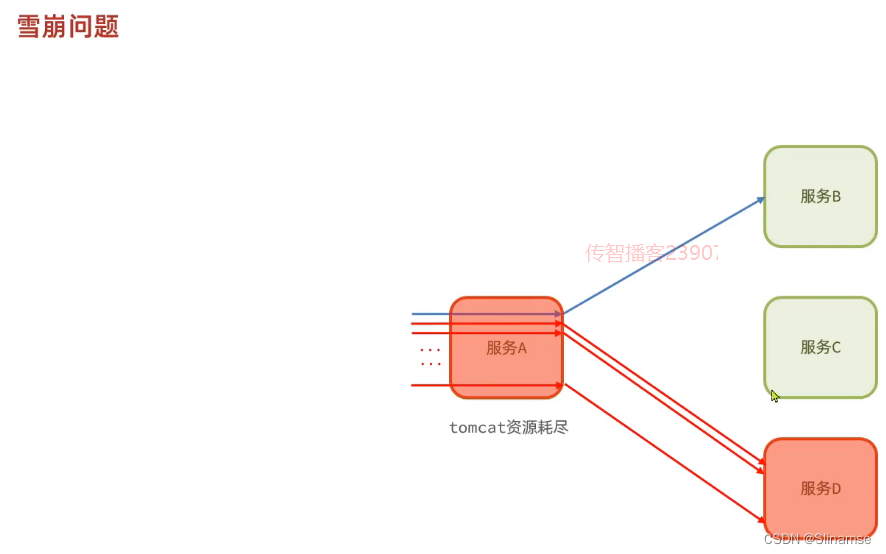
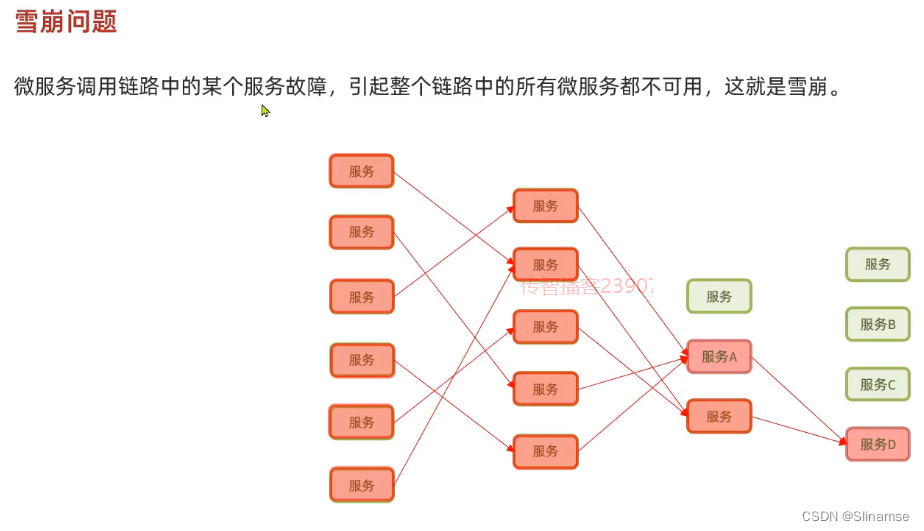
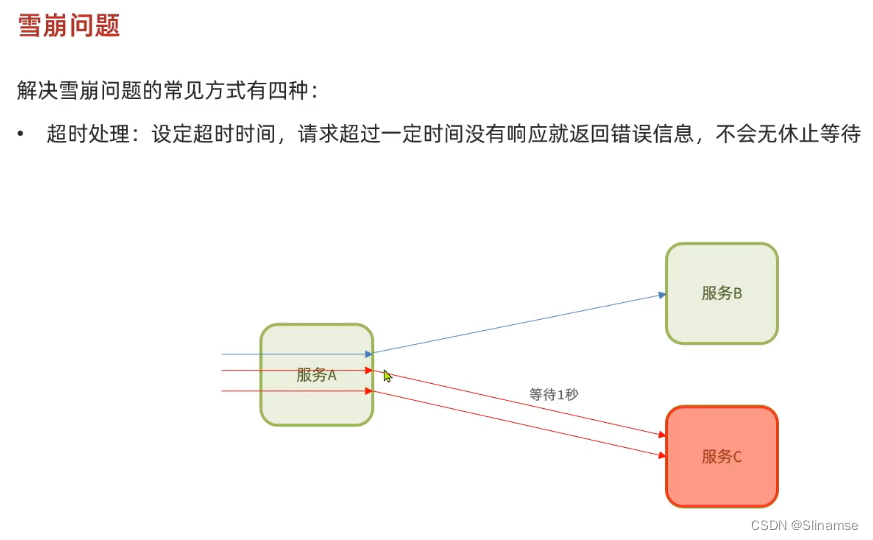
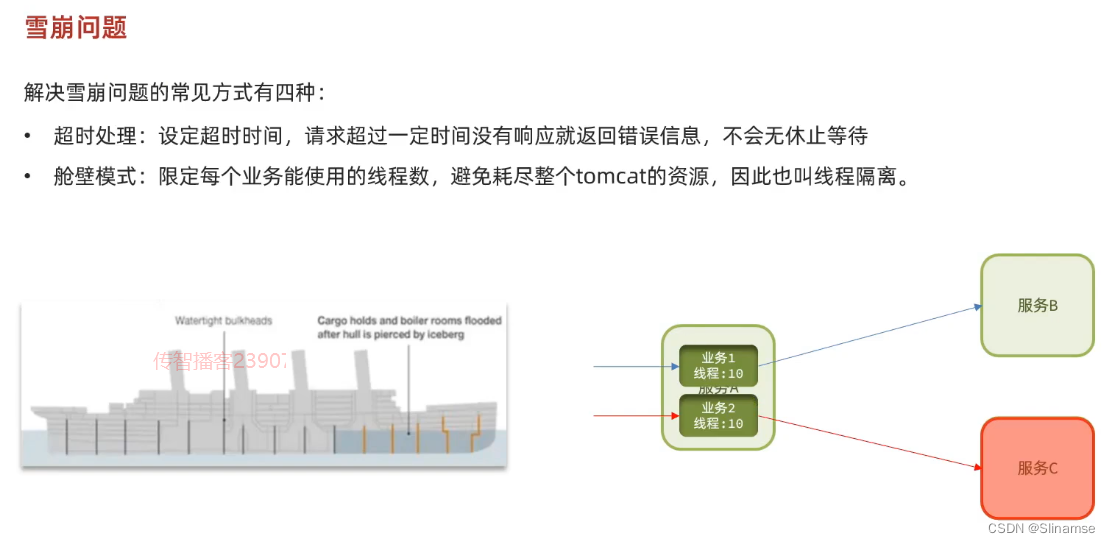




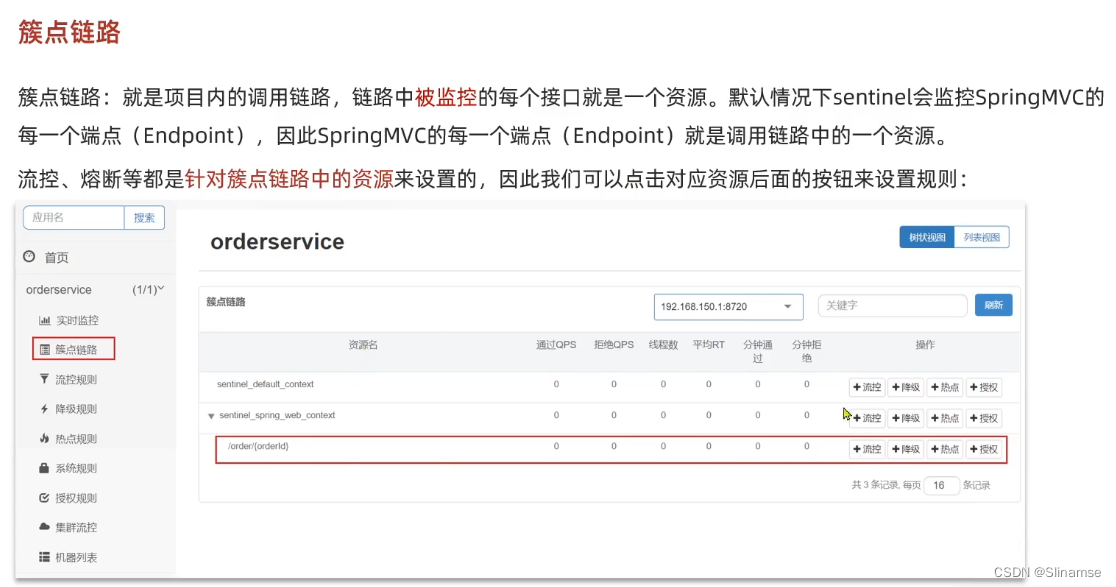
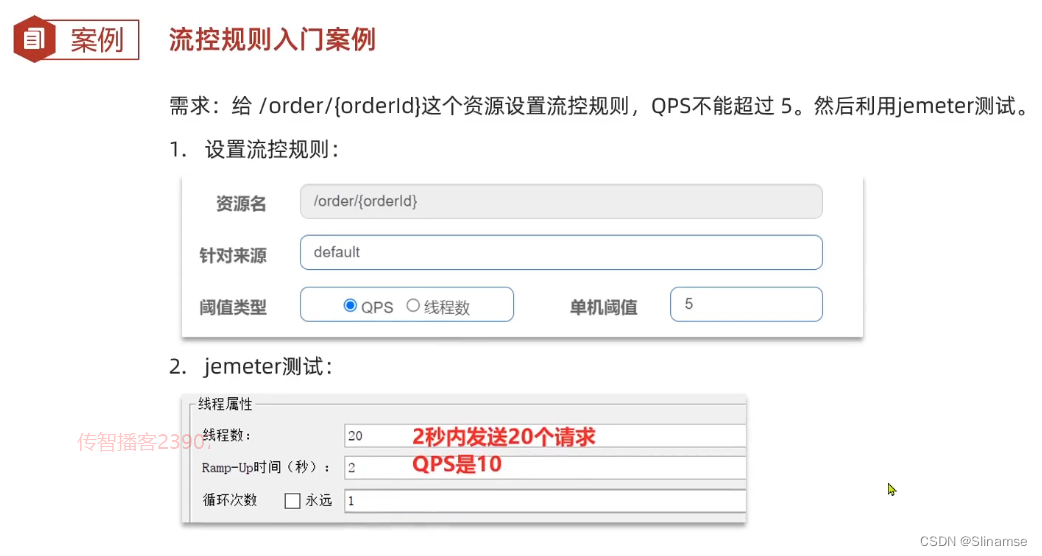
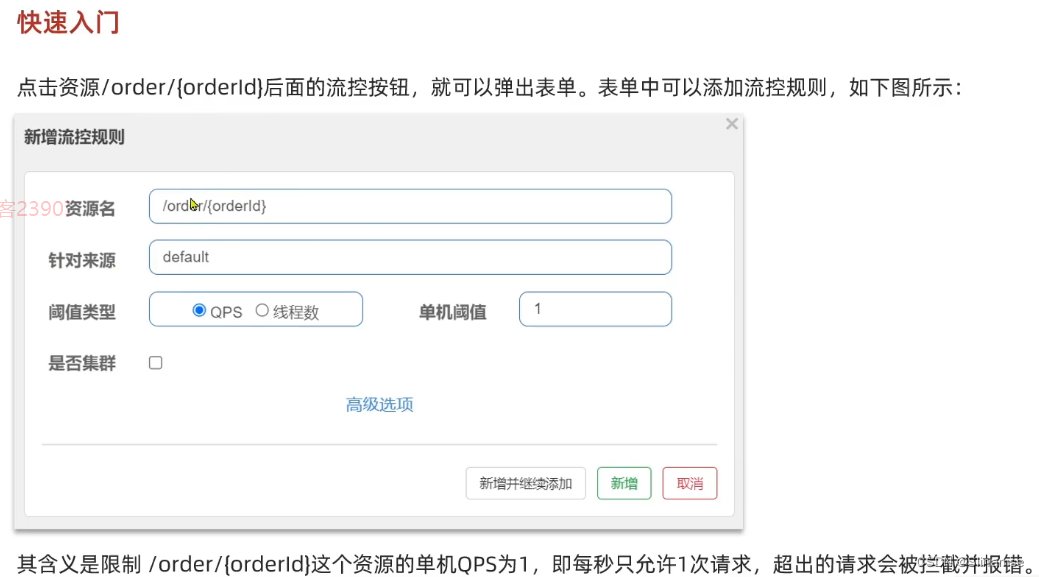
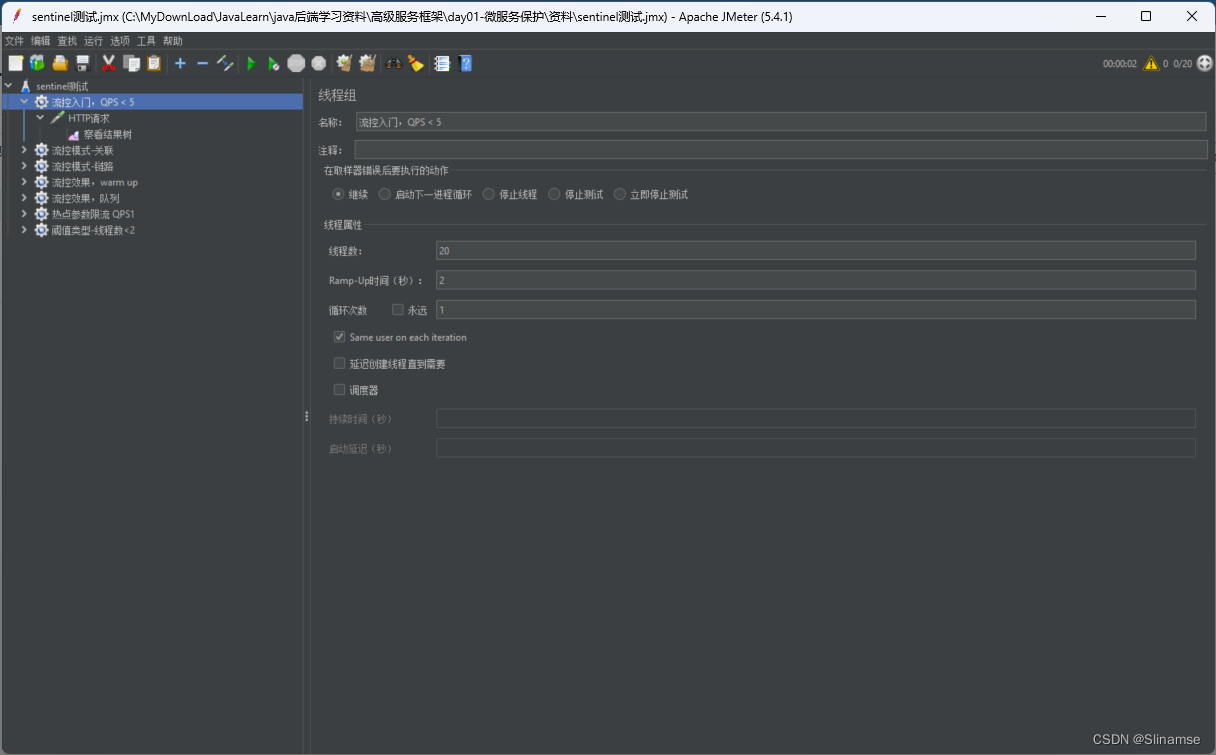


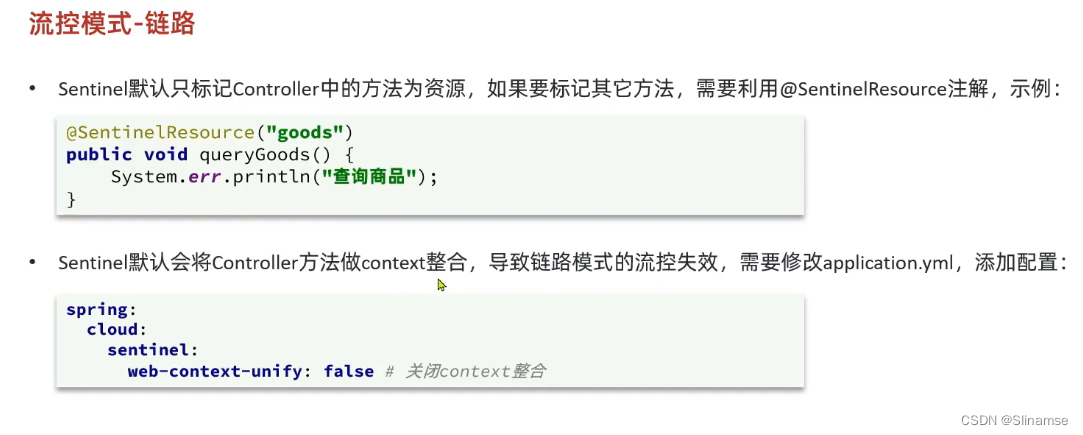
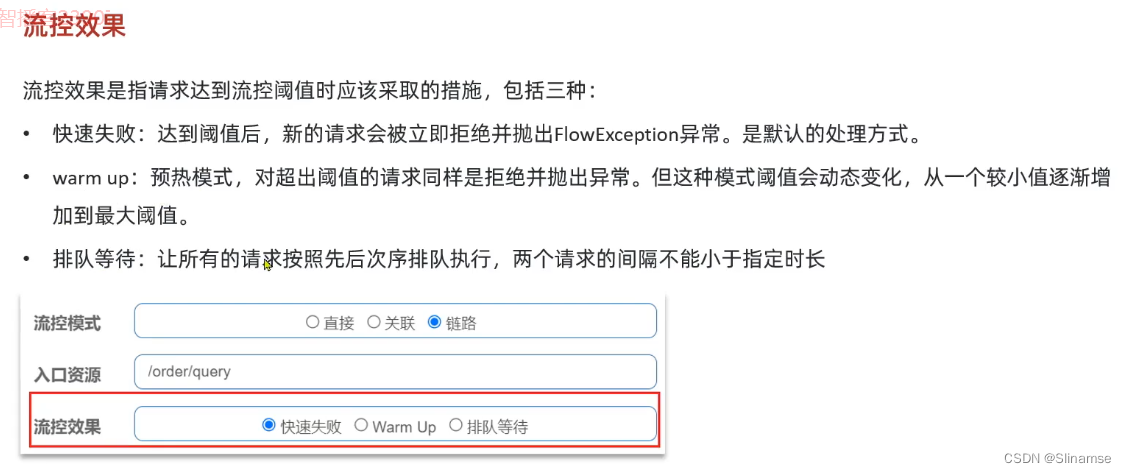


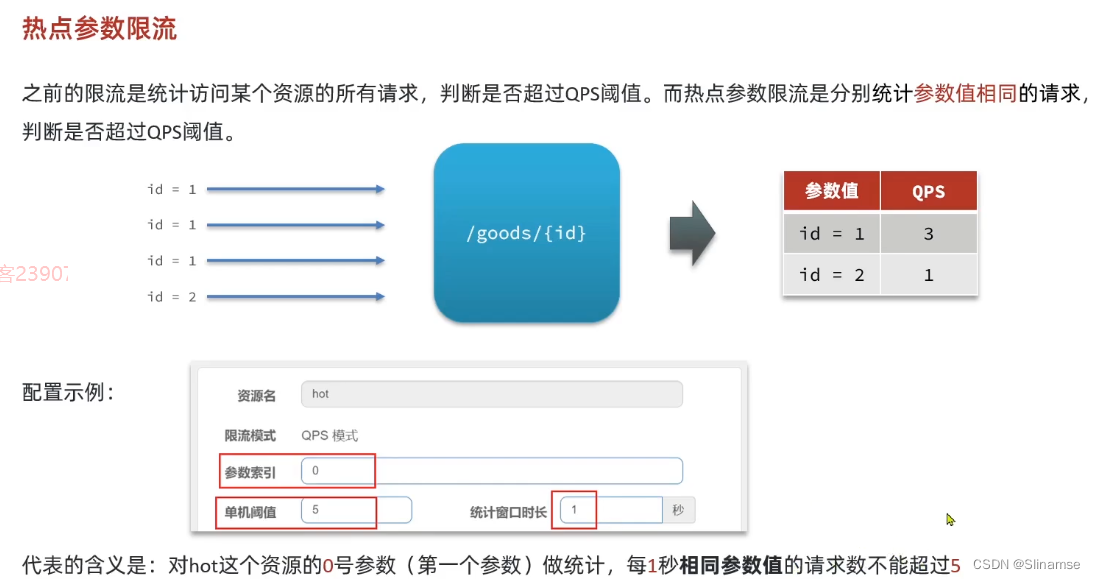
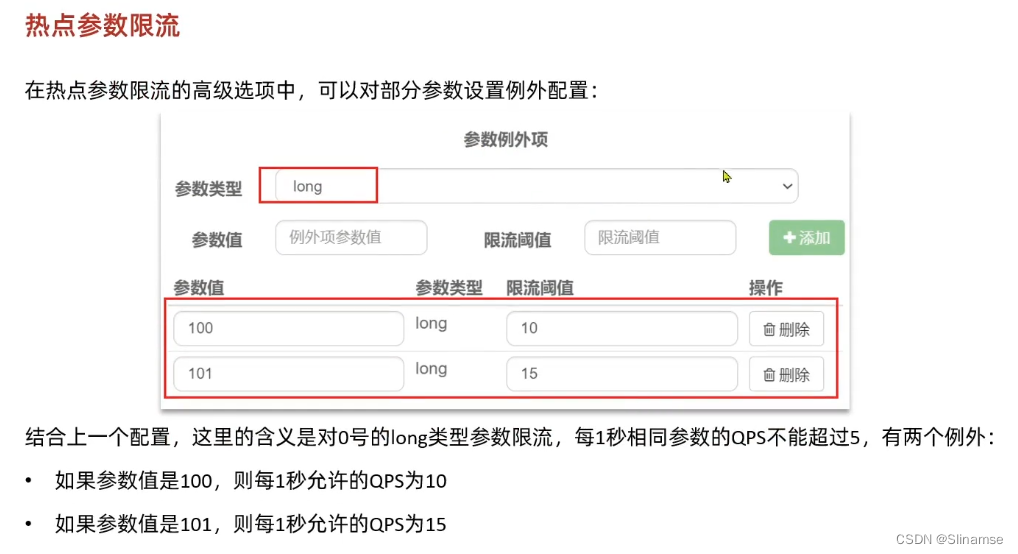
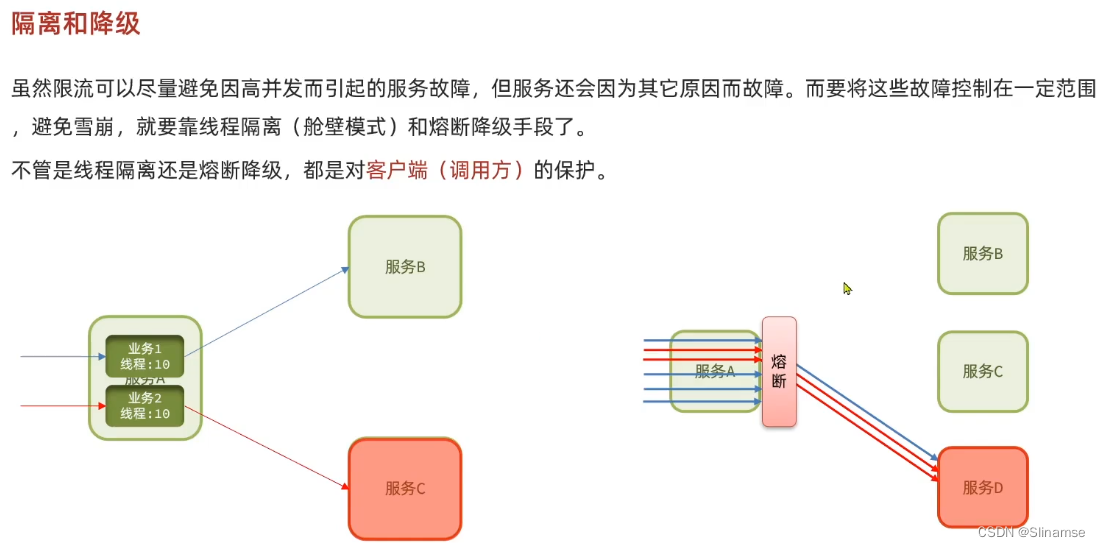

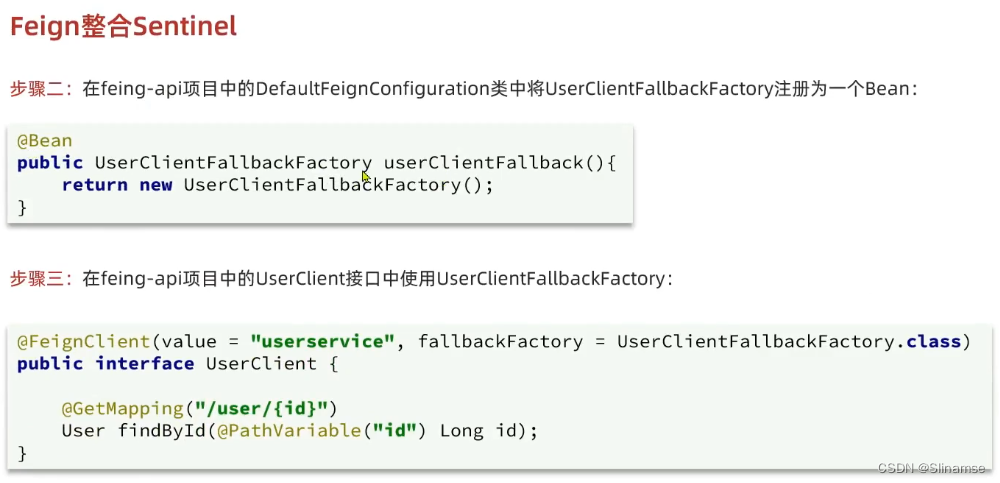
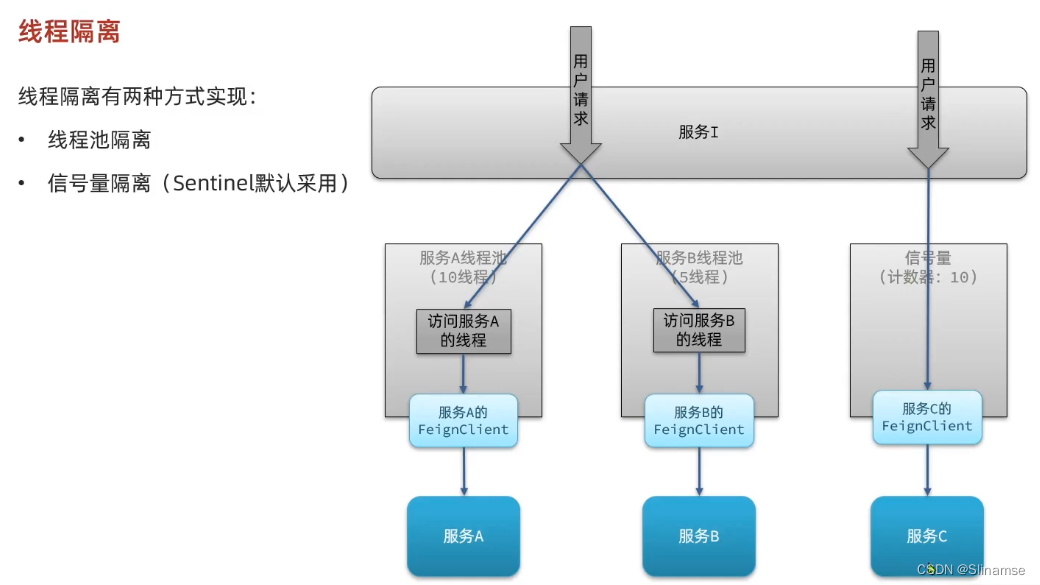
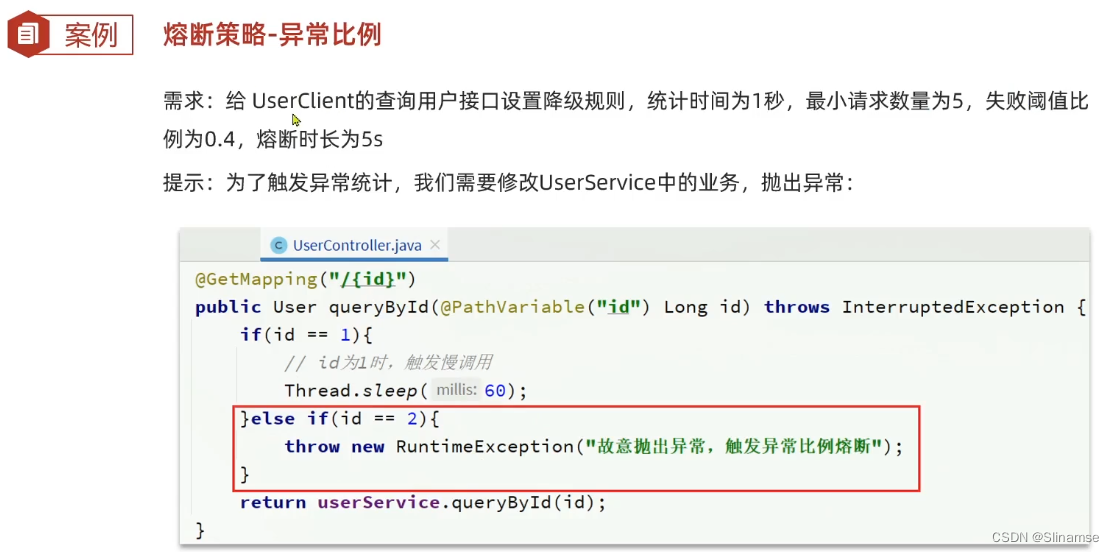
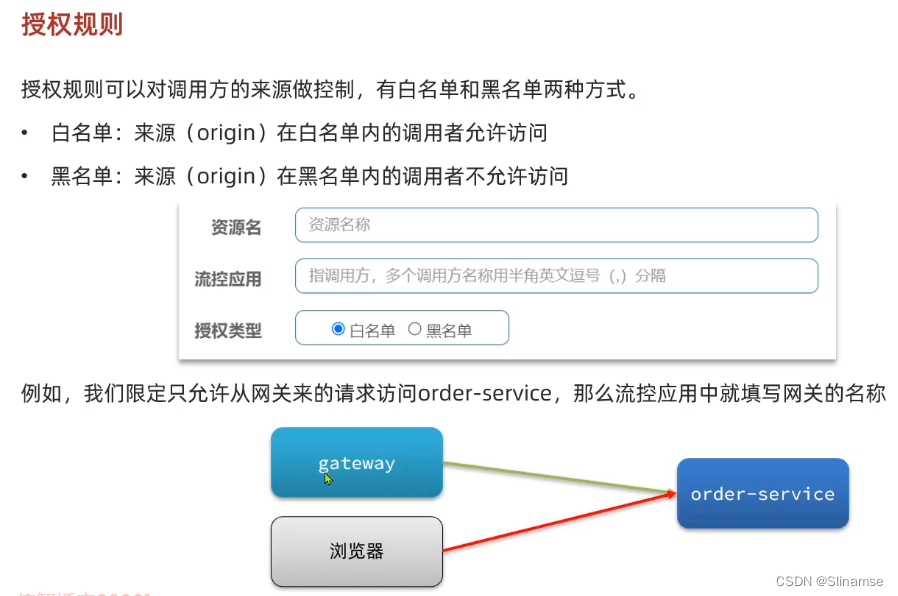
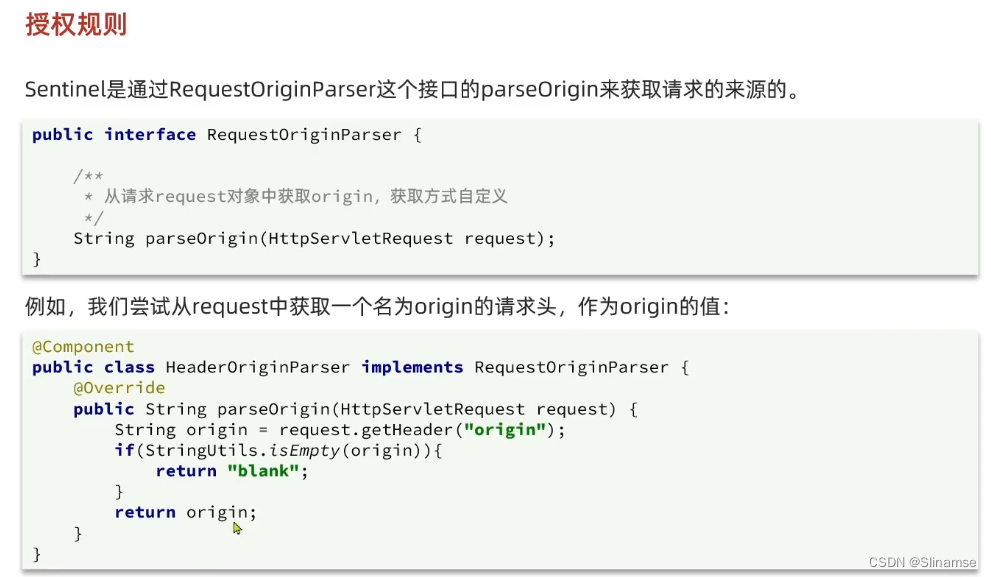
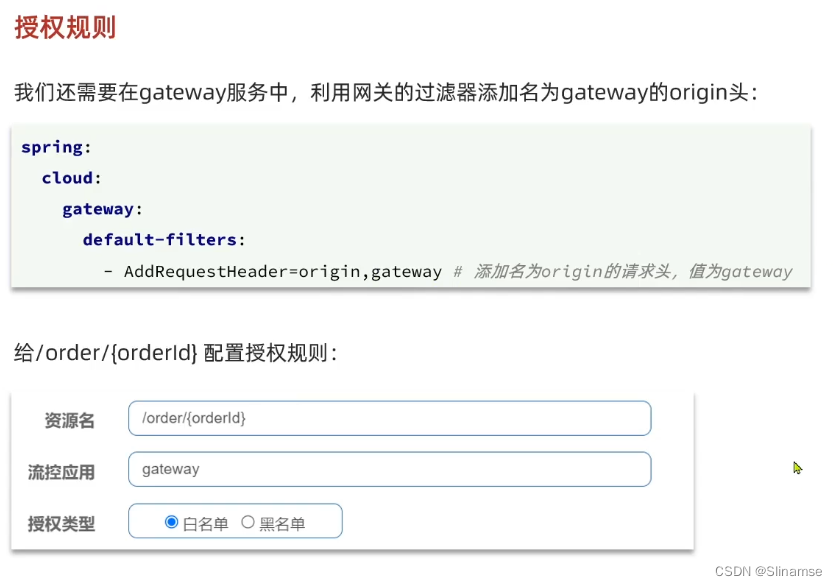



