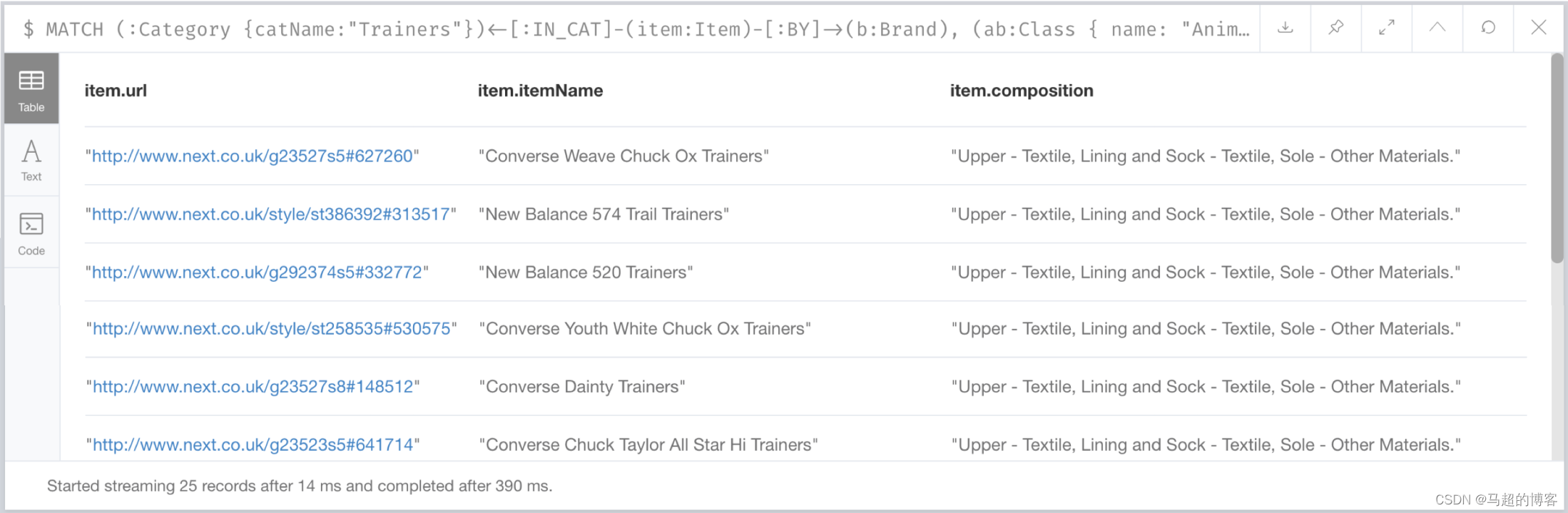
Failover
当设置failover为true时候,elasticjob 集群通过zookeeper 的event watcher 监听是否有instance 丢失,然后对丢失instance 对应的分片进行立即执行。
重复一下,failover是立即执行,不是按crontab时间来触发,这个触发是不管丢失的分片是否处于运行状态。
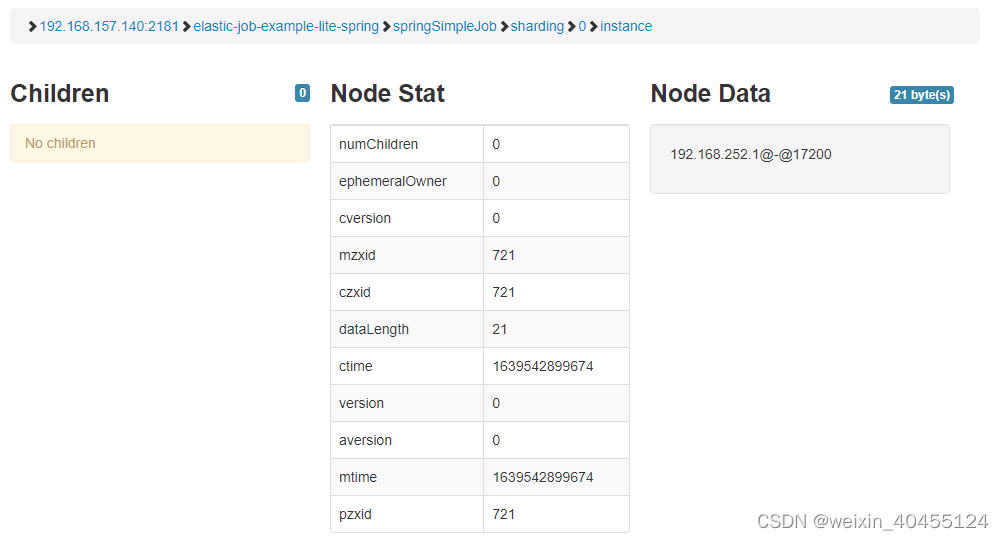
Elasticjob 执行和分配是分离的,上图的node data 是instance 的IP+通信端口(instance client port)决定哪个instance 负责执行,但failover执行除外。
以同一 job 有A,B两个instance ,两个instance 各负责1个分片为例:
1、 instance A 异常退出,instance B在秒级收到zookeeper node remove 事件后 重新设置shard 对应 node data 为自己并设置failover 信息
2、 instance B设置failover后立即触发新分片的执行
核心函数如下:
class JobCrashedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (isFailoverEnabled() && Type.NODE_REMOVED == eventType && instanceNode.isInstancePath(path)) {
String jobInstanceId = path.substring(instanceNode.getInstanceFullPath().length() + 1);
if (jobInstanceId.equals(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId())) {
return;
}
//注意只检查对应instanceid,如果remove的instance 与sharding 的node data不一致,不会触发
List<Integer> failoverItems = failoverService.getFailoverItems(jobInstanceId);
if (!failoverItems.isEmpty()) {
for (int each : failoverItems) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
} else {
// 只要分片是对应被remove的instance 就立即触发
for (int each : shardingService.getShardingItems(jobInstanceId)) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
}
}
}
}
以上代码要注意只检查对应instanceid,如果remove的instance 与sharding 的node data不一致,不会触发failover。
而根据以下代码
/**
* 如果需要失效转移, 则执行作业失效转移.
*/
public void failoverIfNecessary() {
if (needFailover()) {
jobNodeStorage.executeInLeader(FailoverNode.LATCH, new FailoverLeaderExecutionCallback());
}
}
class FailoverLeaderExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
if (JobRegistry.getInstance().isShutdown(jobName) || !needFailover()) {
return;
}
int crashedItem = Integer.parseInt(jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).get(0));
log.info("Failover job '{}' begin, crashed item '{}'.................", jobName, crashedItem);
