1:在train中加载train和test数据集。

2:指定数据集为kitti,确定训练验证的batchsize。

3:提前定义好数据预处理,首先是几何变换,包括随机裁切等。
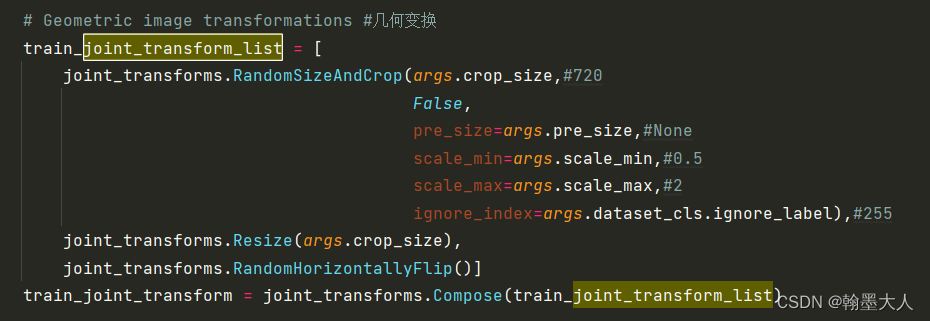
4:然后是外观变换,包括高斯滤波,调整颜色等。
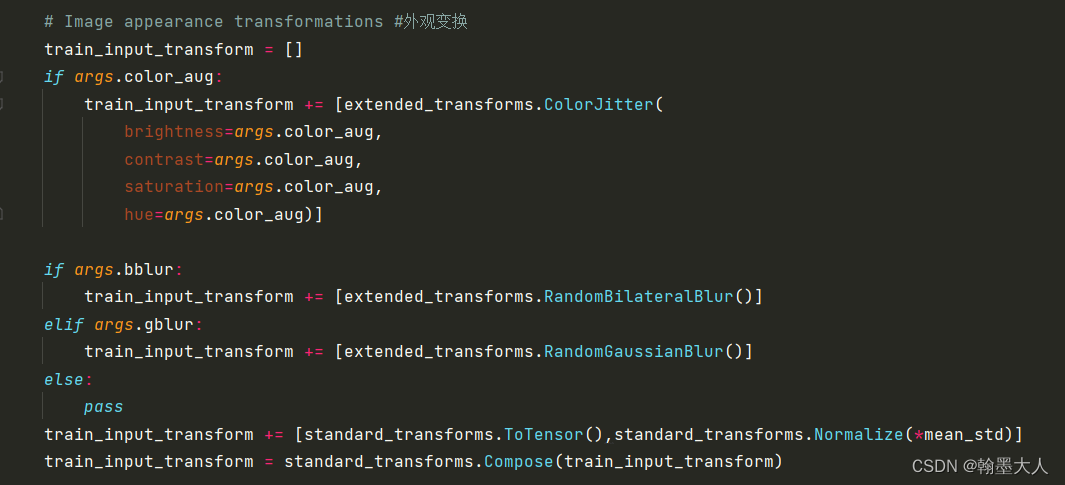
5:这些都是train的变化,接着是validation的变换。只有归一化和转换为tensor。

6:然后就是定义dataset,包括对图片进行处理。
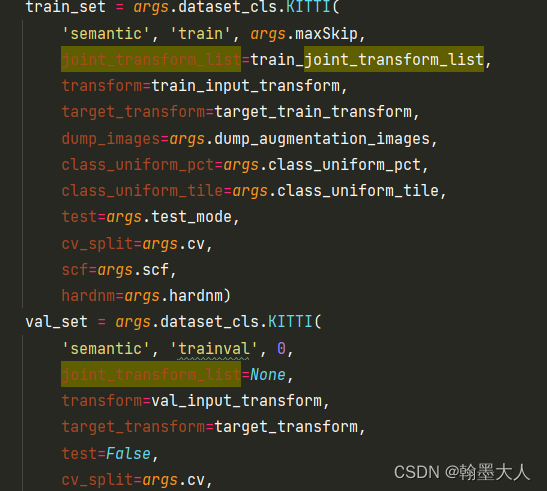
7:接着在KITTI数据集中,定义参数:
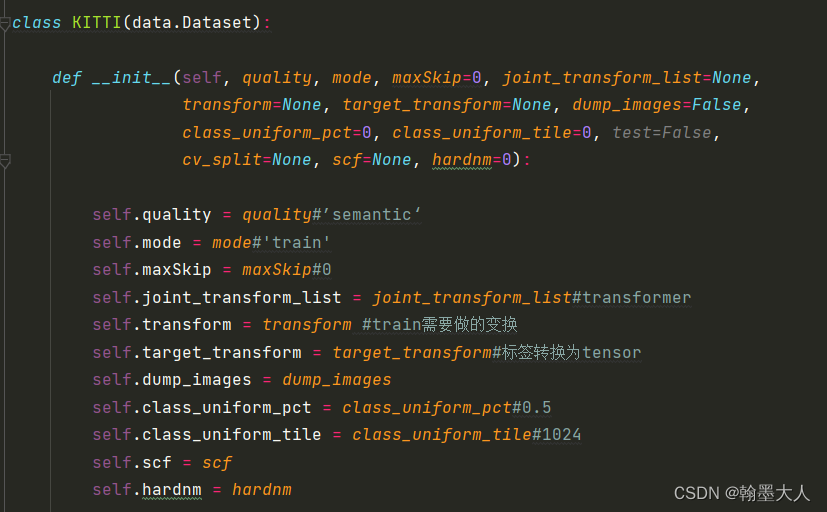
8:最重要的是划分数据集:首先看一下原始目录:

training:

testing:

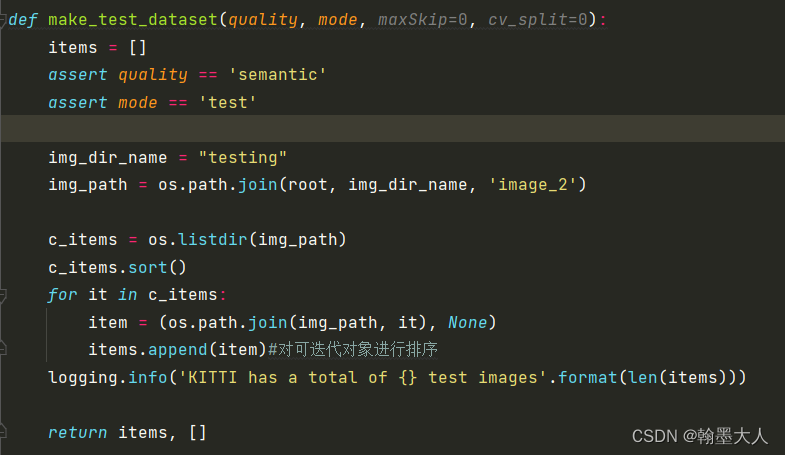
9:如果mode为test,quality为semantic,制作test数据集。

