【人工智能概论】 RNN、LSTM、GRU简单入门与应用举例
文章目录
- 【人工智能概论】 RNN、LSTM、GRU简单入门与应用举例
- 一. RNN简介
- 1.1 概念简介
- 1.2 方法使用简介
- 二. 编码层embedding
- 2.1 embedding的参数
一. RNN简介
1.1 概念简介
- 循环神经网络(Recurrent Neural Network)
- 理念上与CNN类似,都有权值共享的理念在,CNN是一个核扫空间,RNN是一个核扫时间。
- 具体点说RNN有点像是对线性层的复用。
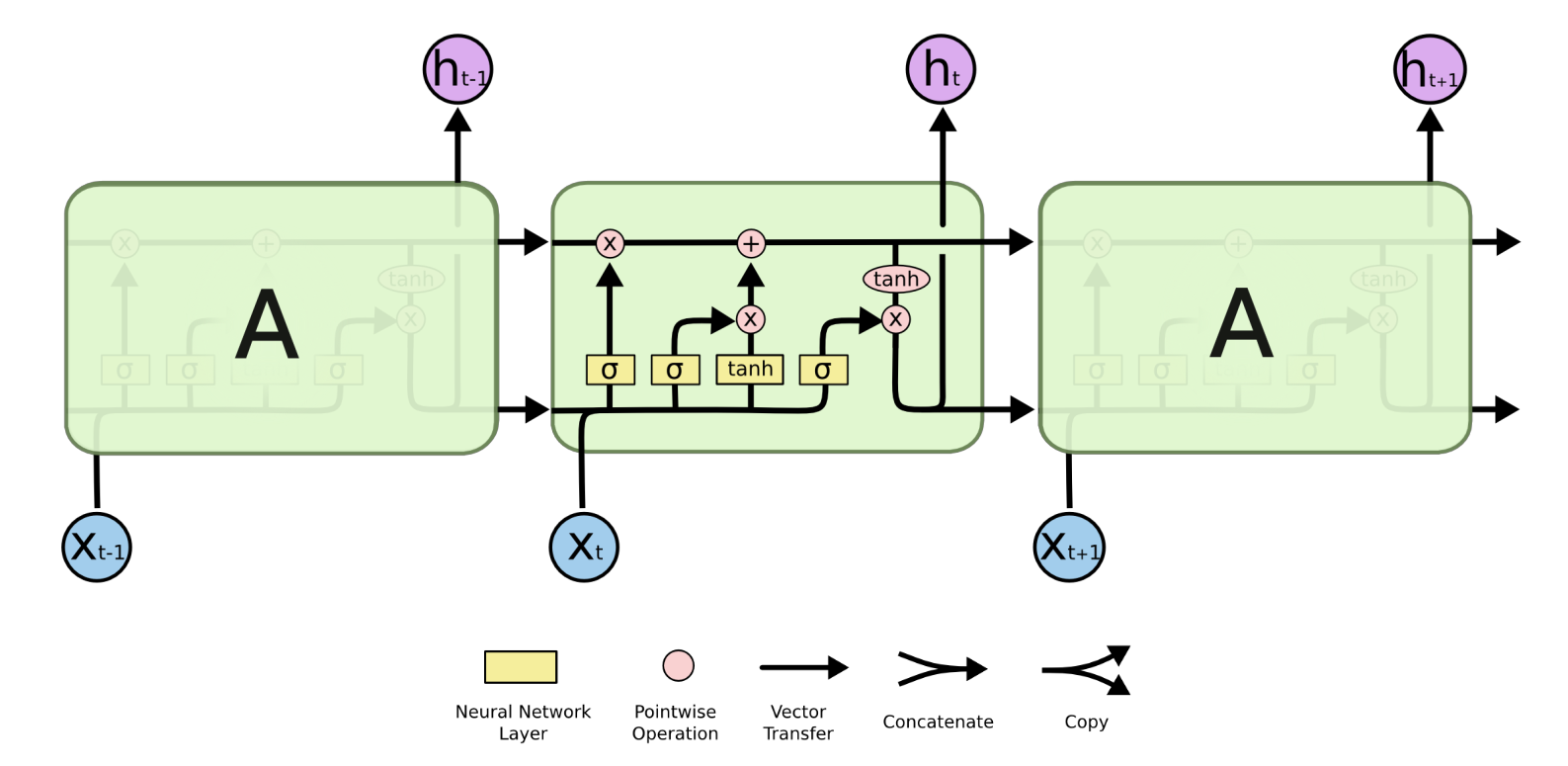
- RNN的结构展示:

- 每个时间步都会产生一个隐变量hi,hi会作为输入的一部分传给下一个时间步,hi会保存之前时间步里的信息。
1.2 方法使用简介
- 可以利用以下的组合实现构建一个RNN结构
RNN = torch.nn.RNN(input_size, hidden_size, num_layers)
outputs, hidden_n = RNN(inputs, hidden_0)
