这两天自己手写了一个可以简单实现通道剪枝的代码,在这篇文章中也会对代码进行讲解,方便大家在自己代码中的使用。
如果还想学习YOLO系列的剪枝代码,可以参考我其他文章,下面的这些文章都是我根据通道剪枝的论文在YOLO上进行的实现,而本篇文章是我自己写的,也是希望能帮助一些想学剪枝的人入门,希望多多支持:
YOLOv4剪枝
YOLOX剪枝
YOLOR剪枝
YOLOv5剪枝
YOLOv7剪枝
目录
网络定义
剪枝代码详解
计算各通道贡献度
对贡献度进行排序
计算要剪掉的通道数量
新建卷积层
权重的重分配
新卷积代替model中的旧卷积
新建BN层
剪枝前后网络结构以及参数对比
完整代码
更新内容:
剪枝:
绘制2D权重:
绘制3D权重
还有一点需要说明,本篇文章现仅支持卷积层的剪枝(后续会不断更新其他网络类型),暂未加入其他类型的剪枝,比如BN层,所以各位在尝试的需要注意一下,不然容易报错(新版本已经支持BN层的轻量化处理,已在github中同步更新)。接下来步入正题。
通道剪枝属于结构化剪枝的一种,该方法可以根据各通道权重大小来进行修剪。可以将那些贡献度小的通道删除,仅保留贡献度大的通道,最终得到修剪后的新卷积,以此减少参数,同时也希望较少的减少精度损失。
一般情况会用L1或者L2来计算各通道权重,然后对通道进行排序后再剪枝。
网络定义
首先我们先定义一个全卷积网络(仅有卷积层和激活函数层),该网络由8层卷积构成,代码如下:
class Model(nn.Module):
def __init__(self, in_channels):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 32, kernel_size=3, padding=1, bias=False)
self.act1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1, bias=False)
self.act2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1, bias=False)
self.act3 = nn.ReLU(inplace=True)
self.conv4 = nn.Conv2d(128, 256, 3, 1, 1, bias=False)
self.act4 = nn.ReLU(inplace=True)
self.conv5 = nn.Conv2d(256, 512, 3, 1, 1, bias=False)
self.act5 = nn.ReLU(inplace=True)
self.conv6 = nn.Conv2d(512, 1024, 3, 1, 1, bias=False)
self.act6 = nn.ReLU(inplace=True)
self.conv7 = nn.Conv2d(1024, 2048, 3, 1, 1, bias=False)
self.act7 = nn.ReLU(inplace=True)
self.conv8 = nn.Conv2d(2048, 4096, 3, 1, 1, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.act2(x)
x = self.conv3(x)
x = self.act3(x)
x = self.conv4(x)
x = self.act4(x)
x = self.conv5(x)
x = self.act5(x)
x = self.conv6(x)
x = self.act6(x)
x = self.conv7(x)
x = self.act7(x)
out = self.conv8(x)
return out剪枝代码详解
接下来是根据剪枝的思想写剪枝函数(完整的代码我会在文末附上)。
定义剪枝函数prune,这里传入两个参数,model:即传入我们前面定义的网络。percentage:剪枝率,比如当percentage为0.5的时候表示对该卷积50%的通道进行剪枝。这里的importance是一个字典类型,用来存储各个卷积层通道L1值。
def prune(model, percentage):
# 计算每个通道的L1-norm并排序
importance = {}计算各通道贡献度
model.named_modules()可以获得模型每层的名字以及该层的类型,比如对前面定义的模型进行遍历时,name='conv1',module=nn.Conv2d。
通过isinstance用来判断我们剪枝的类型,我这里写的是nn.Conv2d,表示对卷积进行剪枝(暂未加入BN层)。
torch.norm是可以计算范数,我们传入的数据是该层的所有通道的权值,1表示L1-norm,如果你写2就是2范数,dim=(1,2,3)是对该维度进行计算。因为我们卷积核的shape是[out_channels,in_channels,kernel_size,kernel_size],比如conv1的shape就是[32,3,3,3],因此dim=(1,2,3)。
所以下述代码表示:判断网络各层属性是否为卷积层,如果是卷积,那么在输出通道维度上计算该卷积各通道的L1范数。
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
importance[name] = torch.norm(module.weight.data, 1, dim=(1, 2, 3))计算值如下(这里只举一个层为例):