10:img位于KITTI下的testing下的image_2目录中。将testing文件夹下image的图片和None(testing没有标签)作为一个列表存储起来,并返回。
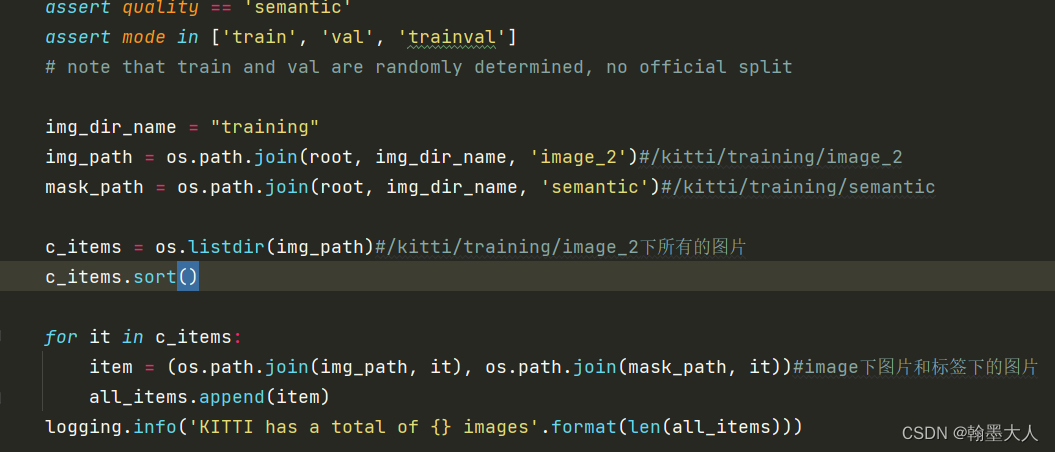
11:如果mode不为test,那么还可以为train,trainval。首先查看training目录下image2和semantic目录下的图片。通过一一遍历组合成一个(image,mask)组成的列表。接着将列表进行划分。
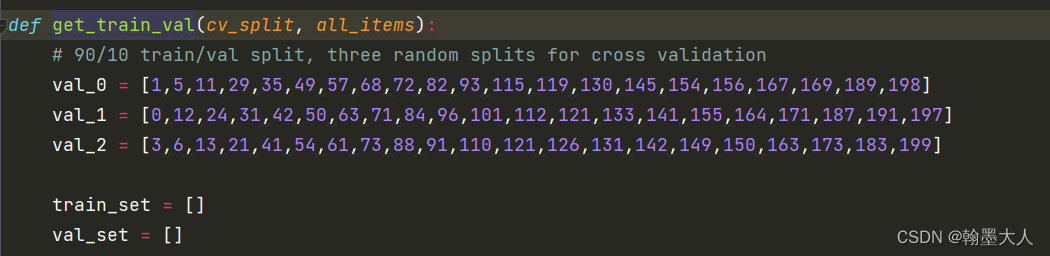
12:通过get_train_val进行划分。确定好按几折划分。
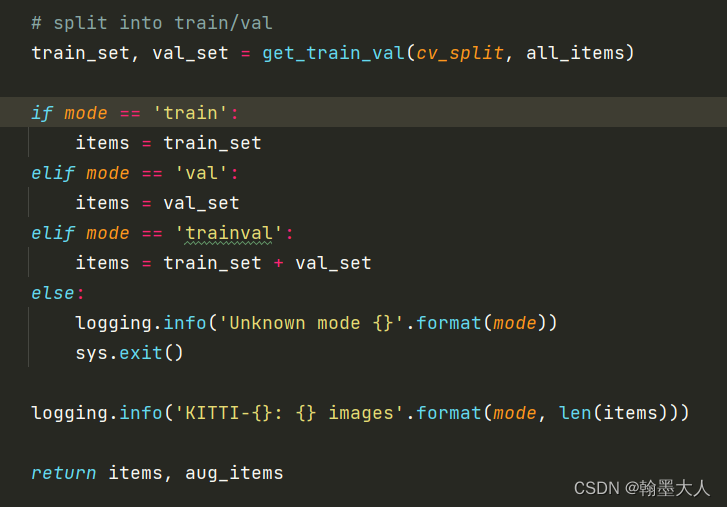
13:给出val所对应的图片,有20个,遍历循环,将位于val_0/1/2的图片添加到val_set中,其余的添加到train_set中并返回。
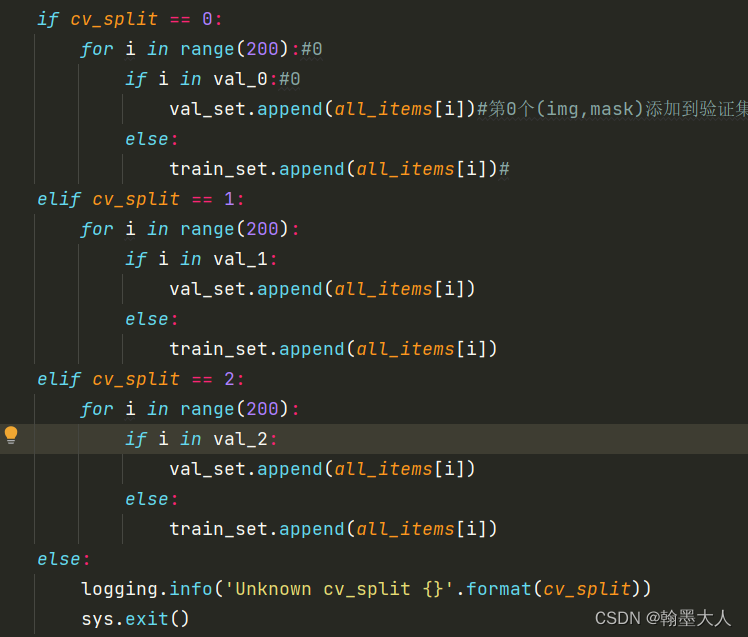
14:判断mode的模式,这里第一次看漏了,如果mode = train,则items=train_set=180张image和对应的180张mask。如果mode=val,则items=val_set=20张image和对应的20张mask。如果mode=trainval,则items=train_set + val_set=200张所有的image和对应的200张mask。
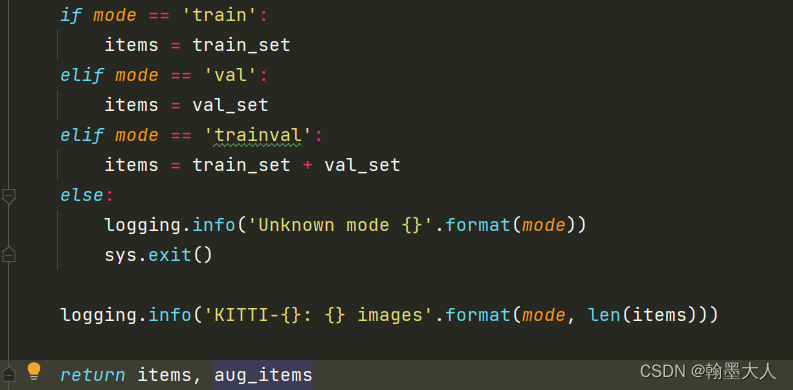
在kitti验证时候,验证的是所有图片。

