文章目录
- 分组卷积 Group Converlution
- 1、由来和用途
- 2、常规卷积和分组卷积的区别
- 2.1、常规卷积:
- 常规卷积的运算量:
- 2.2、分组卷积:
- 3、分组卷积的作用
- 4、深度可分离卷积
- 总结:先做分组卷积,再做1 x 1卷积
- 深度可分离卷积代码
- 参考博客:
分组卷积 Group Converlution
1、由来和用途
分组卷积最开始被使用在经典入门卷积神经网络AlexNet上,用于解决显存不足的问题。在现在被广泛用于各种轻量化模型中,用于减少运算量和参数量,其中应用最广的就是深度可分离卷积。
2、常规卷积和分组卷积的区别
现在我们编写代码时,在PyTorch中常常要处理的数据维度就是 (Batch,Channel, Height, Width),简写(B,C,H,W)。
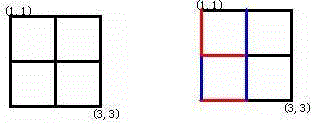
以下图可以说很直观了,相同颜色的卷积核只负责和它相同颜色的featuremap.
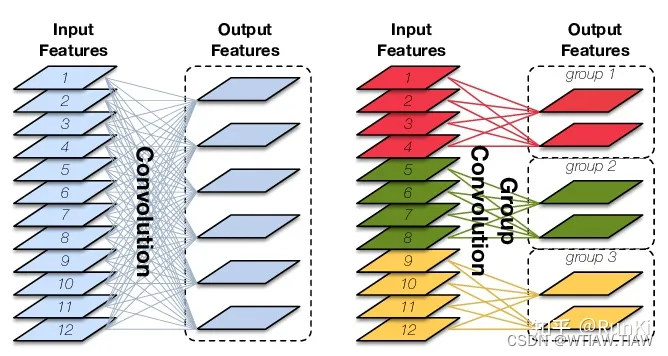
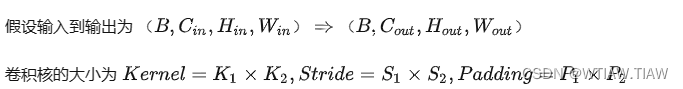
2.1、常规卷积:

常规卷积的运算量:
- 卷积核的运算量应该由乘法和加法两部分组成, 也就是乘加次数MAC(Multiply
Accumulate))需要计算乘法和加法两种操作的计算次数。 - 一个卷积核在某一像素点上的运算量是:

常规卷积的参数量:

# 在Jupyter运行下面代码
from torch import nn
cnn = nn.Conv2d(2, 3, 3, 1, 1, bias=True)
print(f"{cnn.weight.shape=}")
# cnn.weight.shape=torch.Size([3, 2, 3, 3]), 表示三个卷积核,每个卷积核2个通道,每个通道掩膜大小为3x3
print(f"{cnn.bias.shape=}")
# cnn.bias.shape=torch.Size([3]), 表示三个卷积核有三个偏置bias,并不是每个卷积核每个通道一个bias
2.2、分组卷积:

3、分组卷积的作用

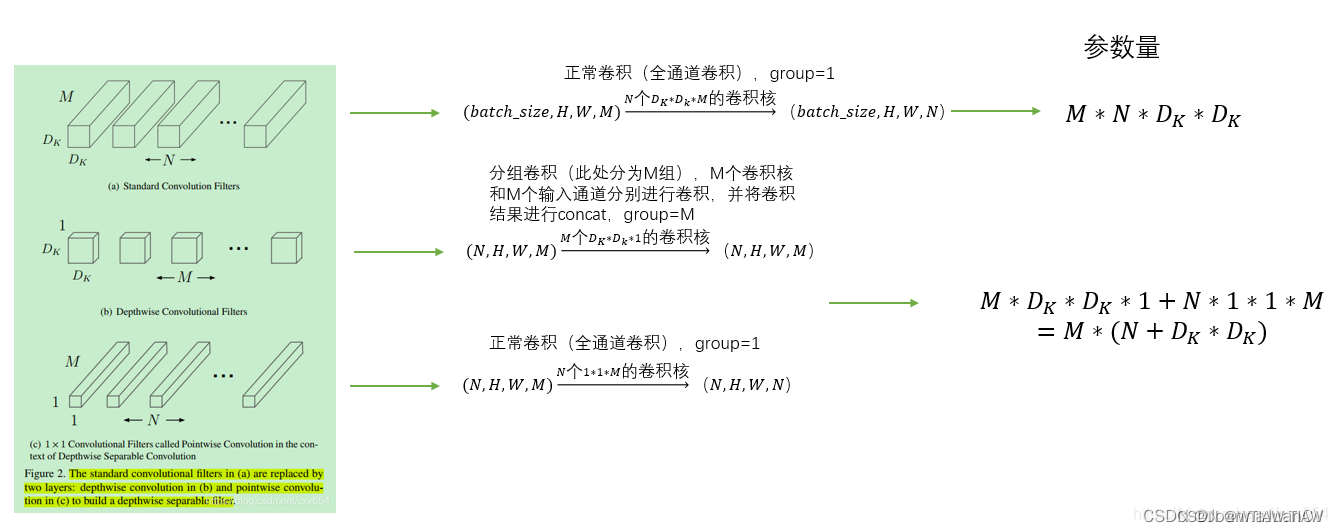
4、深度可分离卷积
总结:先做分组卷积,再做1 x 1卷积
-
分组卷积,g = in = out,此时每个卷积核只负责一个通道,生成的特征图之间不存在信息交换(即在通道维度不存在信息交换)
-
1 x 1卷积,用来实现通道件的信息交换,但在空间层面上缺少信息交流。 可以使用 torch.nn.Conv2d() 中的卷积组参数groups,来实现深度可分离卷积。groups 参数是用于控制输入和输出的连接的,表示要分的组数(in_channels 和out_channels 都必须能被 groups 参数整除)。例如:
1.当 groups =1 (默认值)时,就是同普通的卷积;
2.当 groups=n 时,相当于把原来的卷积分成 n 组,每组 in_channels/n 的输入与 out_channels/n 个 kernel_size x kernel_size x in_channels/n的卷积核卷积,生成 out_channels/n 的输出
,然后将各组输出连接起来,形成完整的 out_channels 的输出;
3.当 groups = in_channels 时,每个输入通道都只跟 out_channels/in_channels 个卷积核卷积; out_channels = in_channels 时就是 Depthwise 卷积。