{'conv1': tensor([2.3424, 2.3291, 2.2797, 3.1257, 2.7289, 2.4918, 2.4897, 2.9199, 2.0484,
2.4627, 2.5531, 2.2539, 2.4477, 2.3570, 2.5563, 2.9574, 2.7499, 2.0182,
2.8837, 2.5835, 2.8180, 2.2055, 3.0783, 2.7072, 2.8927, 2.4416, 2.7805,
2.7791, 2.6328, 2.8975, 2.9354, 2.6887])}
对贡献度进行排序
这一行代码就是对上面计算的L1进行排序,只不过这里返回的sorted_channels是各个通道的索引。
# 对通道进行排序,返回索引
sorted_channels = np.argsort(np.concatenate([x.cpu().numpy().flatten() for x in importance[name]]))得到的排序结果如下(从小到大排序),注意返回的是通道索引:
[17 8 21 11 2 1 0 13 25 12 9 6 5 10 14 19 28 31 23 4 16 27 26 20, 18 24 29 7 30 15 22 3]
计算要剪掉的通道数量
num_channels_to_prune是要剪掉的通道数量,比如此时我设置的剪枝率为0.5,conv1的输出通道为32,那么剪去50%就是16个。
# 要剪掉的通道数量
num_channels_to_prune = int(len(sorted_channels) * percentage)下面为输出结果,表示conv1层要剪16个通道
2023-04-19 09:05:42.241 | INFO | __main__:prune:70 - The number of channels that need to be cut off in the conv1 layer is 16
这16个通道索引为:
conv1 layer pruning channel index is [17 8 21 11 2 1 0 13 25 12 9 6 5 10 14 19]
新建卷积层
new_module是新建的卷积层,该卷积层用来接收剪枝后的结果。
这里需要注意一点的是,我这里输入通道in_channels用的是3 if module.in_channels==3 else in_channels,这是因为如果比如你对conv1剪枝后,那么该层的输出通道会改变,下一层的conv2的输入通道如果不变的化会报shape的错误,因为下层的输入是上层的输出,因此每层剪枝的时候需要记录一下通道的变化。然后其他属性不变。
new_module = nn.Conv2d(in_channels=3 if module.in_channels == 3 else in_channels, # *
out_channels=module.out_channels - num_channels_to_prune,
kernel_size=module.kernel_size,
stride=module.stride,
padding=module.padding,
dilation=module.dilation,
groups=module.groups,
bias=(module.bias is not None)
).to(next(model.parameters()).device)
in_channels = new_module.out_channels # 因为前一层的输出通道会影响下一层的输入通道此时创建的new_module为,可以看到新建的卷积输出通道为16:
Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
同时可以看一下这个new_module卷积部分默认的权重参数(注意留意一下这里,后面要做对比的):
Parameter containing:
tensor([[[[ 0.1232, 0.0262, -0.0958],
[ 0.0085, -0.1569, -0.1070],
[-0.1693, -0.1114, -0.1518]],[[-0.0057, 0.1428, 0.0811],
[ 0.0324, -0.1620, -0.1143],
[-0.0407, 0.1052, -0.1360]],[[-0.1781, -0.0648, -0.1358],
[-0.0793, -0.0506, -0.1243],
[ 0.1060, 0.0986, 0.0328]]],
权重的重分配
由于前num_channels_to_prune是我们剪枝不要的,因此只保留后面的通道,所以通过module.weight.data[num_channels_to_prune:,:c1,...]将原来的权重传给新卷积。
# 重新分配权重 权重的shape[out_channels, in_channels, k, k]
c2, c1, _, _ = new_module.weight.data.shape
new_module.weight.data[...] = module.weight.data[num_channels_to_prune:, :c1, ...]