15:接着生成一个json:
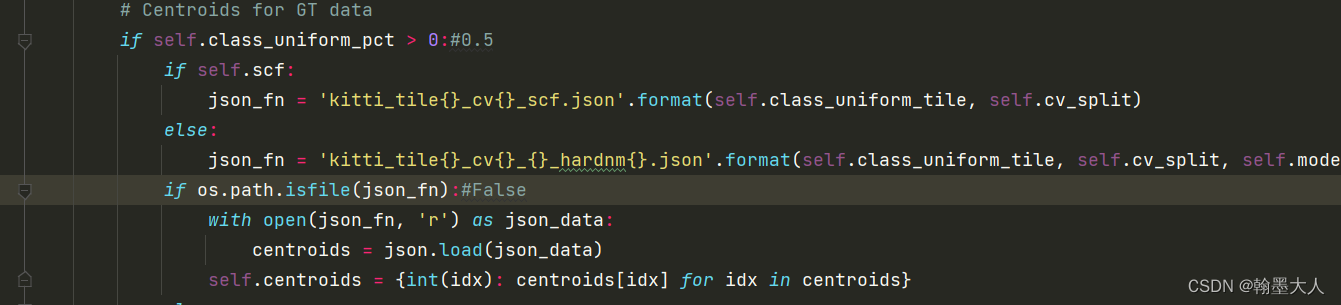
16:将self.imgs图片和类别,以及cityscape的id_to_trainid输入到class_centroids_all中,猜测是将semantic的34个类别映射到19个类别,将centroids写入到json文件中。
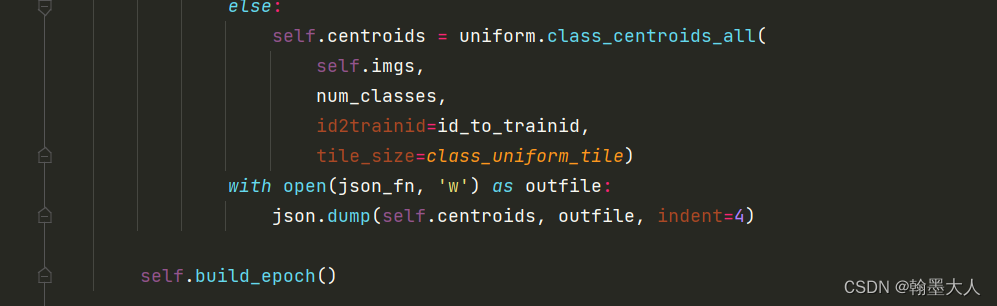
17:接着用新生成的uniform_image代替旧的image。

18:接着在get_item_中读入图片,并对图片进行处理。
SSeg总体思路
news2026/2/8 5:44:00
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/448983.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
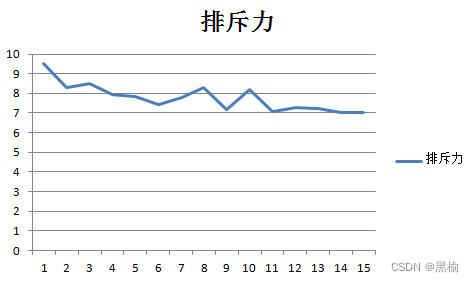
计算同列排斥力的一种可能方法
假设神经网络同列数字之间有一种排斥力,且这种排斥力也与距离的平方成反比。设0是环境,1是粒子,则两个1之间的排斥力就是距离平方的倒数。
考虑任意遥远的两个粒子之间都有排斥力,可以得到同列排斥力的计算方法为 如计算"01…

