Java核心技术 卷1-总结-9
- 使用异常机制的技巧
- 为什么要使用泛型程序设计
- 定义简单泛型类
- 泛型方法
- 类型变量的限定
- 泛型类型的继承规则
使用异常机制的技巧
1.异常处理不能代替简单的测试。 使用异常的基本规则是:只在异常情况下使用异常机制。
2.不要过分地细化异常。
很多程序员习惯将每一条语句都分装在一个独立的try语句块中。
最好将整个任务包装在一个try 语句块中,这样,当任何一个操作出现问题时,整个任务都可以取消。
try {
for(i = 0; i < 100; i++) {
n = s.pop();
out.writeInt(n);
}
}
catch (IOException e) {
// problem writing to file
}
catch (EmptyStackException e) {
// stack was empty
}
3.利用异常层次结构。
不要只抛出RuntimeException异常。应该寻找更加适当的子类或创建自己的异常类。不要只捕获Thowable异常,否则,会使程序代码更难读、更难维护。
考虑受查异常与非受查异常的区别。已检查异常本来就很庞大,不要为逻辑错误抛出这些异常。
将一种异常转换成另一种更加适合的异常时不要犹豫。例如,在解析某个文件中的一个整数时,捕获NumberFormatException异常,然后将它转换成IOException或MySubsystemException的子类。
4.不要压制异常。
在Java中,往往强烈地倾向关闭异常。如果编写了一个调用另一个方法的方法,而这个方法有可能100年才抛出一个异常,那么,编译器会因为没有将这个异常列在throws表中产生抱怨。而没有将这个异常列在throws表中主要出于编译器将会对所有调用这个方法的方法进行异常处理的考虑。因此,应该将这个异常关闭:
public Image loadImage(String s) {
try {
// code that threatens to throw checked exceptions
}
catch (Exception e) {} // so there
}
现在,这段代码就可以通过编译了。除非发生异常,否则它将可以正常地运行。
5.在检测错误时,"苛刻"要比放任更好。
当检测到错误的时候,有些程序员担心抛出异常。在用无效的参数调用一个方法时,返回一个虚拟的数值,还是抛出一个异常,哪种处理方式更好?例如,当栈空时,Stack.pop是返回一个null,还是抛出一个异常?在出错的地方抛出一个EmptyStackException 异常要比在后面抛出一个NullPointerException异常更好。
6.不要羞于传递异常。
很多程序员都感觉应该捕获抛出的全部异常。如果调用了一个抛出异常的方法,例如,FilelnputStream构造器或readLine方法,这些方法就会本能地捕获这些可能产生的异常。其实,传递异常要比捕获这些异常更好:
public void readStuff(String filename)throws IOException { // not a sign of shame!
InputStream in = new FileInputStream(filename);
}
规则5、6可以归纳为“早抛出,晚捕获”。
为什么要使用泛型程序设计
泛型程序设计(Generic programming)意味着编写的代码可以被很多不同类型的对象所重用。例如,我们并不希望为聚集String和File对象分别设计不同的类。实际上,也不需要这样做,因为一个ArrayList类可以聚集任何类型的对象。这是一个泛型程序设计的实例。
定义简单泛型类
一个泛型类(generic class)就是具有一个或多个类型变量的类。以Pair类作为例子:
public class Pair<T> {
private T first;
private T second;
public Pair() { first=null; second=null; }
public Pair(T first,T second) { this.first = first; this.second = second; }
public T getFirst(){ return first; }
public T getSecond() { return second; }
public void setFirst(T newValue){ first m newValue; }
public void setSecond(T newValue){ second = newValue; }
}
Pair类引入了一个类型变量T,用尖括号<>括起来,并放在类名的后面。 泛型类可以有多个类型变量。例如,可以定义Pair类,其中第一个域和第二个域使用不同的类型:
public class Pair<T,U> {...}
类定义中的类型变量指定方法的返回类型以及域和局部变量的类型。 例如,
private T first;// uses the type variable
类型变量使用大写形式。在 Java库中,使用变量E表示集合的元素类型,K和V分别表示表的关键字与值的类型。T(需要时还可以用临近的字母U和S)表示“任意类型”。
用具体的类型替换类型变量就可以实例化泛型类型, 例如:
Pair<String>
可以将结果想象成带有构造器的普通类:
Pair<String>()
Pair<String>(String, String)
和方法:
String getFirst()
String getSecond()
void setFirst(String)
void setSecond(String)
换句话说,泛型类可看作普通类的工厂。
泛型方法
还可以定义带有类型参数的简单方法。
class ArrayAlg {
public static <T> T getMiddle(T... a) {
return a[a.length / 2];
}
}
这个泛型方法是在普通类中定义的,而不是在泛型类中定义的。注意,类型变量放在修饰符(这里是public static)的后面,返回类型的前面。
泛型方法可以定义在普通类中,也可以定义在泛型类中。当调用一个泛型方法时,在方法名前的尖括号中放入具体的类型:
String middle = ArrayAlg.<String>getMiddle("John","Q.", "Public");
类型变量的限定
有时,类或方法需要对类型变量加以约束。下面是一个典型的例子。我们要计算数组中的最小元素:
class ArrayAlg {
public static <T> T min(T[] a) { // almost correct
if (a == null || a.length == 0) {
return null;
}
T smallest = a[0];
for (int i = 1; i < a.length; i++) {
if(smallest.compareTo(a[i])>0) {
smallest = a[i];
}
}
return smallest;
}
}
但是,这里有一个问题。min方法的代码内部,变量smallest类型为T,这意味着它可以是任何一个类的对象。怎么才能确信T所属的类有compareTo方法呢?
