1.简介:
BloomFilter是一种多哈希函数映射的快速查找算法,它实际上是由一个超长的二进制位数组和一系列的哈希函数组成的。初始时二进制位数组全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1,当该元素经过哈希函数计算后会得到所有的偏移位置,若这些位置全都为1,则判断该元素在这个集合中,若有一个不为1,则判断该元素不在这个集合中。
由于BloomFilter是一组哈希函数映射出来的结果,因此通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合,BloomFilter有以下特点:
1.空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中;
2.对于一个元素检测是否存在的调用,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在;
3.缺点是存在误判,告诉你可能存在,不一定真实存在;
例如:
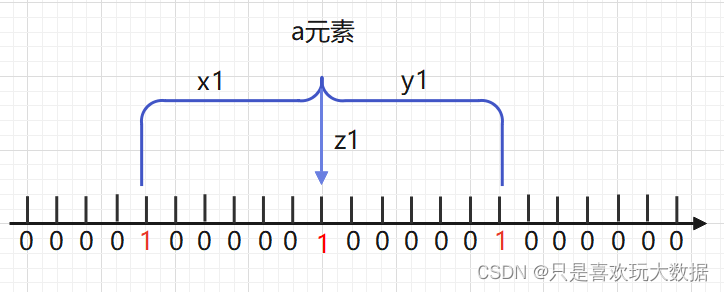
前提条件:一个集合中,包含一些元素(j,q,k…),这些元素通过3个不同的哈希函数(x1,y1,z1)映射在二进制数组的比特位上。
当a元素由x1,y1和z1三个不同哈希函数映射在二进制数组上时,映射后三个位置的数值都等于1,因此,a元素可能存在于这个集合中。
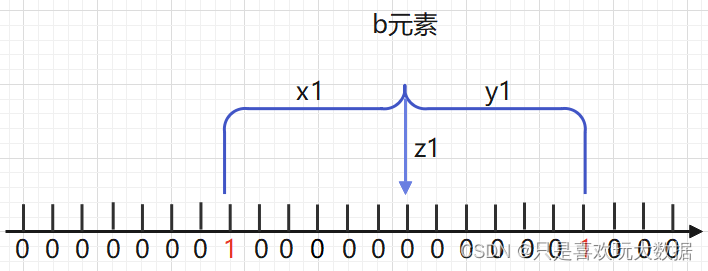
当b元素由x1,y1和z1三个不同哈希函数映射在二进制数组上时,映射后有一个位置的数值等于0,因此b元素一定不在这个集合中。
2.Doris BloomFilter索引的使用:
Doris会自动在底层尽可能的使用一些索引和过滤机制,优化执行计划。但同时我们也可以手动创建BloomFilter索引。Doris的BloomFilter索引可以通过建表的时候指定,也可以通过表的ALTER操作来完成。
2.1创建BloomFilter索引:
可以通过在建表语句的PROPERTIES里加上"bloom_filter_columns"="c1,c2,c3"属性来创建Doris BloomFilter索引。c1,c2,c3是你要创建的BloomFilter索引的Key列名称。
CREATE TABLE `ods_test_bloom_delta` (
`erdat` date NOT NULL COMMENT "",
`vbelv` varchar(20) NULL COMMENT "",
`posnv` varchar(10) NULL COMMENT "",
`vbeln` varchar(20) NULL COMMENT "",,
`city_org_code` varchar(20) NULL COMMENT "",
`create_time` datetime NULL COMMENT ""
) ENGINE=OLAP
UNIQUE KEY(`erdat`, `vbelv`)
COMMENT "test_bloom"
PARTITION BY RANGE(`erdat`)
(PARTITION P_000000 VALUES [('0000-01-01'), ('2023-01-01')),
PARTITION P_202301 VALUES [('2023-01-01'), ('2023-02-01')),
PARTITION P_202302 VALUES [('2023-02-01'), ('2023-03-01')),
PARTITION P_202303 VALUES [('2023-03-01'), ('2023-04-01')),
PARTITION P_202304 VALUES [('2023-04-01'), ('2023-05-01')),
PARTITION P_202305 VALUES [('2023-05-01'), ('2023-06-01')),
PARTITION P_202306 VALUES [('2023-06-01'), ('2023-07-01')))
DISTRIBUTED BY HASH(`vbelv`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"bloom_filter_columns"="posnv,vbeln",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "P_",
"dynamic_partition.replication_allocation" = "tag.location.default: 3",
"dynamic_partition.buckets" = "1",
"in_memory" = "false",
"storage_format" = "V2"
);
2.2修改BloomFilter索引
alter TABLE ods_test_bloom_delta SET ("bloom_filter_columns" = "city_org_code");
2.3删除BloomFilter索引
ALTER TABLE ods_test_bloom_delta SET ("bloom_filter_columns" = "");
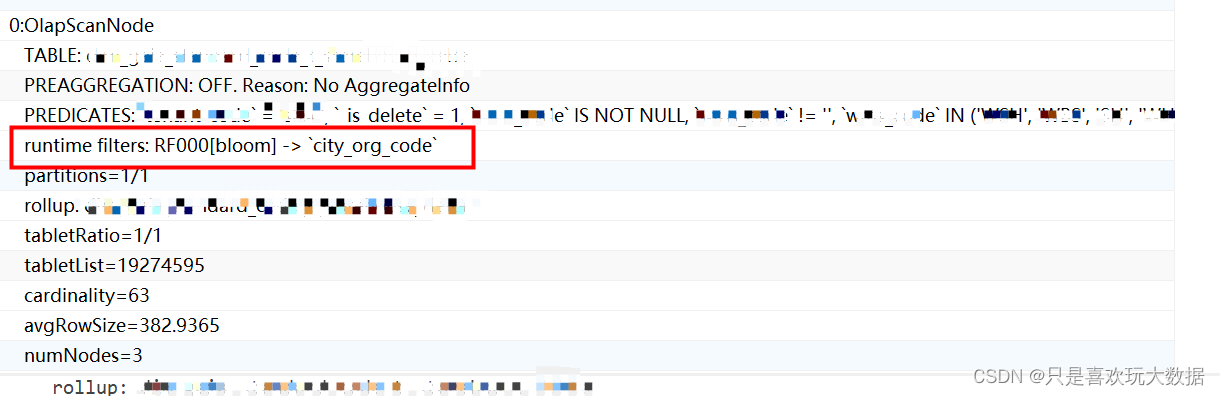
2.4根据执行计划查看是否使用了BloomFilter索引:
根据explain可以查看执行计划,如图所示就说明查询已经使用了bloomFilter;
3.Doris BloomFilter使用场景及注意事项:
应用场景:
满足以下几个条件时可以考虑对某列建立Bloom Filter 索引:
1.首先BloomFilter适用于非前缀过滤.
2.查询会根据该列高频过滤,而且查询条件大多是in和 = 过滤.
3.不同于Bitmap, BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如”性别“列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。
注意事项:
1.不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
2.Bloom Filter索引只对in和 = 过滤查询有加速效果。
3.如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看
4.最后:
欢迎指正。