if module.bias is not None:
new_module.bias.data[...] = module.bias.data[sorted_channels[num_channels_to_prune:]]先看一下conv1中原来的权值:
conv1:对应代码中的module
tensor([[[[-0.0095, -0.1064, -0.0761],
[-0.0687, 0.1567, 0.0410],
[-0.1303, -0.0556, 0.0263]],[[ 0.1690, -0.0342, 0.0444],
[ 0.0423, 0.1286, 0.1294],
[-0.1861, 0.1208, 0.1759]],[[ 0.1747, -0.0429, 0.0311],
[ 0.1235, -0.1835, -0.0983],
[-0.1890, -0.1257, 0.0798]]],
再来看一下权值重新分配,可以和上面未传入参数的new_module做对比,是不是发现现在权值已经更新了:
此时的new_module :
tensor([[[[-0.0095, -0.1064, -0.0761],
[-0.0687, 0.1567, 0.0410],
[-0.1303, -0.0556, 0.0263]],[[ 0.1690, -0.0342, 0.0444],
[ 0.0423, 0.1286, 0.1294],
[-0.1861, 0.1208, 0.1759]],[[ 0.1747, -0.0429, 0.0311],
[ 0.1235, -0.1835, -0.0983],
[-0.1890, -0.1257, 0.0798]]],
通过上述过程就产生了新的剪枝后的卷积了。
新卷积代替model中的旧卷积
最后就是用新的卷积new_module替换我们网络中旧的卷积。仅一行代码就可以解决。
setattr(prune_model, f"{name}", new_module)可以看一下打印,此时的model中的conv1输出通道变成了16,说明剪枝并替换成功。
Model(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act1): ReLU(inplace=True)
新建BN层
如果有BN层,那么对BN层也做轻量化处理。过程与上面卷积层一样。同时用新BN层替换旧的。
elif isinstance(module, nn.BatchNorm2d):
new_bn = nn.BatchNorm2d(num_features=new_module.out_channels,
eps=module.eps,
momentum=module.momentum,
affine=module.affine,
track_running_stats=module.track_running_stats).to(next(model.parameters()).device)
new_bn.weight.data[...] = module.weight.data[sorted_channels[num_channels_to_prune:]]
if module.bias is not None:
new_bn.bias.data[...] = module.bias.data[sorted_channels[num_channels_to_prune:]]
# 用新bn替换旧bn
setattr(prune_model, f"{name}", new_bn)剪枝前后网络结构以及参数对比
现在可以对比一下剪枝前后打印的网络解构,已经能够发现剪枝后各层通道数量减少了一半。
剪枝前:
model: Model(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act1): ReLU(inplace=True)
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act2): ReLU(inplace=True)
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act3): ReLU(inplace=True)
(conv4): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act4): ReLU(inplace=True)
(conv5): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act5): ReLU(inplace=True)
(conv6): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act6): ReLU(inplace=True)
(conv7): Conv2d(1024, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act7): ReLU(inplace=True)
(conv8): Conv2d(2048, 4096, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
剪枝后:
pruned model: Model(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act1): ReLU(inplace=True)
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act2): ReLU(inplace=True)
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act3): ReLU(inplace=True)
(conv4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act4): ReLU(inplace=True)
(conv5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act5): ReLU(inplace=True)
(conv6): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act6): ReLU(inplace=True)
