cs224w课程学习笔记-第10课 异构图
- 前言
- 一、异构图
- 1、异构图定义
- 2、异构图与同构图
- 二、异构图下的GNN
- 1、GCN扩展至RGCN
- 1.1 RGCN原理
- 1.2 异构图的任务预测特点
- 1.3 异构图任务预测基础案例
- 2、完整的异构图GCN
- 三、异构图下的Transformer
前言
异构图的定义是节点内部存在类型不同,边的内部存在类型不同信息,那么类型不同的信息是否可以做特征引入图学习中,由此异构图可做同构图对待?若必须视为异构图,其图学习又如何进行?本节课将介绍异构图的基本定义,以及其与同构图的关系,如何使用GCN实现对异构图的嵌入学习,如何使用Transform实现对异构图的嵌入学习.
一、异构图
1、异构图定义
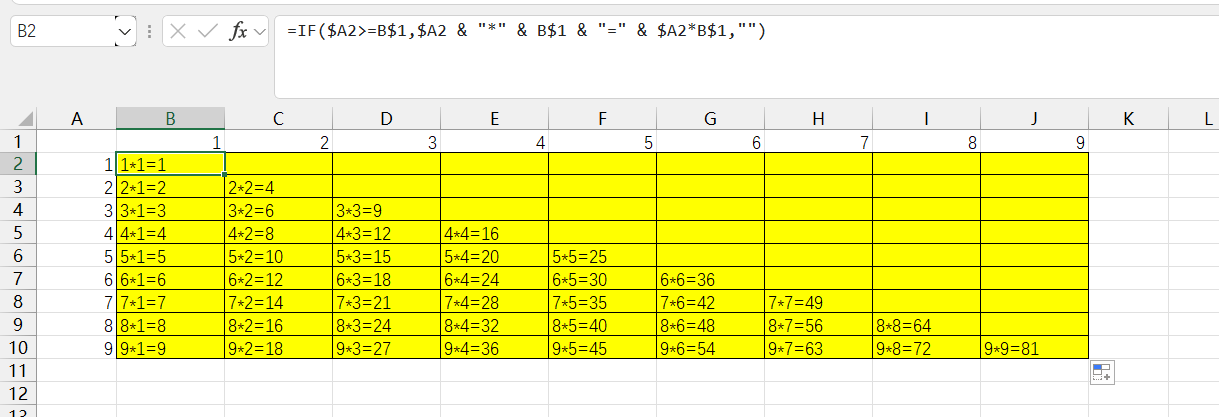
当图中的节点,边有不同类型存在时,可视为异构图,如下图所示,其节点有两种类型,边也有两种类型,若考虑其连接类型则(开始节点类型,边类型,结束节点类型)一共8种.因此从连接类型上看,节点类型数为n,边类型数为m,其连接类型数为(n^2 *m).
因为异构图多了类型,由此其图定义G(V,E),将增加节点类型
τ
\tau
τ 与边类型
ϕ
\phi
ϕ,其具体定义如图所示

常见异构图场景有:医药知识图谱,事件图,电商图,学术图等
2、异构图与同构图
实际上我们将类型信息转为onehot,作为特征引入到同构图中即可,那什么时候我们需要将其作为异构图对待呢?
- 不同类型节点/边有不同维度的特征:比如作者节点5维特征,文章节点4维特征
- 先验知识表明不同关系类型其交互模式存在差异:比如英语翻译法语,英语翻译中文
总体来说异构图所表达的信息更多,相应的计算量也更大.