一、修改order-service服务
修改OrderService,让其监听Nacos中的sentinel规则配置。
具体步骤如下:
1.引入依赖
在order-service中引入sentinel监听nacos的依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>2.配置nacos地址
在order-service中的application.yml文件配置nacos地址及监听的配置信息:
spring:
cloud:
sentinel:
datasource:
flow:
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-flow-rules
groupId: SENTINEL_GROUP
rule-type: flow # 还可以是:degrade、authority、param-flow二、修改sentinel-dashboard源码
SentinelDashboard默认不支持nacos的持久化,需要修改源码。
1. 解压
解压课前资料中的sentinel源码包:

然后并用IDEA打开这个项目,结构如下:
2. 修改nacos依赖
在sentinel-dashboard源码的pom文件中,nacos的依赖默认的scope是test,只能在测试时使用,这里要去除:

将sentinel-datasource-nacos依赖的scope去掉:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>3. 添加nacos支持
在sentinel-dashboard的test包下,已经编写了对nacos的支持,我们需要将其拷贝到main下。
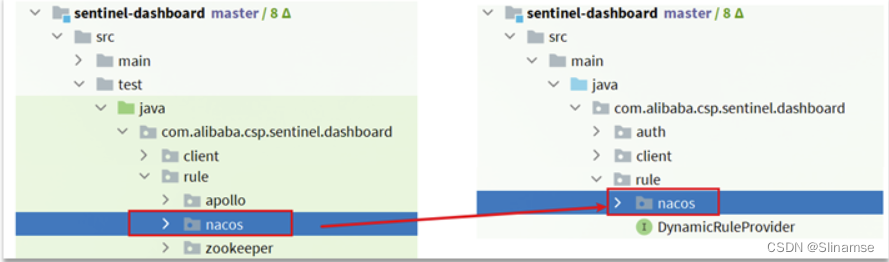
4. 修改nacos地址
然后,还需要修改测试代码中的NacosConfig类:

修改其中的nacos地址,让其读取application.properties中的配置:
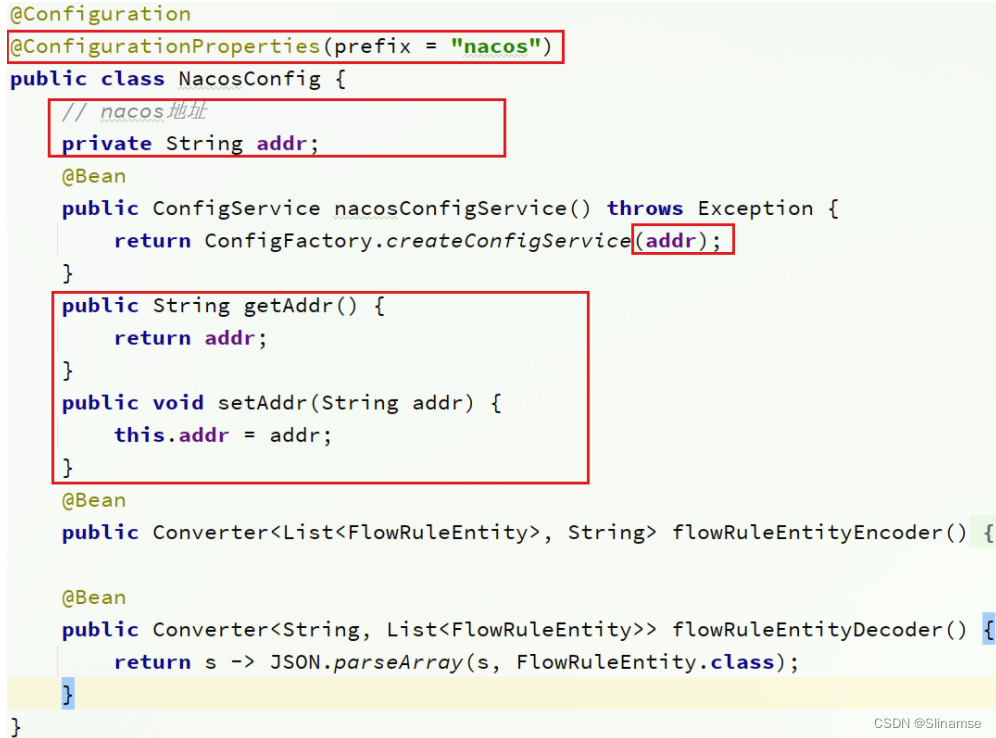
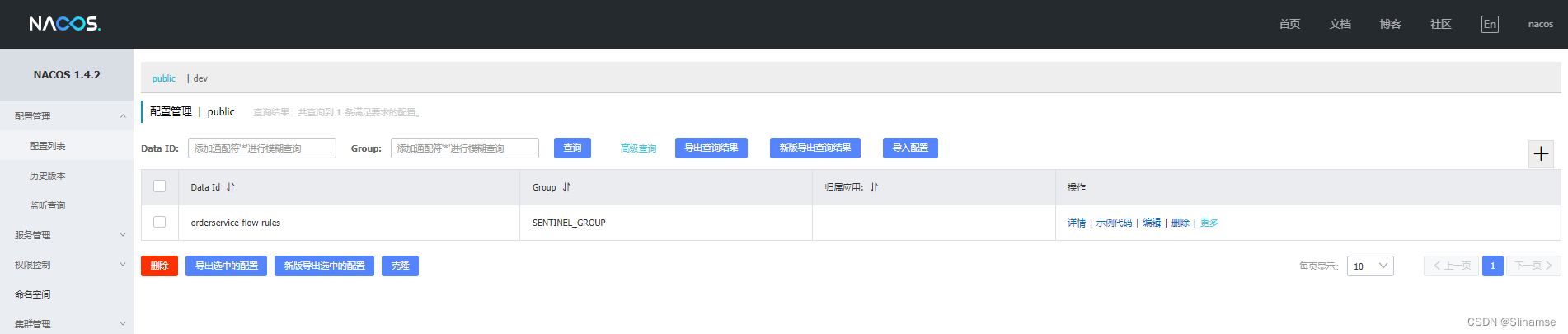
在sentinel-dashboard的application.properties中添加nacos地址配置:
nacos.addr=localhost:88485. 配置nacos数据源
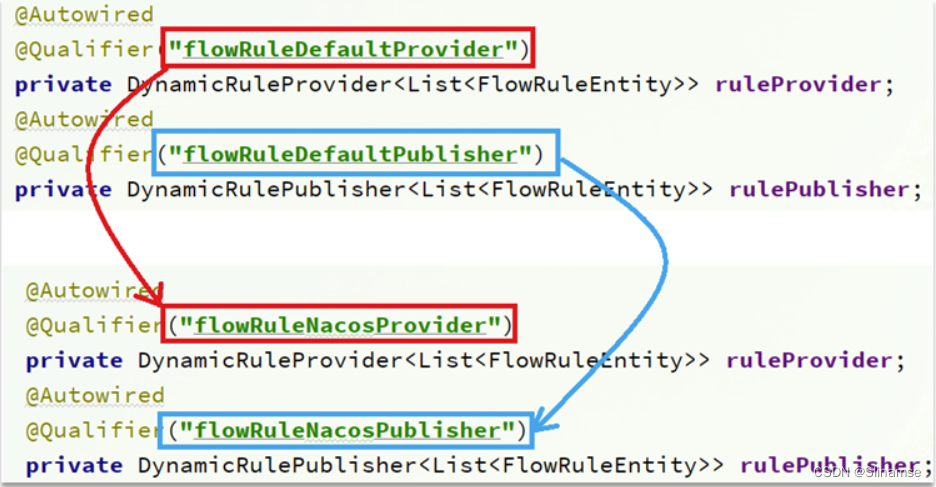
另外,还需要修改com.alibaba.csp.sentinel.dashboard.controller.v2包下的FlowControllerV2类:
 让我们添加的Nacos数据源生效:
让我们添加的Nacos数据源生效:
6. 修改前端页面
接下来,还要修改前端页面,添加一个支持nacos的菜单。
修改src/main/webapp/resources/app/scripts/directives/sidebar/目录下的sidebar.html文件:
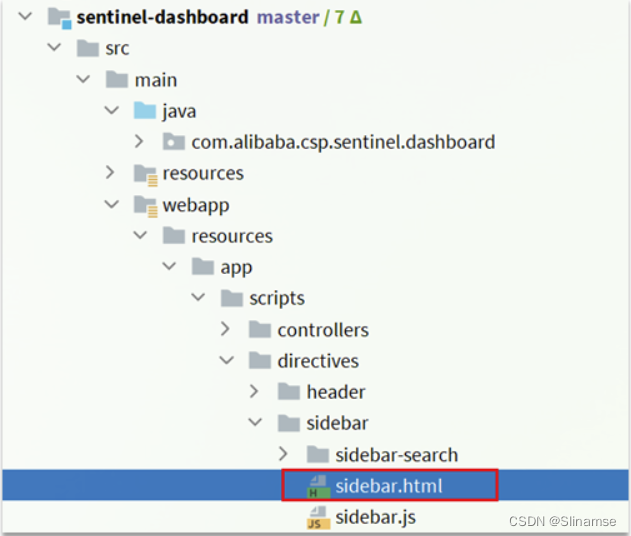
将其中的这部分注释打开:

修改其中的文本:

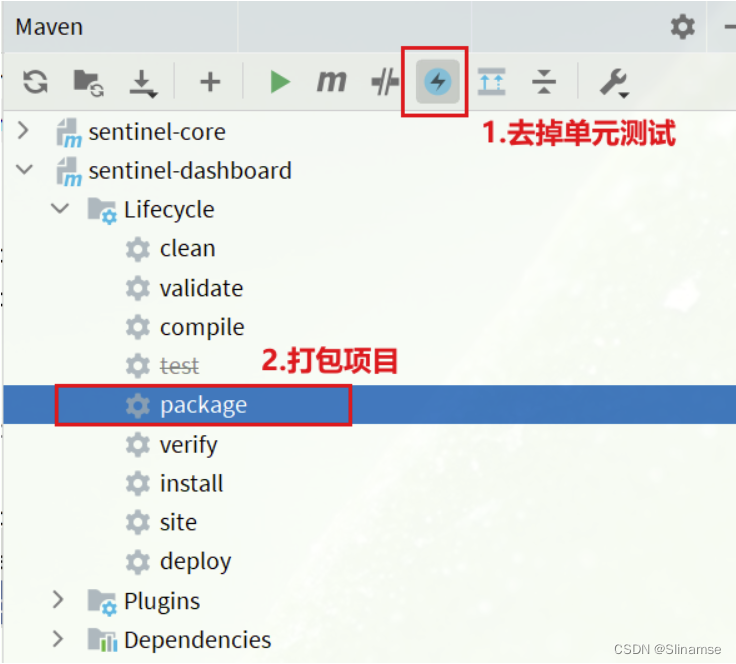
7. 重新编译、打包项目
运行IDEA中的maven插件,编译和打包修改好的Sentinel-Dashboard:
8.启动
启动方式跟官方一样:
java -jar sentinel-dashboard.jar如果要修改nacos地址,需要添加参数:
java -jar -Dnacos.addr=localhost:8848 sentinel-dashboard.jar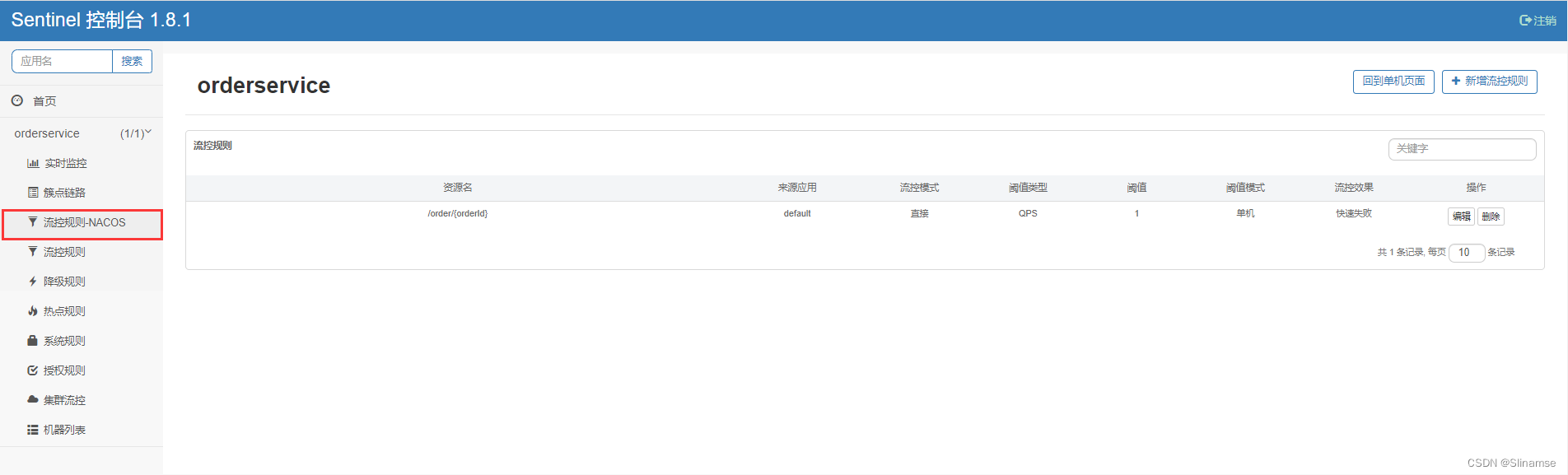

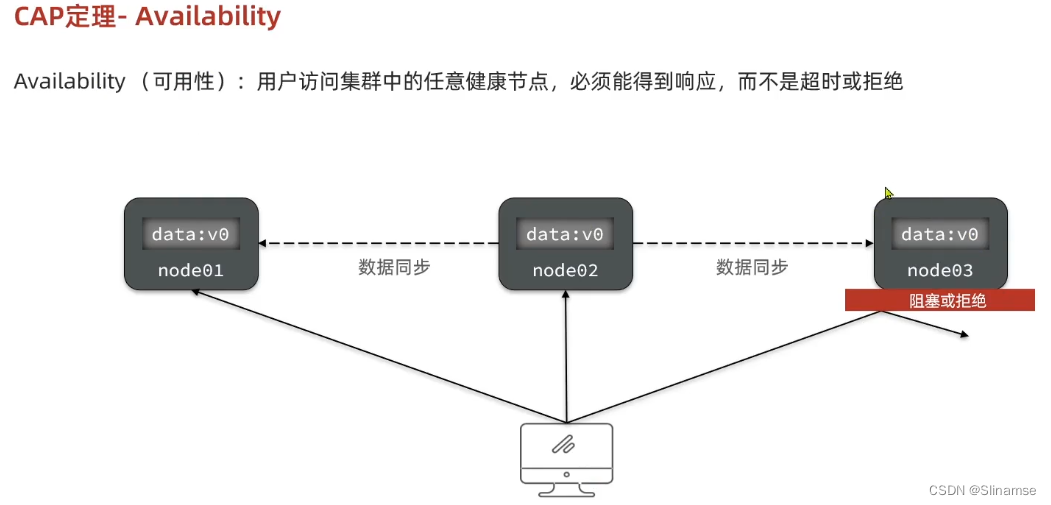
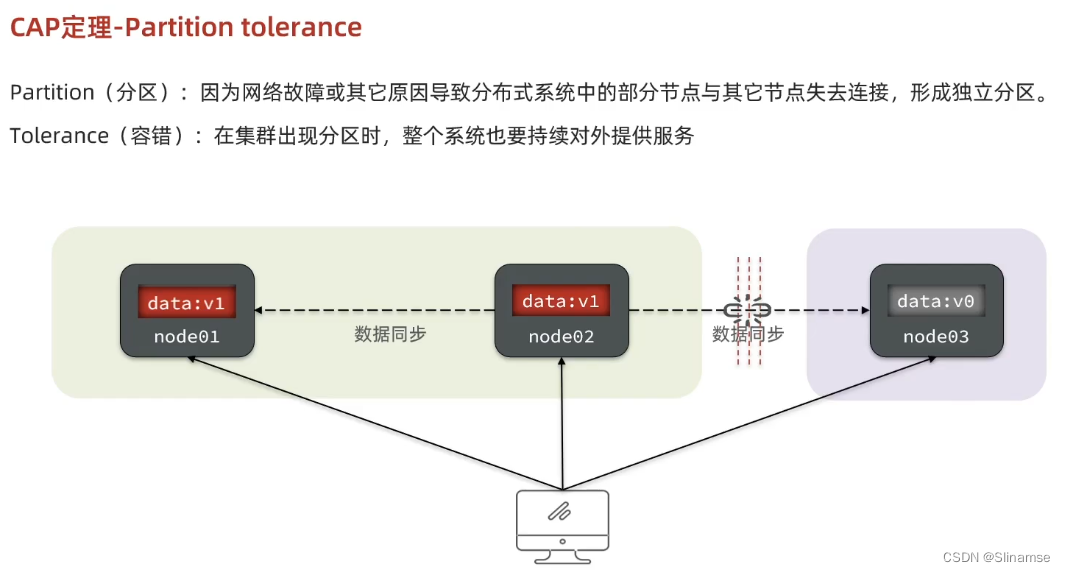

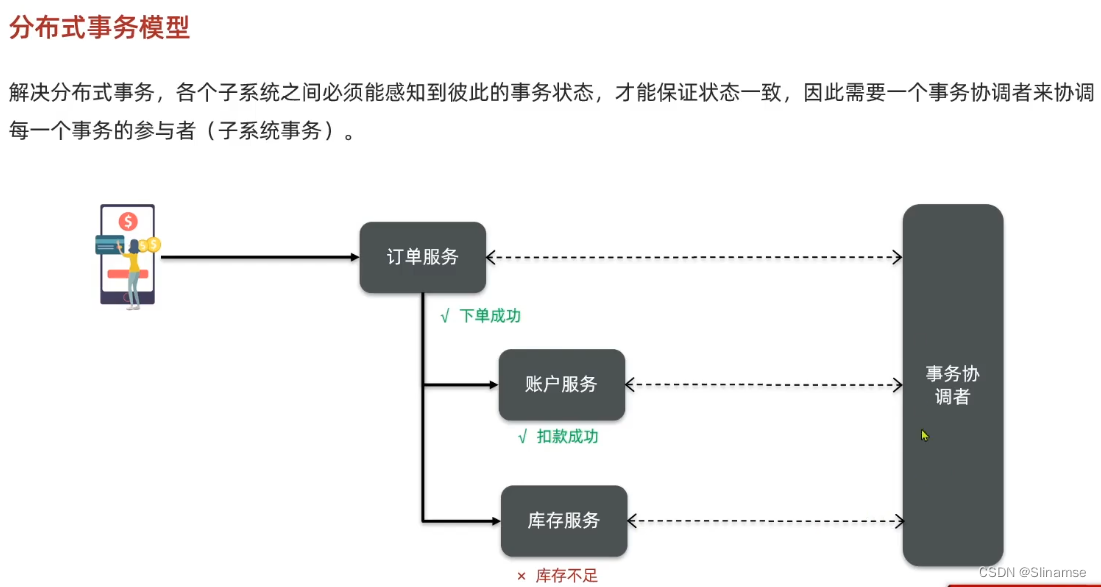
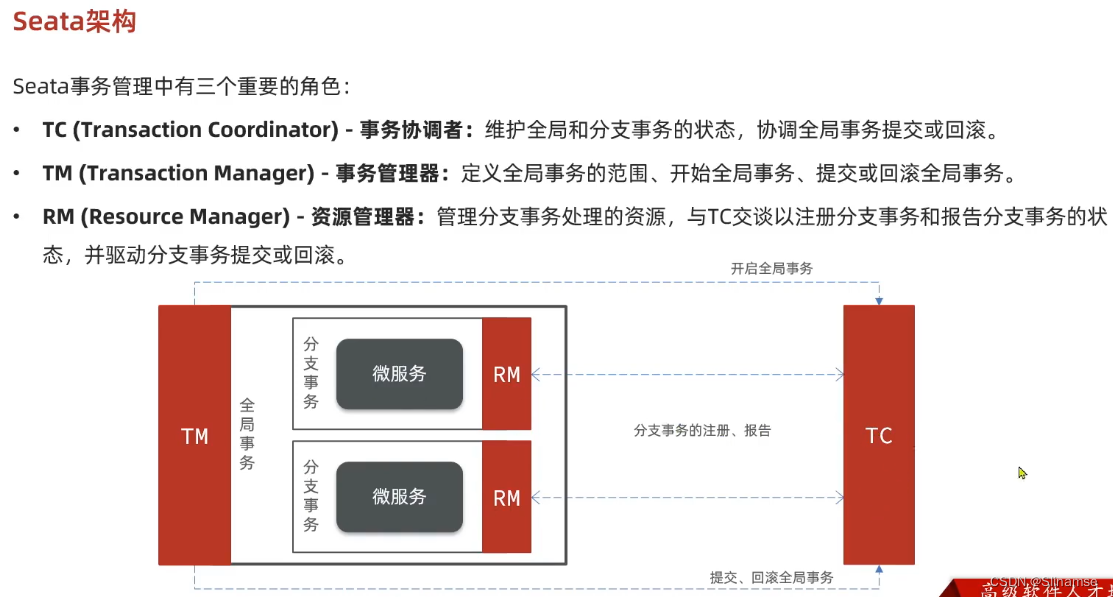
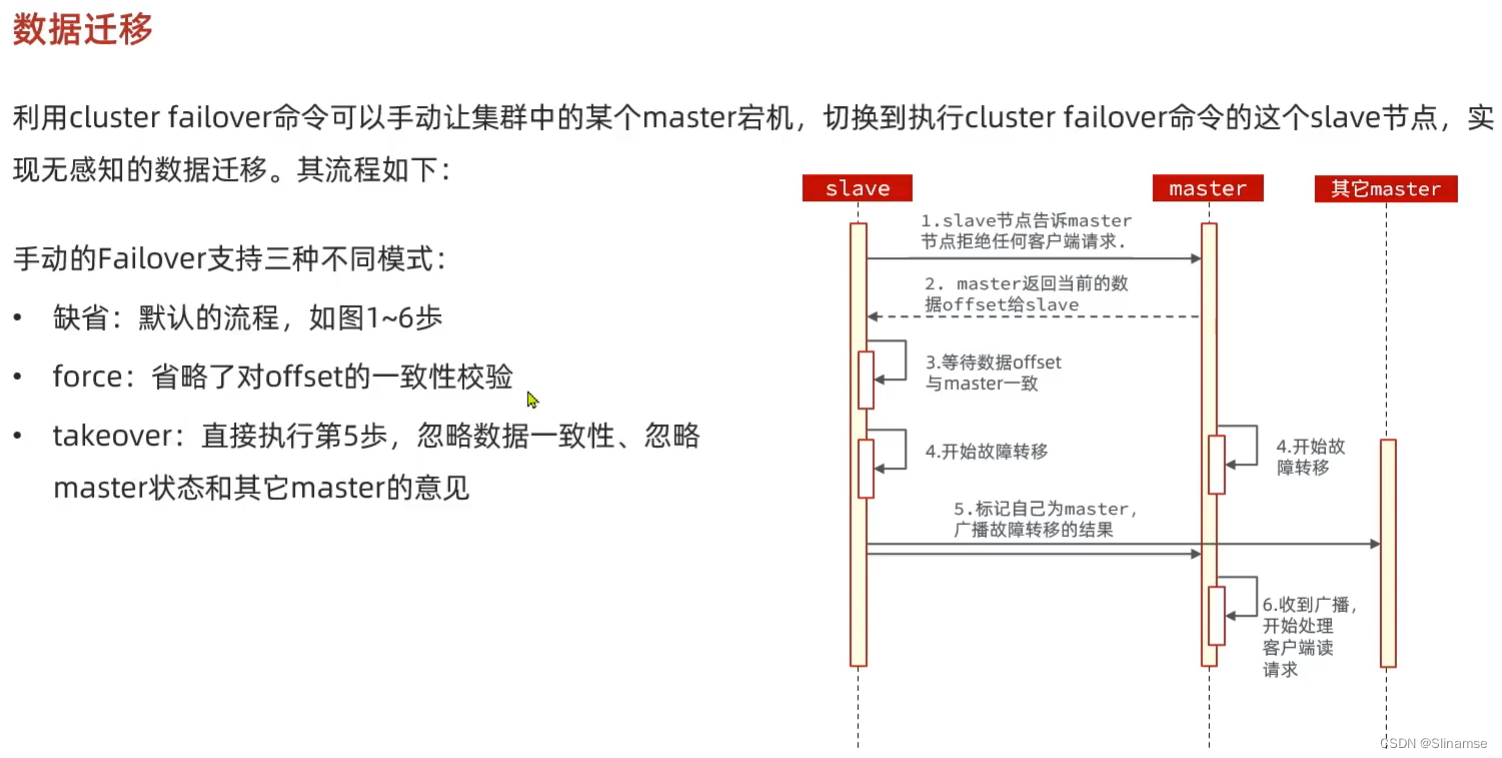
seata的部署和集成
一、部署Seata的tc-server
1.下载
首先我们要下载seata-server包,地址在http://seata.io/zh-cn/blog/download.html
当然,课前资料也准备好了:

2.解压
在非中文目录解压缩这个zip包,其目录结构如下:

3.修改配置
修改conf目录下的registry.conf文件:

内容如下:
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "SH"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}4.在nacos添加配置
特别注意,为了让tc服务的集群可以共享配置,我们选择了nacos作为统一配置中心。因此服务端配置文件seataServer.properties文件需要在nacos中配好。
格式如下:
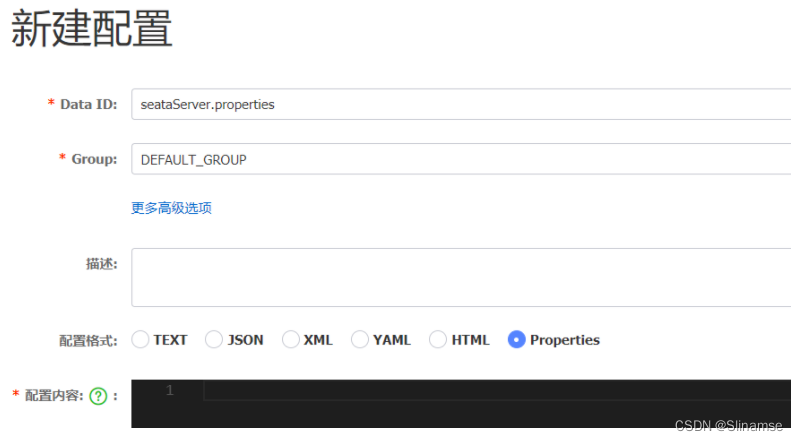
配置内容如下:
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=123
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898其中的数据库地址、用户名、密码都需要修改成你自己的数据库信息。
5.创建数据库表
特别注意:tc服务在管理分布式事务时,需要记录事务相关数据到数据库中,你需要提前创建好这些表。
新建一个名为seata的数据库,运行课前资料提供的sql文件:
这些表主要记录全局事务、分支事务、全局锁信息:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- 分支事务表
-- ----------------------------
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(6) NULL DEFAULT NULL,
`gmt_modified` datetime(6) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- 全局事务表
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;6.启动TC服务
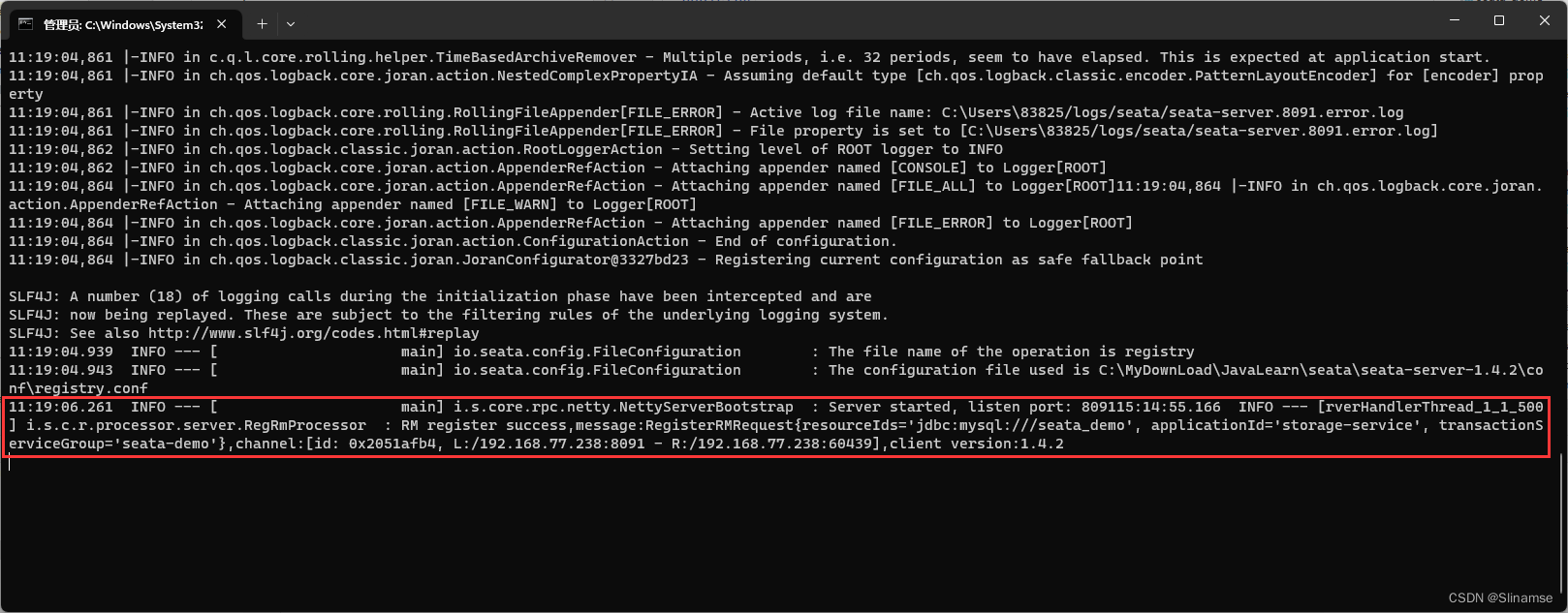
进入bin目录,运行其中的seata-server.bat即可:
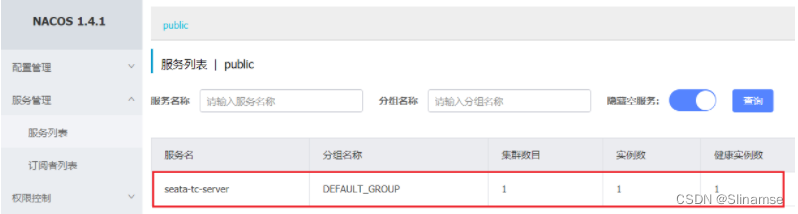
启动成功后,seata-server应该已经注册到nacos注册中心了。
打开浏览器,访问nacos地址:http://localhost:8848,然后进入服务列表页面,可以看到seata-tc-server的信息:




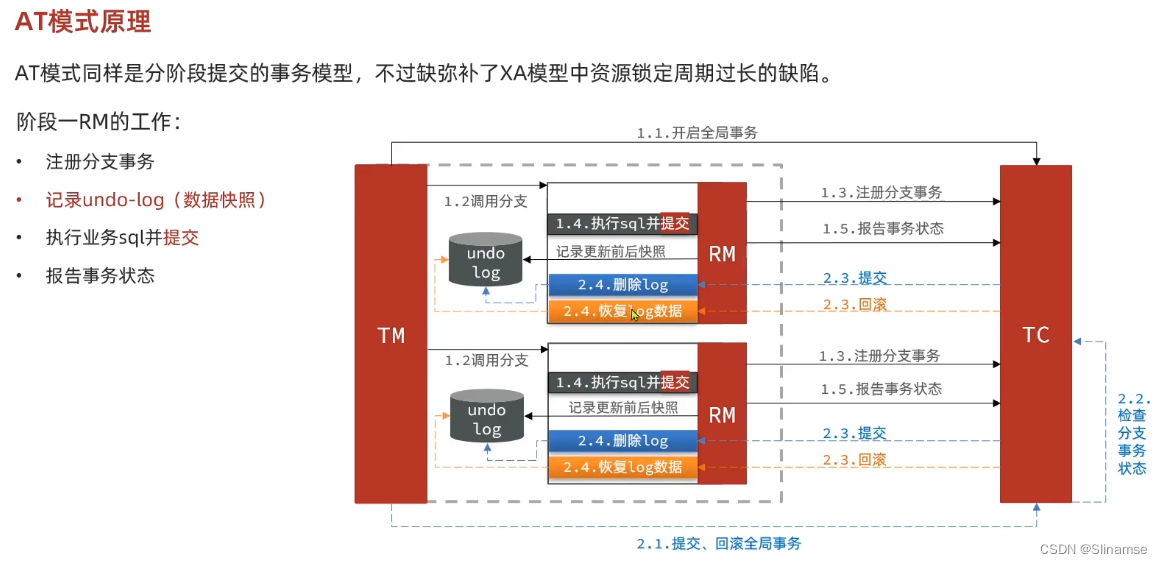
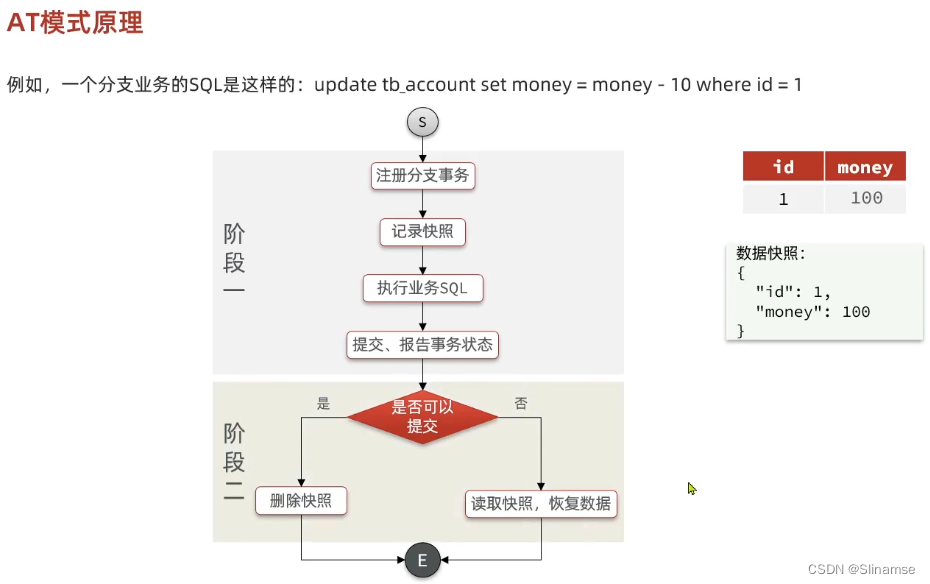