(conv7): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(act7): ReLU(inplace=True)
(conv8): Conv2d(1024, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
再看一下剪枝前后参数对比:
可以看到参数少了不少。
Number of parameter: 100.66M
Number of pruned model parameter: 25.16M
完整代码
import numpy as np
import torch
import torch.nn as nn
from loguru import logger
def count_params(module):
return sum([p.numel() for p in module.parameters()])
class Model(nn.Module):
def __init__(self, in_channels):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 32, kernel_size=3, padding=1, bias=False)
self.act1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1, bias=False)
self.act2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1, bias=False)
self.act3 = nn.ReLU(inplace=True)
self.conv4 = nn.Conv2d(128, 256, 3, 1, 1, bias=False)
self.act4 = nn.ReLU(inplace=True)
self.conv5 = nn.Conv2d(256, 512, 3, 1, 1, bias=False)
self.act5 = nn.ReLU(inplace=True)
self.conv6 = nn.Conv2d(512, 1024, 3, 1, 1, bias=False)
self.act6 = nn.ReLU(inplace=True)
self.conv7 = nn.Conv2d(1024, 2048, 3, 1, 1, bias=False)
self.act7 = nn.ReLU(inplace=True)
self.conv8 = nn.Conv2d(2048, 4096, 3, 1, 1, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.act2(x)
x = self.conv3(x)
x = self.act3(x)
x = self.conv4(x)
x = self.act4(x)
x = self.conv5(x)
x = self.act5(x)
x = self.conv6(x)
x = self.act6(x)
x = self.conv7(x)
x = self.act7(x)
out = self.conv8(x)
return out
def prune(model, percentage):
# 计算每个通道的L1-norm并排序
importance_conv = {}
prune_model = model
for name, module in model.named_modules():
if isinstance(module, (nn.Conv2d, nn.BatchNorm2d)):
# torch.norm用于计算张量的范数,可以计算每个通道上的L1范数 conv.weight.data shape [out_channels,in_channels, k,k]
if isinstance(module, nn.Conv2d):
importance_conv[name] = torch.norm(module.weight.data, 1, dim=(1, 2, 3))
# 对通道进行排序,返回索引
sorted_channels = np.argsort(np.concatenate([x.cpu().numpy().flatten() for x in importance_conv[name]]))
# logger.info(f"{name} layer channel sorting results {sorted_channels}")
# 要剪掉的通道数量
num_channels_to_prune = int(len(sorted_channels) * percentage)
logger.info(
f"The number of channels that need to be cut off in the {name} layer is {num_channels_to_prune}")
logger.info(f"{name} layer pruning channel index is {sorted_channels[:num_channels_to_prune]}")
new_module = nn.Conv2d(in_channels=3 if module.in_channels == 3 else in_channels,
out_channels=module.out_channels - num_channels_to_prune,
kernel_size=module.kernel_size,
stride=module.stride,
padding=module.padding,
dilation=module.dilation,
groups=module.groups,
bias=(module.bias is not None)
).to(next(model.parameters()).device)
in_channels = new_module.out_channels # 因为前一层的输出通道会影响下一层的输入通道
# 重新分配权重 权重的shape[out_channels, in_channels, k, k]
c2, c1, _, _ = new_module.weight.data.shape
new_module.weight.data[...] = module.weight.data[num_channels_to_prune:, :c1, ...]