二、异构图下的GNN
1、GCN扩展至RGCN
1.1 RGCN原理
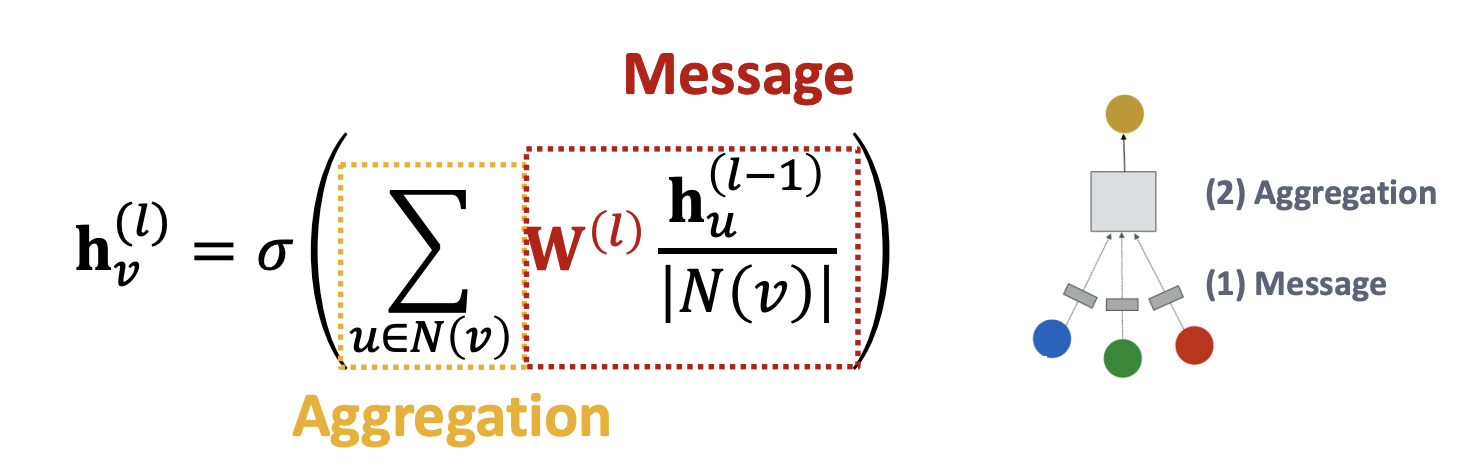
首先回顾一下GCN的计算核心原理,消息传递,然后聚合,其中传递的参数是共享的.
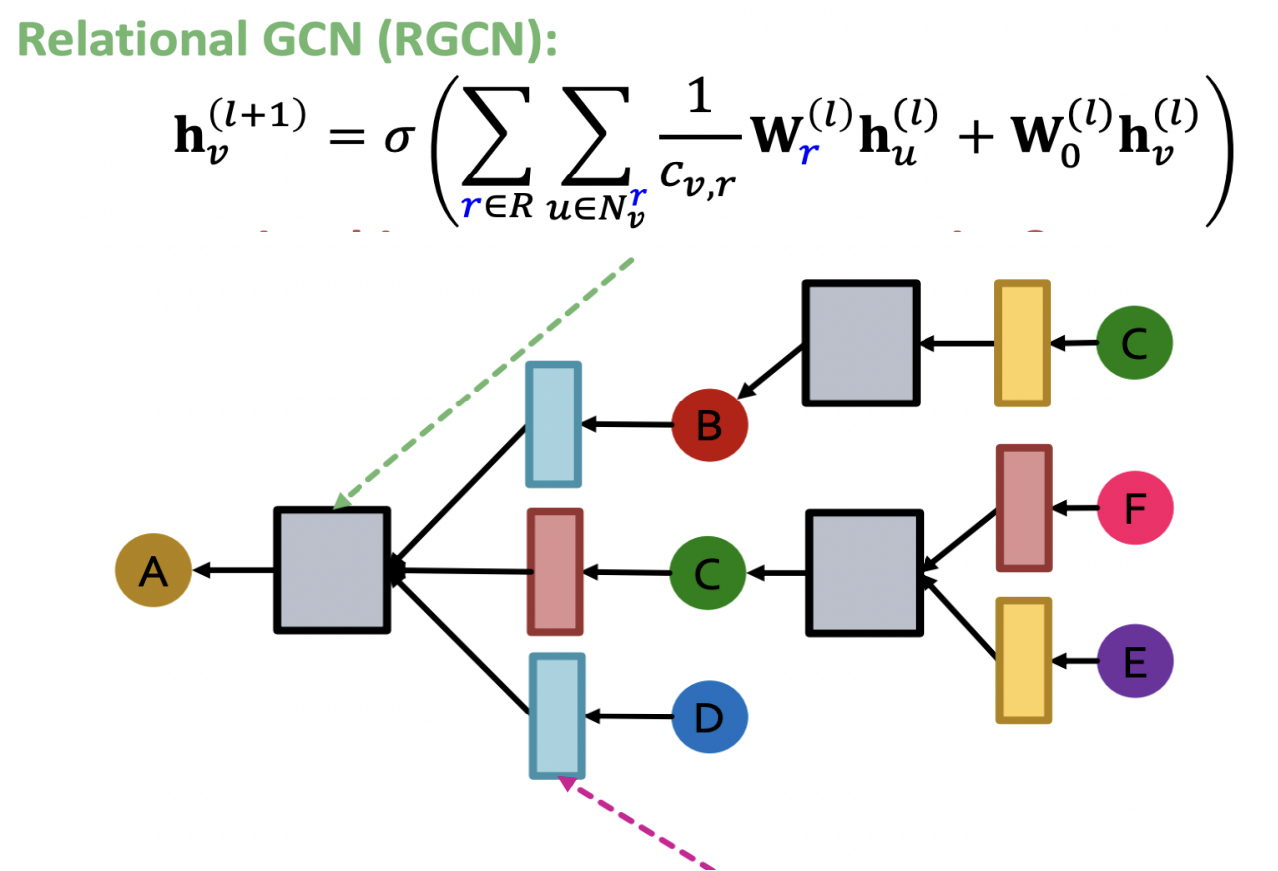
现在**同构图有不同关系类型,其消息传递过程是不是也应该按照关系类型进行区分呢?**自然而然想到一个关系类型给一组参数,这样消息传递过程变为如下形势.
但是每一个关系类型就引入一组参数的方式可能会造成过拟合,因为前面说过关系类型随着节点类型的增长而指数增加.因此可以通过下面两种方法对参数进行正则化:
- Use Block Diagonal Matrices (使用块对角矩阵):如下图所示,除对角的小块外的参数均0,这减少了模型训练时的参数量,同时在结构上仅对相关子类型的信息进行聚合;这防止了模型对多个无关或噪声信息的过拟合.
- Basis/Dictionary Learning (基/字典学习):将 W r W_r Wr表示为某些共享的"基"或"字典"的线性组合, W r = ∑ b = 1 B a r b V b W_r= \sum_{b=1} ^ {B}a_{rb}V_b Wr=∑b=1BarbVb,其中V是基矩阵,一共B个,a是每个基矩阵在r关系类型上的权重.通过该种方式也可以实现参数共享与压缩,有效地降低整体模型的复杂性。
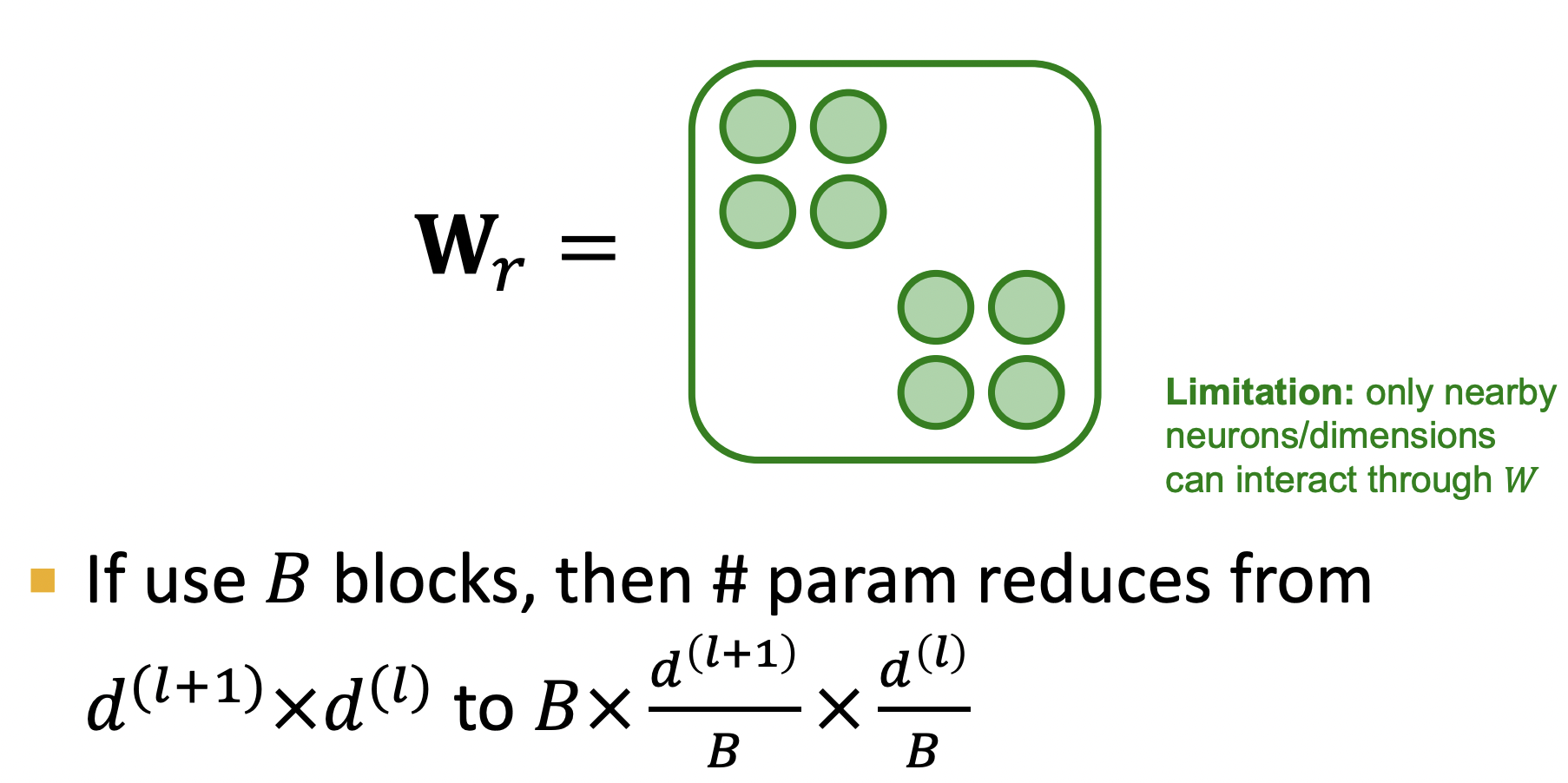
1.2 异构图的任务预测特点
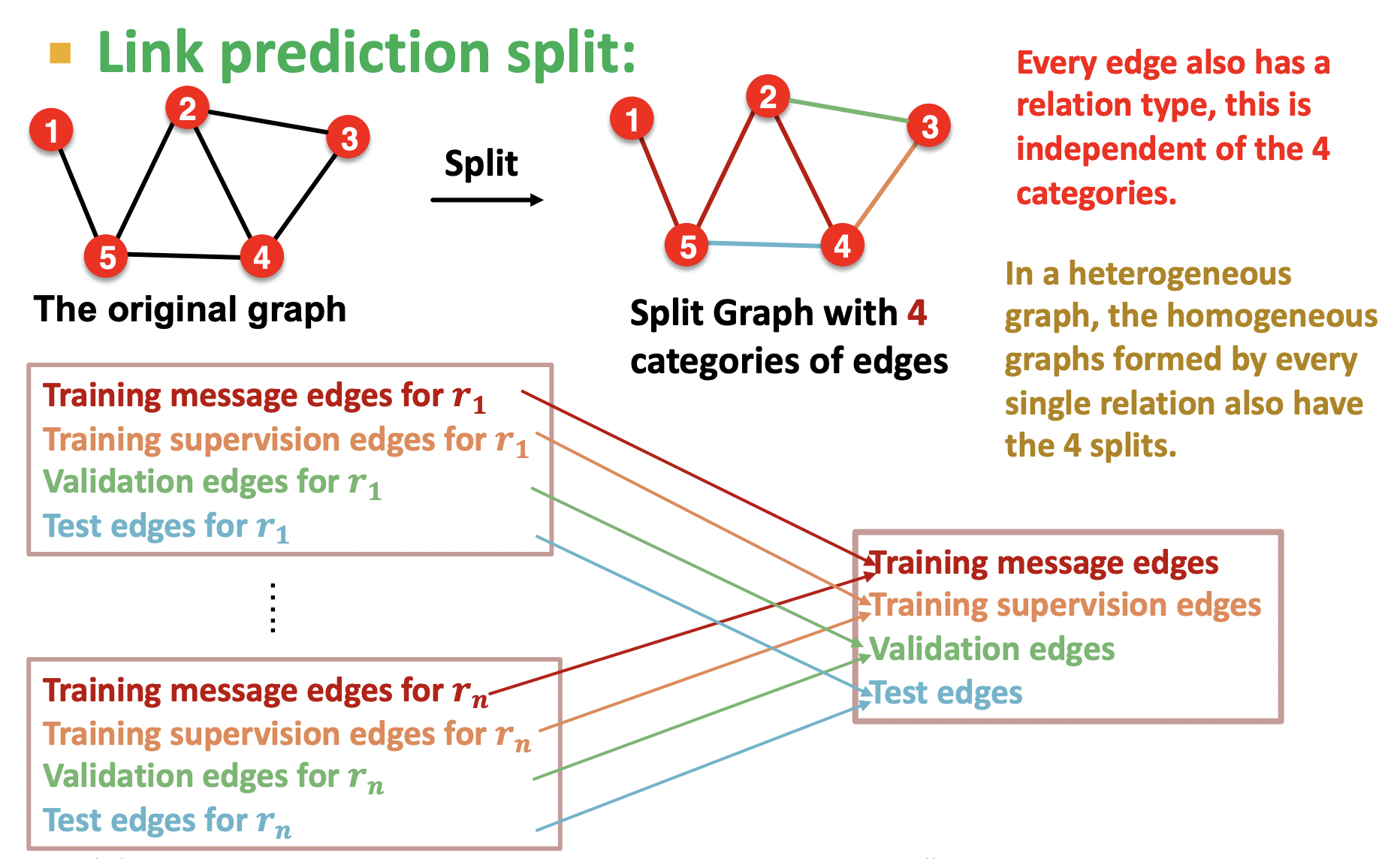
节点任务没有什么特别的,仍然是获得嵌入后进行预测;边任务在训练流程上有些差异,流程回顾见cs224w课程学习笔记-第6课下的数据集划分里有,其差别在训练集,验证集,测试集划分时需要按关系类型配置多套,如下图所示
同时在做负样本生成时,也需要区分关系类型,其具体方法如下所示,目标是(E,r3,A),则负样本可以通过改变尾部节点得到,添加负样本的目的是为了让模型的鲁棒性更强.

在评估时,有了负样本,因此目标是要负样本评分低,正样本评分高 ,由此loss表示为如下形式
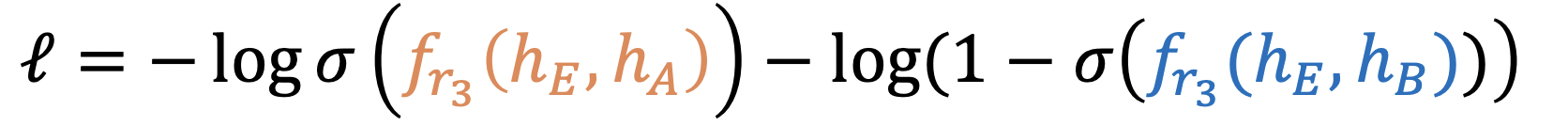
在验证模型性能时,因为都是打分因此需要使用相应的评价指标,如Hits@k方法.MRR方法.

以Hit@k为例,k表示排前K名,如下图所示,正边为(E,r3,D),在评分排名中排在第2名,使用Hit@2指标,则正边排名小于等于2,为1,其排名倒数为1/2.通过对所有正边的指标计算,可知其排名倒数和越大越好,Hit@2指标和越大越好.