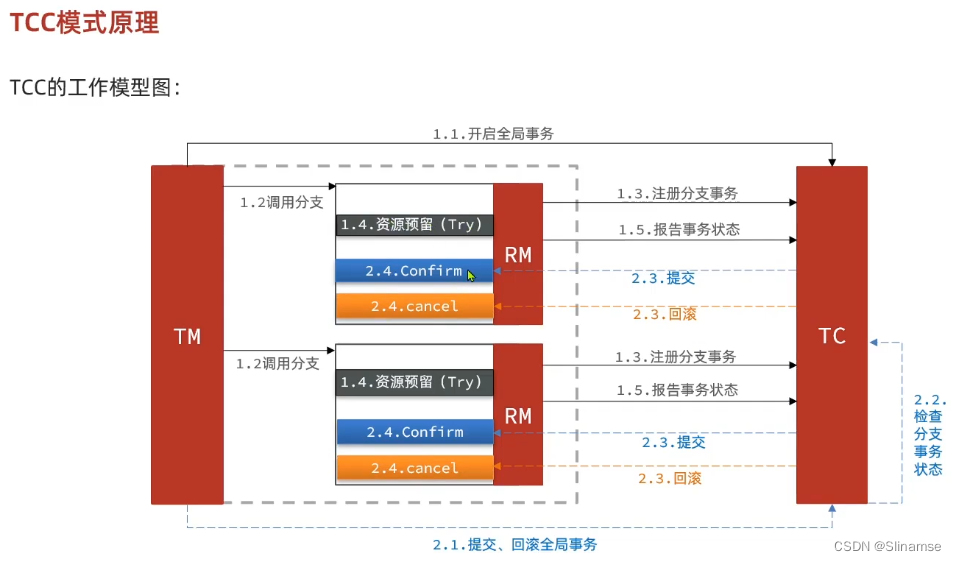

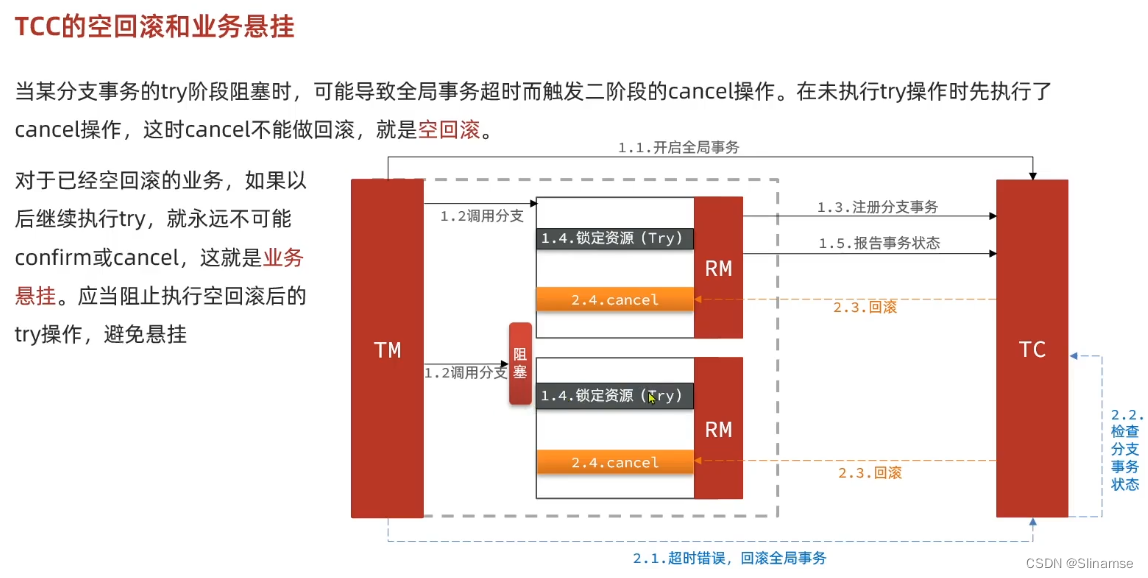


@Service
public class AccountTCCServiceImpl implements AccountTCCService {
@Autowired
private AccountMapper accountMapper;
@Autowired
private AccountFreezeMapper freezeMapper;
@Override
@Transactional
public void prepare(String userId, int money) {
//0.获取事务id
String xid = RootContext.getXID();
//事务悬挂,判断freeze中是否有冻结记录,如果有一定是CANCEL执行过,要拒绝业务
AccountFreeze oldFreeze = freezeMapper.selectById(xid);
if(oldFreeze != null){
//CANCEL执行过,拒绝业务
return;
}
//1.扣减可用余额
accountMapper.deduct(userId,money);
//2.记录冻结金额,事务状态
AccountFreeze freeze = new AccountFreeze();
freeze.setUserId(userId);
freeze.setFreezeMoney(money);
freeze.setState(AccountFreeze.State.TRY);
freeze.setXid(xid);
freezeMapper.insert(freeze);
}
@Override
public boolean confirm(BusinessActionContext context) {
//1.获取事务id
String xid = context.getXid();
//2.根据id删除冻结记录
int count = freezeMapper.deleteById(xid);
return count == 1;
}
@Override
public boolean cancel(BusinessActionContext context) {
//0.查询冻结记录
String xid = context.getXid();
String userId = (String) context.getActionContext("userId");
Integer money = (Integer) context.getActionContext("money");
AccountFreeze freeze = freezeMapper.selectById(xid);
//1.空回滚的判断,判断freeze是否为null,为null证明try没执行,需要空回滚
if(freeze == null){
//证明try没执行,需要空回滚
freeze.setXid(xid);
freeze.setUserId(userId);
freeze.setFreezeMoney(money);
freeze.setState(AccountFreeze.State.CANCEL);
freezeMapper.insert(freeze);
return true;
}
//2.幂等判断
if(freeze.getState() == AccountFreeze.State.CANCEL){
//已经处理过一次CANCEL了,无需重复处理
return true;
}
//1.恢复可用余额
accountMapper.refund(freeze.getUserId(), freeze.getFreezeMoney());
//2.将冻结金额清零,状态改为CANCEL
freeze.setState(AccountFreeze.State.CANCEL);
freeze.setFreezeMoney(0);
int count = freezeMapper.updateById(freeze);
return count == 1;
}
}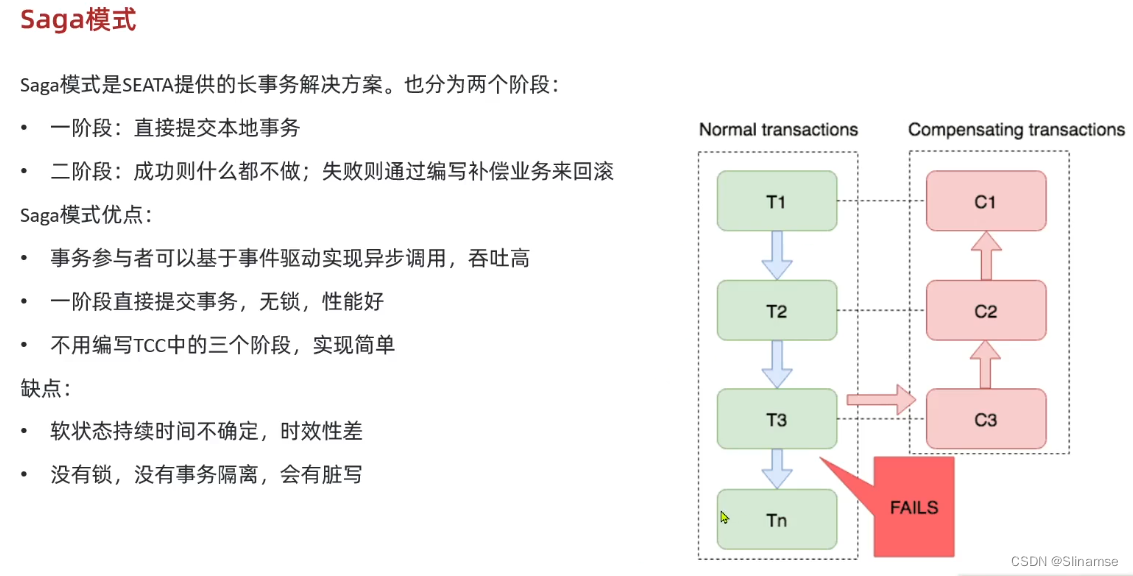
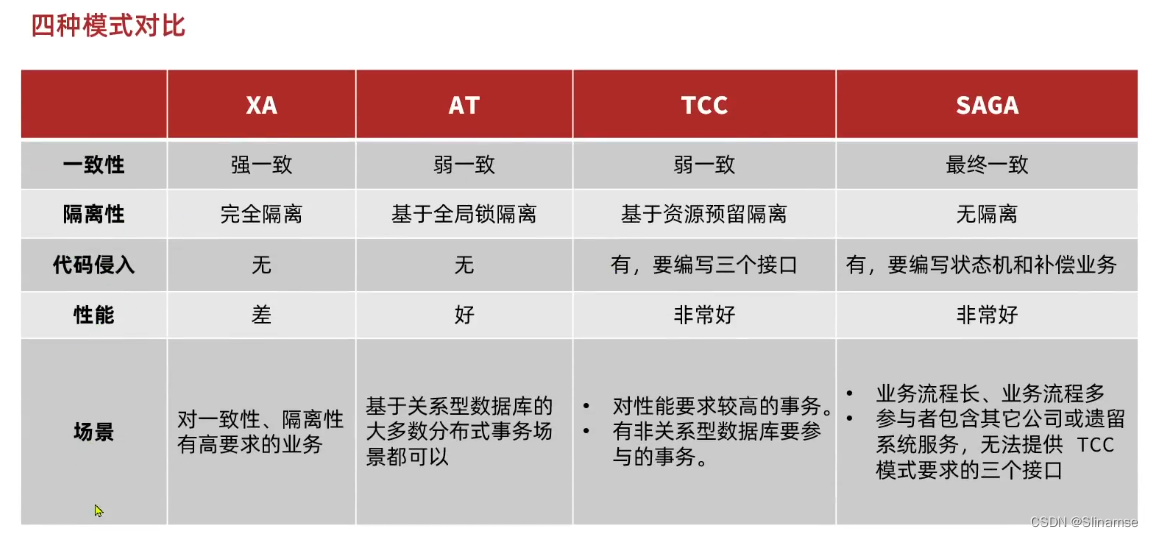
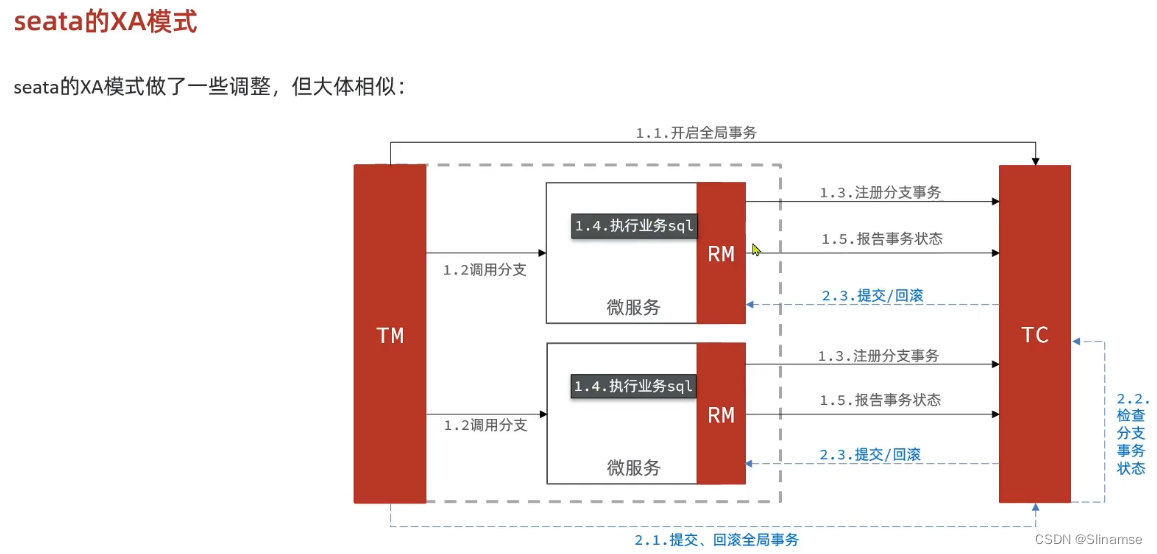
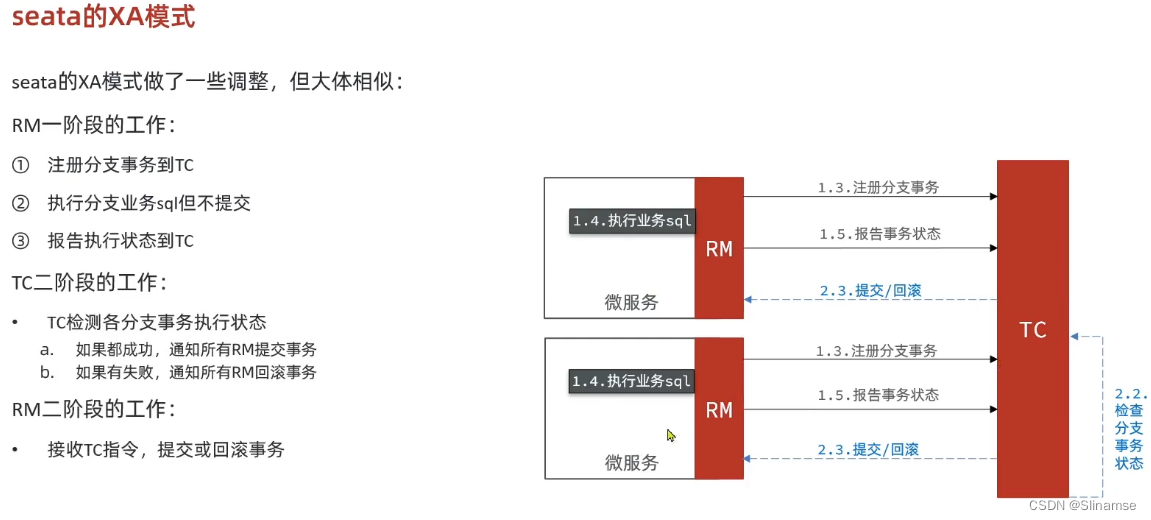
TC服务的高可用和异地容灾
1.模拟异地容灾的TC集群
计划启动两台seata的tc服务节点:
| 节点名称 | ip地址 | 端口号 | 集群名称 |
|---|---|---|---|
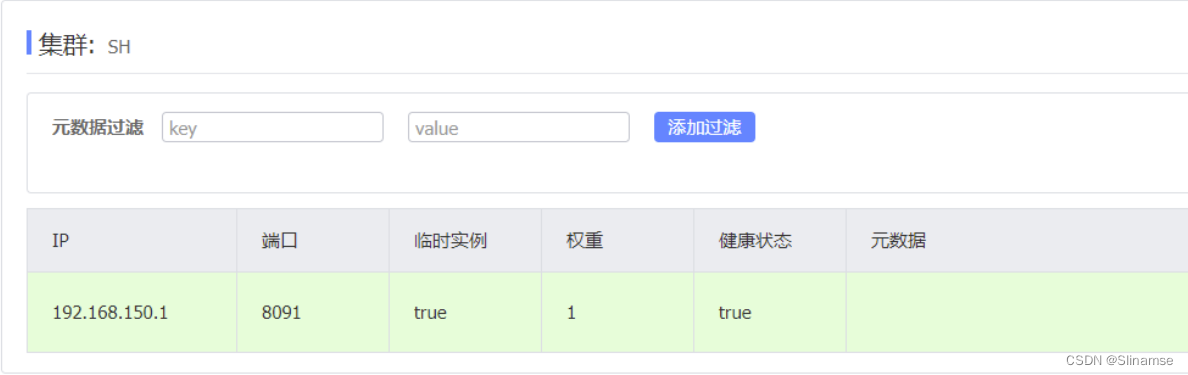
| seata | 127.0.0.1 | 8091 | SH |
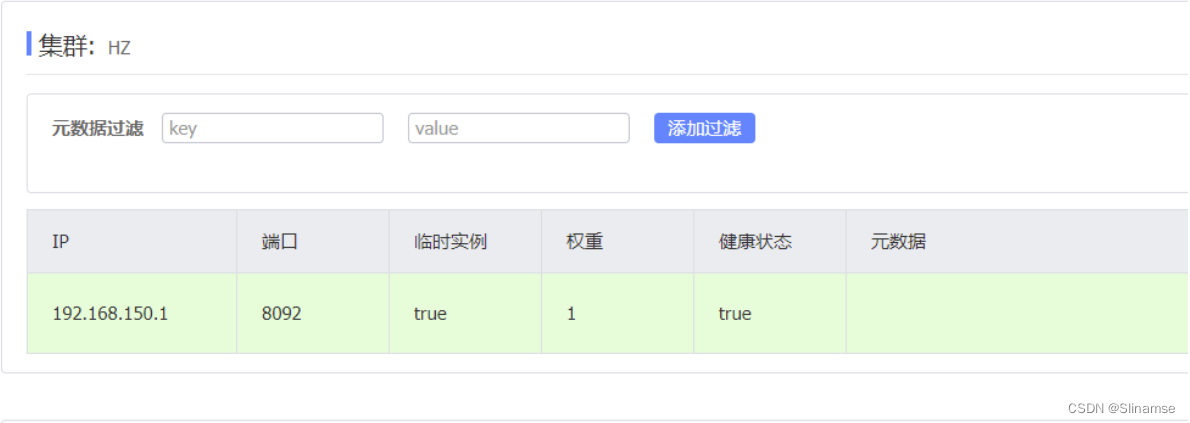
| seata2 | 127.0.0.1 | 8092 | HZ |
之前我们已经启动了一台seata服务,端口是8091,集群名为SH。
现在,将seata目录复制一份,起名为seata2
修改seata2/conf/registry.conf内容如下:
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "HZ"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}进入seata2/bin目录,然后运行命令:
seata-server.bat -p 8092打开nacos控制台,查看服务列表:

点进详情查看:
将事务组映射配置到nacos
接下来,我们需要将tx-service-group与cluster的映射关系都配置到nacos配置中心。
新建一个配置:
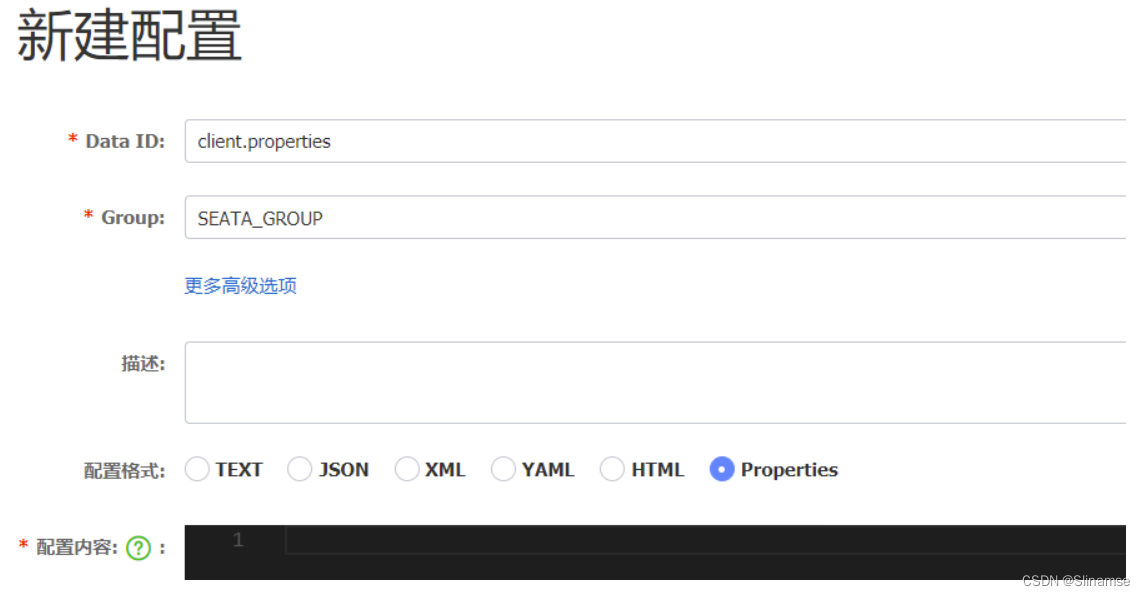
配置的内容如下:
# 事务组映射关系
service.vgroupMapping.seata-demo=SH
service.enableDegrade=false
service.disableGlobalTransaction=false
# 与TC服务的通信配置
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableClientBatchSendRequest=false
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
# RM配置
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=false
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
# TM配置
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
# undo日志配置
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
client.log.exceptionRate=100微服务读取nacos配置
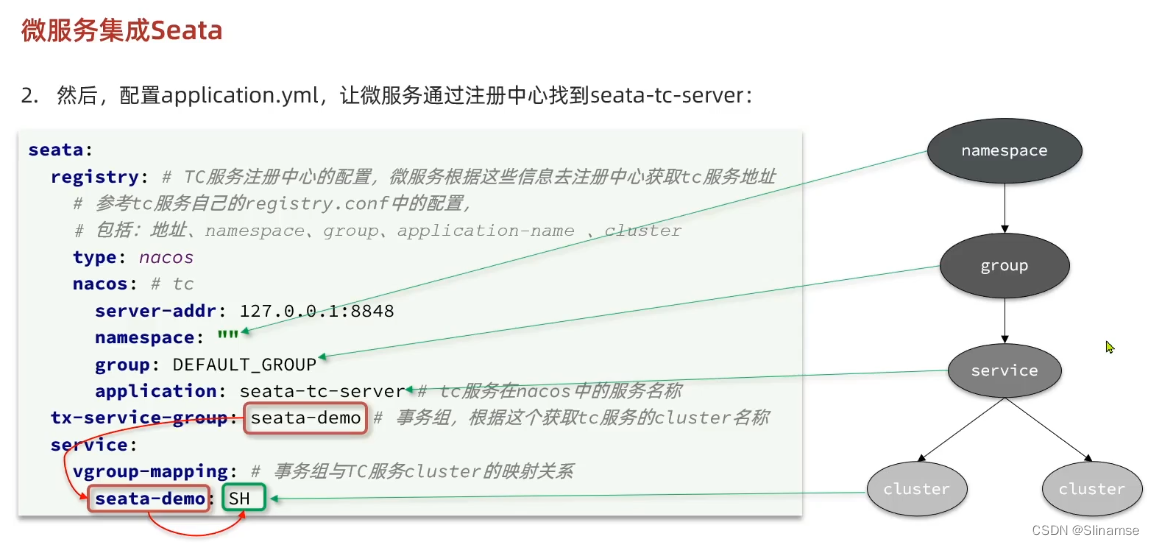
接下来,需要修改每一个微服务的application.yml文件,让微服务读取nacos中的client.properties文件:
seata:
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
username: nacos
password: nacos
group: SEATA_GROUP
data-id: client.properties重启微服务,现在微服务到底是连接tc的SH集群,还是tc的HZ集群,都统一由nacos的client.properties来决定了。




