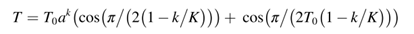目录
- 今日已完成任务列表
- 遇到的问题及解决方案
- 任务完成详细笔记
- 程序性能分析
- 程序流程分析
- 程序静态分析工具 understand
- 程序性能动态分析工具 gprof-使用方式
- 程序性能动态分析工具 gprof-输出结果详解
- 程序性能动态分析工具 gropf-函数调用关系图
- 程序动态分支辅助方式-计时函数
- 其他性能分析工具及 valgrind + Qcachegrind
- HPCG 性能分析实战
- 练习 (使用 gprof 分析 jacobi 程序性能)
- 对自己的表现是否满意
- 其他反馈
今日已完成任务列表
4-3、程序性能分析
遇到的问题及解决方案
编译安装HPCG程序的串行版本,并使用gprof对其进行性能分析。
不会装 〒▽〒
任务完成详细笔记
程序性能分析
程序流程分析
静态分析,即利用代码静态分析工具,对代码进行数据对象、函数接口封装和调用分析
- 代码浏览的分析工具是基于各种编程语言语法,预处理和编译方式以及配置安装信息来有组织有条理的显示代码源文件的工具
- 借助代码浏览分析工具,可以阅读和编辑代码、在代码中进行检索、了解代码的内层逻辑结构、分析代码的语法结构等
程序静态分析工具 understand
用于静态代码分析的工具
[略]
程序性能动态分析工具 gprof-使用方式
动态分析是指在程序实际调用过程中去分析程序执行了哪些函数和流程
Gprof 是一款易用的动态分析工具,除了函数的调用关系,同时还能给出函数的调用时间分布,为我们的性能分析提供参考,快速定位程序的热点函数位置
使用Gprof分析的流程:
- 编译代码文件
g++ -pg main.cpp -o main - 执行可执行文件
yhrun -p thcp1 -N 1 -n 1 main - 对生成的 gmon.out 文件进行转换 (二进制转为普通文本文件)
gprof main gmon.out>output.txt
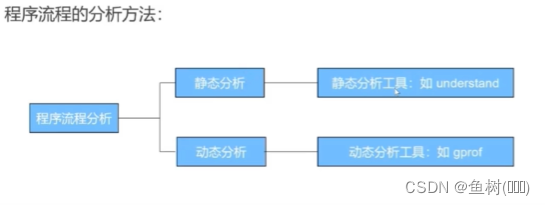
程序性能动态分析工具 gprof-输出结果详解
- Flat profile:扁平化 (性能) 概况
扁平化性能概况不区分函数调用关系,以程序中调用过的完整封装的函数体为对象,列出其执行时间、调用次数等作为性能描述 - Call graph:调用图谱
调用图谱将程序中的独立函数体按照其实际调用过程,列出上下文调用关系,以列表的形式给出来,通过辅助工具可以据此绘制出程序的调用关系图
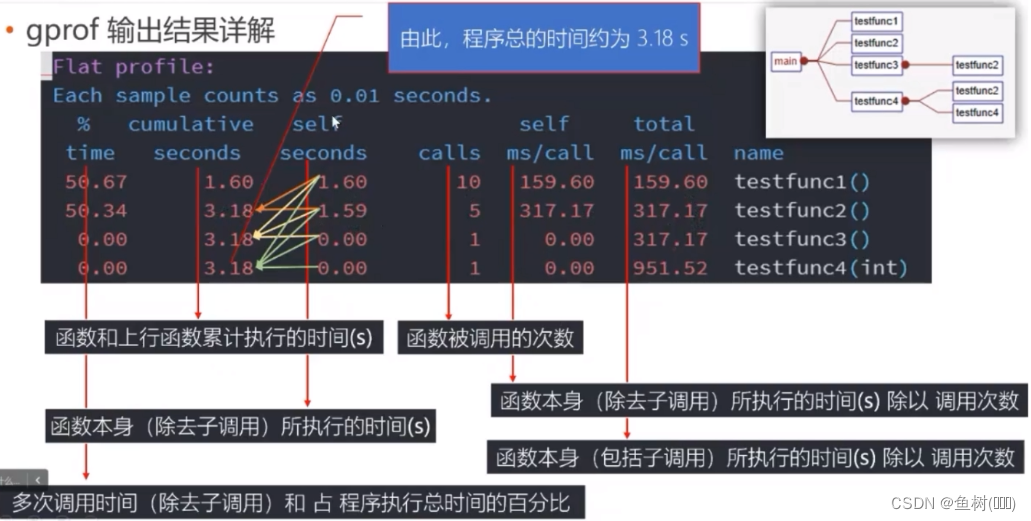
time:当前条目函数所有调用次数总执行时间 (包括子调用) 占整个程序执行时间的百分比
self:当前函数本身的执行时间
- 对于当前函数,self 表示其自身除去子调用的执行时间
- 对于当前函数的父调用,self 表示当前函数本身 (除去子调用) 对父调用的执行时间总贡献
- 对于当前函数的子调用,self 表示当前函数的各子调用各自的执行总时间
children:当前函数子调用的执行时间- 对于当前函数,children 表示所有子调用的总执行时间
- 对于当前函数的父调用,children 表示当前函数的子调用对父调用的执行时间总贡献
- 对于当前函数的子调用,children 表示当前函数的各子调用所调用的子调用对当前函数执行总时间的贡献
called:调用次数
- 对于当前函数,表示该函数实际的总调用次数,“+” 表示该函数为递归调用
- 对于当前函数的父调用,n/N,n 表示在父调用中实际调用的次数,N 表示当前函数调用的总次数
- 对于当前函数的子调用,n/N,n 表示调用了该子调用多少次,N 该子调用被调用的总次数
练习