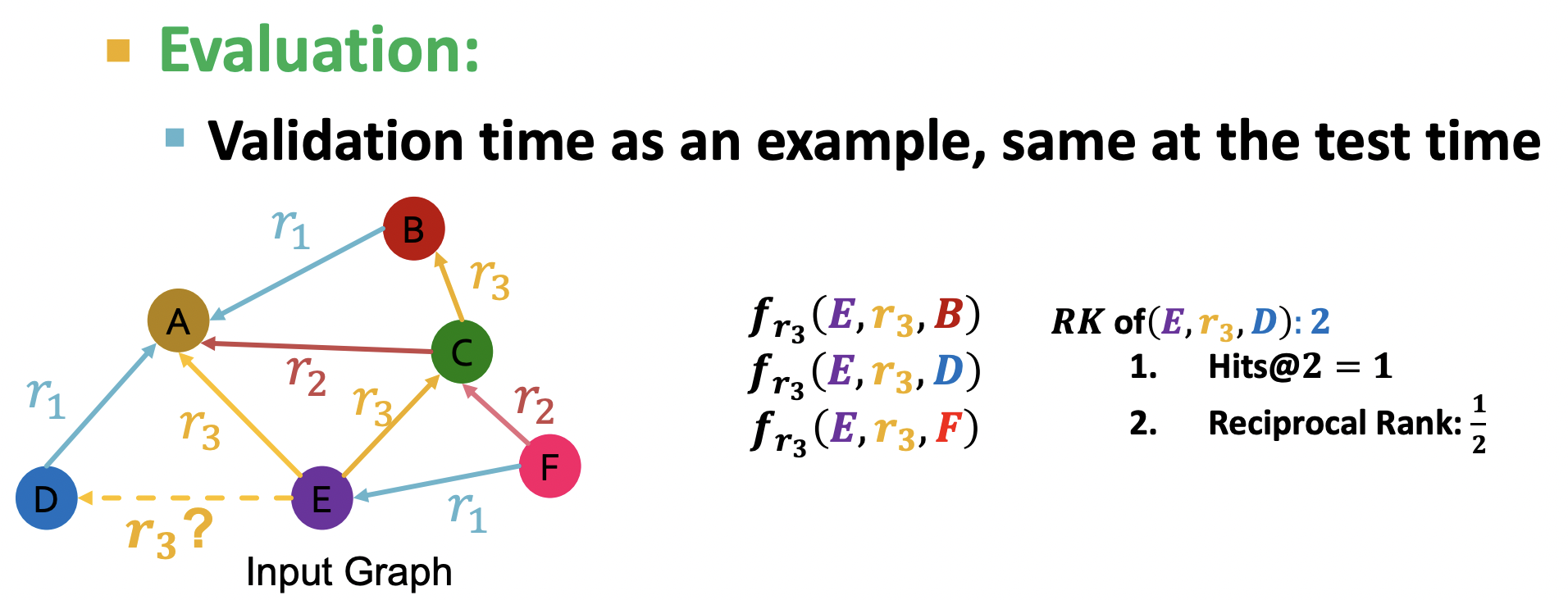
边任务差异性内容就到此结束啦,接下来看一个具体的异构图应用案例
1.3 异构图任务预测基础案例
任务背景说明:
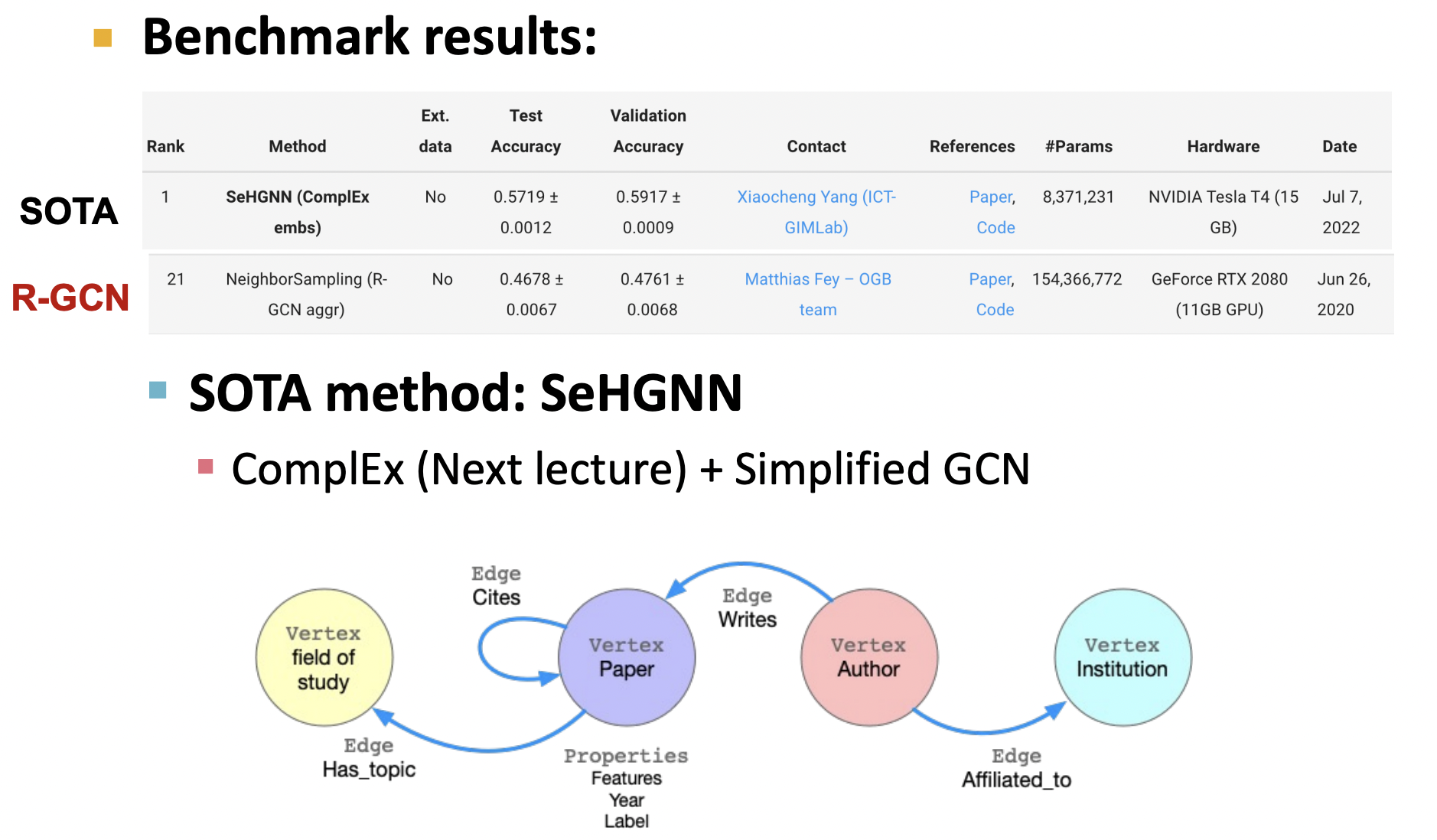
使用微软学术图的ogbn_mag数据集,预测每篇论文的所属会议
这是一个节点分类任务,考虑349个会议,即为349类,通过消息传递,论文节点的信息得到综合表达的嵌入,对嵌入进行分类预测得到该应用输出.其下图展示了该案例的图数据构成(节点类型,边类型)与应用不同算法的表现,可以看到sota算法是一个联合算法,不止是简单的GCN,前面还有一步嵌入算法,这个方法在下一节课中进行阐述.
2、完整的异构图GCN
由前面的内容可以得到GCN如何扩展为RGCN,接下来看实践中两者的不同
首先是消息传递原理的变化,前面介绍RGCN的原理里已说明;
然后是层级间的连接,其前后处理mlp处理的差异是根据节点类型数,边类型数匹配多个mlp进行并行处理(类似moe结构);
其次是图数据处理,特征上统计类特征区分类型进行计算,子图采样上根据每个类型进行近邻采样或者全图随机采样;
最后是任务预测上,嵌入结果在预测应用时考虑不同类型对应不同参数进行预测.

