目录
目录
一、基本思想
二、术语
1、散列方法
2、散列函数
3、散列表
4、冲突
5、同义词
三、如何减少哈希冲突
四、构造散列函数需考虑的情况
五、散列函数的构造方法
1、直接定址法
2、除留余数法
六、如何处理哈希冲突
1、开地址法
2、拉链法
七、散列表查找效率分析
八、宏定义
九、结构体定义
1、HashTabElemType
2、HashNode
3、HashTable
十、函数定义
1、初始化哈希表
2、哈希函数(除留余数法)
3、添加节点
4、插入数据到哈希表
5、哈希表搜索值
十一、Linux环境测试
一、基本思想
记录存储位置和关键字之间的对应关系。
HASH TABLE也可以称为哈希表、散列表、杂凑表。
二、术语
1、散列方法
选取某个函数,用该函数按照关键字计算元素的存储位置,以此存放。
在查找时,用相同的函数计算传入参数的地址位置,再将传入参数与地址单元中的元素进行比较,判断查找是否成功。
2、散列函数
散列方法中使用的转换函数。
3、散列表
按照上述思想构造的表。
4、冲突
不同关键码映射到同一个散列地址。
就是说不同输入参数,经过散列函数得到的散列值是一样的。
5、同义词
具有相同函数值的多个关键字。
例如:输入参数a和输入参数b,经过hash计算得到的hash值相同,则a和b称为同义词。
三、如何减少哈希冲突
哈希冲突是不可避免的,只能尽量减少冲突的发生。
1、根据不同的哈希算法适当的加宽哈希表的长度。
2、选择哈希算法时也要考虑其计算出的哈希值是均匀分布的,但也要考虑算法的转换效率和空间浪费问题。
四、构造散列函数需考虑的情况
1、散列函数执行效率。
2、散列函数的关键字长度。
3、散列表的宽度。
4、关键字的分布情况。
5、查找频率。
五、散列函数的构造方法
| 构造方法名 | 介绍情况 |
| 直接定址法 | 介绍实现原理。 |
| 数字分析法 | 本文不介绍。 |
| 平方取中法 | 本文不介绍。 |
| 折叠法 | 本文不介绍。 |
| 除留余数法 | 介绍实现原理和C源码实现。 |
| 随机数法 | 本文不介绍。 |
1、直接定址法
其中A和B为常数。假设A=2,B=1。
测试数据为正整数:{1,3,2};
1和2之间空出两个空间,且不能存下其他正整数。
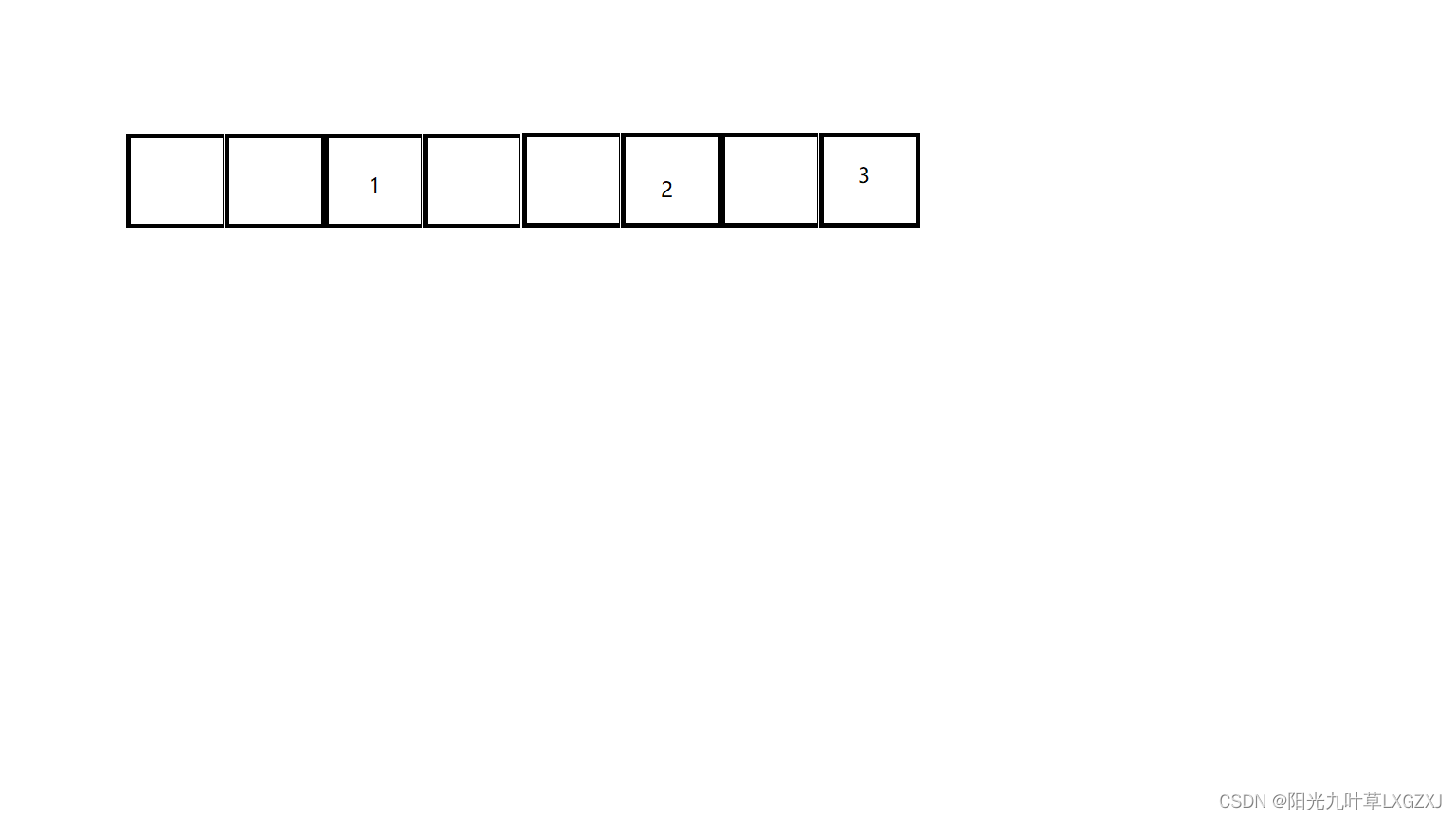
优点:以关键码Key的某个线性函数值为散列地址,不会产生冲突的情况。
缺点:需要占用连续的地址空间,空间效率低。
2、除留余数法
假设表长为N,则P<=N且为质数(质数指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。)
其中P为整数,%为余除,假设P=7。
测试数据为正整数:{1,3,2,8};

优点:空间使用效率高。
缺点:可能会出现哈希冲突。
六、如何处理哈希冲突
| 方法名 | 介绍情况 |