耗时最长的两个函数是:( testfunc1 )和( testfunc2 )。
testfunc2函数自身执行的时间是:( 1.59 )seconds。
main函数分别调用了testfunc1函数( 10 )次,testfunc4函数( 1 )次,testfunc3函数( 1 )次,testfunc2函数( 1 )次。
testfunc2函数总共被调用了5次,其中main函数调用了testfunc2( 1 )次,testfunc4调用了testfunc2( 3 )次,testfunc3调用了testfunc2( 1 )次。
testfunc4递归调用( 1 )次。
程序性能动态分析工具 gropf-函数调用关系图
生成调用关系图
gprof2dot.py output.txt | dot -Tpng -o output.png

程序动态分支辅助方式-计时函数
手动在程序中添加 C 标准库中提供的计时函数对程序速度进行统计
- 计时函数 clock_gettime
函数"clock_gettime"是基于Linux C语言的时间函数,他可以用于计算精度和纳秒
#include<time.h>
int clock_gettime(clockid_t clk_id,struct timespec *tp);
struct timespec
{
time_t tv_sec; /* 秒*/
long tv_nsec; /* 纳秒*/
}
测试:
#include <time.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char **argv)
{
struct timespec time1 = {0, 0};
struct timespec time2 = {0, 0};
float temp;
clock_gettime(CLOCK_REALTIME, &time1);
usleep(1000);
clock_gettime(CLOCK_REALTIME, &time2);
temp = (time2.tv_nsec - time1.tv_nsec) / 1000000;
printf("time = %f ms\n", temp);
return 0;
}
- 统计时钟周期数 clock
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main()
{
int i=10;
clock_t start,finish;
double Times, Times1;
start=clock();
while(i--){
cout<<i<<endl;
};
finish=clock();
Times=(double)(finish-start)/CLOCKS_PER_SEC;
Times1=(double)(finish-start)/CLK_TCK;
cout<<"start(时钟打点): "<<start<<endl;
cout<<"finish(时钟打点): "<<finish<<endl;
cout<<"CLOCKS_PER_SEC: "<<CLOCKS_PER_SEC<<endl;
cout<<"CLK_TCK: "<<CLK_TCK<<endl;
cout<<"运行时间(秒)(CLOCKS_PER_SEC): "<<Times<<endl;
cout<<"运行时间(秒)(CLK_TCK): "<<Times1<<endl;
return 0;
}
其他性能分析工具及 valgrind + Qcachegrind
支持内存调试、内存泄漏检测以及性能分析、检测线程错误的软件开发工具
- Memcheck
用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对 malloc()/free()/new/delete 的调用都会被捕获 - callgrind
和 gprof 类似的分析工具,但其提供的信息更全面,不需要添加额外的编译选项,支持多线程 - Cachegrind
Cache分析器,模拟 CPU 中的缓存,能够精确地指出程序中 cache 的丢失和命中
valgrind+Qcachegrind的使用
yhrun -N 1 -n 1 -p thcp1 [valgrind_Path] [可执行文件_Path]
之后将 callgrind.out.xxx 文件导入 Qcachegrind
HPCG 性能分析实战


练习 (使用 gprof 分析 jacobi 程序性能)
cp -r ~/software/jacobi ~/trainees/username
进入jacobi目录
g++ -pg -O1 -o jacobi jacobi.cpp
编写 run_jacobi.sh文件
#!/bin/bash
yhrun -c 1 -N 1 -n 1 jacobi
执行
yhbatch -N 1 -p thcp1 ./run_jacobi.sh
对 gprof 文件进行转化
gprof jacobi gmon.out>output.txt
查看 output.txt 内容
cat output.txt
对自己的表现是否满意
今天主要对程序性能分析的概念和常用工具进行了了解,并使用 gprof 对一些简单程序进行了分析和解读,还是挺有收获的。
其他反馈
无