jobNodeStorage.fillEphemeralJobNode(FailoverNode.getExecutionFailoverNode(crashedItem), JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
jobNodeStorage.removeJobNodeIfExisted(FailoverNode.getItemsNode(crashedItem));
// TODO 不应使用triggerJob, 而是使用executor统一调度
JobScheduleController jobScheduleController = JobRegistry.getInstance().getJobScheduleController(jobName);
if (null != jobScheduleController) {
jobScheduleController.triggerJob();
}
}
在failover 执行完毕才会去修改sharding 的node data,因此当接管failover的instance 没有执行完failover就shutdown 的话,此时由于node data 与新shutdown instance id不一致 、failover是不会被再次触发的。
因此继续分析以上案例, 以同一 job 有A,B两个instance ,两个instance 各负责1个分片为例:
1、 instance A 异常退出,instance B在秒级收到zookeeper node remove 事件后 重新设置shard 对应 node data 为自己并设置failover 信息
2、 instance B设置failover后立即触发新分片的执行
3、 重新启动一个instance C(PS:进程重新启动由于端口不一样,会认为是新instance)并立即shutdown instance B
4、 如果第1-3步间隔时间短,instance B 还收到zookeeper event,只有1个sharding 在instance C被立即触发
5、 如果1-3 间隔时间长,instance B已经完成instance A 分表执行,instance C会触发instance B 负责2个分片并在执行完毕后接管2个分片直到新instance 加入并重新分片。
Misfire
从代码看在2次正常触发过程中,配置misfire最多执行一次。
Quartz只在执行完毕后执行一次next fire的计算,在计算过程发现misfire 会去调用misfire listener。
调用的stack 信息如下:
Thread [springSimpleJob_QuartzSchedulerThread] (Suspended (breakpoint at line 46 in JobTriggerListener))
owns: Object (id=3883)
JobTriggerListener.triggerMisfired(Trigger) line: 46
QuartzScheduler.notifyTriggerListenersMisfired(Trigger) line: 1905
SchedulerSignalerImpl.notifyTriggerListenersMisfired(Trigger) line: 74
RAMJobStore.applyMisfire(TriggerWrapper) line: 1354
RAMJobStore.acquireNextTriggers(long, int, long) line: 1412
QuartzSchedulerThread.run() line: 272
triggerMisfired 负责设置misfire 标志外,以上堆栈的类都是quartz的类。
Elasticjob triggerMisfired相关代码如下:
@Override
public void triggerMisfired(final Trigger trigger) {
if (null != trigger.getPreviousFireTime()) {
executionService.setMisfire(shardingService.getLocalShardingItems());
}
}
而实际执行代码如下:
if (jobFacade.misfireIfRunning(shardingContexts.getShardingItemParameters().keySet())) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format(