移动硬盘数据恢复软件实用技巧
在我们日常生活中,移动硬盘已经成为了我们不可或缺的存储设备之一。但是,由于各种原因,移动硬盘中的数据有时会丢失或损坏,这时候我们就需要使用移动硬盘数据恢复软件来帮助恢复数据。那么,移动硬盘数据恢复软件有哪些…

Windows环境下实现设计模式——中介者模式(JAVA版)
我是荔园微风,作为一名在IT界整整25年的老兵,今天总结一下Windows环境下如何编程实现中介者模式(设计模式)。
不知道大家有没有这样的感觉,看了一大堆编程和设计模式的书,却还是很难理解设计模式ÿ…
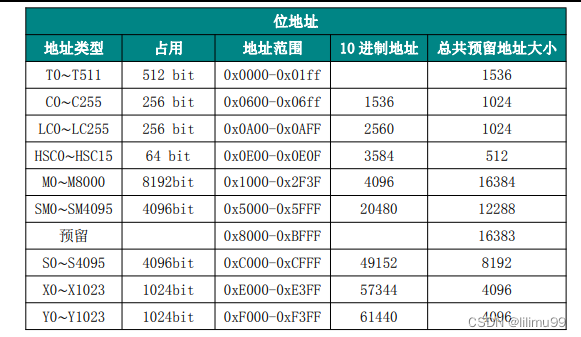
modbus指令测试
目录 一.抓包二.modbus与plc三.usb包分析四.编写modbus指令测试五.调试工具 一.抓包
1.串口抓包?wireshark!: https://xuxeu.github.io/uart-catch/ 2.Windows&Linux USB抓包方法总结:https://zhuanlan.zhihu.com/p/267820933 3.USB The Setup Pack…
(“树” 之 前中后序遍历 ) 94. 二叉树的中序遍历 ——【Leetcode每日一题】
基础概念:前中后序遍历 1/ \2 3/ \ \
4 5 6层次遍历顺序:[1 2 3 4 5 6]前序遍历顺序:[1 2 4 5 3 6]中序遍历顺序:[4 2 5 1 3 6]后序遍历顺序:[4 5 2 6 3 1]
层次遍历使用 BFS 实现,利用的就是 BFS…
一文搞懂Java中的异常问题
思考几个问题 1:JavaWeb系统中,我的代码未做任何处理,报错了还会往下执行吗? 2:JavaWeb系统中,我的代码做了 try catch finally, 报错了还会往下执行吗? 3:JavaWeb系统中,…

软考高频考点--《项目采购管理》
现在离2023年上半年软考还有一个多月的时间,相信各位小伙伴们已经进入紧张的备考状态了。 小编今天为大家整理了软考的一些高频考点–《项目采购管理》,希望对正在备考软考的你有所帮助! 采购是从项目团队外部获得产品、服务或成果的完整的购…

alsa_lib移植到IMX6ULL
简介
ALSA是Advanced Linux Sound Architecture的缩写,目前已经成为了linux下的主流音频体系架构,提供了音频和MIDI的支持。
交叉编译alsa_lib和alsa_utils
下载alsa_lib
在官网中下载AlsaProject
编译
先将文件解压,然后进入alsa_lib…
运筹说 第94期|论文速读之基于关键路径的置换流水车间调度问题
前几期的推送已经讲解了网络计划的基本知识、数学模型和相关算法,相信大家对网络计划已经有了充分的了解,这期小编将带大家一起来读一篇基于关键路径的置换流水车间调度问题的文章。 1.文章信息
题目:An efficient critical path based meth…
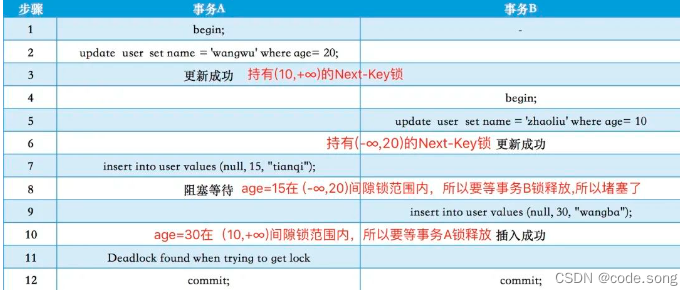
手把手教你分析解决MySQL死锁问题
在生产环境中出现MySQL死锁问题该如何排查和解决呢,本文将模拟真实死锁场景进行排查,最后总结下实际开发中如何尽量避免死锁发生。
一、准备好相关数据和环境 当前自己的数据版本是8.0.22
mysql> select version;
-----------
| version |
--------…
Arduino 多任务软件定时器:Simpletimer库的使用
Arduino 多任务软件定时器:Simpletimer库的使用 📌Simpletimer库Arduino官方介绍信息:https://playground.arduino.cc/Code/SimpleTimer/✨该库也是利用了millis()函数来实现任务轮询的。与之类似的还有ESP8266固件自带的Ticker库,但是Ticker库使用仅限于ESP8266内调用,Si…

