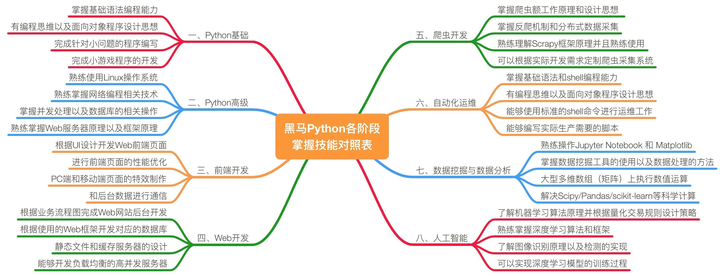
1 函数说明
DataFrame.sort_values(
by,
*,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last',
ignore_index=False,
key=None)2 参数说明
| by | string或者一组string组成的list,根据什么进行排序 |
| axis | {0 or ‘index’, 1 or ‘columns’} |
| ascending | 正序还是倒序 如果by是一组string组成的list,那么ascending可以是一个布尔型的变量,或者一组布尔型变量组成的list【分别对应by每个元素是正序还是倒序】 |
| inplace | 是否替换原来的DataFrame |
| kind | {‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’} |
| na_position | {‘first’, ‘last’} 把NaN放在开头还是结尾 |
| ignore_index | 如果True,那么最后的index就变成0~n-1,否则保持原样 |
3 举例
3.0 数据
# Visual Python: Data Analysis > File
iris_pd=pd.read_csv('https://raw.githubusercontent.com/visualpython/visualpython/main/visualpython/data/sample_csv/iris.csv')
iris_pd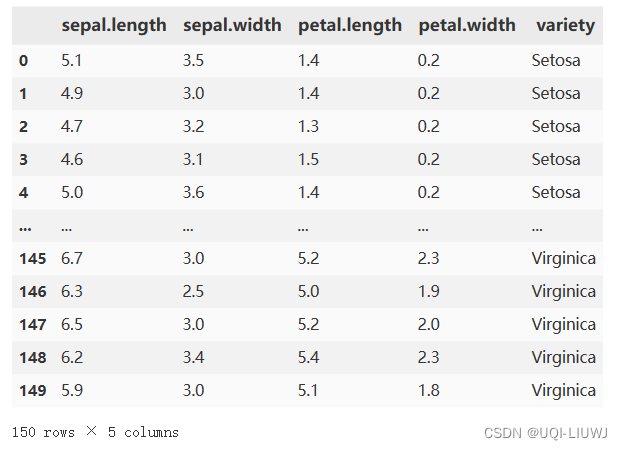
3.1 基本使用
iris_pd.sort_values(by=['sepal.length'])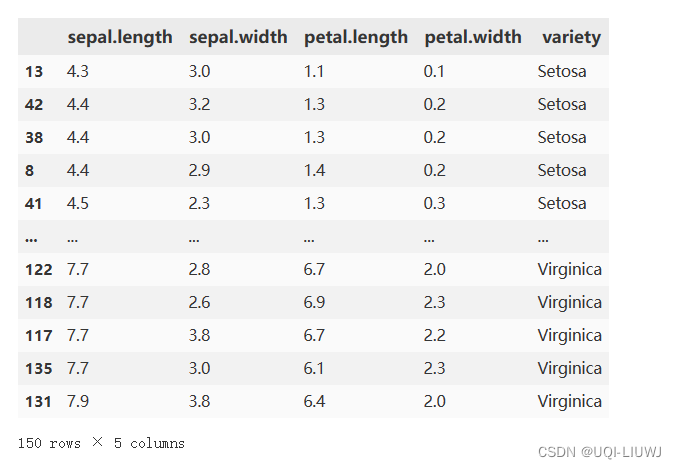
3.2 多个by
iris_pd.sort_values(by=['sepal.length','sepal.width'])
先按照sepal.length排序,sepal.length相同时按照sepal.width排序
3.3 ignore index
iris_pd.sort_values(by=['sepal.length','sepal.width'],ignore_index=True)