"Previous job '%s' - shardingItems '%s' is still running, misfired job will start after previous job completed.", jobName,
shardingContexts.getShardingItemParameters().keySet()));
}
return;
}
try {
jobFacade.beforeJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
可以看出在正常执行完毕后再去触发misfire一次,而且是顺序执行。
执行线程池管理
Elasticjob 默认为每个job 创建CORE*2的线程池队列,核心代码如下
public final class DefaultExecutorServiceHandler implements ExecutorServiceHandler {
@Override
public ExecutorService createExecutorService(final String jobName) {
return new ExecutorServiceObject("inner-job-" + jobName, Runtime.getRuntime().availableProcessors() * 2).createExecutorService();
}
}
public ExecutorServiceObject(final String namingPattern, final int threadSize) {
workQueue = new LinkedBlockingQueue<>();
threadPoolExecutor = new ThreadPoolExecutor(threadSize, threadSize, 5L, TimeUnit.MINUTES, workQueue,
new BasicThreadFactory.Builder().namingPattern(Joiner.on("-").join(namingPattern, "%s")).build());
threadPoolExecutor.allowCoreThreadTimeOut(true);
}
每次执行通过以下代码获取对应的执行线程池,没有就去新建:
/**
* 获取线程池服务.
*
* @param jobName 作业名称
* @param executorServiceHandler 线程池服务处理器
* @return 线程池服务
*/
public static synchronized ExecutorService getExecutorServiceHandler(final String jobName, final ExecutorServiceHandler executorServiceHandler) {
if (!REGISTRY.containsKey(jobName)) {
REGISTRY.put(jobName, executorServiceHandler.createExecutorService(jobName));
}
return REGISTRY.get(jobName);
}
因此如果job很多,会创建大量的线程,如果同时运行的job多就会带来频繁的Thread Context 切换。
如果都是短时间可以执行job,可以配置job的
executor-service-handler=“com.dangdang.ddframe.job.custom. DefaultExecutorServiceHandler”
并使用以下代码替换默认线程池
public final class DefaultExecutorServiceHandler implements ExecutorServiceHandler {
final ExecutorService executorService= new ExecutorServiceObject("innerjob-executepool", Runtime.getRuntime().availableProcessors() * N).createExecutorService();
@Override
public ExecutorService createExecutorService(final String jobName) {
return executorService;
}
}
即共用一个线程池,执行效率可能更高。