来源:投稿 作者:王老师
编辑:学姐
目标检测-预训练相关

论文标题:DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
论文链接: https://arxiv.org/abs/2304.04514
代码链接:暂未开源
作者单位:香港科技大学 & 华为诺亚方舟实验室 & 中山大学
发表于CVPR 2023
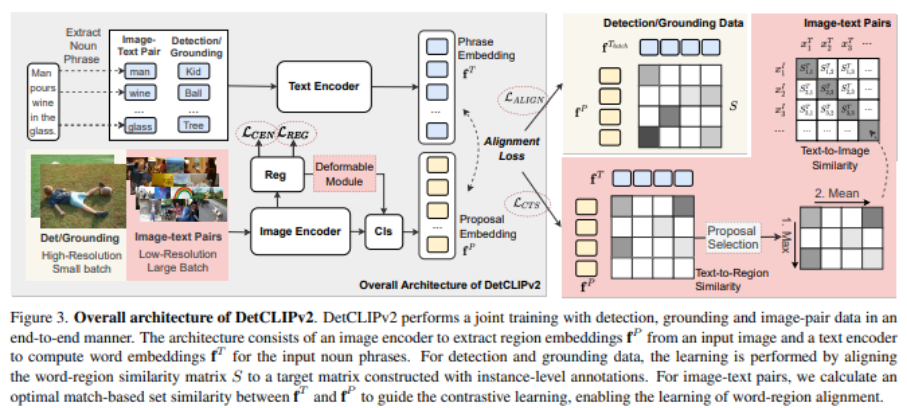
本文提出了DetCLIPv2,这是一个高效且可扩展的训练框架,它结合了大规模的图像-文本对来实现开放词汇对象检测(open-vocabulary object detection,OVD)。与以前的OVD框架不同,它们通常依赖于预先训练的视觉语言模型(例如CLIP)或通过伪标记过程利用图像-文本对,DetCLIPv2以端到端的方式直接从海量图像-文本配对中学习细粒度的单词区域对齐。为了实现这一点,我们在区域建议和文本单词之间使用最大单词区域相似性来指导对比目标。为了使模型能够在学习广泛概念的同时获得定位能力,DetCLIPv2在统一的数据公式下通过检测、基础和图像-文本对数据的混合监督进行训练。通过使用交替方案进行联合训练,并对图像-文本对采用低分辨率输入,DetCLIPv2高效利用图像-文本配对数据:在相似的训练时间下,DetCLIPv2比DetCLIP多使用13倍的图像-文本对数,并提高了性能。DetCLIPv2拥有1300万个图像-文本对用于预训练,显示出卓越的开放词汇检测性能,例如,具有Swin-T主干的DetCLIPv2在LVIS基准上实现40.4%的零样本AP,这分别比以前的作品GLIP/GLIPv2/DetCLIP高14.4/11.4/4.5%的AP,甚至大大超过了其完全监管的同类产品。

目标检测-半监督相关

论文标题:SOOD: Towards Semi-Supervised Oriented Object Detection
论文链接: https://arxiv.org/abs/2304.04515
代码链接:https://github.com/HamPerdredes/SOOD
作者单位:华中科技大学 & 百度
发表于CVPR 2023
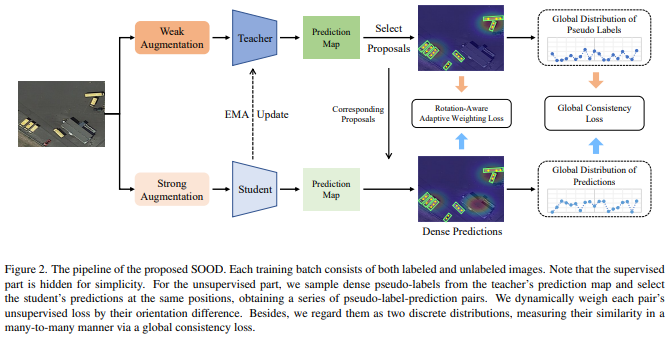
半监督对象检测(Semi-Supervised Object Detection, SSOD)旨在探索未标记的数据,以增强对象检测器,近年来已成为一项积极的任务。然而,现有的SSOD方法主要关注水平物体,而航空图像中常见的多向物体尚未被探索。本文在主流伪标记框架的基础上,提出了一种新的半监督面向对象检测模型SOOD。针对空中场景中的定向对象,我们设计了两个损失函数,以提供更好的监督。关注对象的方向,第一损失利用基于其方向间隙的自适应权重来正则化每个伪标签预测对(包括预测及其对应的伪标签)之间的一致性。关注图像的布局,第二个损失正则化了相似性,并明确地建立了伪标签集和预测集之间的多对多关系。这样的全局一致性约束可以进一步促进半监督学习。我们的实验表明,当用两种拟议的损失进行训练时,在DOTA-1.5基准的各种设置下,SOOD超过了最先进的SSOD方法。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“CVPR”获取CV方向顶会必读论文
码字不易,欢迎大家点赞评论收藏!