网上经常盛传 大数据=sql boy,后端开发=crud boy,算法工程师=调参boy
在大数据领域也工作了好几年了,确实大数据开发,很多工作就是写sql,hive sql、spark sql、flink sql等等sql
一、背景:
但是经常有这样一个需求,一大段sql 跑出来之后,发现不是自己想要的结果?比如:
demo 1:
select id,name from (
select id,name from table1
union all
select id,name from table2
union all
select id,name from table3
union all
select id,name from table4
)t group by id,name
demo 2:
select a.id,a.name,a.class from (select id,name from table1 where id>=10) a left join (select name,class from table2 where name is not null)
b on a.name=b.name;比如说:
demo 1 中的sql 出来这样的结果数据
| id | name |
|---|---|
| 101 | xiaolan |
| 102 | xiaobing |
| 100 | xiaohong |
但是其中id为100的这条数据从业务逻辑上来看应该是被过滤掉的,但是实际却出来了,也就是代码实际运行结果和我们预期想的不一样
其实和c语言开发和java 开发类似,就是预期结果和代码实际结果不一致,一般在java开发或者c语言开发中,我们是通过打日志(print、log.debug )或者使用idea打断点进调试模式进行调试代码,一步一步查看中间结果,也称之为debug过程。

那么因此想到sql 实际运行结果和预期不符的时候能不能进行debug 调试呢?
二、大部分人的解决方案:
大部分数据开发者遇到这个问题,都是把sql 进行拆分,比如说demo 1 的sql拆分如下4个sql,分别对每个sql 进行运行判断100这个结果到底是哪个表产出的。
select id,name from table1 where id='100'
select id,name from table2 where id='100'
select id,name from table3 where id='100'
select id,name from table4 where id='100'或者稍微修改一下
select * from (
select id,name,flag from (
select id,name,'1' as flag from table1
union all
select id,name,'2' as flag from table2
union all
select id,name,'3' as flag from table3
union all
select id,name,'4' as flag from table4
)t group by id,name,flag )t1 where id='100'
三、最终方案:
那有没有一种方法,也能做到像和java或者c语言一样进行调试中间结果呢,也就是idea debug或者通过打印日志的方式?因此称呼sql 调试的过程为sql debug。
java 或者c 语言 开启debug 模式,需要打印日志或者配合idea 进行debug,本文先讲述怎么通过打印日志进行sql debug。
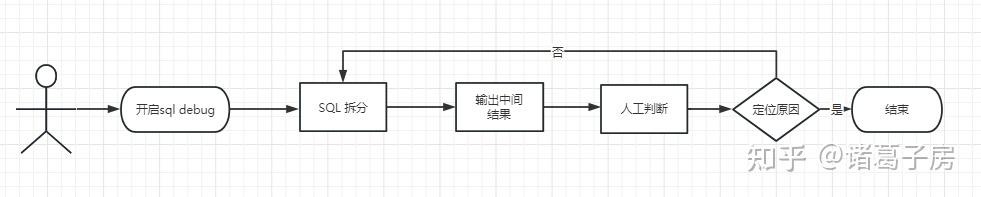
(1)开启debug 模式
(2)拆分sql
(3)输出中间结果
(4)人工判断中间结果是否正确定位原因
(5)重复2-4过程直到找到最终结果结束
举例:
select u,
max(tm),
p1
from
(
select device_id as u,unix_timestamp(dt,'yyyy-MM-dd')*1000 as tm,p1
from test.table1
where dt='2023-04-09' and length(trim(device_id))>0
union ALL
select device_id as u,unix_timestamp(dt,'yyyy-MM-dd')*1000 as tm,p1
from test.table2
where dt='2023-04-09' and length(trim(device_id))>0
union all
select device_id as u,unix_timestamp(dt,'yyyy-MM-dd')*1000 as tm,p1
from test.table3
where dt='2023-04-09' and length(trim(device_id))>0
) a
GROUP BY u,
p1(1)将这样一段sql 进行转换成语法树(如下图),这样就完成了sql解析和拆分(实际上更复杂的sql 也可进行快速拆分)

(2)将拆分出来的sql进行批量建表
(3)实际分析问题的时候,可以直接查询建的中间表数据
(4)分析完成之后需要自动删除建的中间表数据
![[java聊天室]服务器发送消息给客户端守护线程同步锁(三)](https://img-blog.csdnimg.cn/1a48c92bb29b438096f5174b9078882f.png)