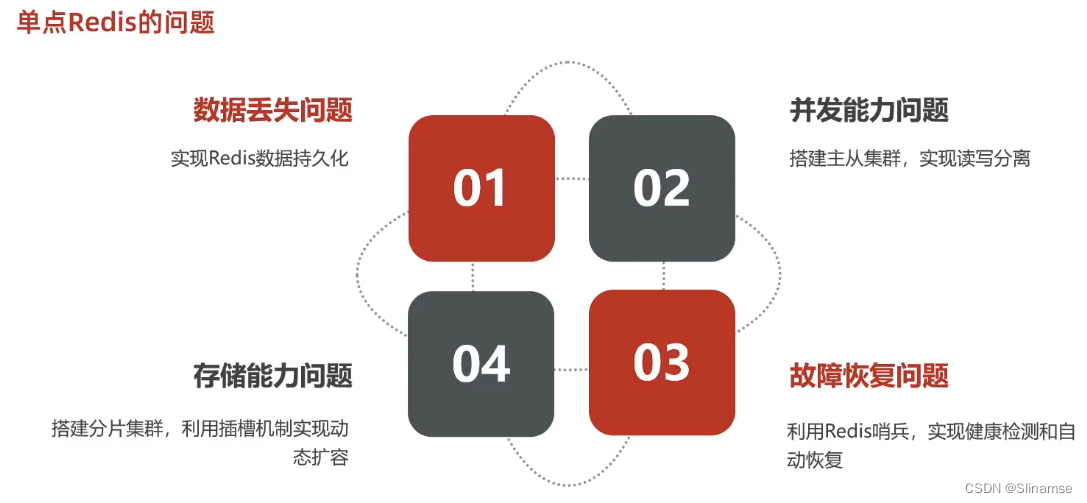

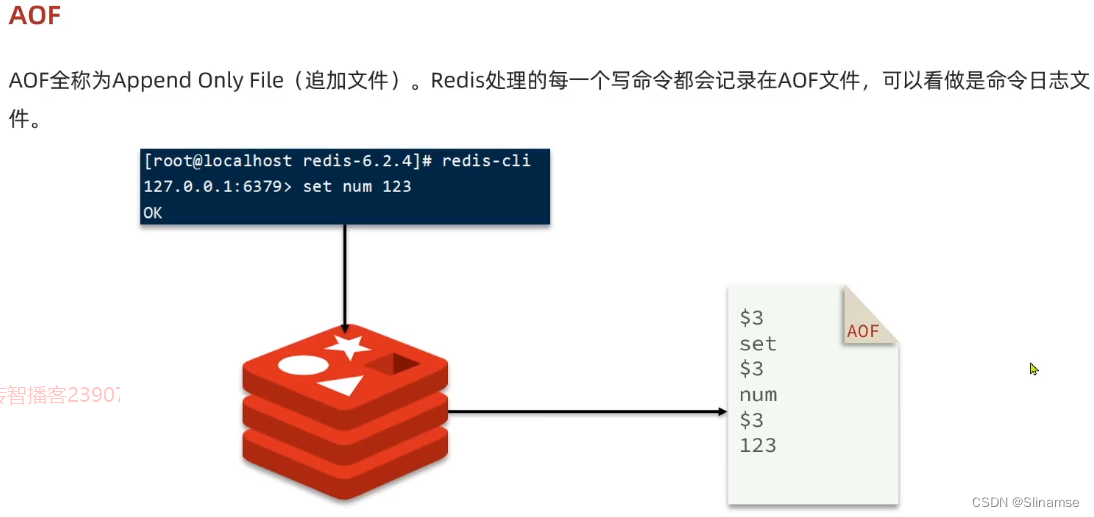


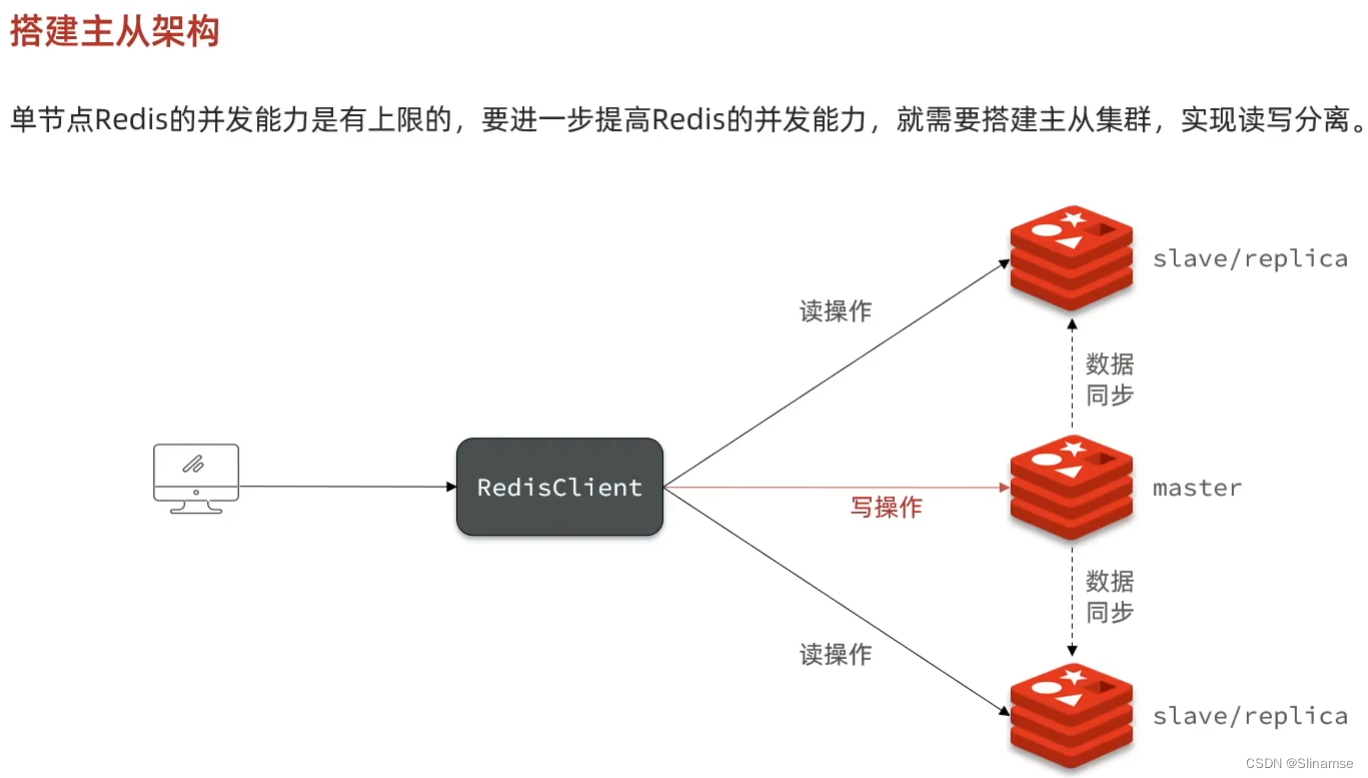
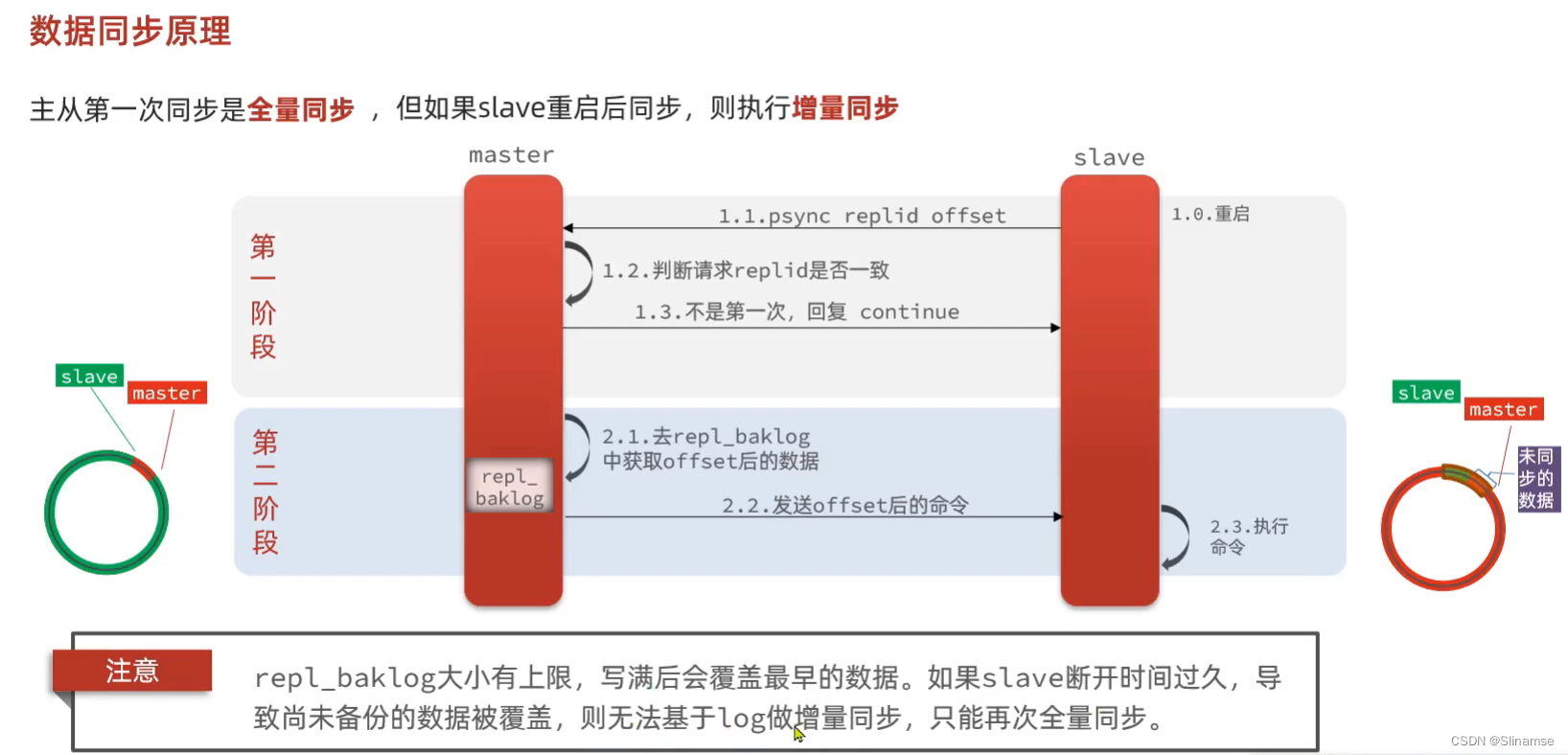
共包含三个节点,一个主节点,两个从节点。
这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | slave |
| 192.168.150.101 | 7003 | slave |
准备实例和配置
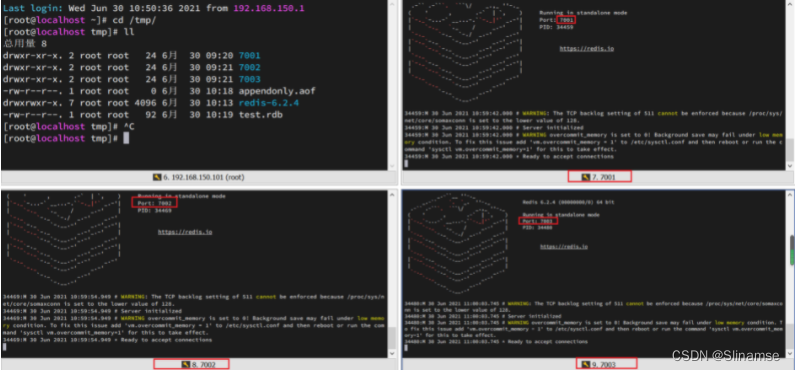
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
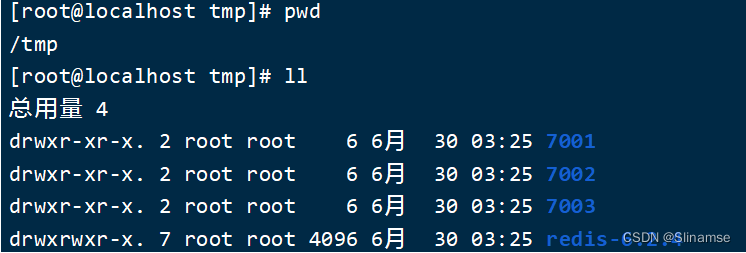
1)创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003如图:
2)恢复原始配置
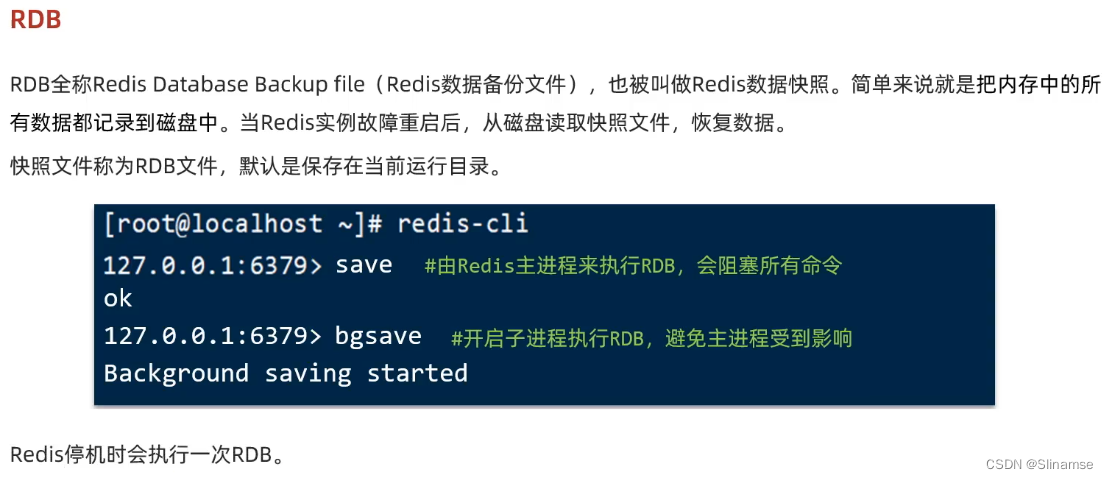
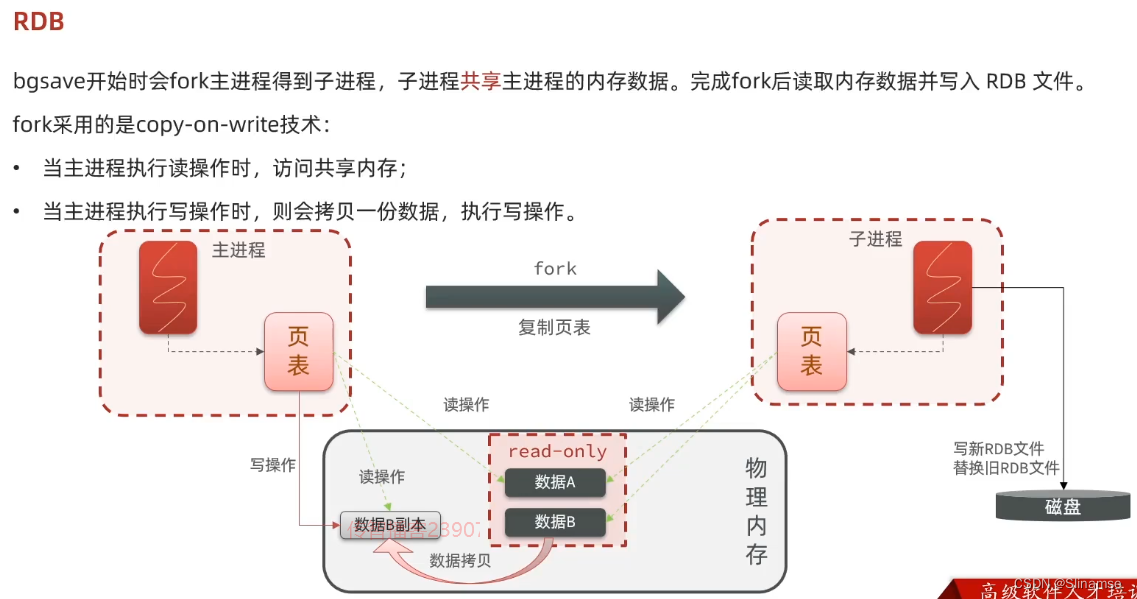
修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态。
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 关闭AOF
appendonly no3)拷贝配置文件到每个实例目录
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf4)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf5)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
# redis实例的声明 IP
replica-announce-ip 192.168.150.101每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
# 逐一执行
sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf
# 或者一键修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf启动后:
如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown开启主从关系
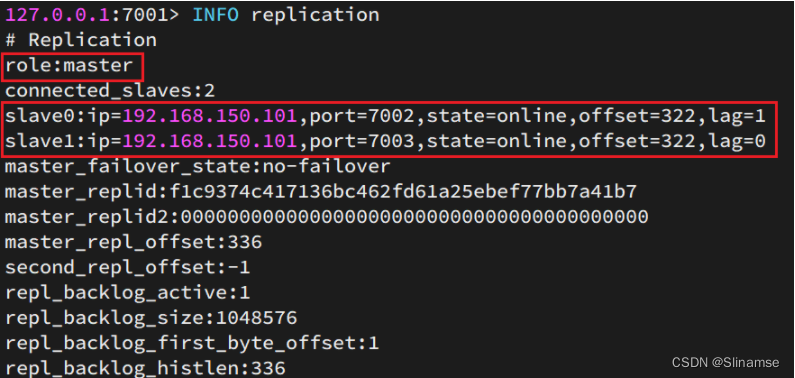
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改配置文件(永久生效)
-
在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
-
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>注意:在5.0以后新增命令replicaof,与salveof效果一致。
这里我们为了演示方便,使用方式二。
通过redis-cli命令连接7002,执行下面命令:
# 连接 7002
redis-cli -p 7002
# 执行slaveof
slaveof 192.168.150.101 7001通过redis-cli命令连接7003,执行下面命令:
# 连接 7003
redis-cli -p 7003
# 执行slaveof
slaveof 192.168.150.101 7001结果:
测试
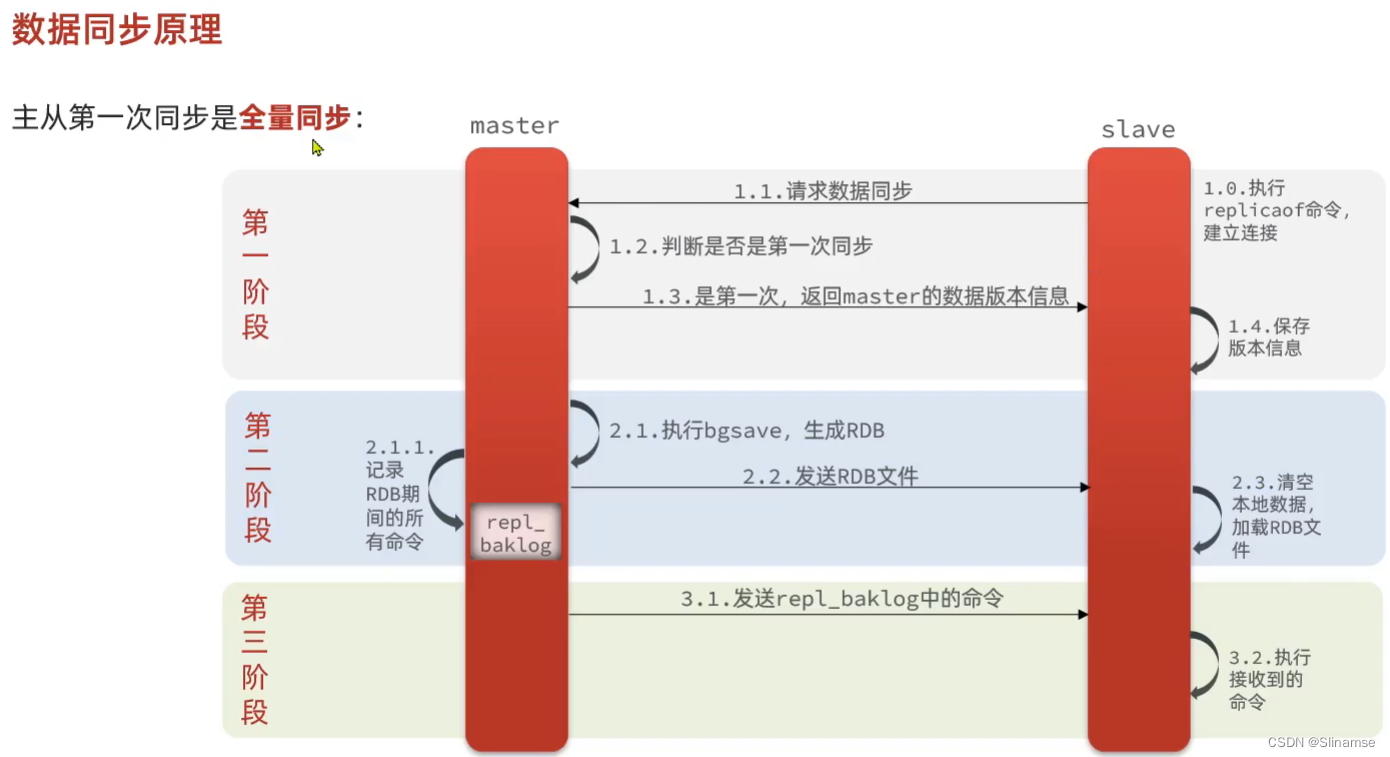
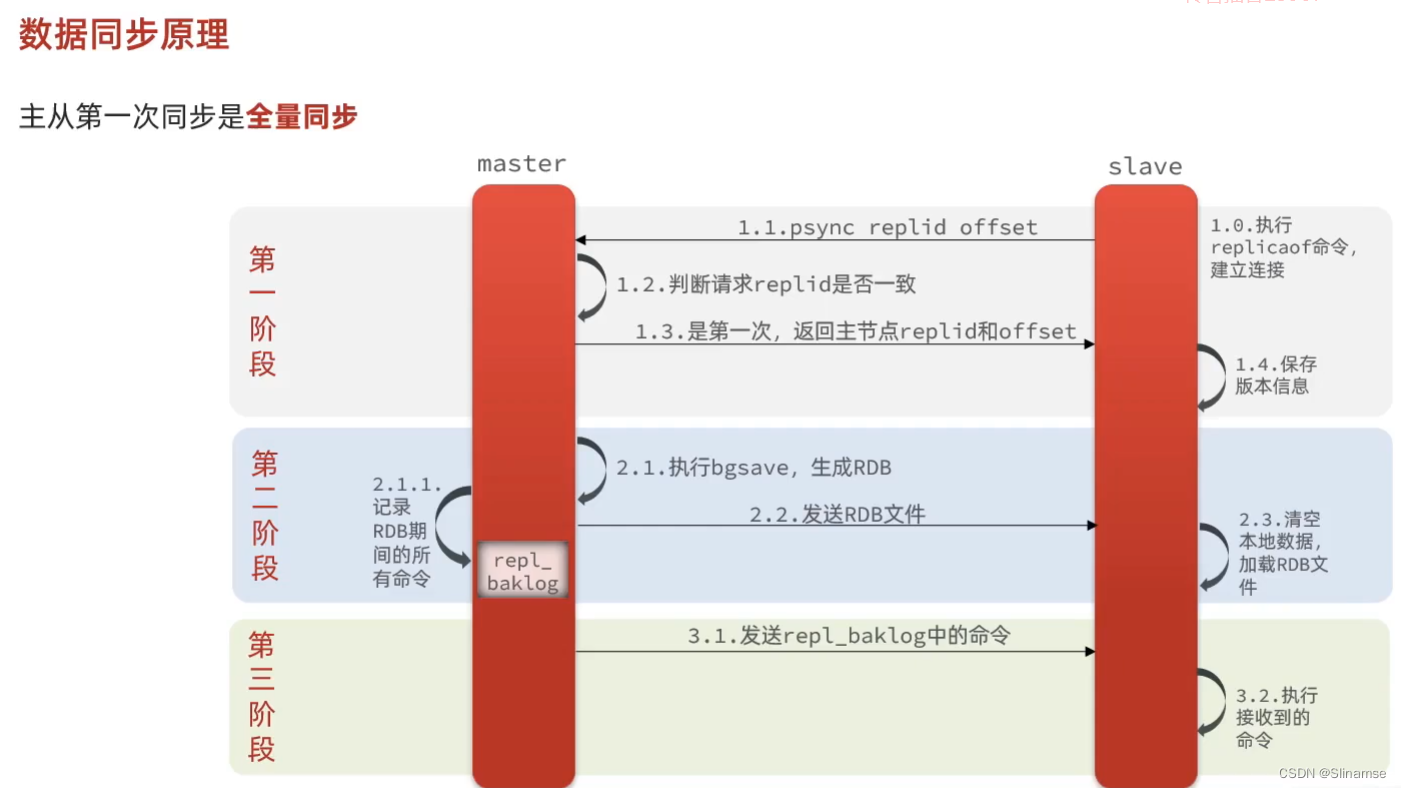
执行下列操作以测试:
-
利用redis-cli连接7001,执行
set num 123 -
利用redis-cli连接7002,执行
get num,再执行set num 666 -
利用redis-cli连接7003,执行
get num,再执行set num 888
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。



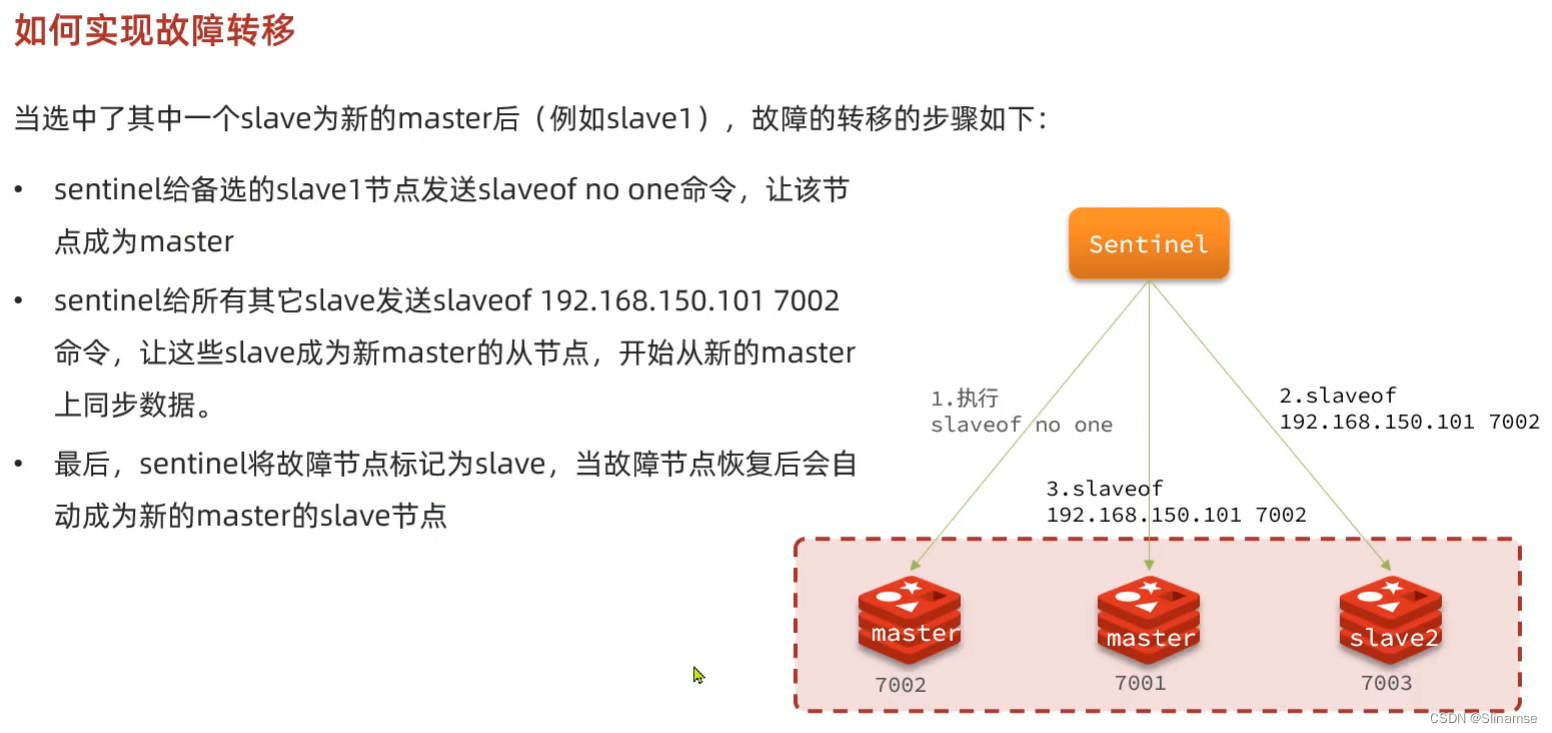
搭建哨兵集群
集群结构
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群。如图:
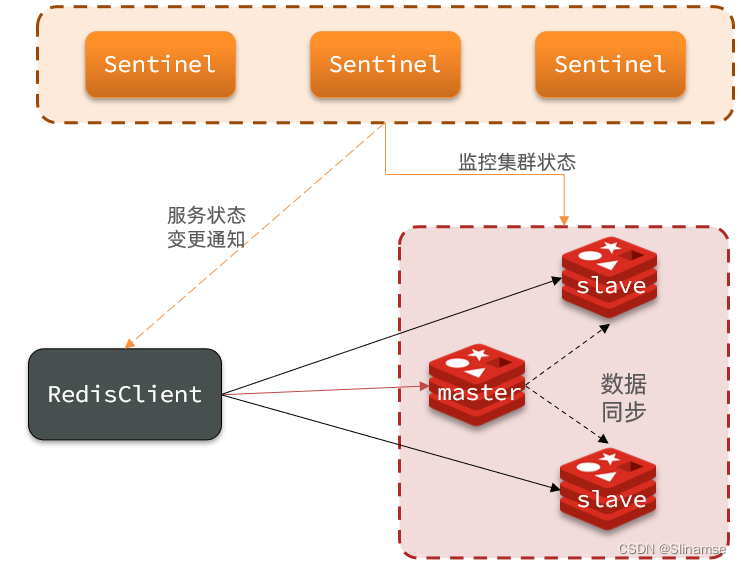
三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir s1 s2 s3如图:
然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"解读:
-
port 27001:是当前sentinel实例的端口 -
sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息-
mymaster:主节点名称,自定义,任意写 -
192.168.150.101 7001:主节点的ip和端口 -
2:选举master时的quorum值
-
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-sentinel s1/sentinel.conf
# 第2个
redis-sentinel s2/sentinel.conf
# 第3个
redis-sentinel s3/sentinel.conf启动后:
测试
尝试让master节点7001宕机,查看sentinel日志:
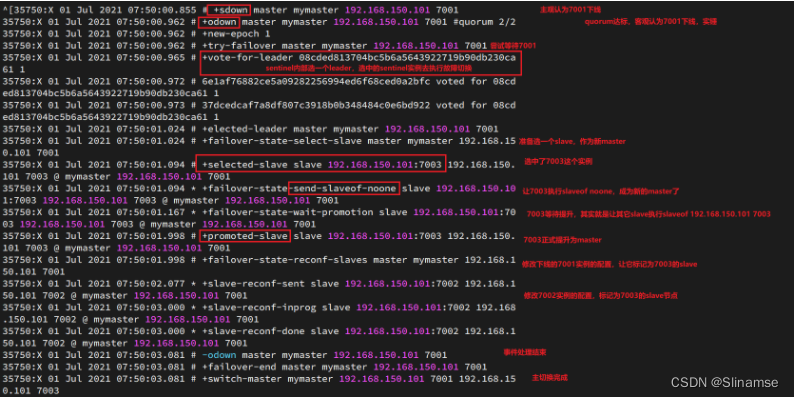
查看7003的日志:

查看7002的日志:
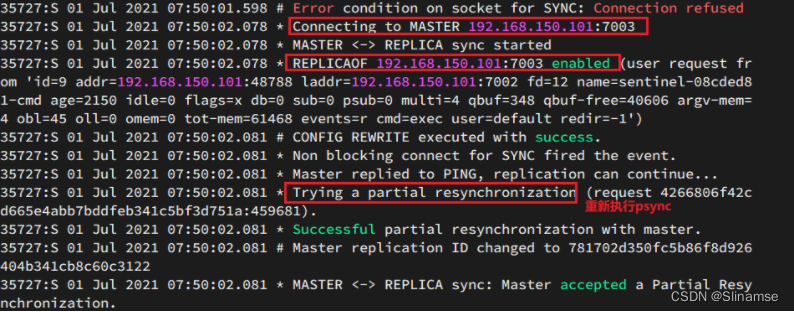
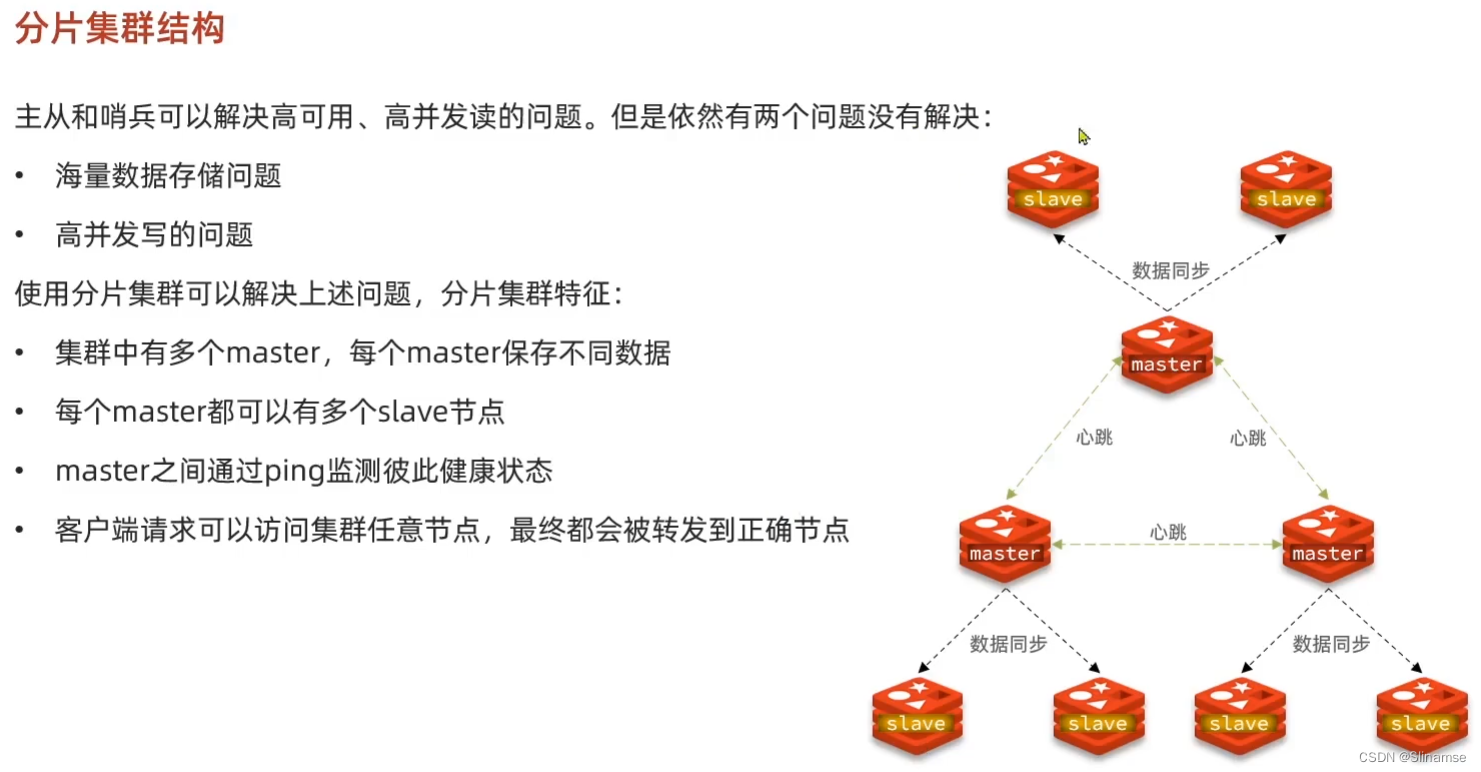
搭建分片集群
集群结构
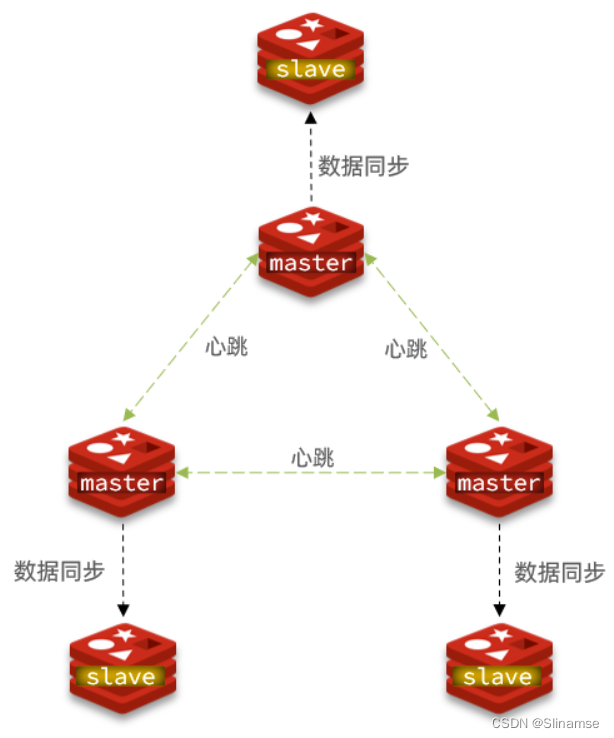
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
准备实例和配置
删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:
# 进入/tmp目录
cd /tmp
# 删除旧的,避免配置干扰
rm -rf 7001 7002 7003
# 创建目录
mkdir 7001 7002 7003 8001 8002 8003在/tmp下准备一个新的redis.conf文件,内容如下:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log将这个文件拷贝到每个目录下:
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf启动
因为已经配置了后台启动模式,所以可以直接启动服务:
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf通过ps查看状态:
ps -ef | grep redis发现服务都已经正常启动:

如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis然后通过命令来管理集群:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:80032)Redis5.0以后
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
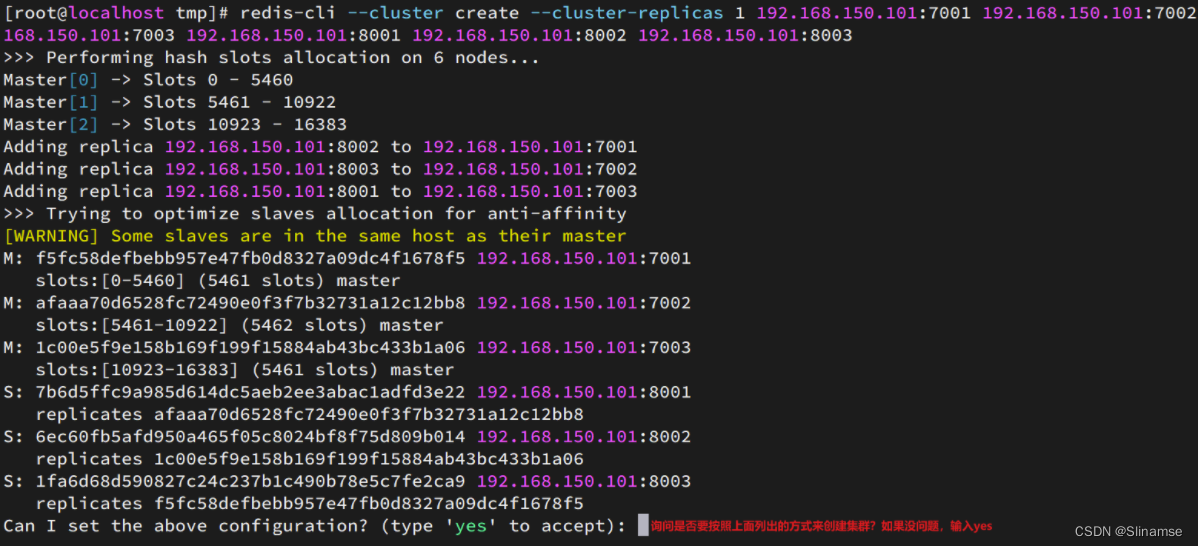
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003命令说明:
-
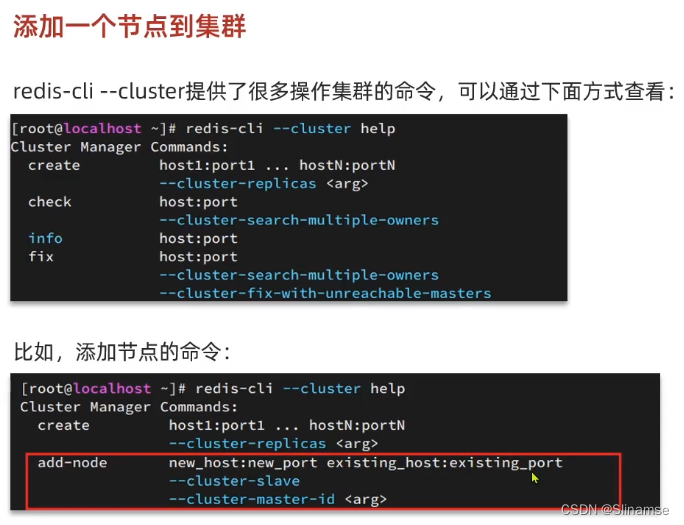
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令 -
create:代表是创建集群 -
--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
运行后的样子:
这里输入yes,则集群开始创建:
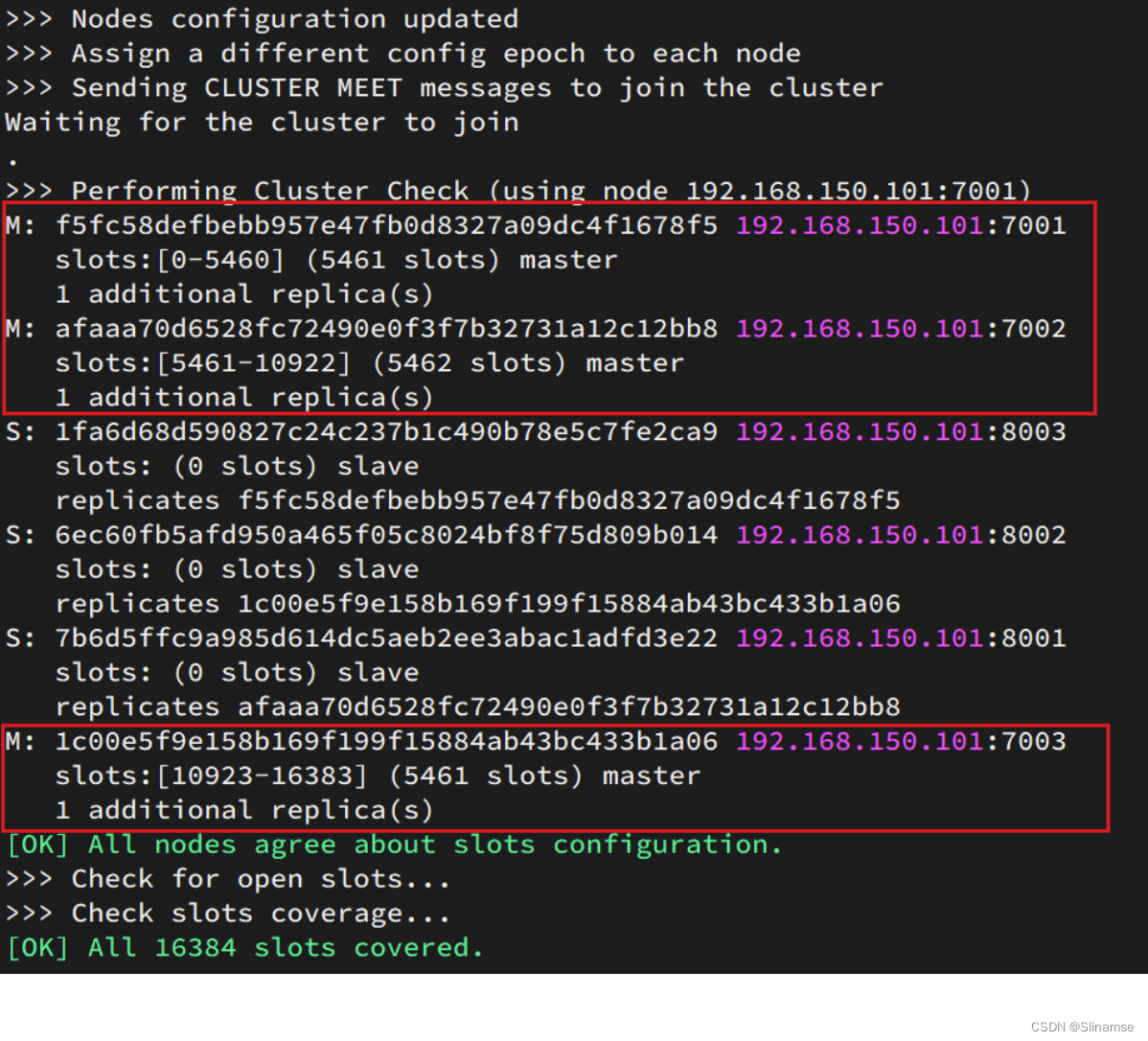
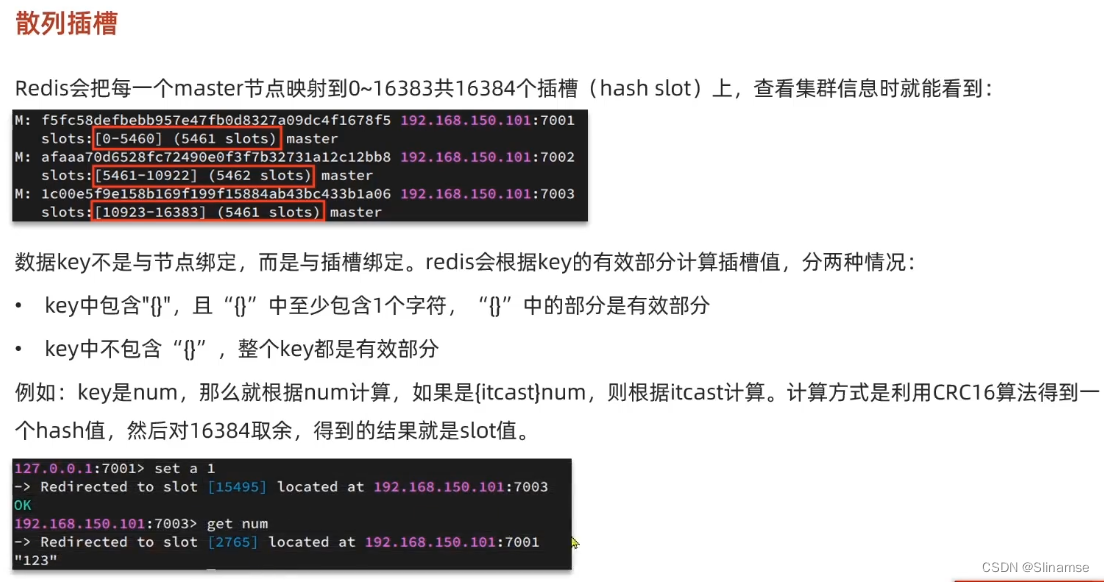
通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes
测试
尝试连接7001节点,存储一个数据:
# 连接
redis-cli -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
set a 1结果悲剧了:
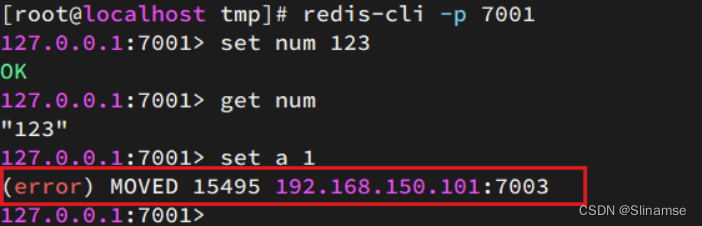
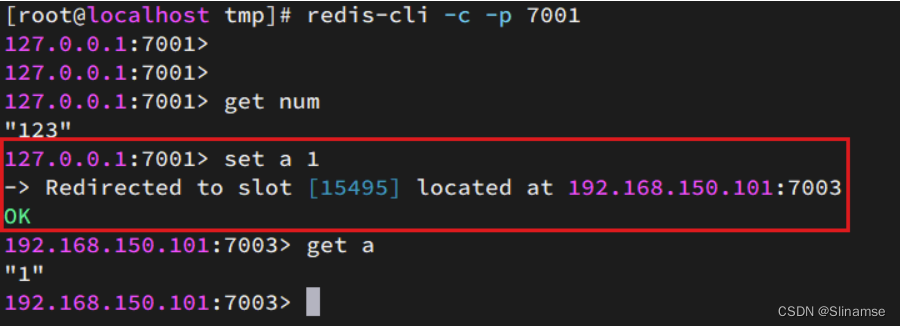
集群操作时,需要给redis-cli加上-c参数才可以:
redis-cli -c -p 7001这次可以了:

[root@localhost ~]# mkdir 7004
[root@localhost ~]# cp redis.conf 7004
[root@localhost ~]# sed -i s/6379/7004/g 7004/redis.conf
[root@localhost ~]# redis-server 7004/redis.conf
[root@localhost ~]# ps -ef|grep redis
root 9043 1 0 10:19 ? 00:00:02 redis-server 0.0.0.0:7001 [cluster]
root 9045 1 0 10:19 ? 00:00:02 redis-server 0.0.0.0:7002 [cluster]
root 9051 1 0 10:19 ? 00:00:02 redis-server 0.0.0.0:7003 [cluster]
root 9057 1 0 10:19 ? 00:00:02 redis-server 0.0.0.0:8001 [cluster]
root 9067 1 0 10:19 ? 00:00:02 redis-server 0.0.0.0:8002 [cluster]
root 9073 1 0 10:19 ? 00:00:02 redis-server 0.0.0.0:8003 [cluster]
root 43224 1 0 10:56 ? 00:00:00 redis-server 0.0.0.0:7004 [cluster]
root 43395 7363 0 10:56 pts/0 00:00:00 grep --color=auto redis
[root@localhost ~]# redis-cli --cluster add-node 192.168.136.150:7004 192.168.136.150:7001
>>> Adding node 192.168.136.150:7004 to cluster 192.168.136.150:7001
>>> Performing Cluster Check (using node 192.168.136.150:7001)
M: 75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002
slots: (0 slots) slave
replicates 6f4d16202085216450ee2706e459080179c86c35
M: 2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003
slots: (0 slots) slave
replicates 75e72a990938d6cb8ab99da3339ec1cfa0338d26
S: 928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001
slots: (0 slots) slave
replicates 2ef840fd76cf185978476a1ce4310e639d422244
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.136.150:7004 to make it join the cluster.
[OK] New node added correctly.
[root@localhost ~]# redis-cli -p 7001 cluster nodes
75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001@17001 myself,master - 0 1681527852000 1 connected 0-5460
6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003@17003 master - 0 1681527852573 3 connected 10923-16383
baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002@18002 slave 6f4d16202085216450ee2706e459080179c86c35 0 1681527851597 3 connected
2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002@17002 master - 0 1681527853224 2 connected 5461-10922
adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003@18003 slave 75e72a990938d6cb8ab99da3339ec1cfa0338d26 0 1681527852682 1 connected
93396d8684bf261e763948dc4354af00f0a4e602 192.168.136.150:7004@17004 master - 0 1681527852573 0 connected
928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001@18001 slave 2ef840fd76cf185978476a1ce4310e639d422244 0 1681527851000 2 connected
[root@localhost ~]# redis-cli -c -p 7001
127.0.0.1:7001> get num
"123"
127.0.0.1:7001> get a
-> Redirected to slot [15495] located at 192.168.136.150:7003
"1"
192.168.136.150:7003> get num
-> Redirected to slot [2765] located at 192.168.136.150:7001
"123"
[root@localhost ~]# redis-cli --cluster reshard 192.168.136.150:7001
>>> Performing Cluster Check (using node 192.168.136.150:7001)
M: 75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002
slots: (0 slots) slave
replicates 6f4d16202085216450ee2706e459080179c86c35
M: 2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003
slots: (0 slots) slave
replicates 75e72a990938d6cb8ab99da3339ec1cfa0338d26
M: 93396d8684bf261e763948dc4354af00f0a4e602 192.168.136.150:7004
slots: (0 slots) master
S: 928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001
slots: (0 slots) slave
replicates 2ef840fd76cf185978476a1ce4310e639d422244
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 3000
What is the receiving node ID? 93396d8684bf261e763948dc4354af00f0a4e602
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 75e72a990938d6cb8ab99da3339ec1cfa0338d26
Source node #2: done
[root@localhost ~]# redis-cli -c -p 7001
127.0.0.1:7001> get num
-> Redirected to slot [2765] located at 192.168.136.150:7004
"123"
192.168.136.150:7004> set num 10
OK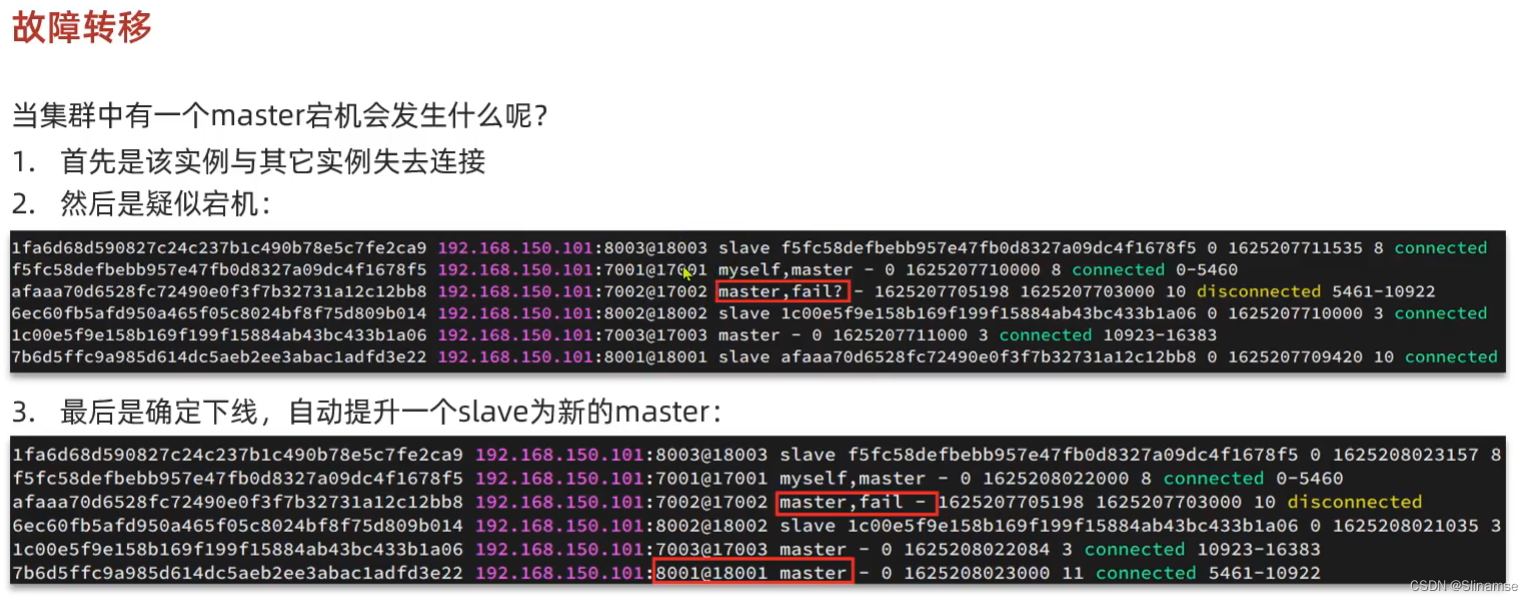
[root@localhost ~]# redis-cli -p 7001 cluster nodes
75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001@17001 myself,master - 0 1681529197000 1 connected 3000-5460
6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003@17003 master - 0 1681529198000 3 connected 10923-16383
baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002@18002 slave 6f4d16202085216450ee2706e459080179c86c35 0 1681529197555 3 connected
2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002@17002 master - 0 1681529198000 2 connected 5461-10922
adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003@18003 slave 75e72a990938d6cb8ab99da3339ec1cfa0338d26 0 1681529198848 1 connected
93396d8684bf261e763948dc4354af00f0a4e602 192.168.136.150:7004@17004 master - 0 1681529198733 7 connected 0-2999
928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001@18001 slave 2ef840fd76cf185978476a1ce4310e639d422244 0 1681529197663 2 connected
[root@localhost ~]# redis-cli -p 7002 shutdown
[root@localhost ~]# redis-cli -p 7001 cluster nodes
75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001@17001 myself,master - 0 1681529253000 1 connected 3000-5460
6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003@17003 master - 0 1681529254545 3 connected 10923-16383
baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002@18002 slave 6f4d16202085216450ee2706e459080179c86c35 0 1681529255519 3 connected
2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002@17002 master - 1681529255519 1681529253000 2 disconnected 5461-10922
adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003@18003 slave 75e72a990938d6cb8ab99da3339ec1cfa0338d26 0 1681529255519 1 connected
93396d8684bf261e763948dc4354af00f0a4e602 192.168.136.150:7004@17004 master - 0 1681529256066 7 connected 0-2999
928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001@18001 slave 2ef840fd76cf185978476a1ce4310e639d422244 0 1681529255519 2 connected
[root@localhost ~]# redis-server 7002/redis.conf
[root@localhost ~]# redis-cli -p 7001 cluster nodes
75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001@17001 myself,master - 0 1681529314000 1 connected 3000-5460
6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003@17003 master - 0 1681529314466 3 connected 10923-16383
baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002@18002 slave 6f4d16202085216450ee2706e459080179c86c35 0 1681529314000 3 connected
2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002@17002 slave 928f38e334530842905b84f5bc2f457f5c74111f 0 1681529313816 8 connected
adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003@18003 slave 75e72a990938d6cb8ab99da3339ec1cfa0338d26 0 1681529315531 1 connected
93396d8684bf261e763948dc4354af00f0a4e602 192.168.136.150:7004@17004 master - 0 1681529313385 7 connected 0-2999
928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001@18001 master - 0 1681529314248 8 connected 5461-10922

[root@localhost ~]# redis-cli -p 7002
127.0.0.1:7002> CLUSTER FAILOVER
OK
127.0.0.1:7002>
[root@localhost ~]# redis-cli -p 7001 cluster nodes
75e72a990938d6cb8ab99da3339ec1cfa0338d26 192.168.136.150:7001@17001 myself,master - 0 1681545541000 1 connected 3000-5460
6f4d16202085216450ee2706e459080179c86c35 192.168.136.150:7003@17003 master - 0 1681545542594 3 connected 10923-16383
baa24ffbe5cb1b8e256f81038d7d1d0c55cff90b 192.168.136.150:8002@18002 slave 6f4d16202085216450ee2706e459080179c86c35 0 1681545542000 3 connected
2ef840fd76cf185978476a1ce4310e639d422244 192.168.136.150:7002@17002 master - 0 1681545543575 9 connected 5461-10922
adcf7bdb736e4e56157308d4be4481b7d82ee287 192.168.136.150:8003@18003 slave 75e72a990938d6cb8ab99da3339ec1cfa0338d26 0 1681545542000 1 connected
93396d8684bf261e763948dc4354af00f0a4e602 192.168.136.150:7004@17004 master - 0 1681545542000 7 connected 0-2999
928f38e334530842905b84f5bc2f457f5c74111f 192.168.136.150:8001@18001 slave 2ef840fd76cf185978476a1ce4310e639d422244 0 1681545543031 9 connected

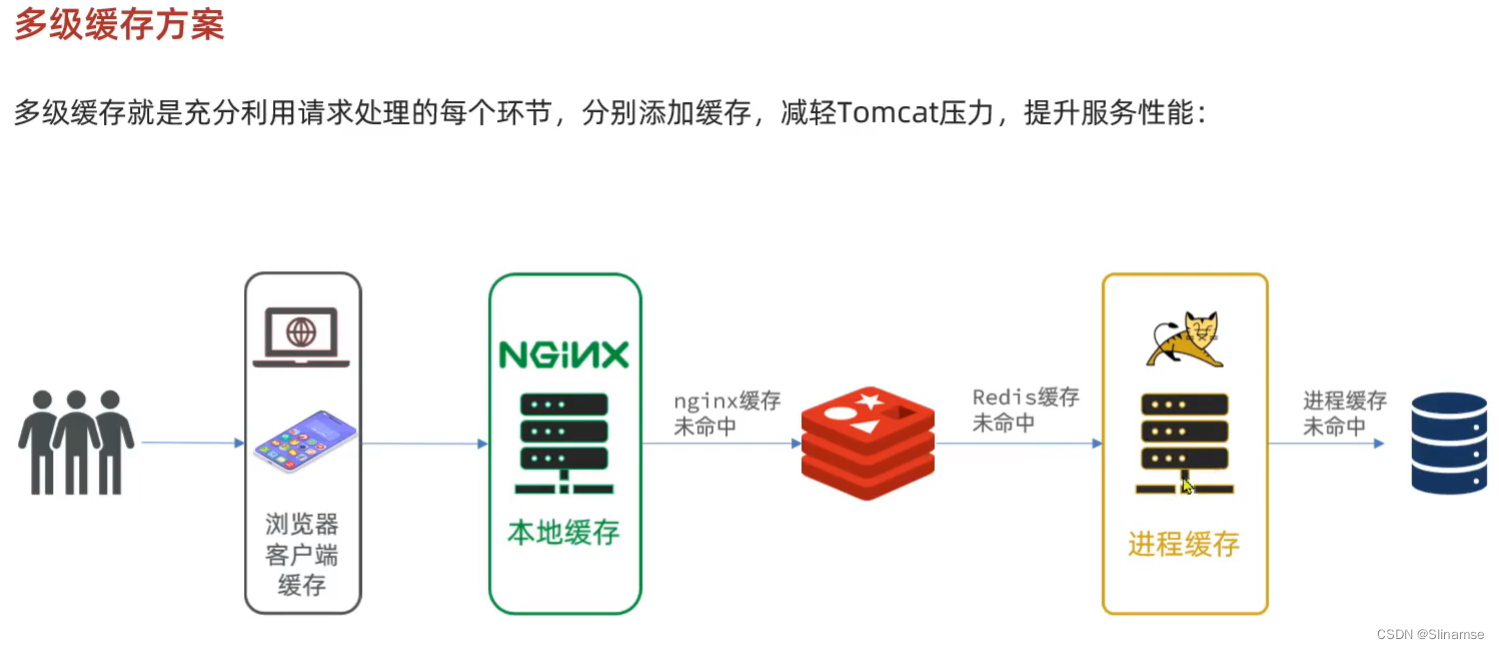
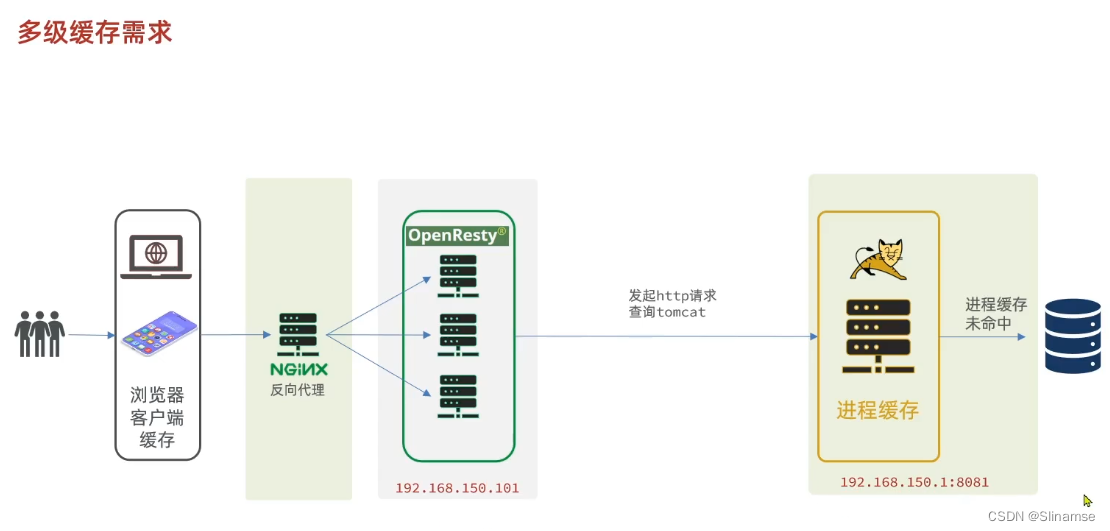
导入商品查询页面
商品查询是购物页面,与商品管理的页面是分离的。
部署方式如图:
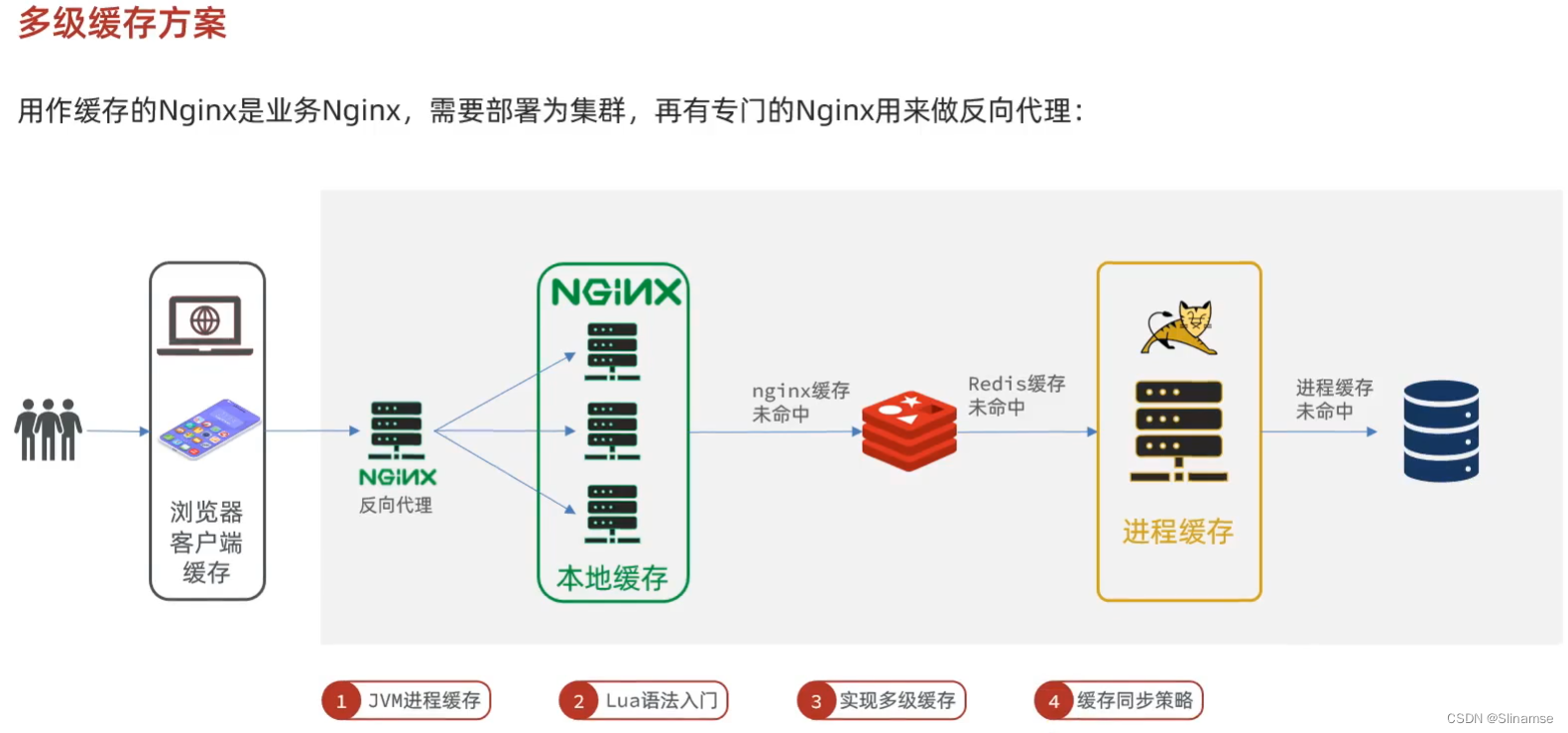
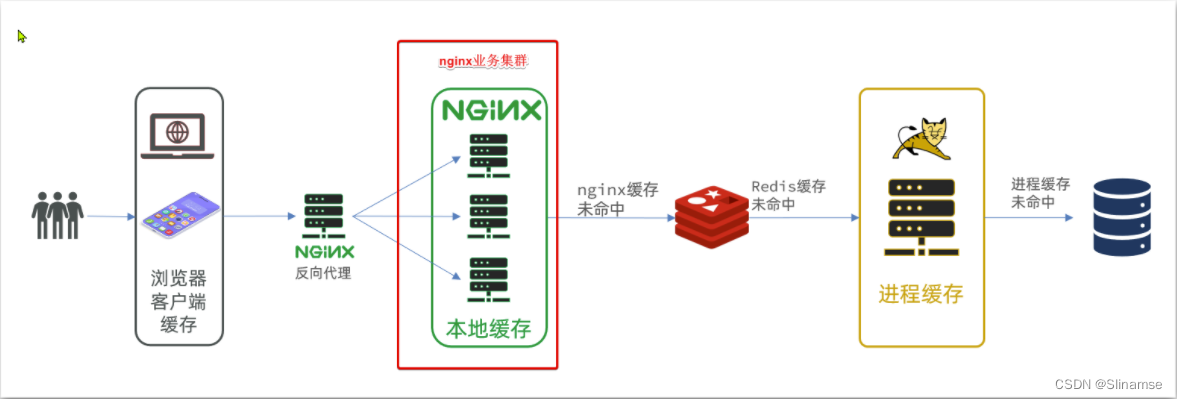
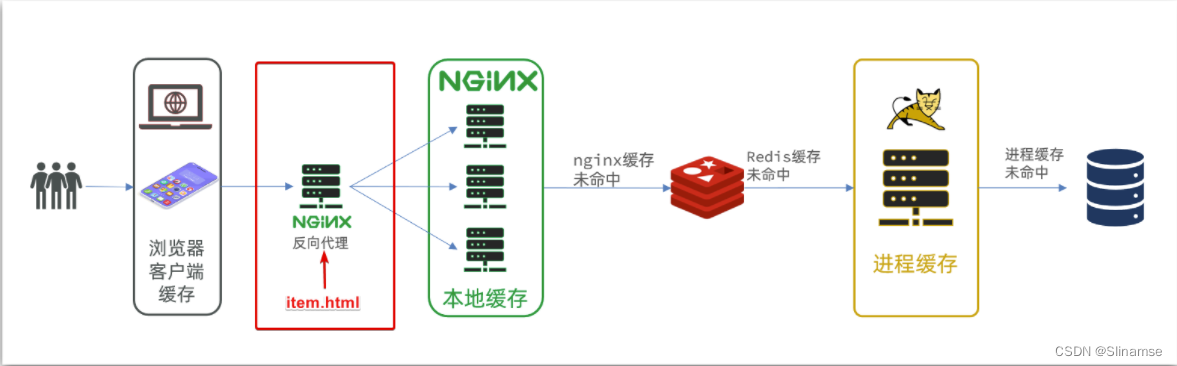 我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面放到nginx目录中。
我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面放到nginx目录中。
页面需要的数据通过ajax向服务端(nginx业务集群)查询。
运行nginx服务
这里我已经给大家准备好了nginx反向代理服务器和静态资源。
我们找到课前资料的nginx目录:

将其拷贝到一个非中文目录下,运行这个nginx服务。
运行命令:
start nginx.exe然后访问 http://localhost/item.html?id=10001即可:
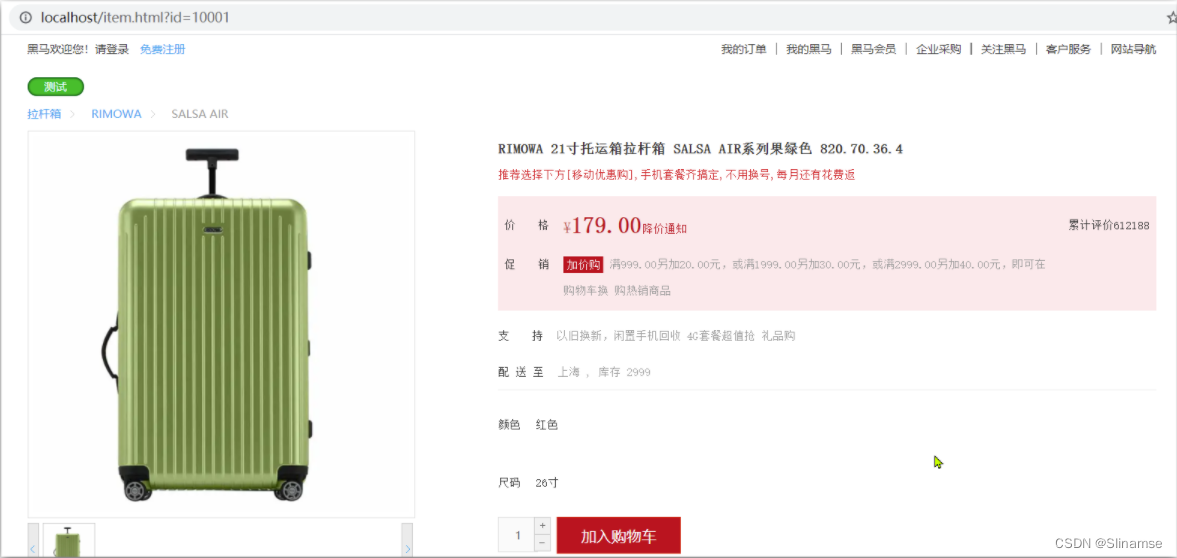
反向代理
现在,页面是假数据展示的。我们需要向服务器发送ajax请求,查询商品数据。
打开控制台,可以看到页面有发起ajax查询数据:
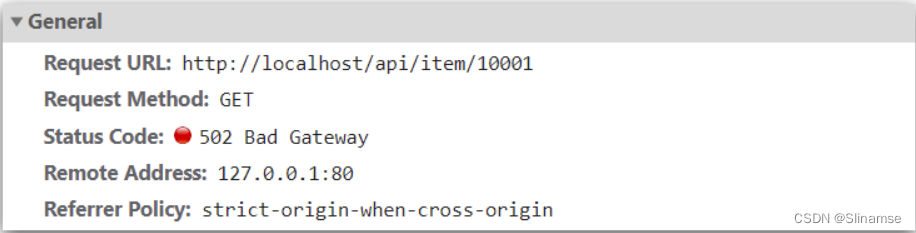
而这个请求地址同样是80端口,所以被当前的nginx反向代理了。
查看nginx的conf目录下的nginx.conf文件:
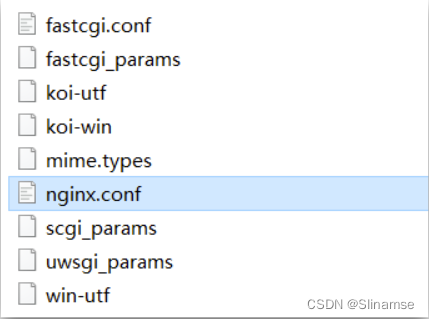
其中的关键配置如下:
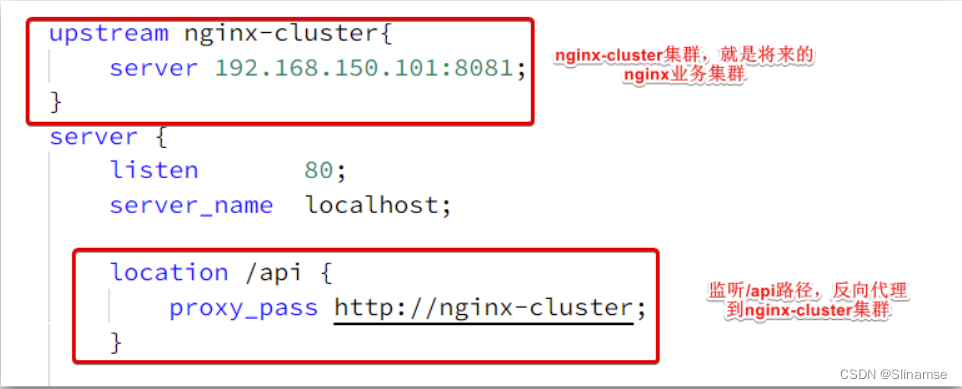
其中的192.168.150.101是我的虚拟机IP,也就是我的Nginx业务集群要部署的地方:

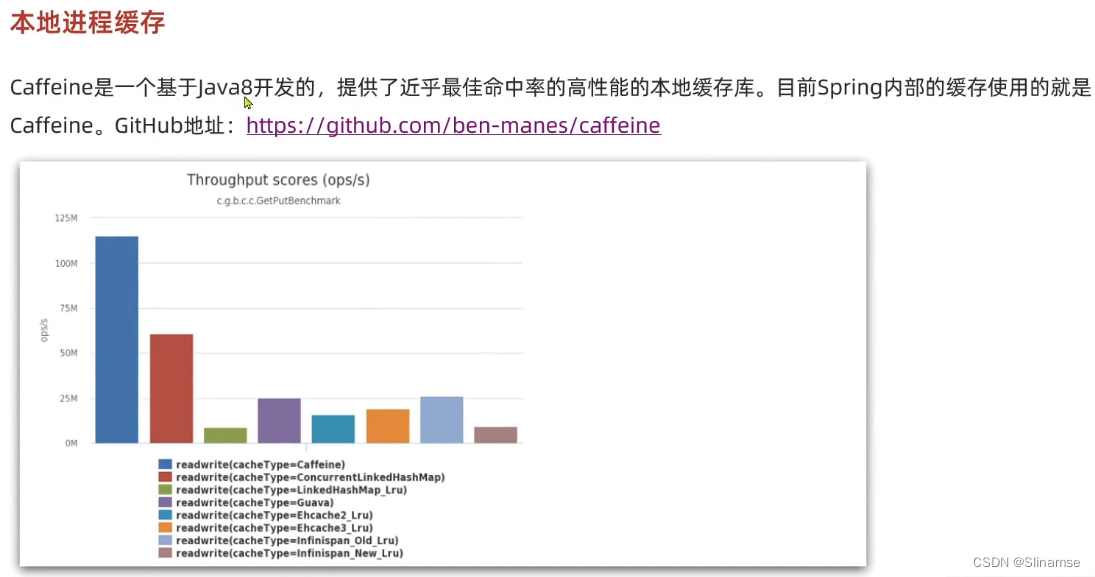



CaffeineConfig
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long, ItemStock> stockCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}ItemController
@RestController
@RequestMapping("item")
public class ItemController {
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
@Autowired
private Cache<Long, Item> itemCache;
@Autowired
private Cache<Long, ItemStock> stockCache;
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id){
return itemCache.get(id, key -> {
return itemService.query()
.ne("status", 3).eq("id", key)
.one();
});
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id){
return stockCache.get(id, key->{
return stockService.getById(key);
});
}
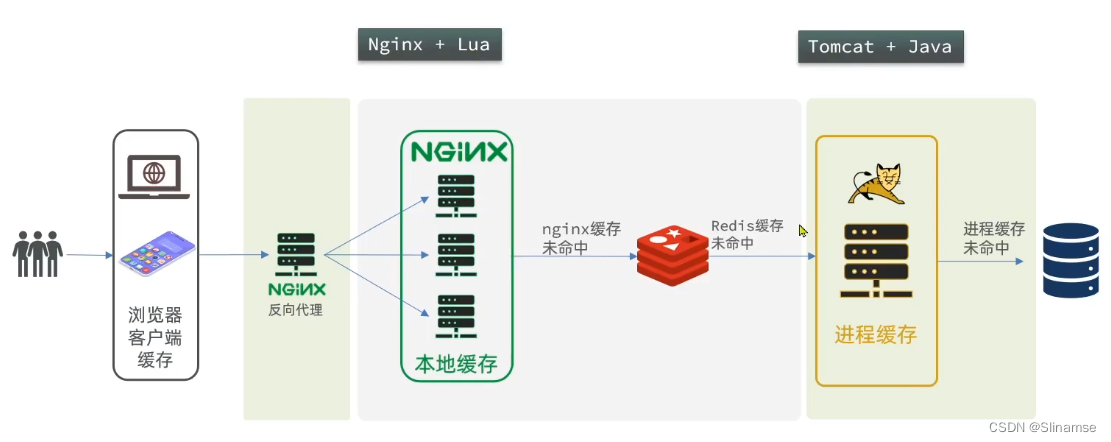
}