if module.bias is not None:
new_module.bias.data[...] = module.bias.data[sorted_channels[num_channels_to_prune:]]
# 用新卷积替换旧卷积
setattr(prune_model, f"{name}", new_module)
elif isinstance(module, nn.BatchNorm2d):
new_bn = nn.BatchNorm2d(num_features=new_module.out_channels,
eps=module.eps,
momentum=module.momentum,
affine=module.affine,
track_running_stats=module.track_running_stats).to(next(model.parameters()).device)
new_bn.weight.data[...] = module.weight.data[sorted_channels[num_channels_to_prune:]]
if module.bias is not None:
new_bn.bias.data[...] = module.bias.data[sorted_channels[num_channels_to_prune:]]
# 用新bn替换旧bn
setattr(prune_model, f"{name}", new_bn)
return prune_model
model = Model(3)
total_param = count_params(model)
torch.save(model, "model.pth")
print(f'\033[5;33m model: {model}\033[0m')
x = torch.randn(1, 3, 32, 32)
prune_model = prune(model, 0.5)
print(f'\033[1;36m pruned model: {prune_model}\033[0m')
total_prune_param = count_params(prune_model)
print("Number of parameter: %.2fM" % (total_param / 1e6))
print("Number of pruned model parameter: %.2fM" % (total_prune_param / 1e6))
torch.save(prune_model, "pruned.pth")
out = prune_model(x)
上面代码中有两行需要注意,torch.save(prune_model)而不是torch.save(prune_model.state_dict())【两者的区别是前者会将网络模型和权值全部报错,后者只保存权值,这点必须注意,如果要实现微调训练必须用前者进行保存,不然会报keys的shape问题】。out = prune_model(x)是用来判断剪枝后的模型能否正常输出。
如果你网络的最后一层的输出通道为num_classes,那建议你最后一层不要剪枝,不然就影响了分类输出。
更新内容:
2023.04.21更新内容:
对上述剪枝代码进行了整理,同时加入了2D和3D权重的绘制。
prunmodel_.py参数说明:
--prune:是否开启剪枝功能
--percent:剪枝率,默认0.5
--save:是否保存模型
--plt:绘制2D卷积权重图
--plt_3d:绘制3D卷积权重图
--layer_name:需要绘制的权重层名字
项目代码链接:
GitHub - YINYIPENG-EN/deeplearning_channel_prune: pytorch环境下卷积层的通道剪枝
剪枝:
python prunmodel_.py --prune --percent 0.5绘制2D权重:
这里以绘制conv1为例
python prunmodel_.py --plt --layer_name 'conv1.weight' 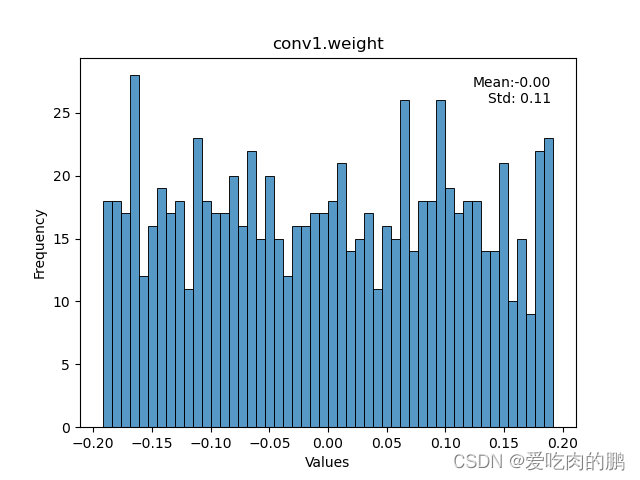
绘制3D权重
python prunmodel_.py --plt_3d --layer_name 'conv1.weight' 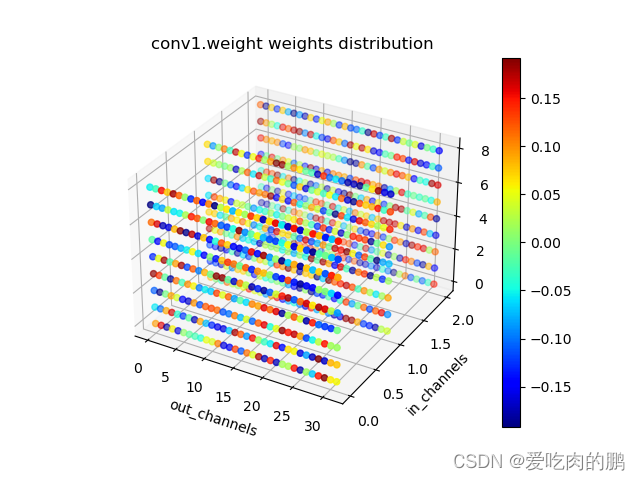
2023.04.22更新内容:
支持BN层的轻量化,可实现对VGG网络的剪枝。
后续将不定时更新其他类型的剪枝,希望多多支持~~