Discourse Google Analytics 3 的升级提示
根据 Google 官方的消息:
Google Analytics(分析)4 是我们的新一代效果衡量解决方案,即将取代 Universal Analytics。自 2023 年 7 月 1 日起,标准 Universal Analytics 媒体资源将停止处理新的命中数据。如果您仍在使…

linux-01-基础回顾
文章目录 Linux-Day01课程内容1. 前言1.1 什么是Linux1.2 为什么要学Linux1.3 学完Linux能干什么 2. Linux简介2.1 主流操作系统2.2 Linux发展历史2.3 Linux系统版本 3. Linux安装3.1 安装方式介绍3.2 安装VMware3.3 安装Linux TODO3.4 网卡设置3.5 安装SSH连接工具3.5.1 SSH连…

【Python】【进阶篇】1、Django是什么?
目录 1、Django是什么?1. Django的由来2. Django的命名3. Django的版本发布1) 功能版2) 补丁版3) LTS 版本 4. Django框架的特点 1、Django是什么?
Django 是使用 Python 语言开发的一款免费而且开源的 Web 应用框架。由于 Python 语言的跨平台性&#…


VLAN与access接口、hybrid接口实验
[r1]dhcp enable //开启DHC0功能P
[r1-GigabitEthernet0/0/0]int g 0/0/0.1 [r1-GigabitEthernet0/0/0.1]ip add 192.168.1.1 24 [r1-GigabitEthernet0/0/0.1]dhcp select interface //接口地址池 [r1-GigabitEthernet0/0/0.1]dhcp server dns-list 8.8.8.8 [r1-GigabitEthern…

【Linux】输入系统详述 + 触摸屏应用实战(tslib)
目录简述
前言:
一、输入系统
二、Linux输入系统框架
(1)输入系统的驱动层 (2)输入系统核心层
(3)输入系统事件层
三、APP访问硬件的方式
(1)查询方式、休眠-唤醒…

Linux环境下安装RocketMQ
目录
前置要求:
一、下载RocketMQ
二、上传解压
三、配置rocketmq的环境变量
四、查看rocketmq的目录结构
五、启动
5.1 启动nameserver
5.2 启动broker
六、测试发送消息
七、关闭 前置要求:
准备一台Linux系统的虚拟机提前安装jdk1.8
不会…
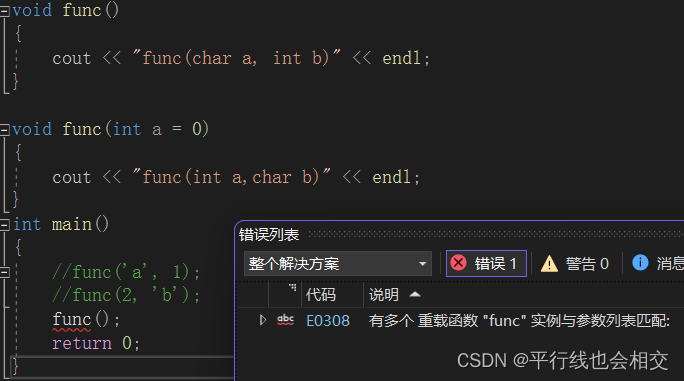
C++函数重载的简单介绍
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【C之路】 中华文化博大精深,我们知道在我们的汉语中,每个词语都有着其不同的含义,甚至是一个词语中有…

毫米波雷达将被颠覆?楚航科技发布隐形雷达ART
4月19日上海车展现场,楚航科技首次对外展示最新的前瞻性研发第N代创新产品——隐形雷达ART。
楚航科技本次发布的科技隐形雷达ART,打破一体式封装设计,重新定义车载毫米波雷达物理形态,为行业提供全新的颠覆性产品设计新路线。 资…