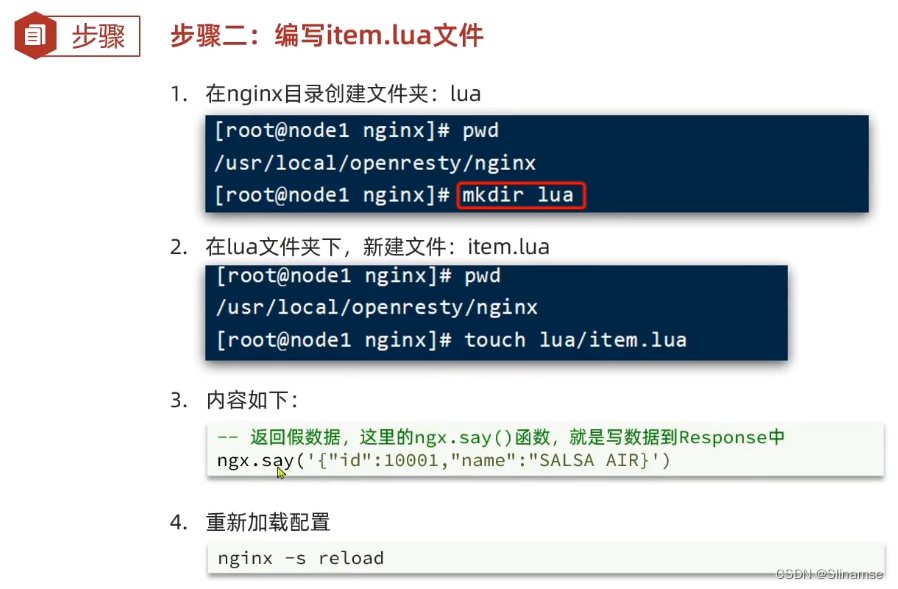
安装OpenResty
1.安装
首先你的Linux虚拟机必须联网
1)安装开发库
首先要安装OpenResty的依赖开发库,执行命令:
yum install -y pcre-devel openssl-devel gcc --skip-broken2)安装OpenResty仓库
你可以在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新我们的软件包(通过 yum check-update 命令)。运行下面的命令就可以添加我们的仓库:
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo如果提示说命令不存在,则运行:
yum install -y yum-utils 然后再重复上面的命令
3)安装OpenResty
然后就可以像下面这样安装软件包,比如 openresty:
yum install -y openresty4)安装opm工具
opm是OpenResty的一个管理工具,可以帮助我们安装一个第三方的Lua模块。
如果你想安装命令行工具 opm,那么可以像下面这样安装 openresty-opm 包:
yum install -y openresty-opm5)目录结构
默认情况下,OpenResty安装的目录是:/usr/local/openresty
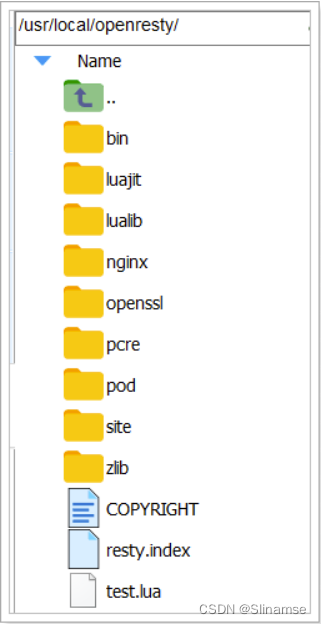
看到里面的nginx目录了吗,OpenResty就是在Nginx基础上集成了一些Lua模块。
6)配置nginx的环境变量
打开配置文件:
vi /etc/profile在最下面加入两行:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATHNGINX_HOME:后面是OpenResty安装目录下的nginx的目录
然后让配置生效:
source /etc/profile2.启动和运行
OpenResty底层是基于Nginx的,查看OpenResty目录的nginx目录,结构与windows中安装的nginx基本一致:
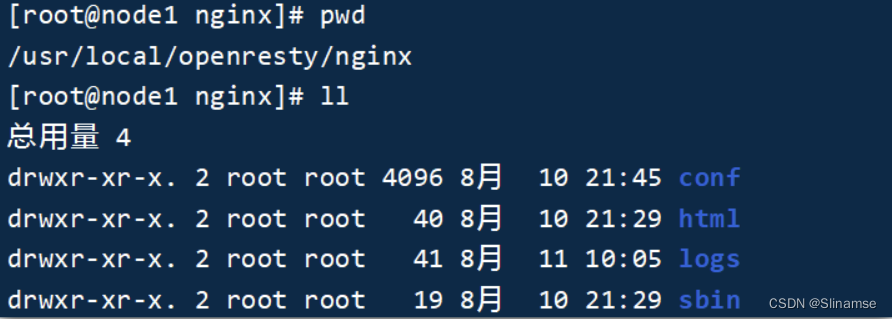
所以运行方式与nginx基本一致:
# 启动nginx
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stopnginx的默认配置文件注释太多,影响后续我们的编辑,这里将nginx.conf中的注释部分删除,保留有效部分。
修改/usr/local/openresty/nginx/conf/nginx.conf文件,内容如下:
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}在Linux的控制台输入命令以启动nginx:
nginx然后访问页面:http://192.168.150.101:8081,注意ip地址替换为你自己的虚拟机IP
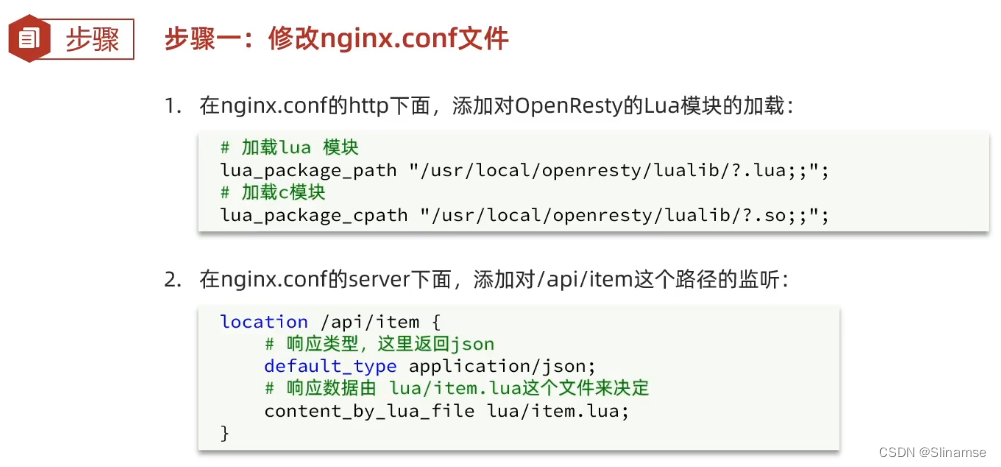
加载OpenResty的lua模块:
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; 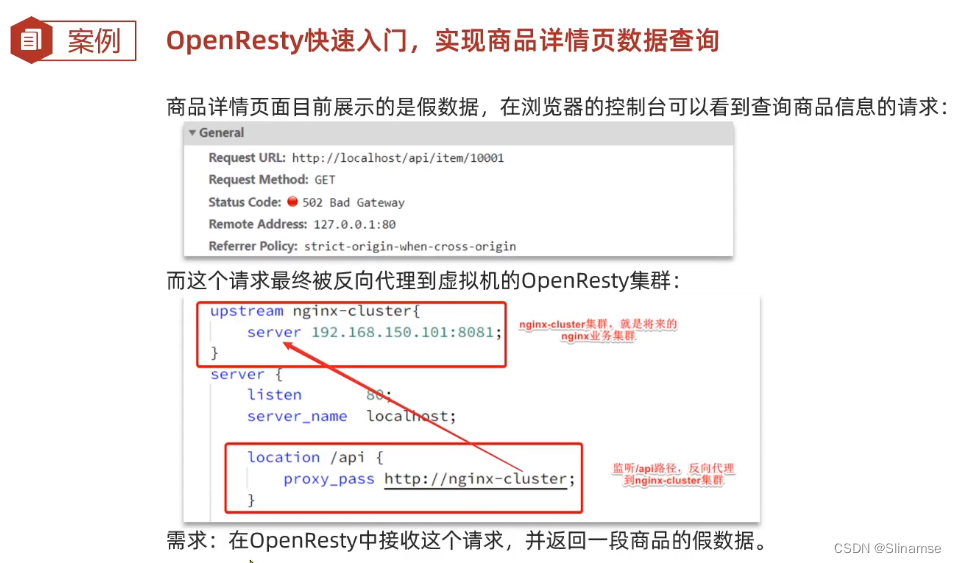
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
location /api/item{
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item。lua文件来决定
content_by_lua_file lua/item.lua;
}
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}


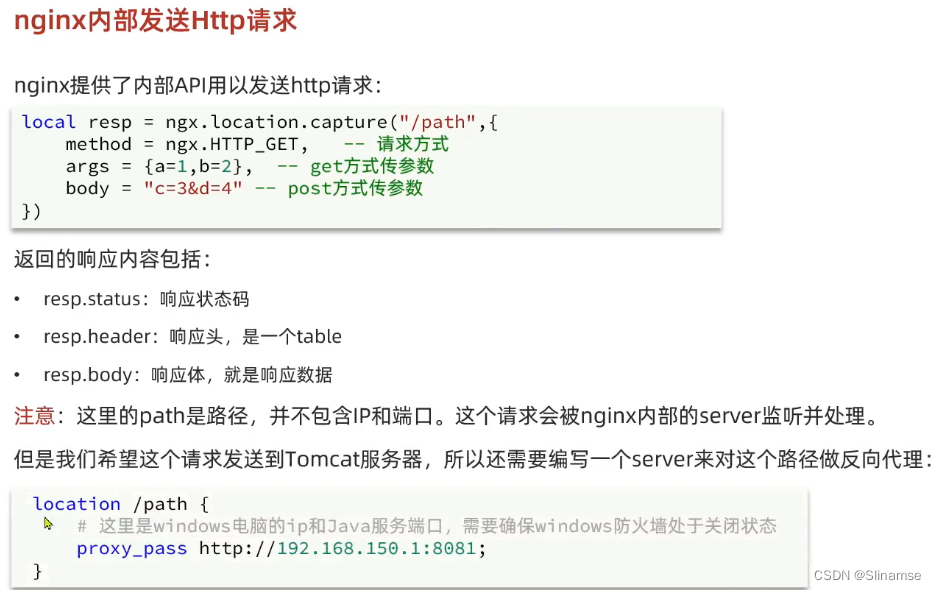


-- 导入common函数库
local common = require('common')
local read_http = common.read_http
-- 导入cjson函数库
local cjson = require('cjson')
-- 获取路径参数
local id = ngx.var[1]
--查询商品信息
local itemJSON = read_http("/item/" .. id, nil)
--查询库存信息
local stockJSON = read_http("/item/stock/" .. id, nil)
--JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
--组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为JSON 返回结果
ngx.say(cjson.encode(item))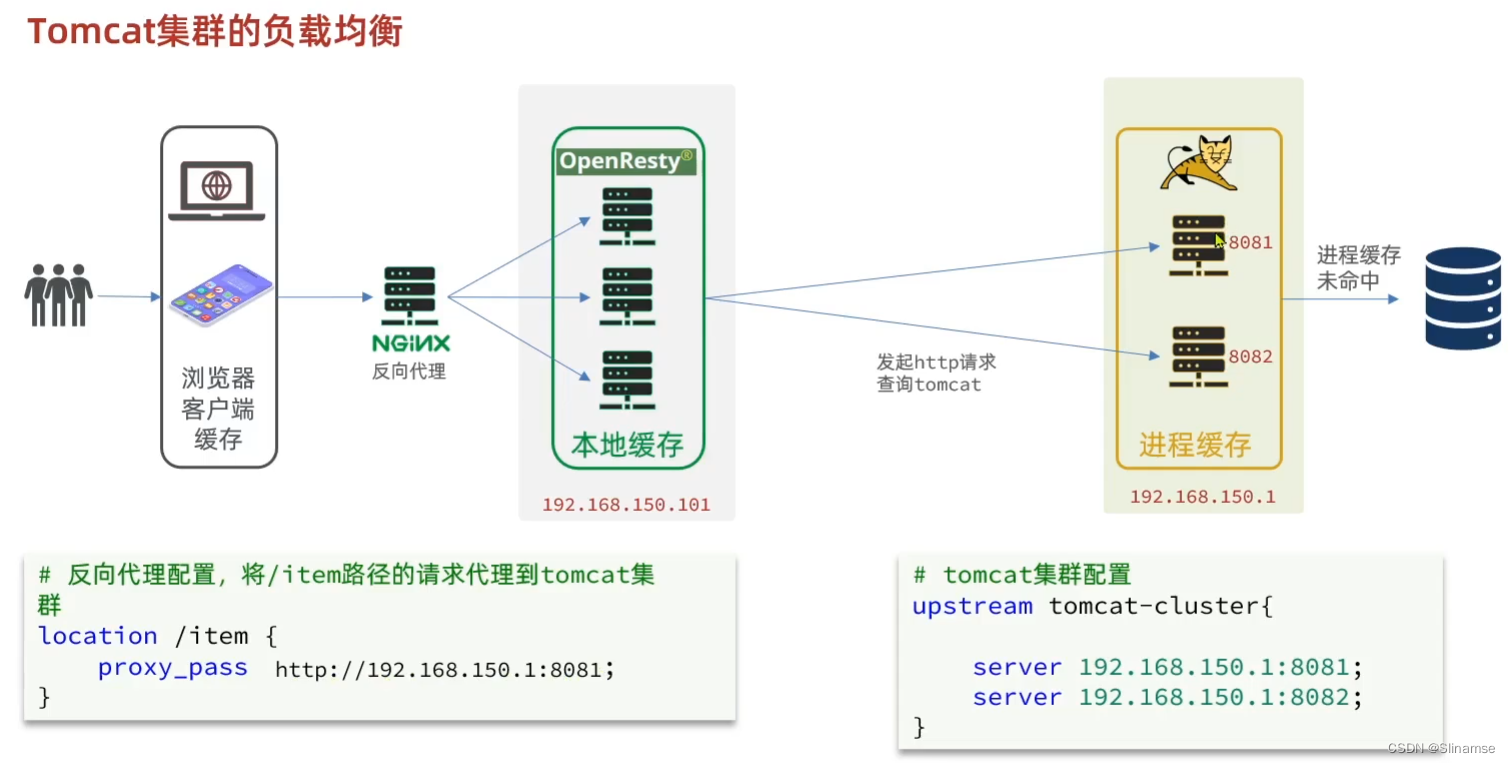
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
upstream tomcat-cluster {
hash $request_uri;
server 192.168.137.1:8081;
server 192.168.137.1:8082;
}
server {
listen 8081;
server_name localhost;
location /item {
proxy_pass http://tomcat-cluster;
}
location ~ /api/item/(\d+) {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item。lua文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}

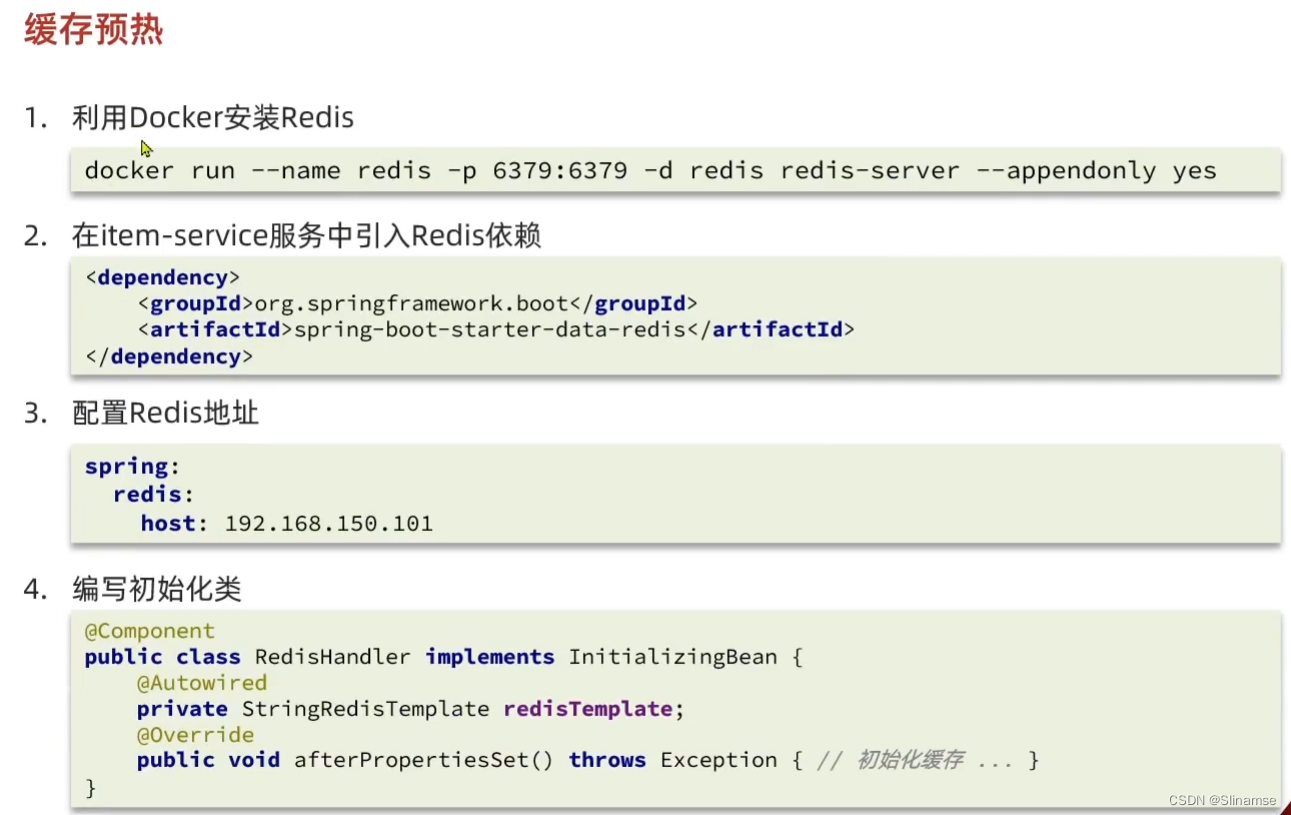
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ItemService itemService;
@Autowired
private ItemStockService itemStockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void afterPropertiesSet() throws Exception {
//初始化缓存
//1.查询商品信息
List<Item> itemList = itemService.list();
//2.放入缓存
for (Item item : itemList) {
//2.1。item序列化为JSON
String itemJson = MAPPER.writeValueAsString(item);
//2.2.存入redis
redisTemplate.opsForValue().set("item:id:" + item.getId().toString(),itemJson);
}
//3.查询货存信息
List<ItemStock> itemStockList = itemStockService.list();
//4.放入缓存
for (ItemStock itemStock : itemStockList) {
String itemStockJson = MAPPER.writeValueAsString(itemStock);
redisTemplate.opsForValue().set("stock:id" + itemStock.getId().toString(),itemStockJson);
}
}
}

--导入redis
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new()
-- 设置Redis超时时间
red:set_timeouts(1000, 1000, 1000)
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
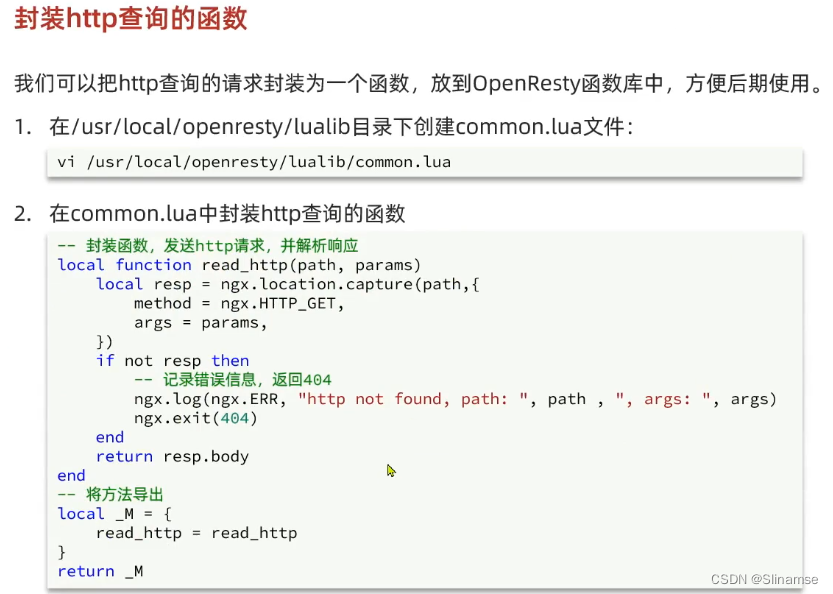
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson函数库
local cjson = require('cjson')
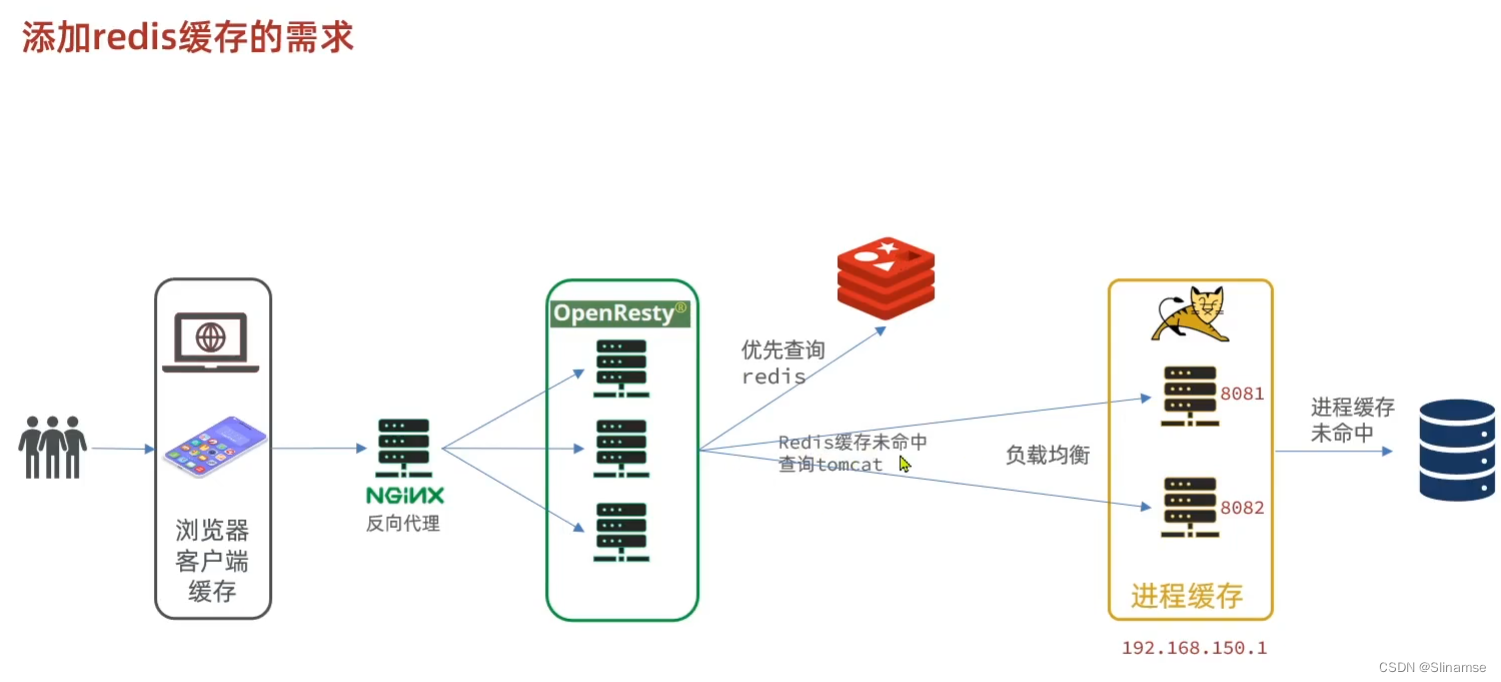
-- 封装函数, 先查询redis, 再查询http
local function read_data(key, path, params)
-- 查询redis
local resp = read_redis("127.0.0.1", 6379, key)
-- 判断redis是否命中
if not resp then
-- Redis查询失败,查询http
resp = read_http(path, params)
end
return resp
end
-- 获取路径参数
local id = ngx.var[1]
--查询商品信息
local itemJSON = read_data("item:id:" .. id,"/item/" .. id, nil)
--查询库存信息
local stockJSON = read_data("item:stock:id:" .. id,"/item/stock/" .. id, nil)
--JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
--组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为JSON 返回结果
ngx.say(cjson.encode(item))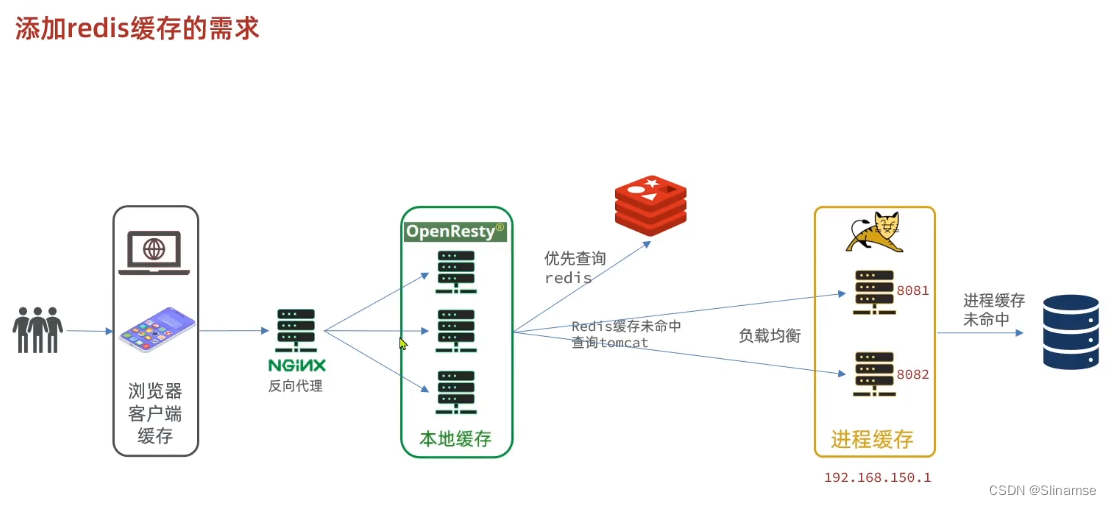
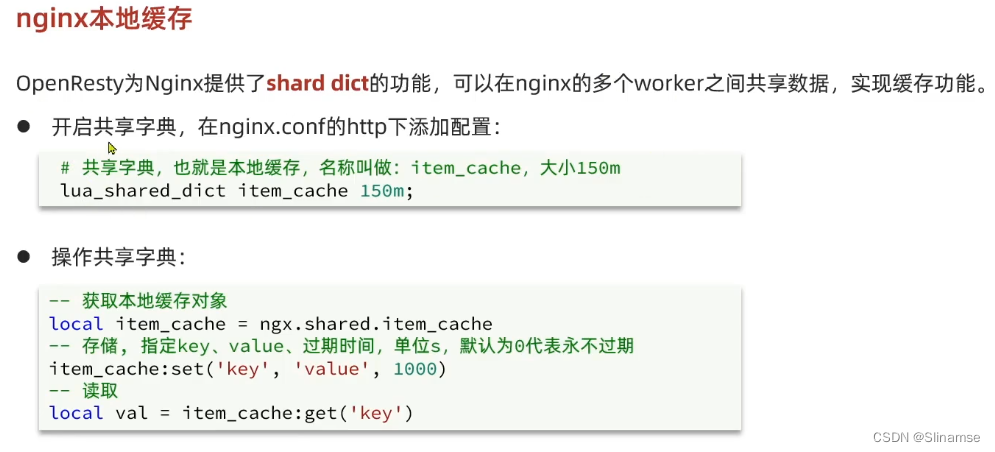
 nginx.conf
nginx.conf
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
#添加共享词典,本地缓存
lua_shared_dict item_cache 150m;
upstream tomcat-cluster {
hash $request_uri;
server 192.168.137.1:8081;
server 192.168.137.1:8082;
}
server {
listen 8081;
server_name localhost;
location /item {
proxy_pass http://tomcat-cluster;
}
location ~ /api/item/(\d+) {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item。lua文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
item.lua
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson函数库
local cjson = require('cjson')
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装函数, 先查询redis, 再查询http
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
-- 判断本地缓存是否命中
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)
--本地缓存查询失败,查询redis
val = read_redis("127.0.0.1", 6379, key)
-- 判断redis是否命中
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key:", key)
-- Redis查询失败,查询http
val = read_http(path, params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
-- 获取路径参数
local id = ngx.var[1]
--查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800,"/item/" .. id, nil)
--查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, 60,"/item/stock/" .. id, nil)
--JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
--组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为JSON 返回结果
ngx.say(cjson.encode(item))common.lua
--导入redis
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new()
-- 设置Redis超时时间
red:set_timeouts(1000, 1000, 1000)
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
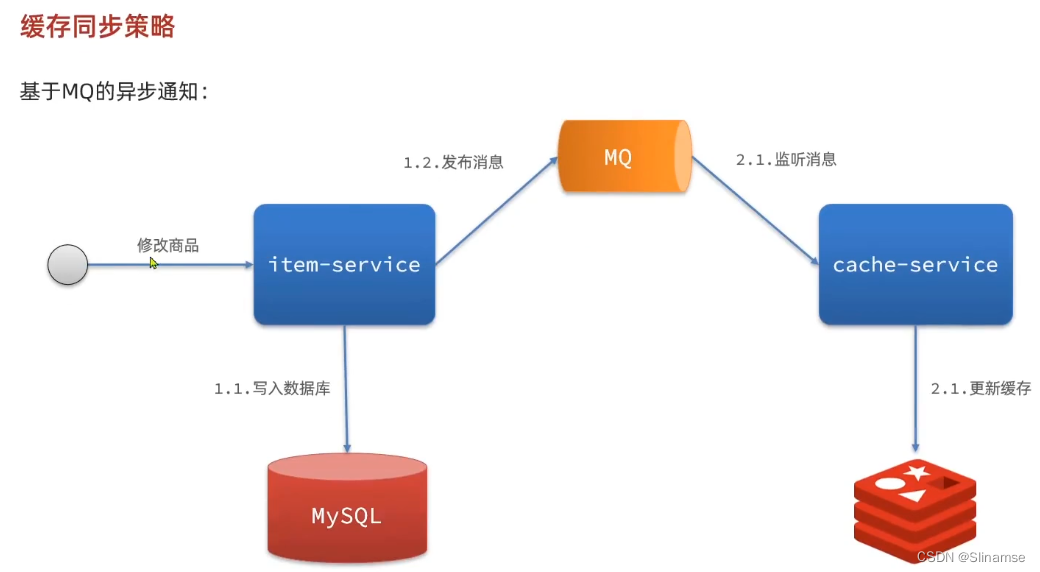
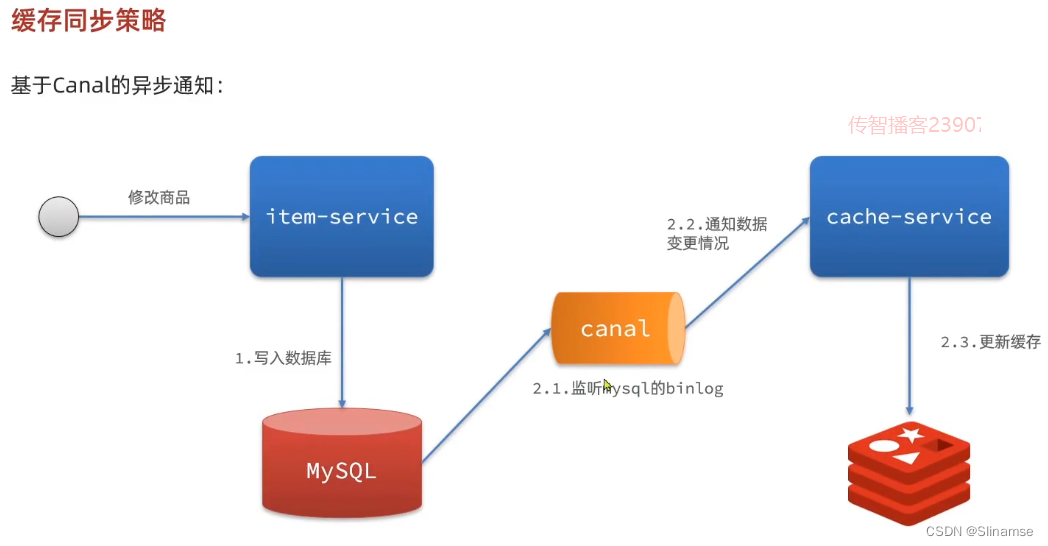
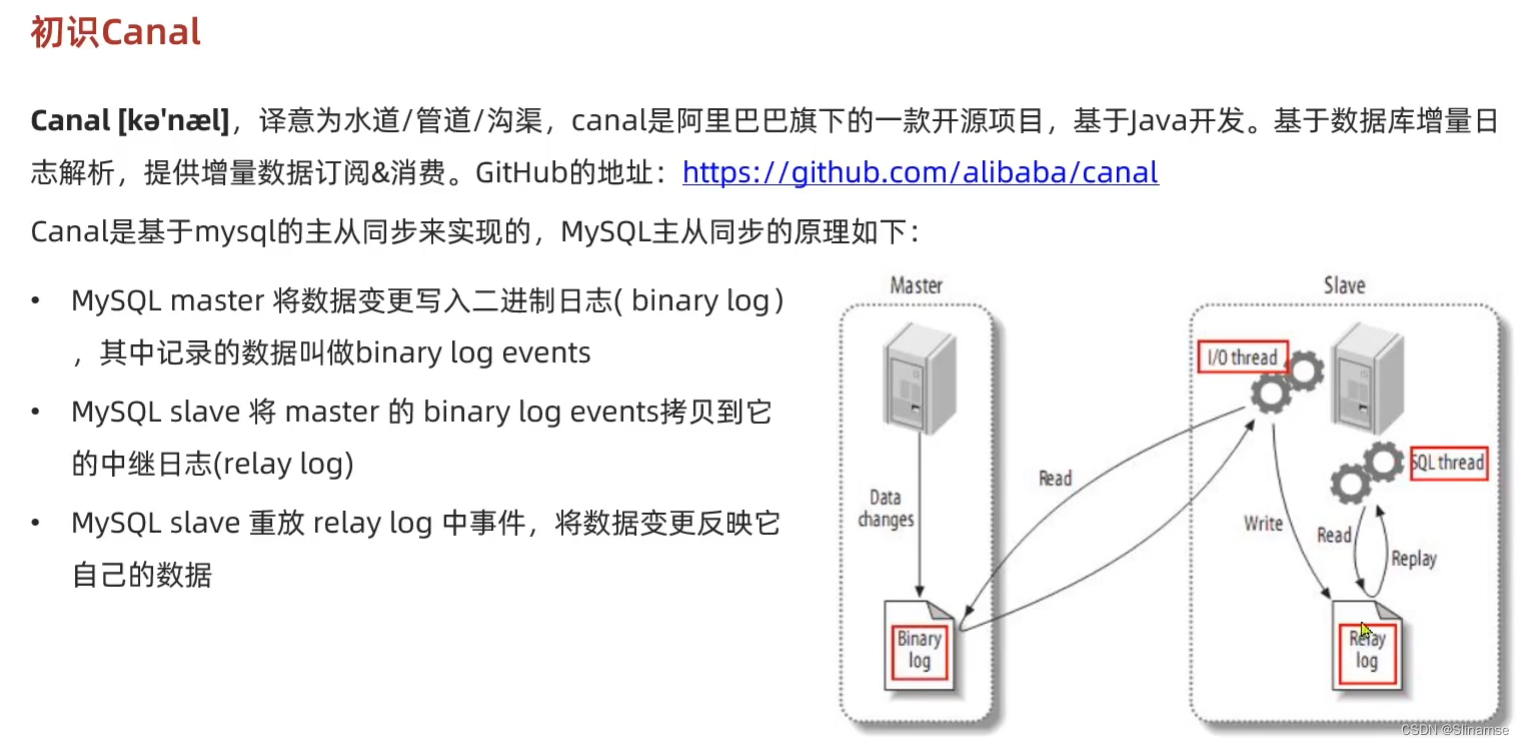
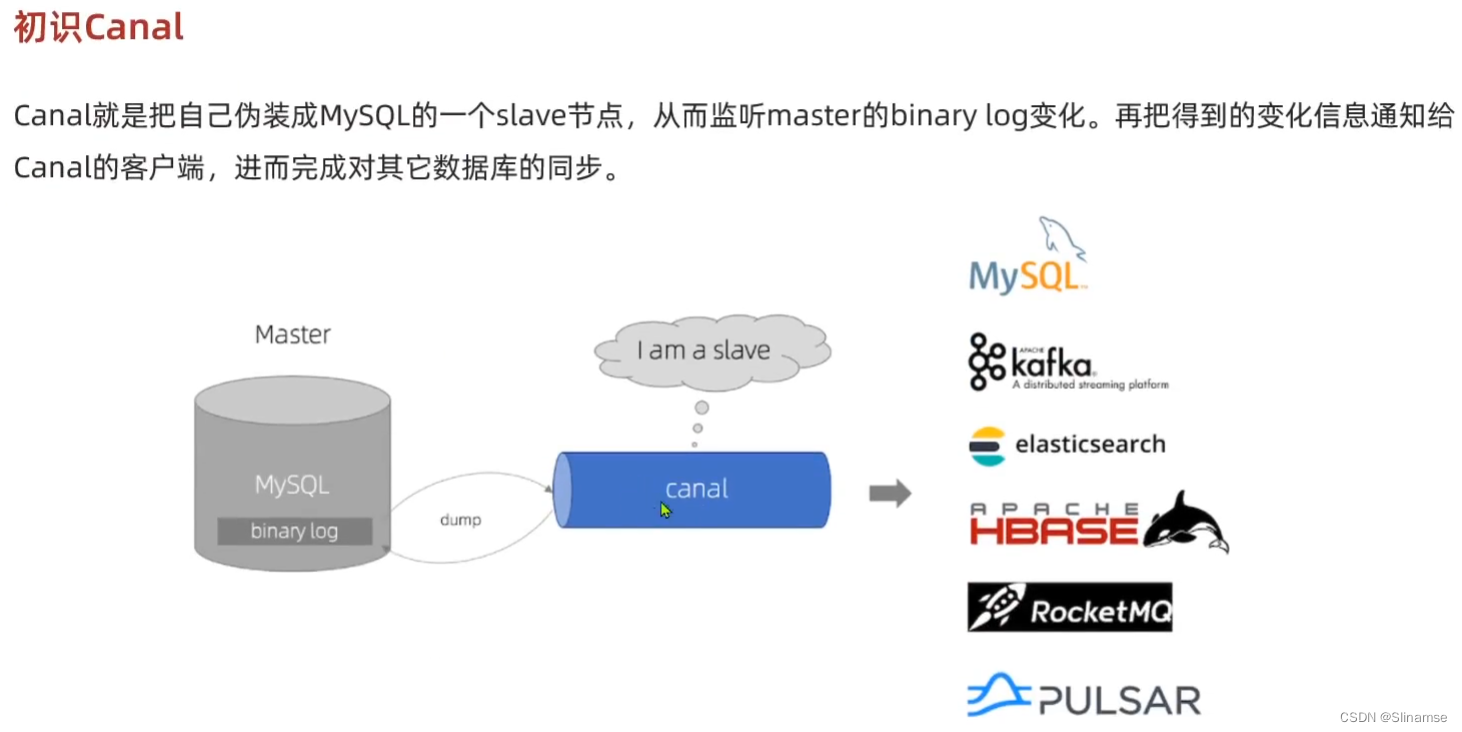
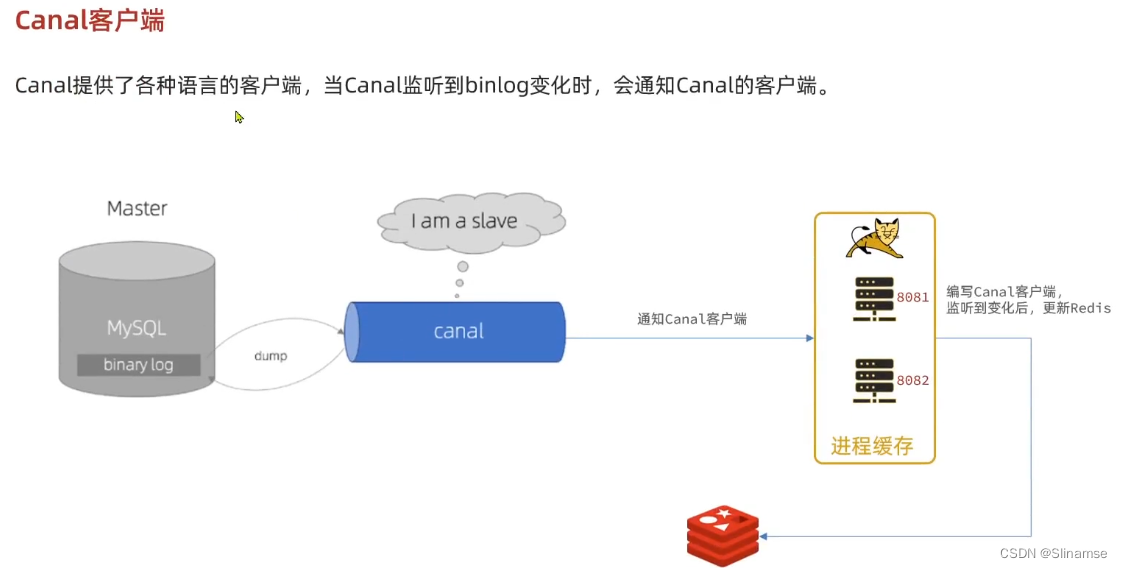
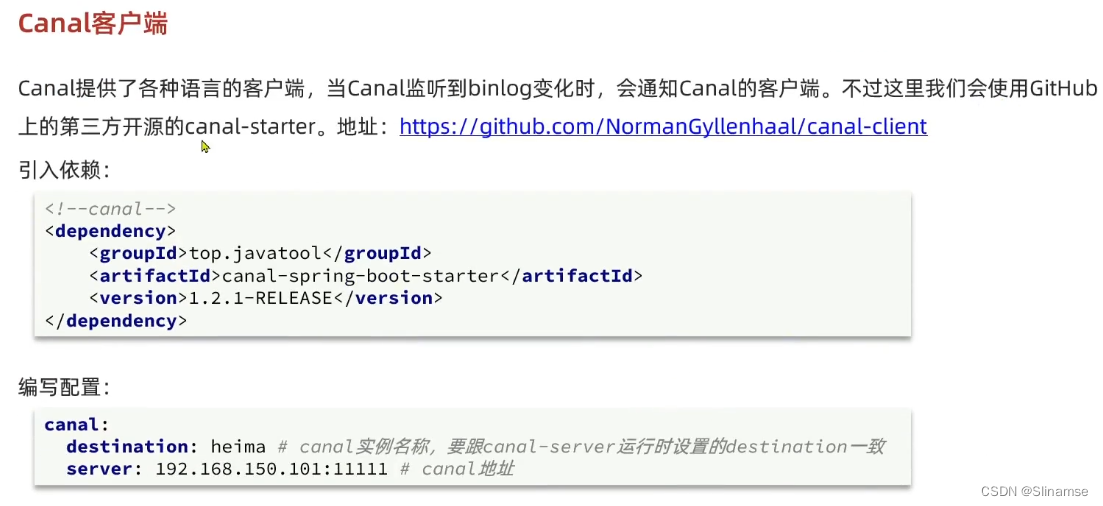
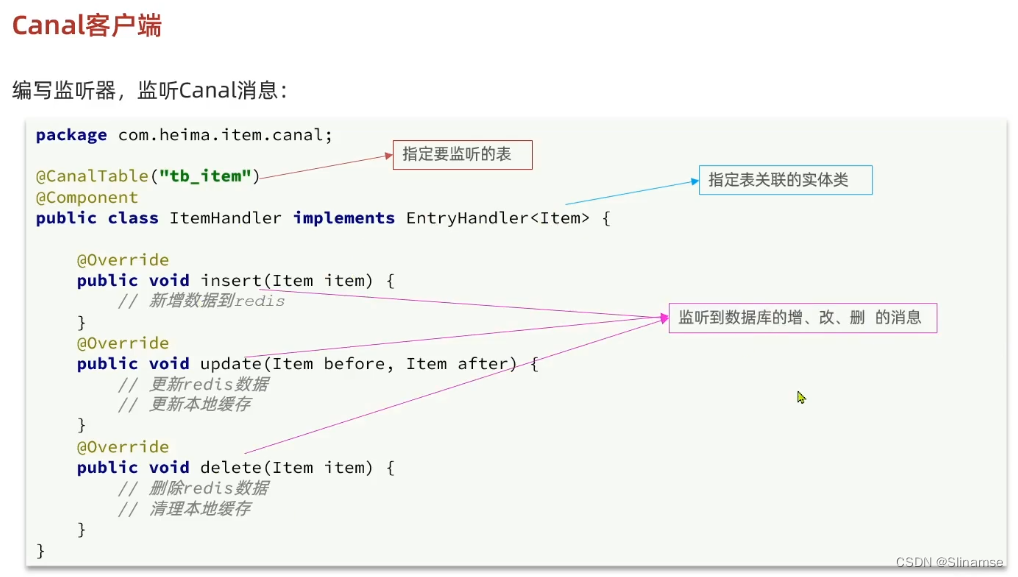
安装和配置Canal
下面我们就开启mysql的主从同步机制,让Canal来模拟salve
1.开启MySQL主从
Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。
这里以之前用Docker运行的mysql为例:
1.1.开启binlog
打开mysql容器挂载的日志文件,我的在/tmp/mysql/conf目录:
修改文件:
vi /tmp/mysql/conf/my.cnf添加内容:
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima配置解读:
-
log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-bin -
binlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库
最终效果:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima1.2.设置用户权限
接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对heima这个库的操作权限。
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;重启mysql容器即可
docker restart mysql测试设置是否成功:在mysql控制台,或者Navicat中,输入命令:
show master status;
2.安装Canal
2.1.创建网络
我们需要创建一个网络,将MySQL、Canal、MQ放到同一个Docker网络中:
docker network create heima让mysql加入这个网络:
docker network connect heima mysql2.3.安装Canal
课前资料中提供了canal的镜像压缩包:

大家可以上传到虚拟机,然后通过命令导入:
docker load -i canal.tar然后运行命令创建Canal容器:
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:v1.1.5说明:
-
-p 11111:11111:这是canal的默认监听端口 -
-e canal.instance.master.address=mysql:3306:数据库地址和端口,如果不知道mysql容器地址,可以通过docker inspect 容器id来查看 -
-e canal.instance.dbUsername=canal:数据库用户名 -
-e canal.instance.dbPassword=canal:数据库密码 -
-e canal.instance.filter.regex=:要监听的表名称
表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2 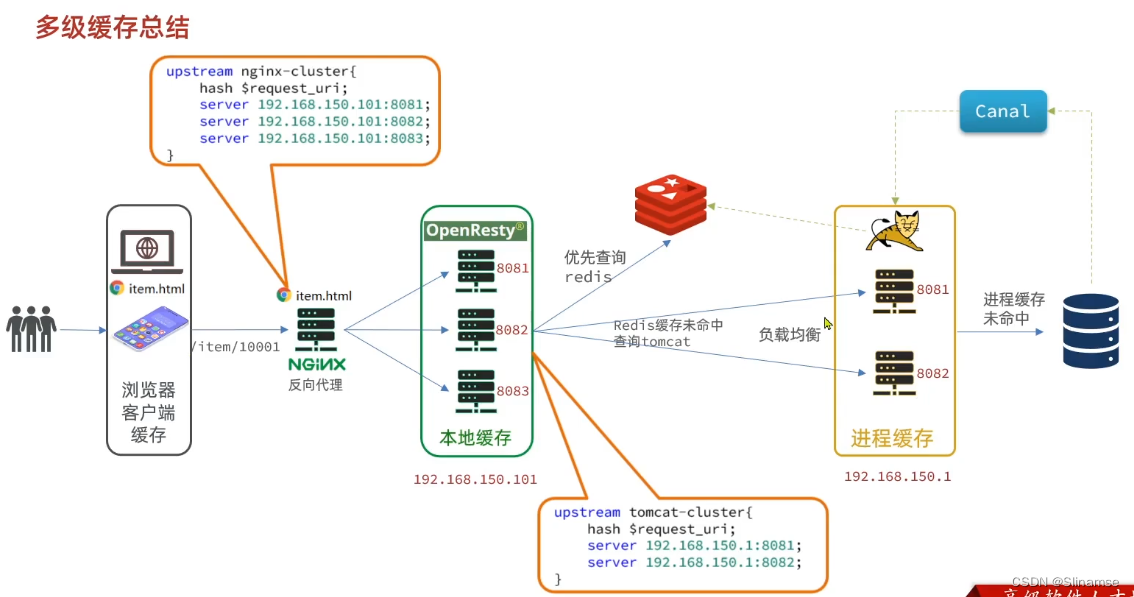
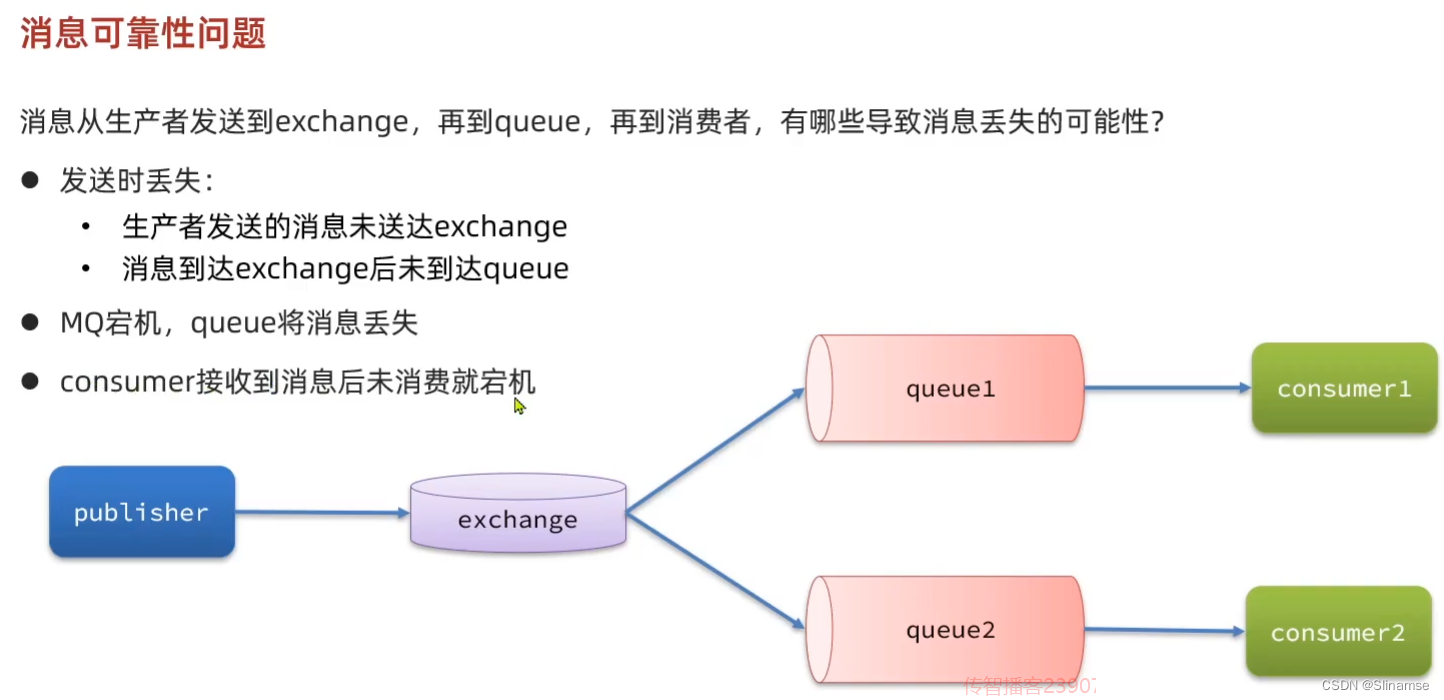

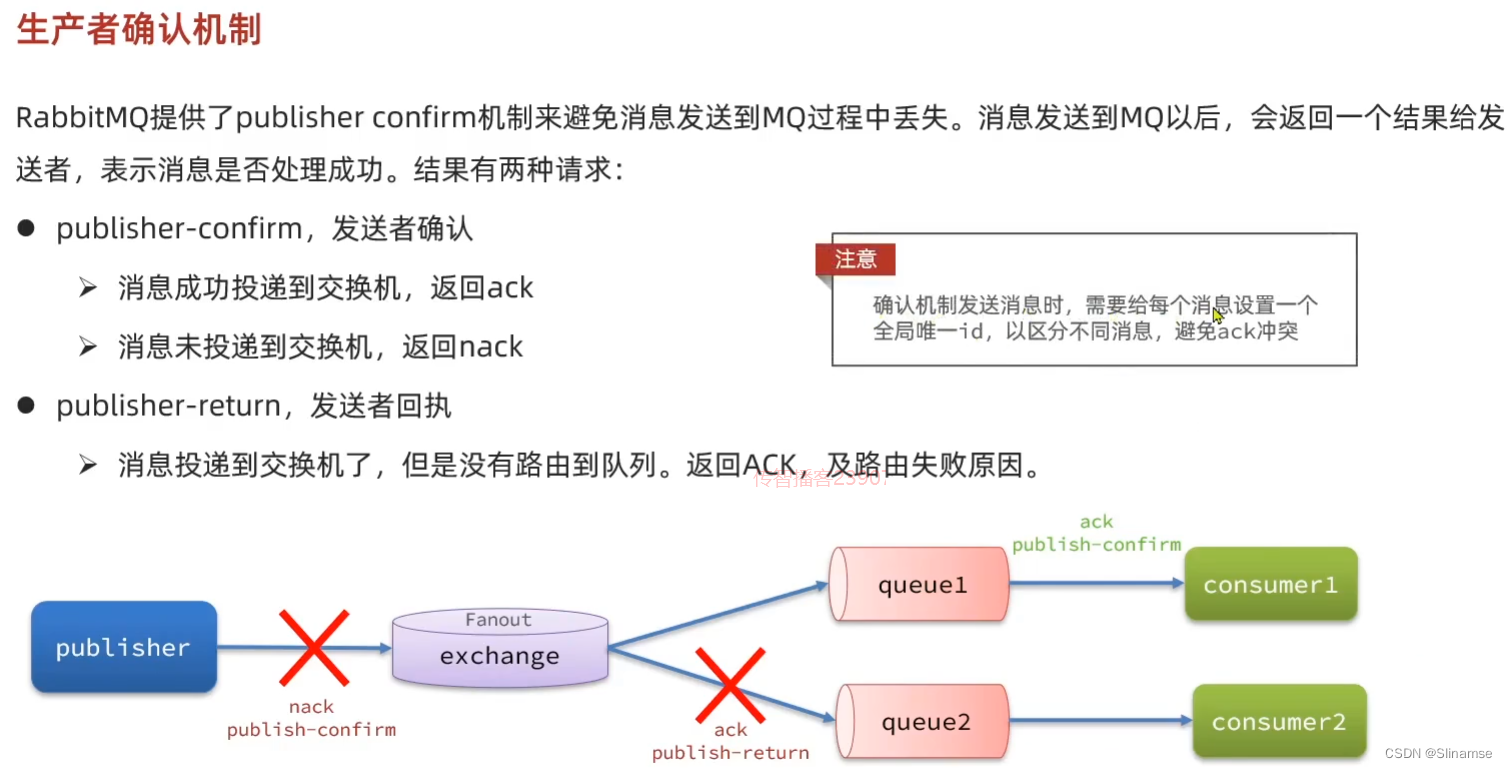





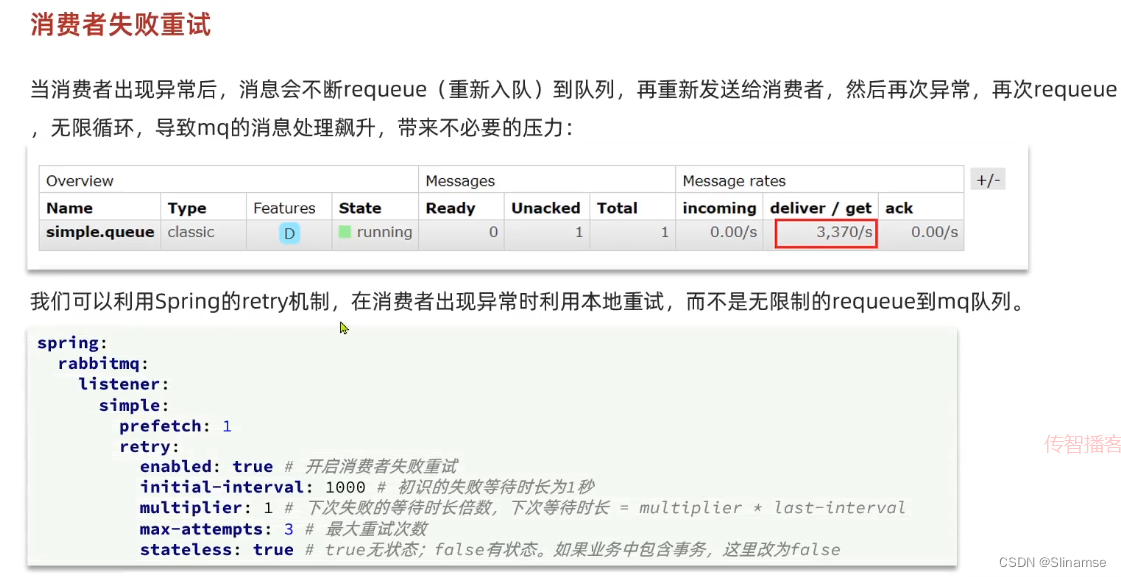
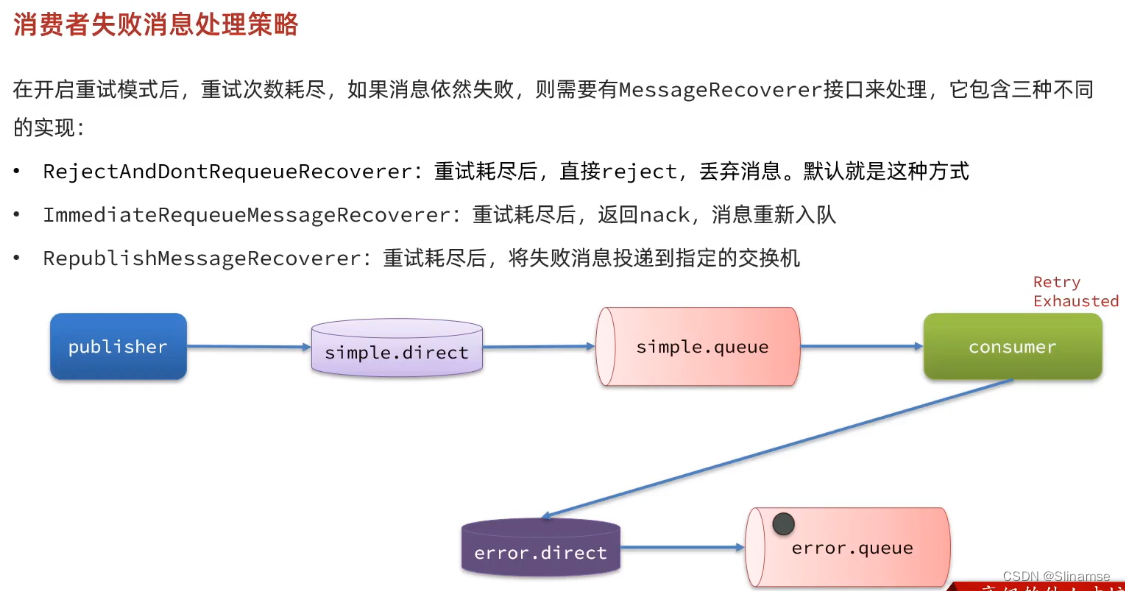


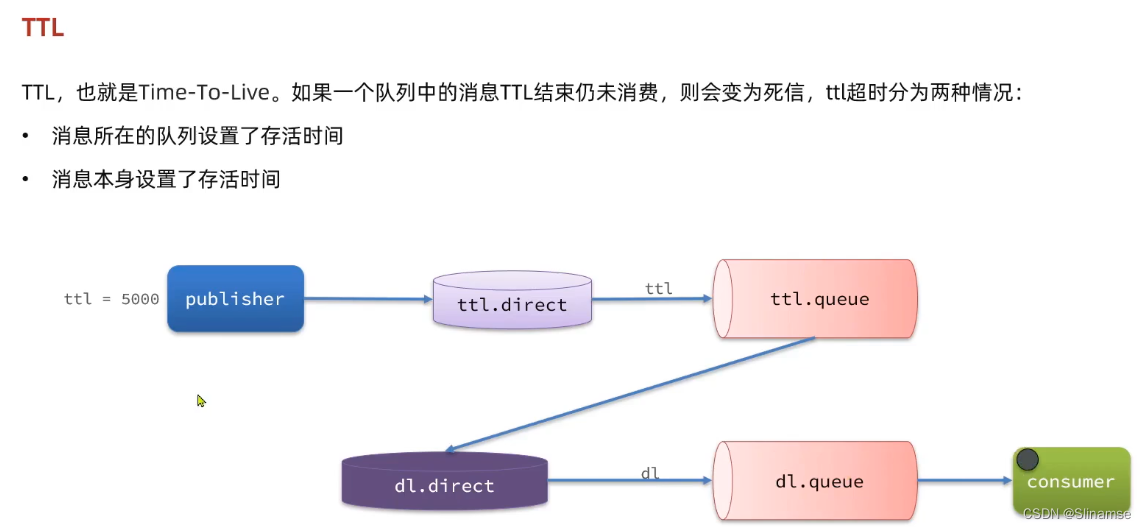
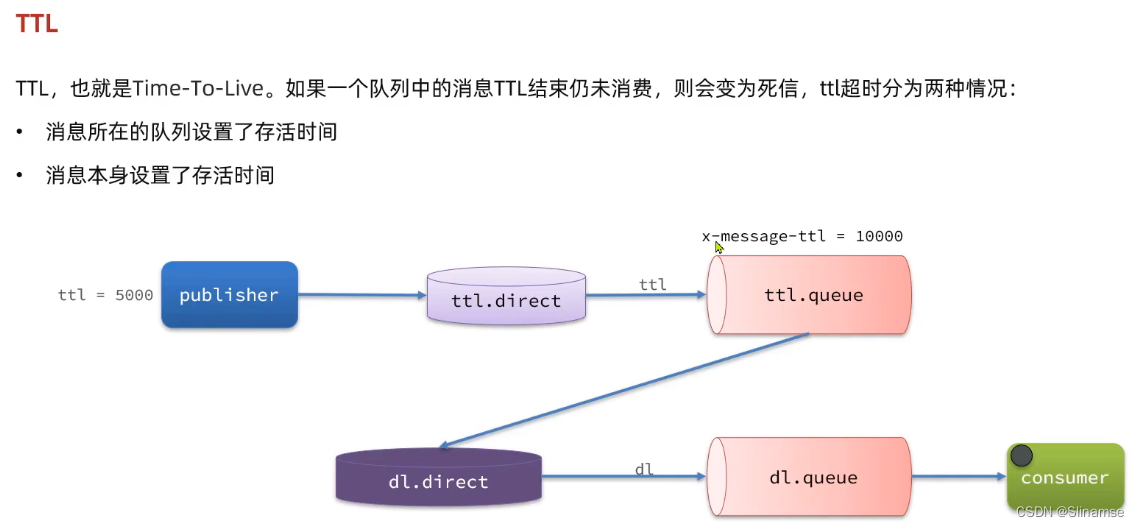
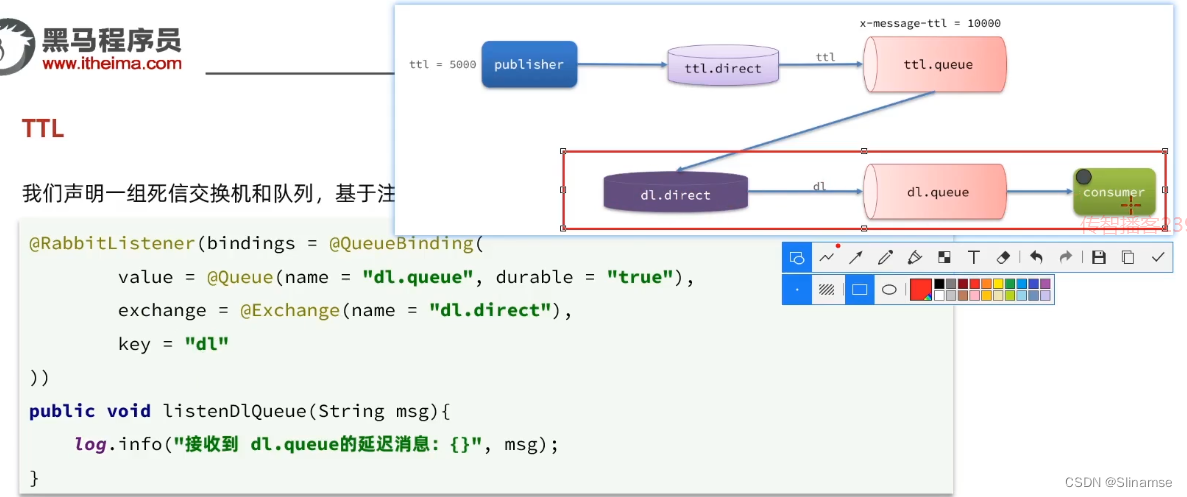


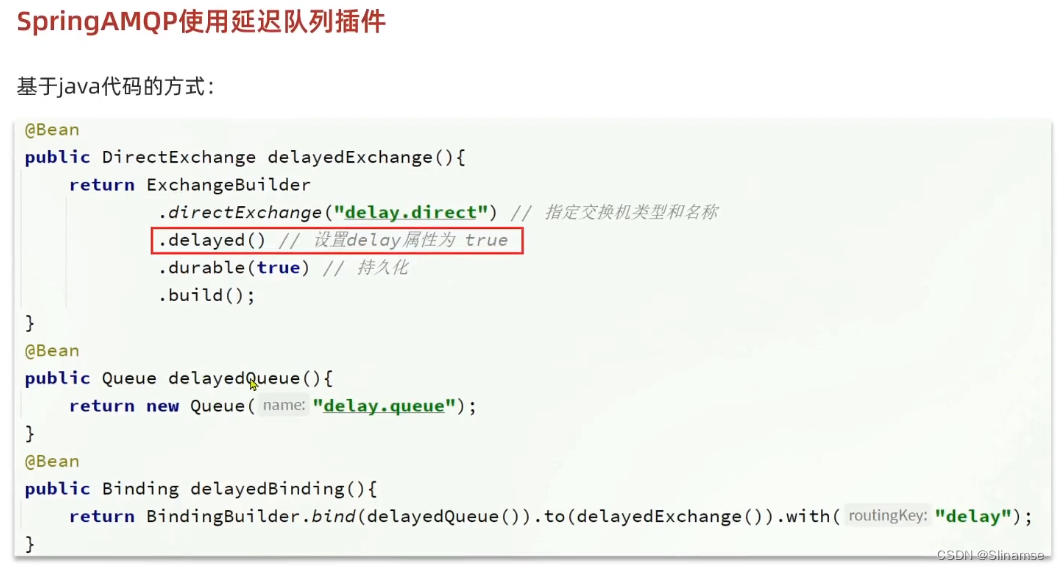
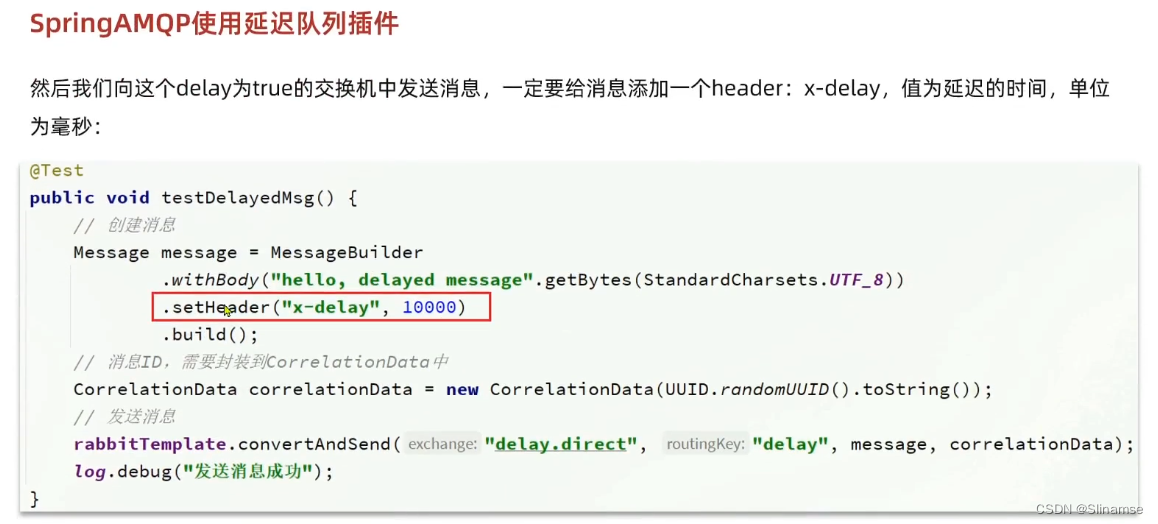
2.安装DelayExchange插件
官方的安装指南地址为:Scheduling Messages with RabbitMQ | RabbitMQ - Blog
上述文档是基于linux原生安装RabbitMQ,然后安装插件。
因为我们之前是基于Docker安装RabbitMQ,所以下面我们会讲解基于Docker来安装RabbitMQ插件。
2.1.下载插件
RabbitMQ有一个官方的插件社区,地址为:Community Plugins — RabbitMQ
其中包含各种各样的插件,包括我们要使用的DelayExchange插件:
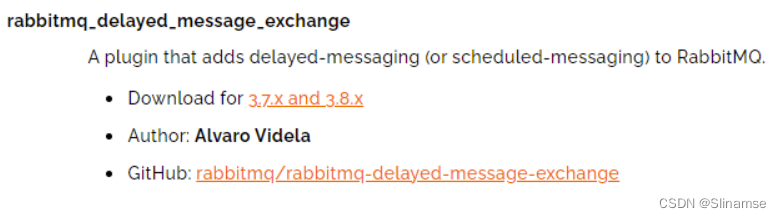
大家可以去对应的GitHub页面下载3.8.9版本的插件,地址为https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/tag/3.8.9这个对应RabbitMQ的3.8.5以上版本。
课前资料也提供了下载好的插件:
2.2.上传插件
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。如果不是基于Docker的同学,请参考第一章部分,重新创建Docker容器。
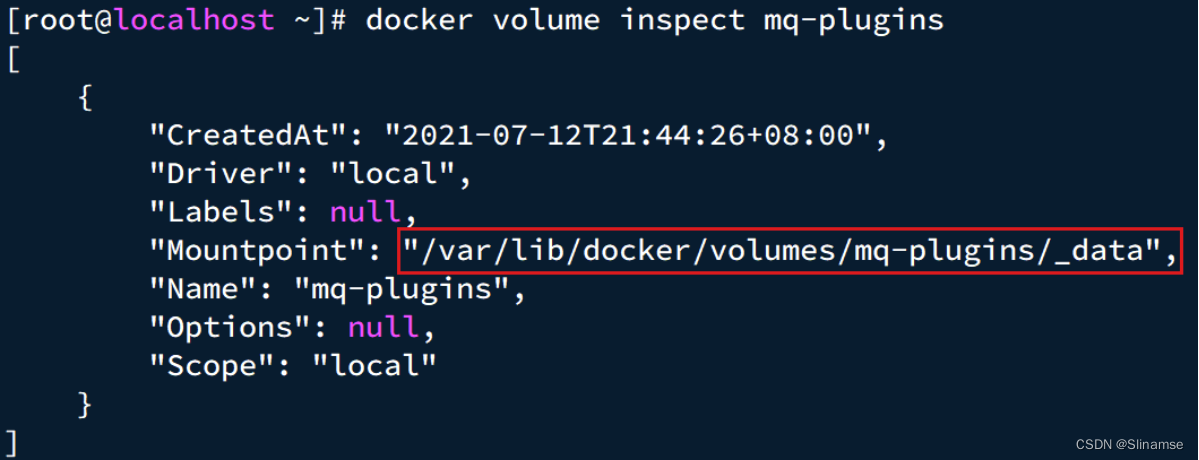
我们之前设定的RabbitMQ的数据卷名称为mq-plugins,所以我们使用下面命令查看数据卷:
docker volume inspect mq-plugins可以得到下面结果:
接下来,将插件上传到这个目录即可:
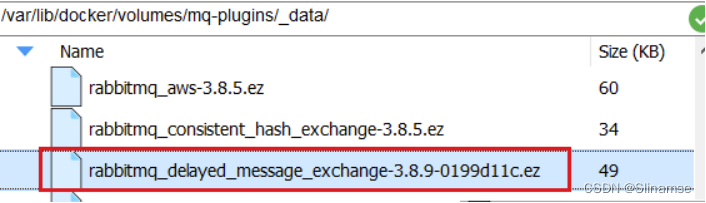
2.3.安装插件
最后就是安装了,需要进入MQ容器内部来执行安装。我的容器名为mq,所以执行下面命令:
docker exec -it mq bash执行时,请将其中的 -it 后面的mq替换为你自己的容器名.
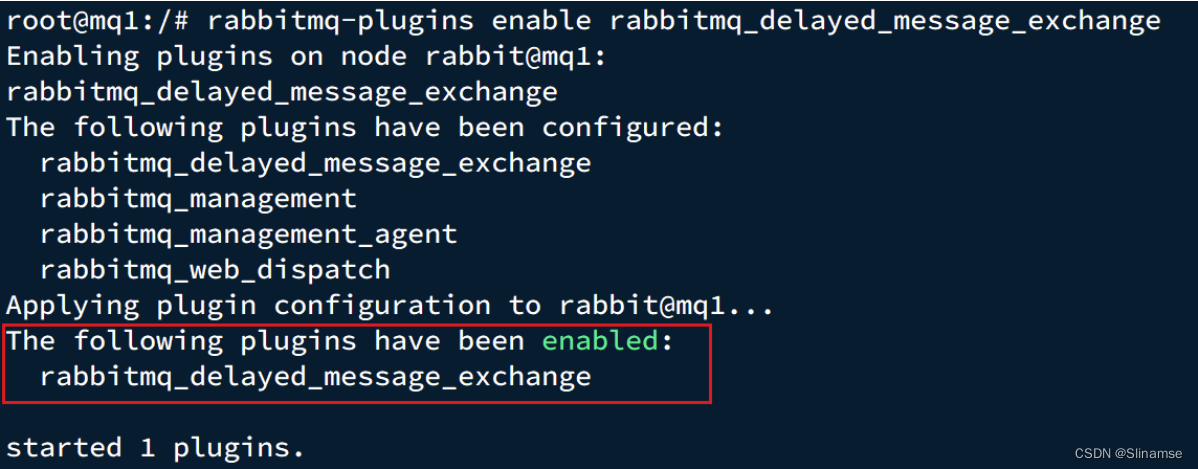
进入容器内部后,执行下面命令开启插件:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange结果如下:




集群部署
接下来,我们看看如何安装RabbitMQ的集群。
2.1.集群分类
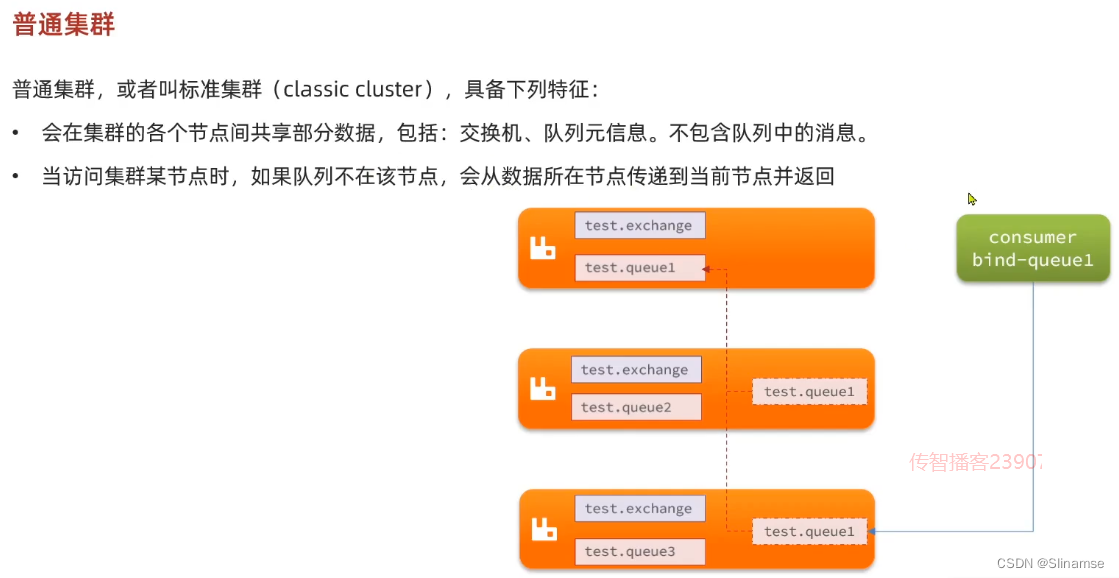
在RabbitMQ的官方文档中,讲述了两种集群的配置方式:
-
普通模式:普通模式集群不进行数据同步,每个MQ都有自己的队列、数据信息(其它元数据信息如交换机等会同步)。例如我们有2个MQ:mq1,和mq2,如果你的消息在mq1,而你连接到了mq2,那么mq2会去mq1拉取消息,然后返回给你。如果mq1宕机,消息就会丢失。
-
镜像模式:与普通模式不同,队列会在各个mq的镜像节点之间同步,因此你连接到任何一个镜像节点,均可获取到消息。而且如果一个节点宕机,并不会导致数据丢失。不过,这种方式增加了数据同步的带宽消耗。
我们先来看普通模式集群,我们的计划部署3节点的mq集群:
| 主机名 | 控制台端口 | amqp通信端口 |
|---|---|---|
| mq1 | 8081 ---> 15672 | 8071 ---> 5672 |
| mq2 | 8082 ---> 15672 | 8072 ---> 5672 |
| mq3 | 8083 ---> 15672 | 8073 ---> 5672 |
集群中的节点标示默认都是:rabbit@[hostname],因此以上三个节点的名称分别为:
-
rabbit@mq1
-
rabbit@mq2
-
rabbit@mq3
2.2.获取cookie
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 cookie 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang cookie。cookie 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 cookie。实例之间也需要它来相互通信。
我们先在之前启动的mq容器中获取一个cookie值,作为集群的cookie。执行下面的命令
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie可以看到cookie值如下:
FXZMCVGLBIXZCDEMMVZQ接下来,停止并删除当前的mq容器,我们重新搭建集群。
docker rm -f mq
2.3.准备集群配置
在/tmp目录新建一个配置文件 rabbitmq.conf:
cd /tmp
# 创建文件
touch rabbitmq.conf文件内容如下:
loopback_users.guest = false
listeners.tcp.default = 5672
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@mq1
cluster_formation.classic_config.nodes.2 = rabbit@mq2
cluster_formation.classic_config.nodes.3 = rabbit@mq3再创建一个文件,记录cookie
cd /tmp
# 创建cookie文件
touch .erlang.cookie
# 写入cookie
echo "FXZMCVGLBIXZCDEMMVZQ" > .erlang.cookie
# 修改cookie文件的权限
chmod 600 .erlang.cookie准备三个目录,mq1、mq2、mq3:
cd /tmp
# 创建目录
mkdir mq1 mq2 mq3然后拷贝rabbitmq.conf、cookie文件到mq1、mq2、mq3:
# 进入/tmp
cd /tmp
# 拷贝
cp rabbitmq.conf mq1
cp rabbitmq.conf mq2
cp rabbitmq.conf mq3
cp .erlang.cookie mq1
cp .erlang.cookie mq2
cp .erlang.cookie mq32.4.启动集群
创建一个网络:
docker network create mq-netdocker volume create
运行命令
docker run -d --net mq-net \
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq1 \
--hostname mq1 \
-p 8071:5672 \
-p 8081:15672 \
rabbitmq:3.8-managementdocker run -d --net mq-net \
-v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq2 \
--hostname mq2 \
-p 8072:5672 \
-p 8082:15672 \
rabbitmq:3.8-managementdocker run -d --net mq-net \
-v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq3 \
--hostname mq3 \
-p 8073:5672 \
-p 8083:15672 \
rabbitmq:3.8-management2.5.测试
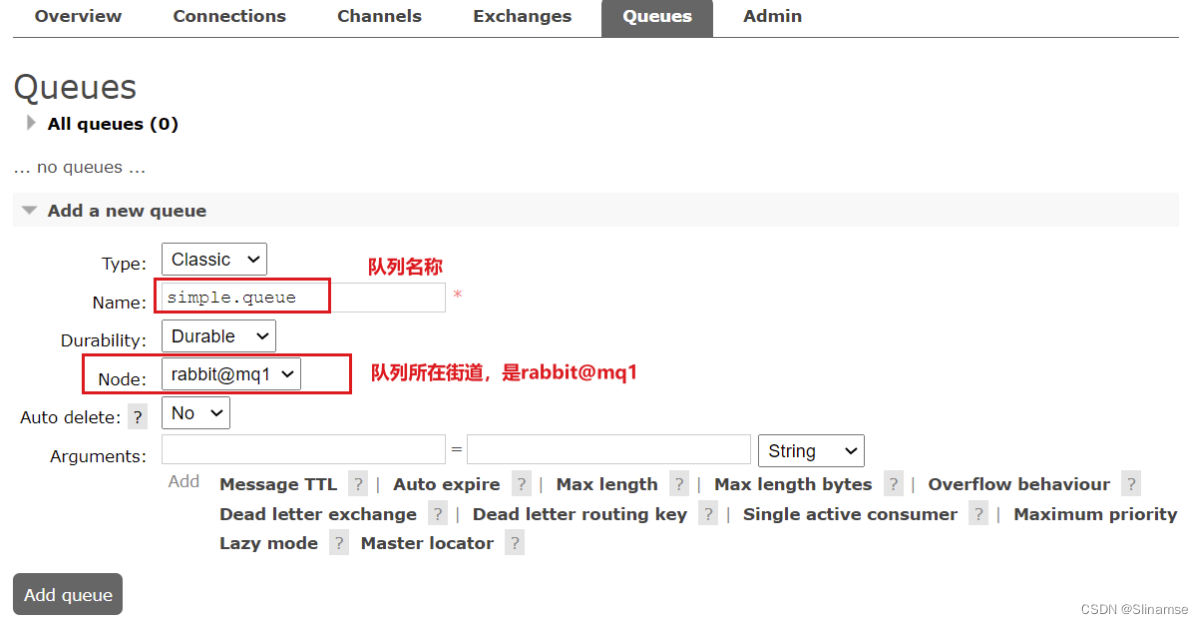
在mq1这个节点上添加一个队列:
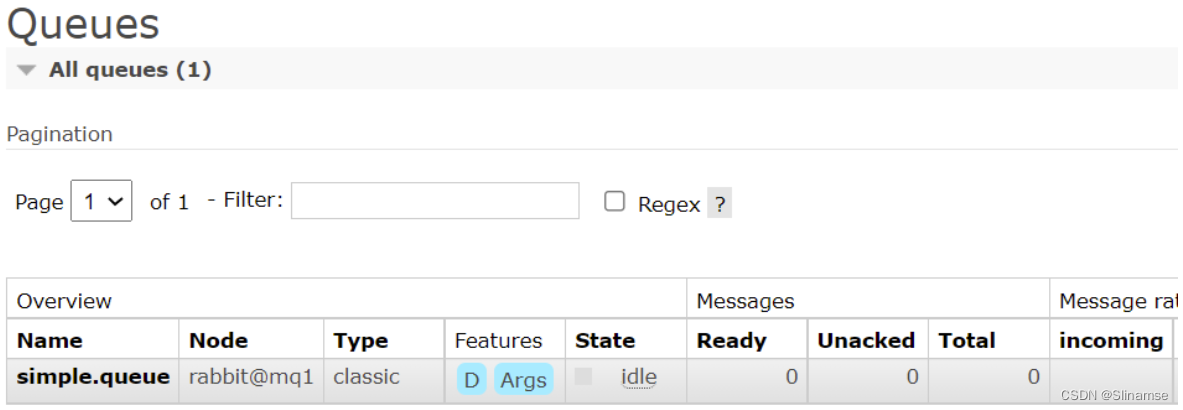
如图,在mq2和mq3两个控制台也都能看到:
2.5.1.数据共享测试
点击这个队列,进入管理页面:
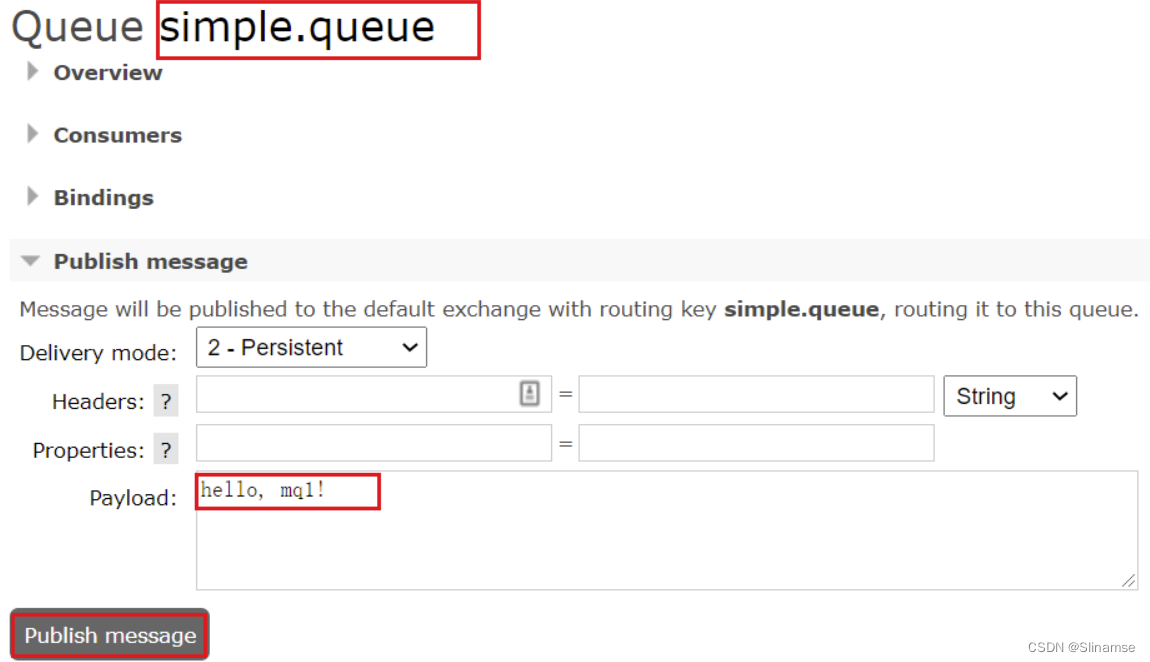
然后利用控制台发送一条消息到这个队列:
结果在mq2、mq3上都能看到这条消息:
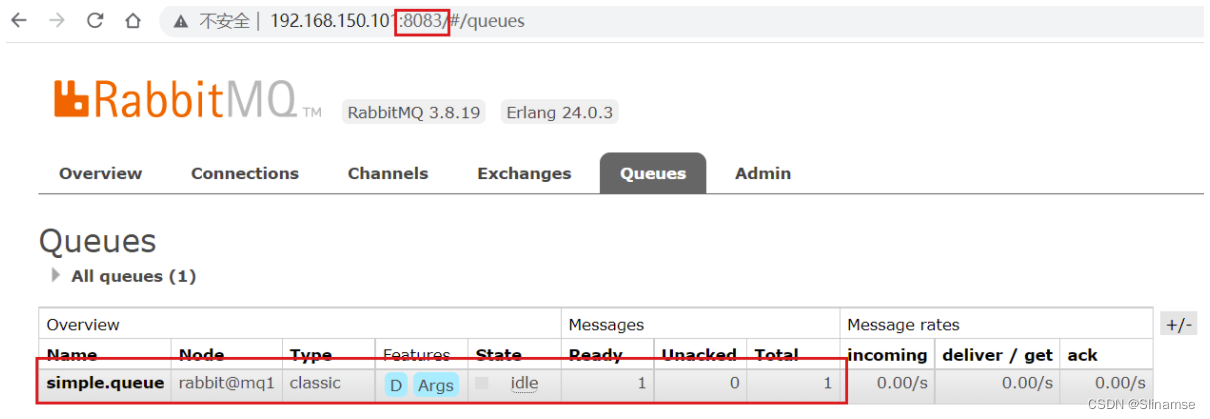
2.5.2.可用性测试
我们让其中一台节点mq1宕机:
docker stop mq1然后登录mq2或mq3的控制台,发现simple.queue也不可用了:
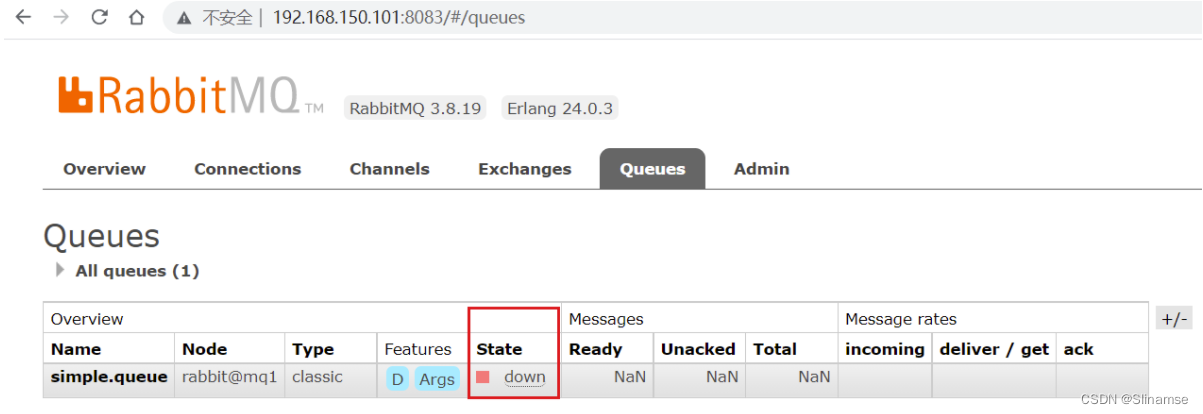
说明数据并没有拷贝到mq2和mq3。

镜像模式
在刚刚的案例中,一旦创建队列的主机宕机,队列就会不可用。不具备高可用能力。如果要解决这个问题,必须使用官方提供的镜像集群方案。
官方文档地址:Classic Queue Mirroring — RabbitMQ
4.1.镜像模式的特征
默认情况下,队列只保存在创建该队列的节点上。而镜像模式下,创建队列的节点被称为该队列的主节点,队列还会拷贝到集群中的其它节点,也叫做该队列的镜像节点。
但是,不同队列可以在集群中的任意节点上创建,因此不同队列的主节点可以不同。甚至,一个队列的主节点可能是另一个队列的镜像节点。
用户发送给队列的一切请求,例如发送消息、消息回执默认都会在主节点完成,如果是从节点接收到请求,也会路由到主节点去完成。镜像节点仅仅起到备份数据作用。
当主节点接收到消费者的ACK时,所有镜像都会删除节点中的数据。
总结如下:
-
镜像队列结构是一主多从(从就是镜像)
-
所有操作都是主节点完成,然后同步给镜像节点
-
主宕机后,镜像节点会替代成新的主(如果在主从同步完成前,主就已经宕机,可能出现数据丢失)
-
不具备负载均衡功能,因为所有操作都会有主节点完成(但是不同队列,其主节点可以不同,可以利用这个提高吞吐量)
4.2.镜像模式的配置
镜像模式的配置有3种模式:
| ha-mode | ha-params | 效果 |
|---|---|---|
| 准确模式exactly | 队列的副本量count | 集群中队列副本(主服务器和镜像服务器之和)的数量。count如果为1意味着单个副本:即队列主节点。count值为2表示2个副本:1个队列主和1个队列镜像。换句话说:count = 镜像数量 + 1。如果群集中的节点数少于count,则该队列将镜像到所有节点。如果有集群总数大于count+1,并且包含镜像的节点出现故障,则将在另一个节点上创建一个新的镜像。 |
| all | (none) | 队列在群集中的所有节点之间进行镜像。队列将镜像到任何新加入的节点。镜像到所有节点将对所有群集节点施加额外的压力,包括网络I / O,磁盘I / O和磁盘空间使用情况。推荐使用exactly,设置副本数为(N / 2 +1)。 |
| nodes | node names | 指定队列创建到哪些节点,如果指定的节点全部不存在,则会出现异常。如果指定的节点在集群中存在,但是暂时不可用,会创建节点到当前客户端连接到的节点。 |
这里我们以rabbitmqctl命令作为案例来讲解配置语法。
语法示例:
4.2.1.exactly模式
docker exec -it mq1 bash
root@mq1:/# rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
-
rabbitmqctl set_policy:固定写法 -
ha-two:策略名称,自定义 -
"^two\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以two.开头的队列名称 -
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}': 策略内容-
"ha-mode":"exactly":策略模式,此处是exactly模式,指定副本数量 -
"ha-params":2:策略参数,这里是2,就是副本数量为2,1主1镜像 -
"ha-sync-mode":"automatic":同步策略,默认是manual,即新加入的镜像节点不会同步旧的消息。如果设置为automatic,则新加入的镜像节点会把主节点中所有消息都同步,会带来额外的网络开销
-
4.2.2.all模式
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'-
ha-all:策略名称,自定义 -
"^all\.":匹配所有以all.开头的队列名 -
'{"ha-mode":"all"}':策略内容-
"ha-mode":"all":策略模式,此处是all模式,即所有节点都会称为镜像节点
-
4.2.3.nodes模式
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'-
rabbitmqctl set_policy:固定写法 -
ha-nodes:策略名称,自定义 -
"^nodes\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以nodes.开头的队列名称 -
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}': 策略内容-
"ha-mode":"nodes":策略模式,此处是nodes模式 -
"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略参数,这里指定副本所在节点名称
-
4.3.测试
我们使用exactly模式的镜像,因为集群节点数量为3,因此镜像数量就设置为2.
运行下面的命令:
docker exec -it mq1 rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'下面,我们创建一个新的队列:
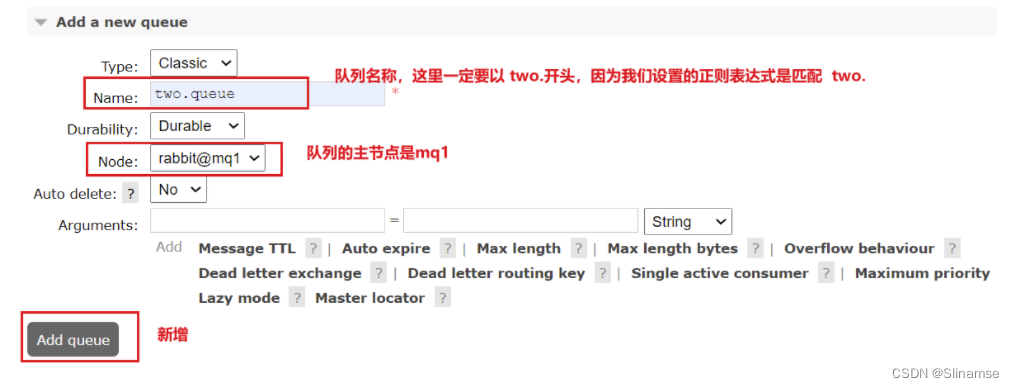
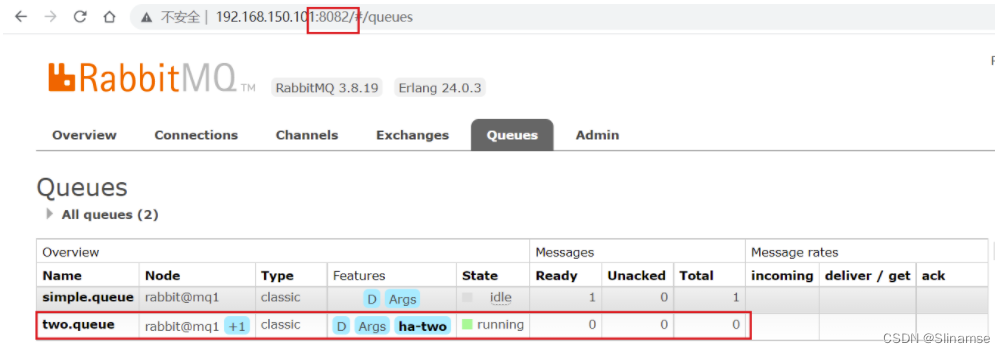
在任意一个mq控制台查看队列:
4.3.1.测试数据共享
给two.queue发送一条消息:
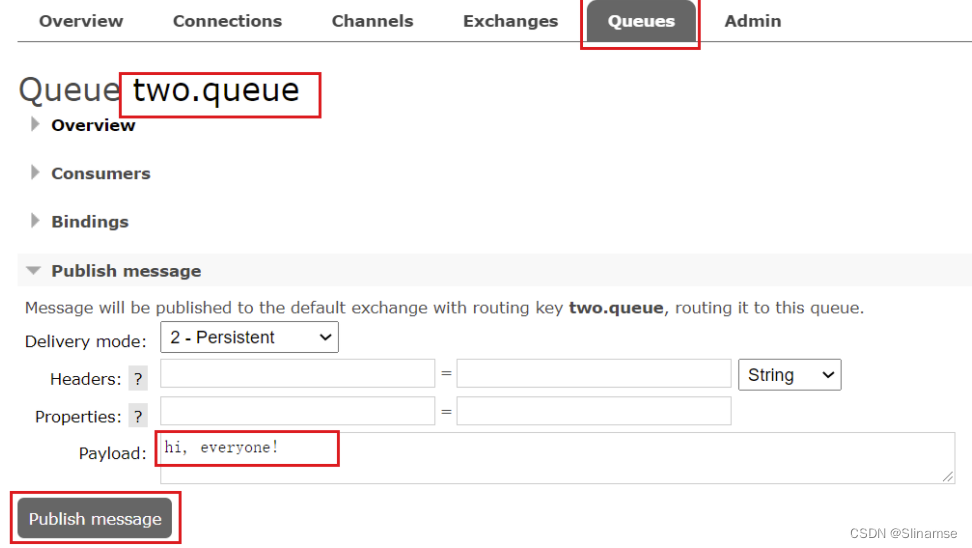
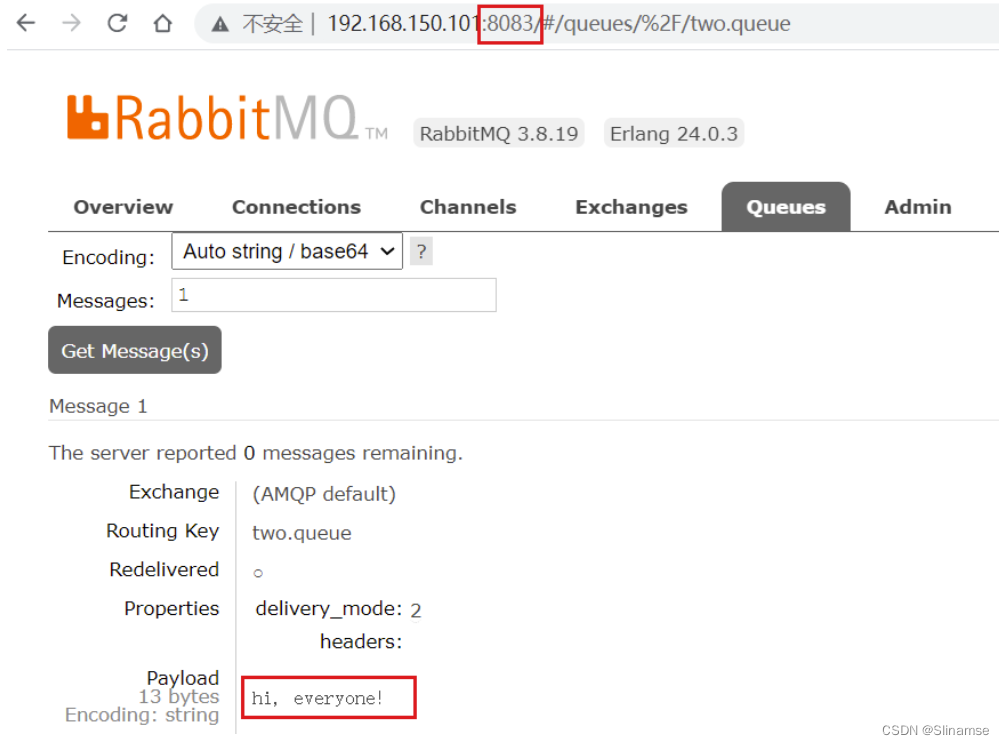
然后在mq1、mq2、mq3的任意控制台查看消息:
4.3.2.测试高可用
现在,我们让two.queue的主节点mq1宕机:
docker stop mq1查看集群状态:

查看队列状态:
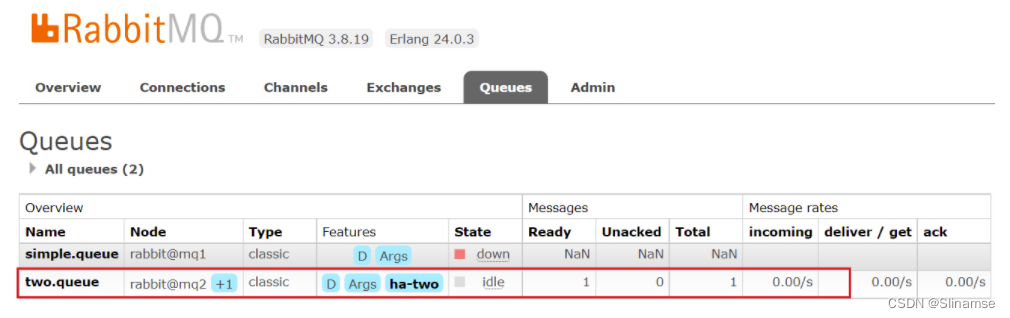
发现依然是健康的!并且其主节点切换到了rabbit@mq2上
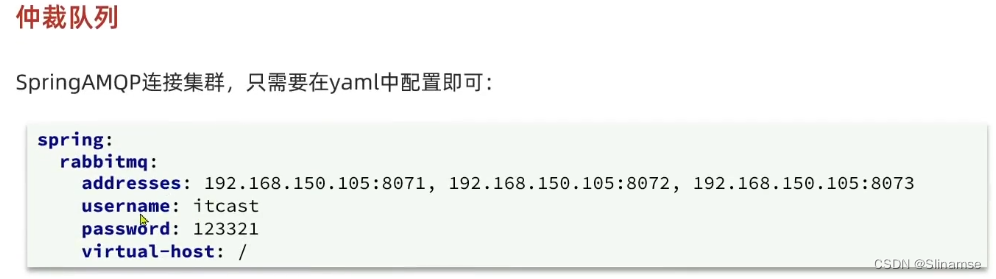
仲裁队列
从RabbitMQ 3.8版本开始,引入了新的仲裁队列,他具备与镜像队里类似的功能,但使用更加方便。
5.1.添加仲裁队列
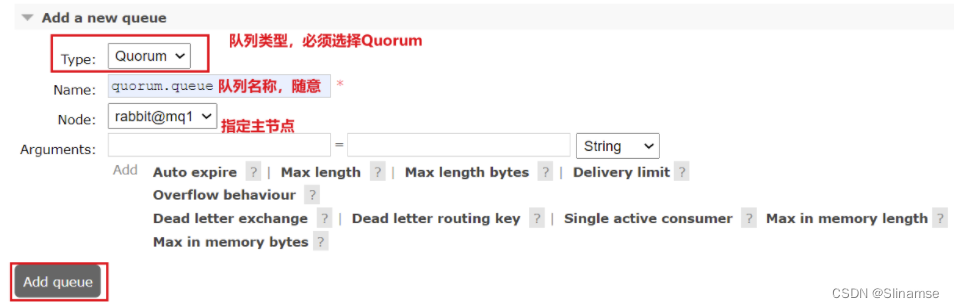
在任意控制台添加一个队列,一定要选择队列类型为Quorum类型。
在任意控制台查看队列:
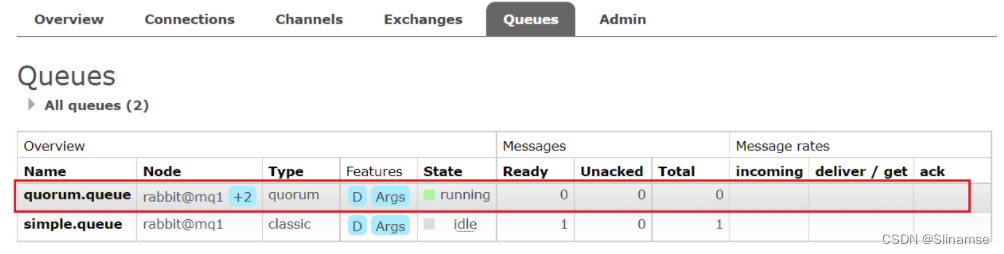
可以看到,仲裁队列的 + 2字样。代表这个队列有2个镜像节点。
因为仲裁队列默认的镜像数为5。如果你的集群有7个节点,那么镜像数肯定是5;而我们集群只有3个节点,因此镜像数量就是3.
5.2.测试
可以参考对镜像集群的测试,效果是一样的。