- 其中:
- input_size可以理解为词编码的维度,hidden_size是隐变量的维度,num_layers是RNN的堆叠层数;
- 为了每次输入的都是同一时间步的数据,inputs的形状为
(seqlen,batch_size,input_size);- hidden_0指的是初始隐变量h0,它是个先验数据,不知道不妨全给0,其形状为(num_layers,batch_size,hidden_size);
- outputs是所有时间步产生的隐变量,其尺寸为(seqlen,batch_size,hidden_size);
- hidden_n是最后一个时间步的隐变量hn,其尺寸为(num_layers,batch_size,hidden_size)。
二. 编码层embedding
2.1 embedding的参数
nn.Embedding((num_embeddings,embedding_dim)
- num_embeddings代表词典大小尺寸,比如训练时所可能出现的词语一共5000个词,那么就有num_embedding=5000;
- embedding_dim表示嵌入向量的维度,即用一个多少维的向量来表示一个符号。
- 是一个lookup table,存储了固定大小的dictionary(的word embeddings)。输入是indices,来获取指定indices的word embedding向量。(指定字典大小后,根据索引编号进行查表)
- (1)把从单词到索引的映射存储在word_to_idx的字典中。(2)索引embedding表时,必须使用torch.LongTensor(因为索引是整数)
- 其实就是按index取词向量!
- 其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。输入为一个编号列表,输出为对应的符号嵌入向量列表。
- nn.embedding的输入只能是编号,不能是隐藏变量,比如one-hot,或者其它,这种情况,可以自己建一个自定义维度的线性网络层,参数训练可以单独训练或者跟随整个网络一起训练(看实验需要)
- 下面那仨都看看 其实主要就是用法,别的也无所谓
 - 满足这个形式就可以做维度变换,因此RNN的三维数据也可以直接通过线性层,前N-1维一致即可