三、异构图下的Transformer
回忆一下其原理是注意力机制Q,K,V,同构图对不同边使用的是同一套QKV,对标GCN变RGCN的思想,直接扩为关系类型数的QKV套数(类比多条注意力),但是直接增加注意力头数,会让计算量激增,因此考滤将该方式分解为节点类型数与边类型数的注意力机制,这样的话若节点类型数为3,边类型数为2,则其关系类型数为332=18,而分解后的注意力集为3+3+2=8.
其具体分解原理如下图所示,
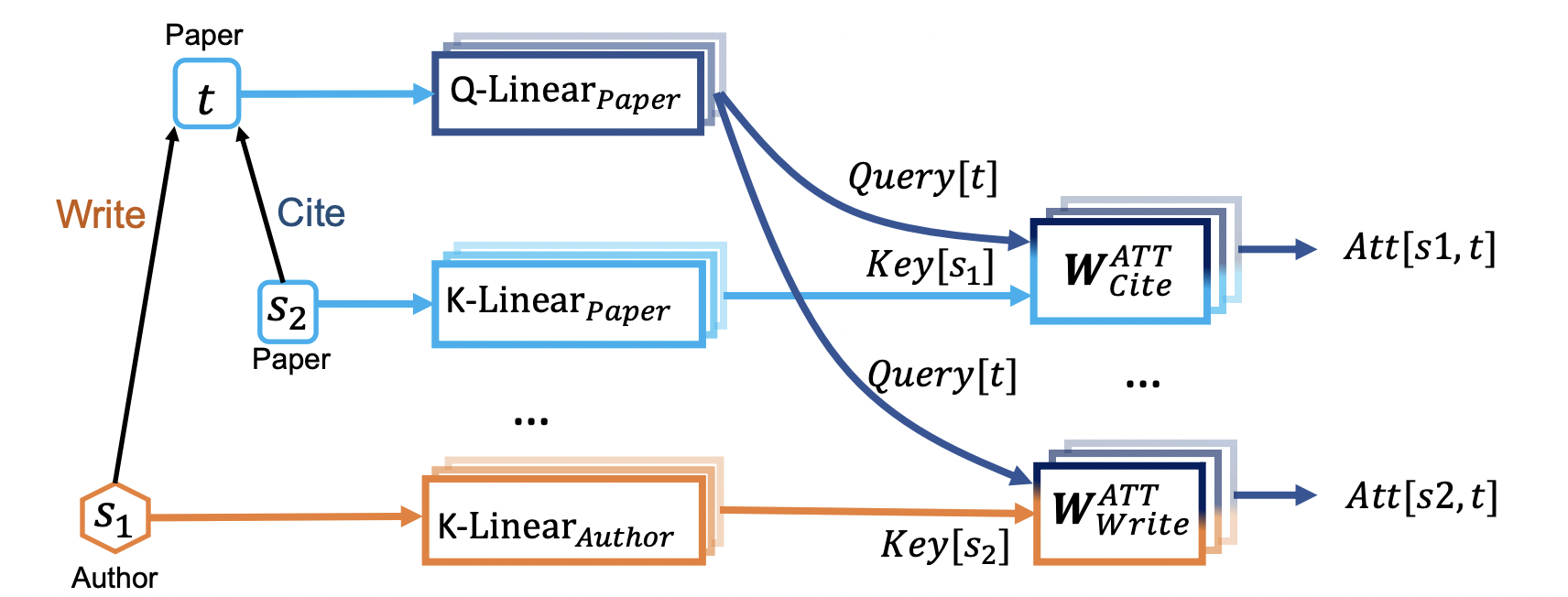
其公式如下所示,我们知道GAT与GCN的差异就在权重上,因此扩展到异构图上,RGAT与RGCN的差异也是在权重上.至此异构图的Transformer便扩展完成啦.

应用于基线数据可以看到在参数量更少的情况下,异构图的GAT(HGT)表现效果更好.









![大模型本地部署系列(3) Ollama部署QwQ[阿里云通义千问]](https://i-blog.csdnimg.cn/img_convert/79e9a055724e4064361ae20da1f5fda3.webp?x-oss-process=image/format,png)