Hadoop笔记
- nn和sn的区别
- nn有inprogress,sn没有,隔一段时间sn会拉取nn上的fsi和edits进行合并然后返回给nn
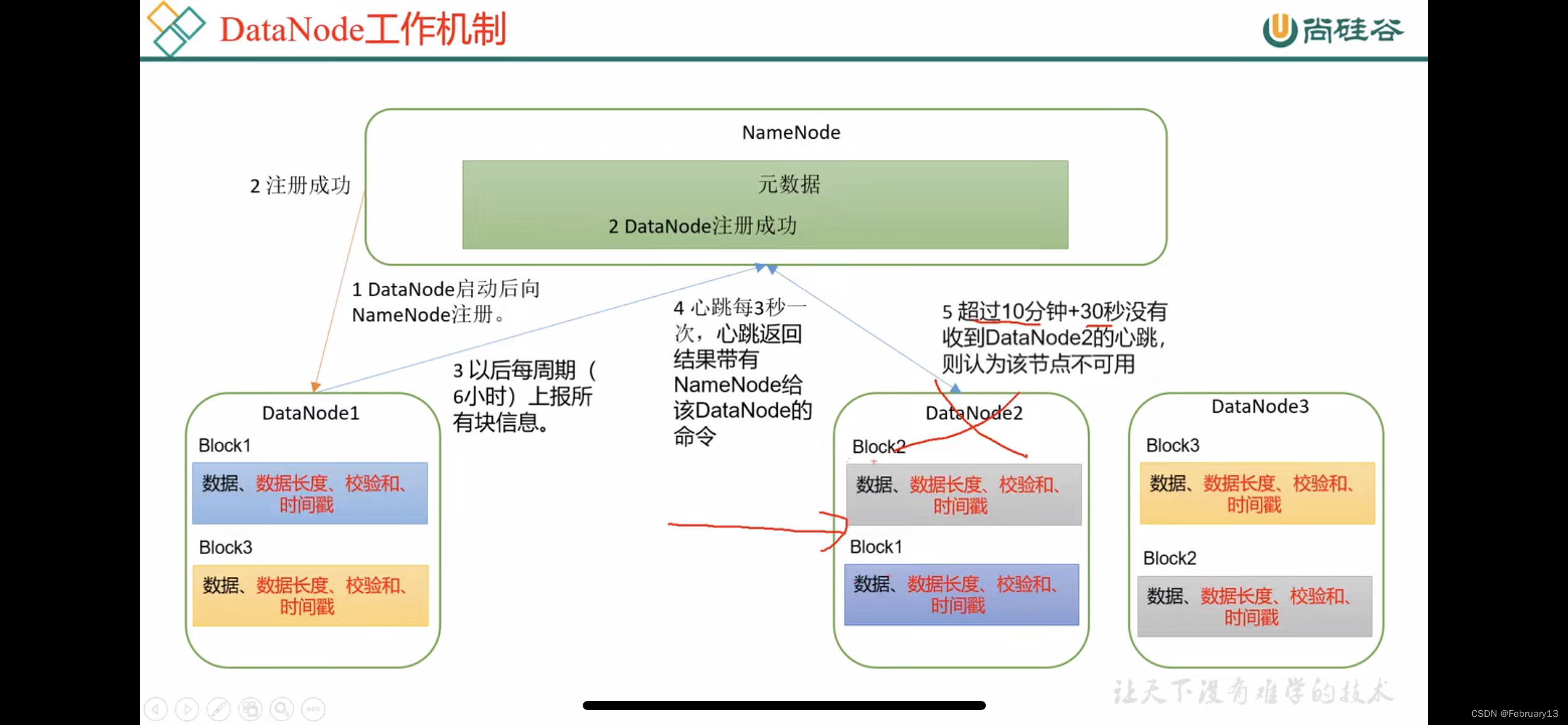
- nn和dn
- 序列化和反序列化
- 当需要将内存中对象从一个服务器传输到另一个服务器的时候,将内存中的对象写进磁盘(序列化)并传输到目标服务器磁盘后再写入内存(反序列化)的过程
- mr任务的代码步骤
- 新建job对象,传入conf
- job联系三个类:mapper,reducer,driver(套路化的设置,如导包,配参数,使用的集群等)
- 指定mapper类
- 指定reducer类
- driver
- 指定mapper阶段结构的输出类型
- 指定最终结果的输出类型
- 指定输入输出路径,输出路径不能存在结果文件
- 执行
- mapper阶段会遍历文件,用每一行的偏移量作为key,内容作为value传入,输出key为内容和,value为1的中间结果,然后根据reduce阶段给每个key分配的reduce节点上进行聚合操作计算所有结果再汇总所有节点的结果
- 序列化和反序列化一定要按队列来
- 并行度由maptask的切片数决定
- 切片大小与block块大小一致,效率最佳,避免跨节点执行任务
- 切片是按照单个文件来的,与数据集无关
- mr数据倾斜
- 空值过多,删除
- 自定义分区,在null后面拼接随机数打散二次聚合
- 增加reduce个数
- 提前combiner做聚合在map端,mapjoin
- 空值过多,删除
- 小文件
- archive,存储方向
- 切片用combinetextinputformat将多个小文件放在一起当作单个文件进行,计算方向
- jvm重用,uber模式,同一个job得多个task共用jvm,减少初始化和关闭的操作