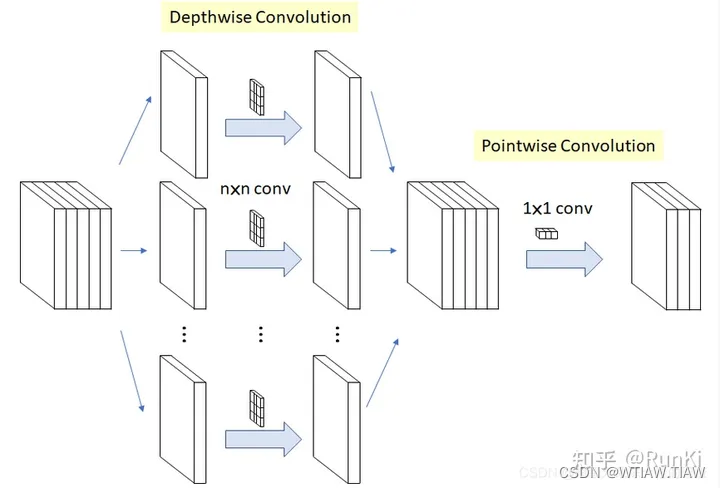
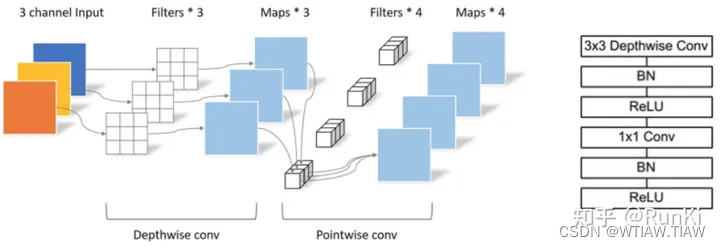
深度可分离卷积代码
import torch
from torchsummary import summary
class myGroupConv(torch.nn.Module):
def __init__(self):
super(myGroupConv, self).__init__()
self.conv2d = torch.nn.Conv2d(in_channels=4,
out_channels=8,
kernel_size=3,
stride=1,
padding=1,
groups=1,
bias=False)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv2d(x)
x = self.relu(x)
return x
# 先做分组卷积再做1x1卷积提取通道之间的信息通信
class depthwise_separable_conv(torch.nn.Module):
def __init__(self, ch_in, ch_out):
super(depthwise_separable_conv, self).__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.depth_conv = torch.nn.Conv2d(ch_in, ch_in, kernel_size=3, padding=1, groups=ch_in, bias=False)
self.point_conv = torch.nn.Conv2d(ch_in, ch_out, kernel_size=1, bias=False)
def forward(self, x):
x = self.depth_conv(x)
x = self.point_conv(x)
return x
class mydspConv(torch.nn.Module):
def __init__(self):
super(mydspConv, self).__init__()
self.conv2d = depthwise_separable_conv(4, 8)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv2d(x)
x = self.relu(x)
return x
device = torch.device("cuda" )
model_1 = myGroupConv().to(device)
summary(model_1, (4, 3, 3))
model_2 = mydspConv().to(device)
summary(model_2, (4, 3, 3))
输出:
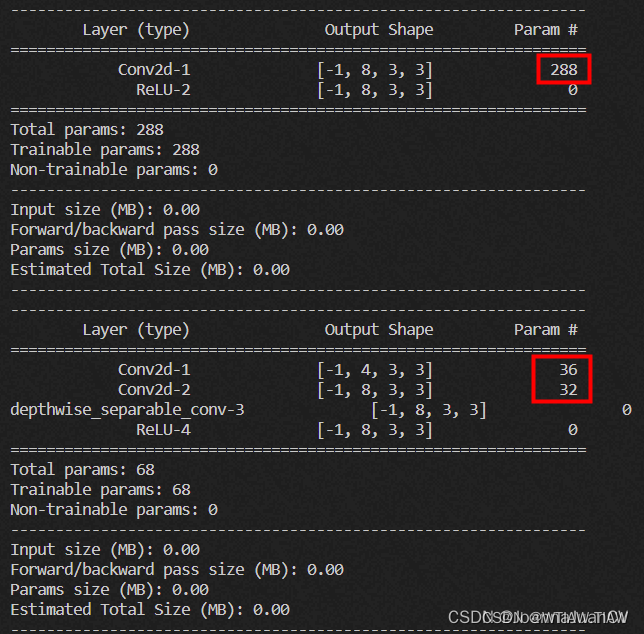
说明:
输入尺寸:3x3x4
输出尺寸:3x3x8
常规卷积,group=1,参数量:3x3x4x8=288;测试代码中偏置设为False,所以不加上偏置的参数量,若设为true,则参数量还需要加上等于输出通道个数的偏执量的个数,等于296;
深度可分离卷积:
逐通道卷积:groups=输入通道数,输出通道数=输入通道数,kernel_size=3,每一个卷积核只在一个通道上进行卷积,其参数量=3×3×4=36
逐点卷积:kernel_size=1, 其参数量=1×1×4×8=32;
总参数量=36 + 32 = 68
参考博客:
https://blog.csdn.net/zfjBIT/article/details/127521956
https://zhuanlan.zhihu.com/p/490685194