解决这个问题的方案是将T限制为实现了Comparable接口(只含一个方法compareTo的标准接口)的类。可以通过对类型变量T设置限定(bound) 实现这一点:
public static <T extends Comparable> T min(T[] a)...
现在,泛型的min方法只能被实现了Comparable接口的类(如 String、LocalDate 等)的数组调用。
在此为什么使用关键字extends而不是implements?毕竟,Comparable是一个接口。
<T extends BoundingType>
表示T应该是绑定类型的子类型(subtype)。T和绑定类型可以是类,也可以是接口。 选择关键字 extends 的原因是更接近子类的概念。
一个类型变量或通配符可以有多个限定,例如:
T extends Comparable & Serializable
限定类型用“&”分隔,而逗号用来分隔类型变量。
在Java的继承中,可以根据需要拥有多个接口超类型,但限定中至多有一个类。如果用一个类作为限定,它必须是限定列表中的第一个。
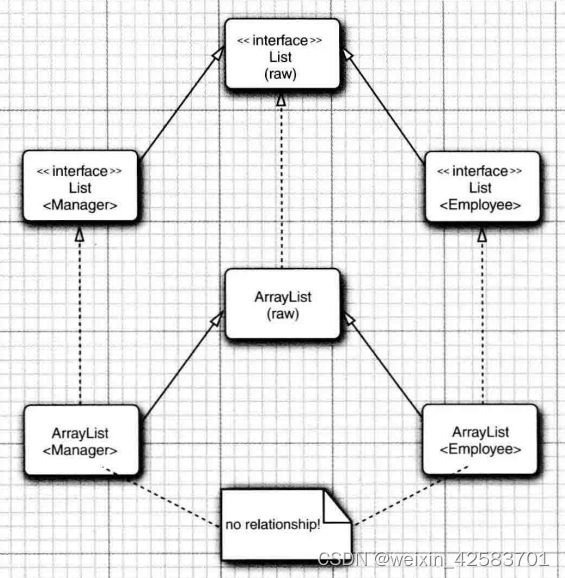
泛型类型的继承规则
考虑一个类和一个子类,如Employee和Manager。Pair不是Pair的一个子类,下面的代码将不能编译成功:
Manager[] topHonchos = . . .;
Pair<Employee> result = ArrayAlg.minmax(topHonchos);// Error
minmax 方法返回Pair,而不是Pair,并且这样的赋值是不合法的。无论S与T有什么联系。
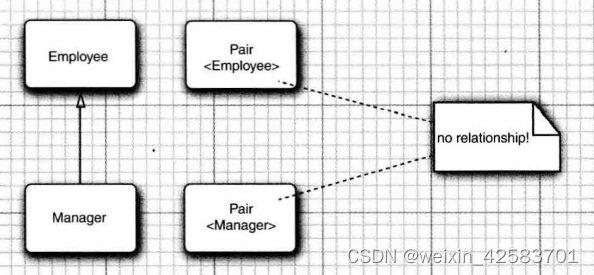
这一限制看起来过于严格,但对于类型安全非常必要。假设允许将Pair转换为Pair。考虑下面代码:
Pair<Manager> managerBuddies = new Pair<>(ceo, cfo);
Pair<Employee> employeeBuddies = managerBuddies; // illegal, but suppose it wasn't
employeeBuddies.setFirst(lowlyEmployee);
显然,最后一句是合法的。但是employeeBuddies和managerBuddies引用了同样的对象。现在将cfo和一个普通员工组成一对,这对于Pair<Manager>来说应该是不可能的。
注意∶必须注意泛型与Java数组之间的重要区别。可以将一个Manager[]数组赋给一个类型为Employee[]的变量:
Manager[] managerBuddies = { ceo, cfo };
Employee[] employeeBuddies = managerBuddies; // OK
然而,数组带有特别的保护。如果试图将一个低级别的雇员存储到employeeBuddies[0],虚拟机将会抛出ArrayStoreException异常。
永远可以将参数化类型转换为一个原始类型。例如,Pair是原始类型Pair的一个子类型。在与遗留代码衔接时,这个转换非常必要。
但转换成原始类型之后会产生类型错误。比如下面这个示例:
Pair<Manager> managerBuddies = new Pair<>(ceo, cfo);
Pair rawBuddies = managerBuddies;// OK
rawBuddies.setFirst(new File("...."));// only a compile-time warning
当使用getFirst获得外来对象并赋给Manager变量时,与通常一样,会抛出 ClassCastException异常。这里失去的只是泛型程序设计提供的附加安全性。
泛型类可以扩展或实现其他的泛型类。 就这一点而言,与普通的类没有什么区别。例如,ArrayList<T>类实现List<T>接口。这意味着,一个ArrayList<Manager>可以被转换为一个List<Manager>。但是,,一个 ArrayList<Manager>不是一个ArrayList<Employee>或List<Employee>。