| 开放定址法(开地址法) | 介绍实现原理。 |
| 链地址法(拉链法) | 介绍实现原理和C源码实现。 |
| 再散列法(双散列函数法) | 本文不介绍。 |
| 建立一个公共溢出区 | 本文不介绍。 |
1、开地址法
基本思想:在发生冲突时会去寻找下一个空的地址,只要散列表的宽度足够,一定能找到空的地址存储下。
除留余数法为例:
其中Di为增量序列。由于Di的不同,可以划分为三种常用方法。
| 方法名 | 描述 |
| 线性探测法 | Di为1,2,.....,P-1线性序列。 |
| 二次探测法 | Di为1^2,-1^2,2^2,-2^2,......,Q^2二次序列。 |
| 伪随机探测法 | Di为伪随机序列。 |
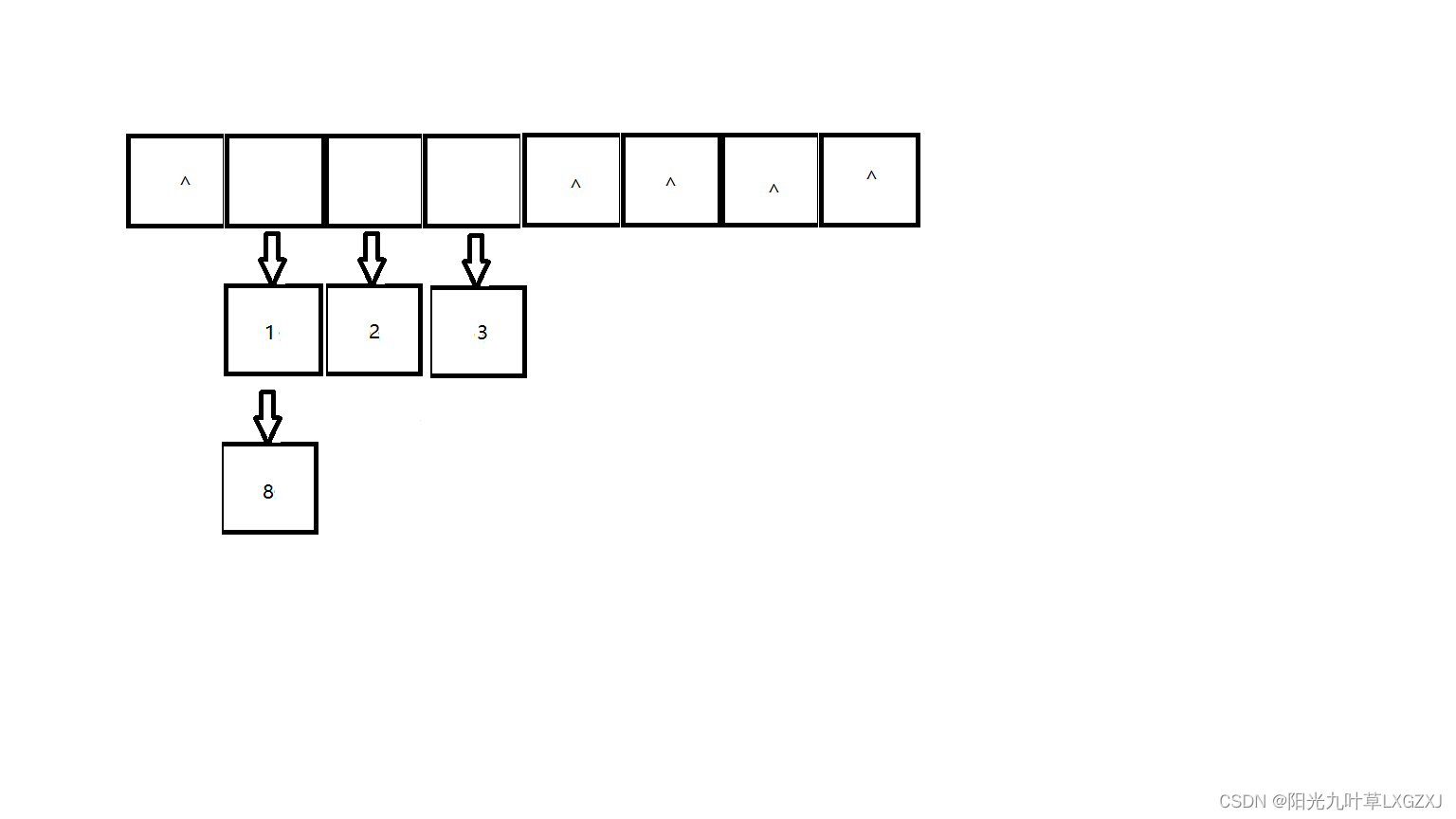
这里就拿线性探测法简单举例说明一下,利用
P等于7进行计算,发现8和1有哈希冲突, 这时用
,Di为1,也就是((8 % 7) + 1) % 7,等于2,但2号索引位存了2,还是冲突,继续线性探测,
((8 % 7) + 2) % 7,等于3 ,但3号索引位存了3,还是冲突,继续线性探测,((8 % 7) + 3) % 7,等于4,4号索引位为空,可以存储。
其他两种探测法也是类似的,大家可以自己推理一下。
2、拉链法
基本思想:相同散列地址的记录链成一单链表,m个散列地址设置m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态结构。
如果出现冲突,单链表就会添加一个节点。理想情况下时间复杂度可以达到O(1)。
七、散列表查找效率分析
ASL(平均查找长度)衡量散列表查找算法,有以下几个影响因素:
1、散列函数。
2、处理冲突的方法。
3、散列表的填装因子α。
α = 表中填入记录数 / 哈希表长度。
α越大,表示表中数据越多,发生哈希冲突的概率越大,查找时比较的次数也越多。
时间复杂度既不是O(1),也不是O(n)。
ASL ≈ 1 + α / 2 (拉链法)
ASL ≈ (1 + 1 / (1 - α) ) / 2 (线性探测法)
八、宏定义
#define HASH_TABLE_MAX_SIZE 17哈希表的最大长度,也是除留余数法中的除数。
九、结构体定义
1、HashTabElemType
typedef long long int HashTabElemType; //-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807哈希表中存储的数据类型。
2、HashNode
typedef struct HashNode
{
HashTabElemType Data;
struct HashNode* NextPtr;
}HashNode;哈希表中单链表的结构。
3、HashTable
typedef struct HashTable