- 满足这个形式就可以做维度变换,因此RNN的三维数据也可以直接通过线性层,前N-1维一致即可
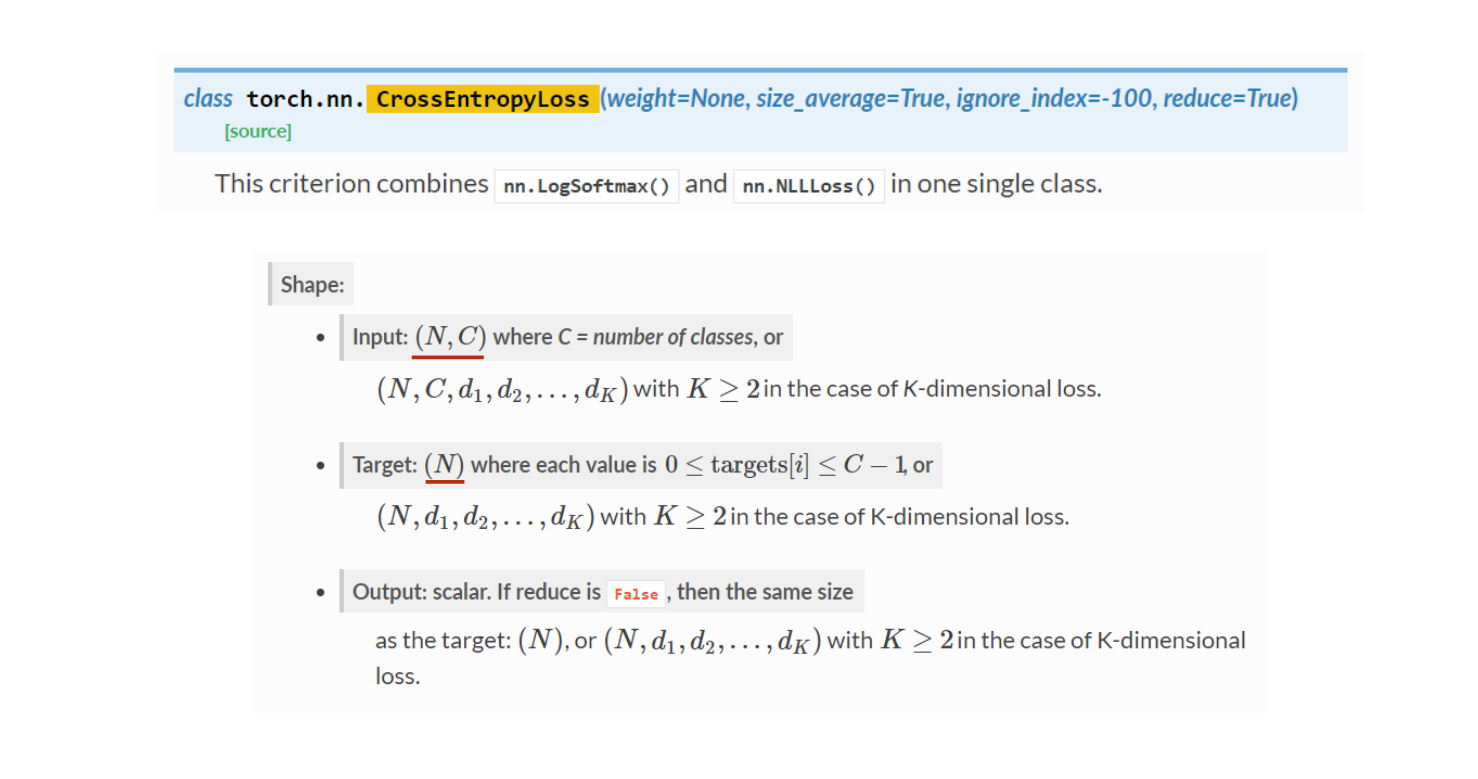 - 保障交叉熵的第一个输入是二维的且dim=1的维度上数量是classnum第二个输入target是一维的且与input的dim=0的尺寸一致,
- 保障交叉熵的第一个输入是二维的且dim=1的维度上数量是classnum第二个输入target是一维的且与input的dim=0的尺寸一致,
- 搞清楚它俩的尺寸关系,有助于高分类,为什么直接把x输入线性层就能得到所有的线性映射,因为只看第一个和最后一个。

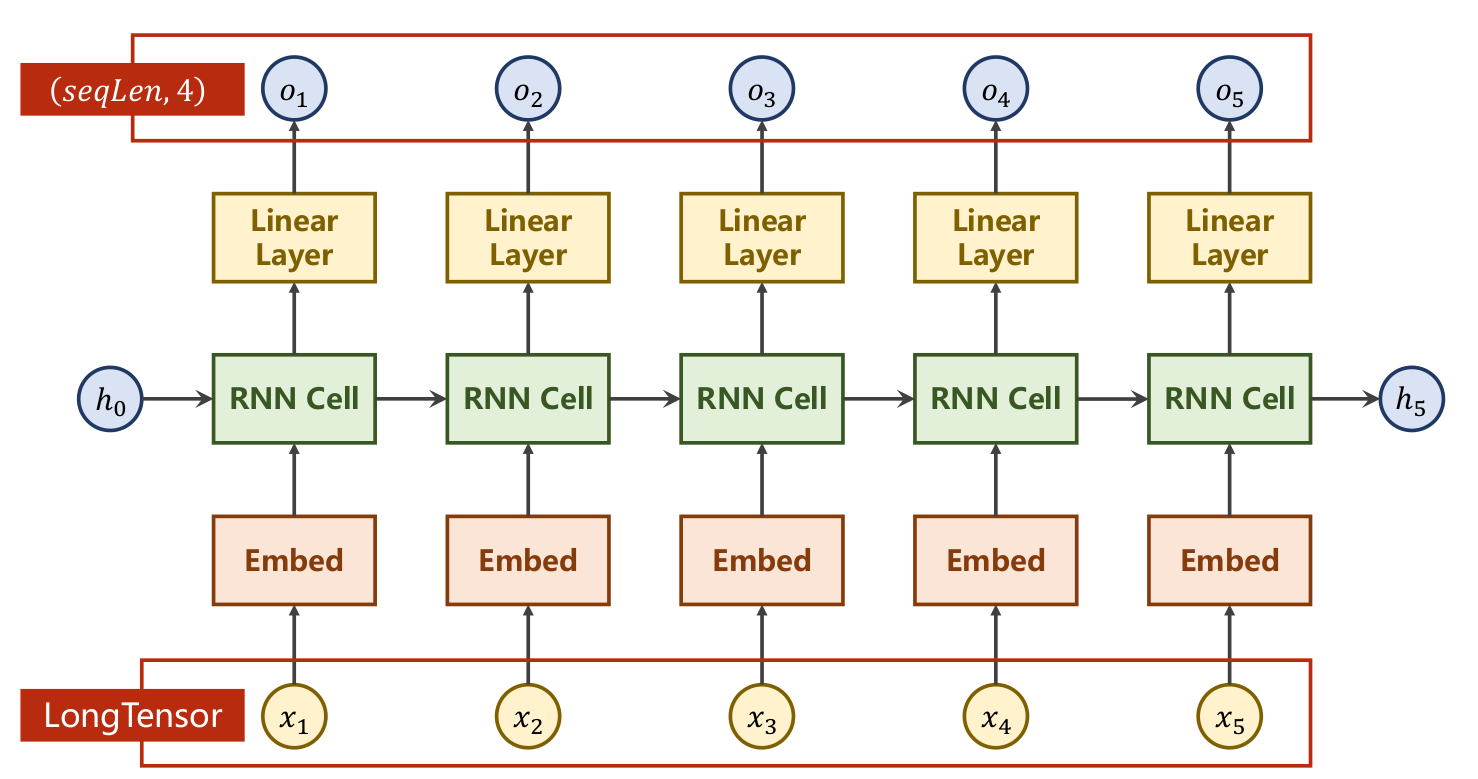
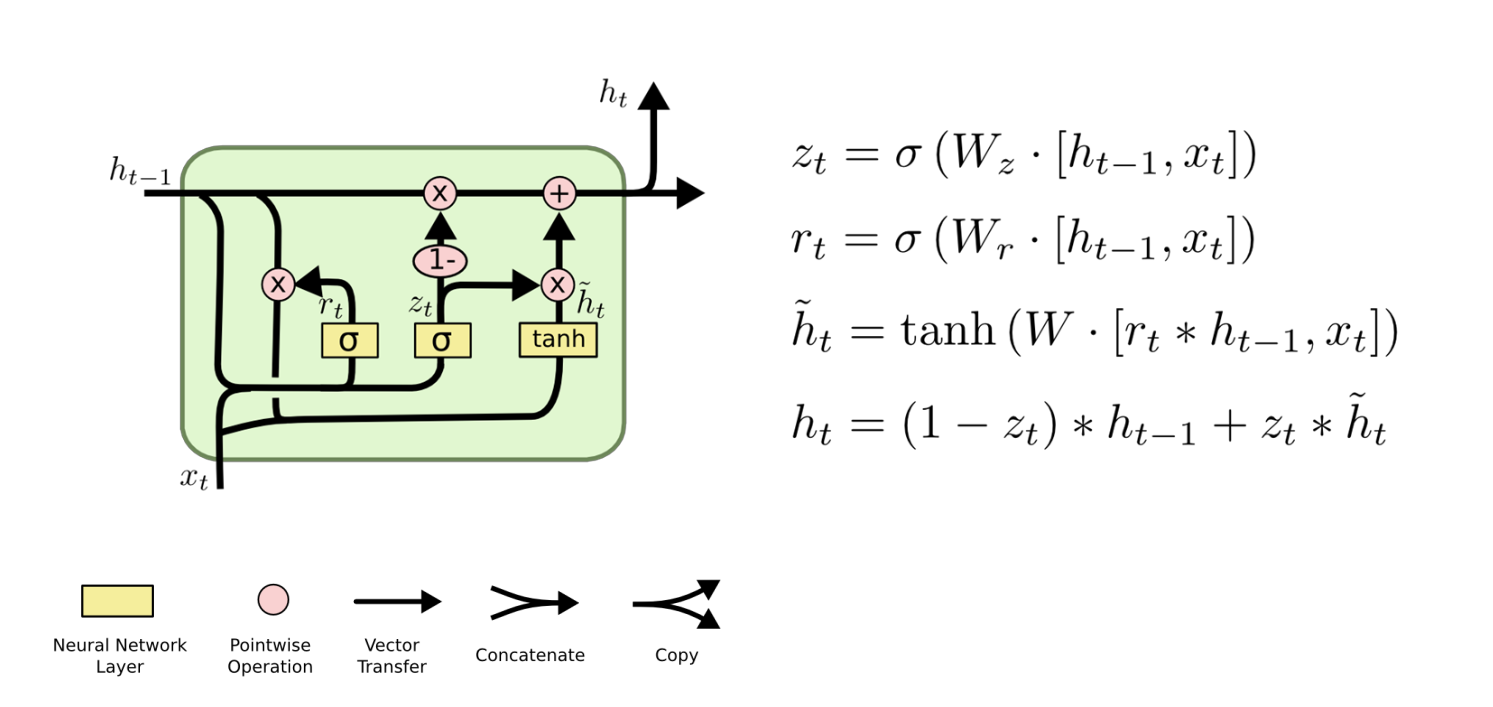
lstm gru的思路也是类似的,只不过更复杂一点,它俩效果差不多,但是gru的计算量小。

- 双向LSTM就是正向反向各做一次,然后做拼接



每一组,若干特征,若干组(有时序)用于预测一件事,如是否下雨,不是对特征的预测