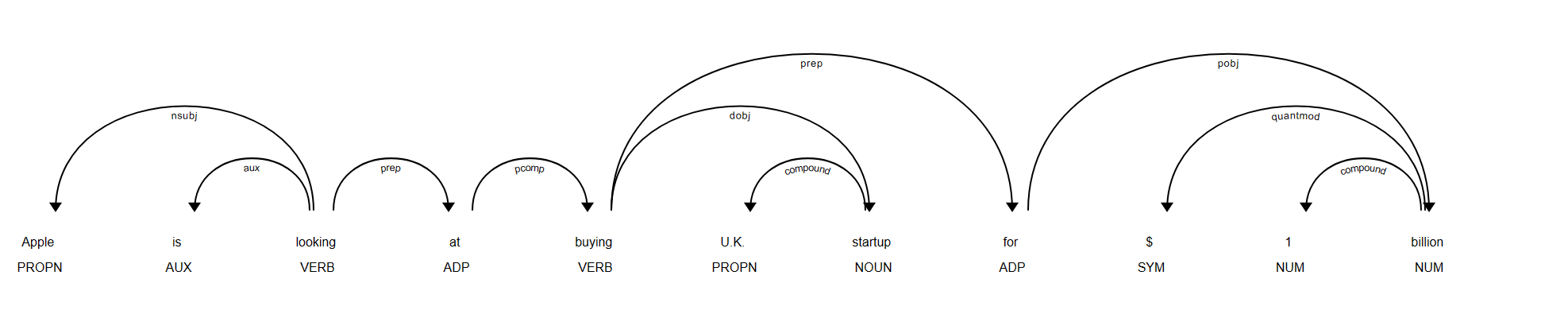
2.7.2 依存关系可视化
可以使用SpaCy的displacy模块来生成句子的依存关系可视化。示例如下:
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
svg = displacy.render(doc, style="dep", jupyter=False)
with open("./dependency_parse.svg", "w", encoding="utf-8") as f:
f.write(svg)
实验结果:
2.8 词性还原
SpaCy中的词性还原(Lemmatization)是将单词还原为它的基本形式(即词根或词干)的过程。相比于简单地去除单词的词缀,词性还原可以更准确地还原单词的原始含义,并帮助机器理解单词之间的关系。
SpaCy中的词性还原是通过使用词典和规则来实现的。具体来说,当SpaCy处理文本时,它会查找一个内置的词典,该词典包含了大量单词及其对应的基本形式。如果要还原的单词位于词典中,则SpaCy会直接返回它的基本形式;否则,它会根据一些规则来尝试将单词还原为基本形式。
例如,考虑句子"The dogs are barking outside."。在这个句子中,“dogs"和"barking"都是需要进行词性还原的单词。其中,“dogs"这个名词的基本形式就是"dog”,而"barking"这个动词的基本形式则是"bark”。SpaCy会通过查找词典和应用规则来得到这些基本形式。
使用SpaCy进行词性还原非常简单,只需要调用token.lemma_属性即可,示例如下:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("The dogs are barking outside.")
for token in doc:
print(token.text, token.lemma_)
实验结果:
The the
dogs dog
are be
barking bark
outside outside
. .
4. 总结
本章主要介绍了Spacy库的基本使用方法,包括安装、加载语言模型、分句、分词、词性标注、停用词识别、命名实体识别、依存分析和词性还原等内容。重点介绍了每个步骤的具体实现方式和应用场景,并给出了相关代码示例。
参考:
spacy简单使用-CSDN博客
成功解决OSError: [E050] Can’t find model ‘en_core_web_sm’._安静到无声的博客-CSDN博客