{
HashNode* FirstHashNode;
HashTabElemType DataNum;
}HashTable;哈希表的结构。DataNum表示这条链上有多少个数据节点。
十、函数定义
1、初始化哈希表
Status InitHashTable(HashTable** HashTab)
{
JudgeAllNullPointer(HashTab);
*HashTab = (HashTable*)MyCalloc(HASH_TABLE_MAX_SIZE, sizeof(HashTable));
Log("Init Hash Table OK\n",Debug);
return SuccessFlag;
}
2、哈希函数(除留余数法)
//除留余数法
HashTabElemType MyHashFunc(HashTabElemType Num)
{
return Num % HASH_TABLE_MAX_SIZE;
}
3、添加节点
HashNode* NewHashNode(HashTabElemType Num)
{
HashNode* NewNode = (HashNode*)MyMalloc(sizeof(HashNode));
NewNode->Data = Num;
NewNode->NextPtr = NULL;
return NewNode;
}
4、插入数据到哈希表
Status InsertHashTable(HashTable* HashTab, HashTabElemType Num)
{
JudgeAllNullPointer(HashTab);
HashTabElemType HashValue = MyHashFunc(Num);
(HashTab[HashValue].DataNum)++;
if(HashTab[HashValue].FirstHashNode == NULL)//no data
{
HashTab[HashValue].FirstHashNode = NewHashNode(Num);
Log("Insert Hash Table OK\n",Debug);
return SuccessFlag;
}
//have data
HashNode* NewNode = NewHashNode(Num);
NewNode->NextPtr = HashTab[HashValue].FirstHashNode;
HashTab[HashValue].FirstHashNode = NewNode;
Log("Insert Hash Table OK , Hash Conflict\n",Debug);
return SuccessFlag;
}实现思路:
1、算哈希值,定索引位,此链表数据长度加一。
2、如果链表头指针为空,就插入。
3、如果不为空,就用头插法把数据插入到链表中。
5、哈希表搜索值
//HashValue为返回的索引位
Status SearchHashTable(HashTable* HashTab, HashTabElemType Num, HashTabElemType* HashValue)
{
JudgeAllNullPointer(HashTab);
*HashValue = MyHashFunc(Num);
HashNode* TmpHashNode = HashTab[*HashValue].FirstHashNode;
while(TmpHashNode != NULL)
{
if(TmpHashNode->Data == Num)
{
Log("Search Hash Table OK\n",Debug);
return SuccessFlag;
}
TmpHashNode = TmpHashNode->NextPtr;
}
Log("Search Hash Table Fail\n",Debug);
return FailFlag;
}实现思路:
1、算哈希值,将值赋予输出参数HashValue,定索引位。
2、如果链表指针为空,查询失败。
3、如果匹配到值,查询成功。
十一、Linux环境测试
[gbase@localhost Select]$ make
gcc -Wall -O3 ../Log/Log.c ../PublicFunction/PublicFunction.c Select.c HashTable.c main.c -o TestSelect -I ../Log/ -I ../PublicFunction/ -I ./
[gbase@localhost Select]$ ./TestSelect
[2023-4]--[ Debug ]--Init Hash Table OK
[2023-4]--[ Debug ]--Insert Hash Table OK
[2023-4]--[ Debug ]--Insert Hash Table OK , Hash Conflict
[2023-4]--[ Debug ]--Insert Hash Table OK
[2023-4]--[ Debug ]--Insert Hash Table OK
[2023-4]--[ Debug ]--Printf HashTable
DataNum : 0 , [(nil)]
DataNum : 2 , [1,1]
DataNum : 1 , [2]
DataNum : 1 , [3]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
DataNum : 0 , [(nil)]
[2023-4]--[ Debug ]--Search Hash Table OK
1
[2023-4]--[ Debug ]--Search Hash Table Fail
8