Lucene简介:
Lucene主要用于构建文本搜索应用程序,包括Web搜索引擎、桌面搜索工具和商业应用程序。它提供了诸如单词分析、查询解析、搜索结果排序等功能,可以轻松地在大量文档中快速搜索和查找相关信息。
Lucene具有以下特点:
可扩展性:Lucene可以轻松处理大规模的数据集,支持分布式搜索,可轻松扩展以处理更多数据。
高性能:Lucene使用了许多高效的算法和数据结构,可以在大型文档集合中快速进行搜索。
全文搜索:Lucene支持全文搜索,可以搜索文档中的所有内容,包括文本、数字、日期等。
多语言支持:Lucene支持多种语言,可以轻松处理不同语言的文本。
易于使用:Lucene提供了简单易用的API,使开发人员可以轻松地构建搜索应用程序。
Lucene是一个强大的文本搜索引擎库,具有高性能、可扩展性和易用性,可以用于构建各种文本搜索应用程序。
Solr简介:
Solr是基于Apache Lucene搜索引擎库构建,提供了强大的全文检索和高级搜索功能,支持多种数据格式和多种查询方式。Solr使用Java语言编写,可以运行在任何支持Java虚拟机的操作系统上。
Solr主要用于构建大规模的搜索应用程序,如电子商务网站、新闻门户网站、社交媒体应用程序等。Solr具有高度可扩展性、高性能、高可用性和易于集成的特点,支持多种部署模式,如独立模式、云模式、集群模式等。
Solr提供了丰富的API和插件,可以轻松地集成到现有的应用程序中,还提供了强大的管理和监控工具,可用于管理索引、监控性能和进行故障排除。此外,Solr还支持多种数据格式和多种查询方式,包括基于文本、XML、JSON等格式的查询,以及支持复杂查询逻辑的查询方式。
Solr是一种强大的搜索平台,它提供了全面的搜索功能和易于集成的特点,适用于各种类型的应用程序。
Elasticsearch简介:
Elasticsearch是基于Lucene搜索引擎的分布式、开源的搜索和分析引擎。它能够快速地搜索、分析和存储大量的数据,并且可以轻松地水平扩展,以处理任何规模的数据。
Elasticsearch主要用于大规模应用程序的搜索、数据分析和数据可视化。它能够快速地搜索和分析大规模数据集,并提供实时的数据可视化。它也可以用于日志分析、安全分析、企业搜索等应用程序中。
Elasticsearch支持以下数据类型:
文本类型(Text):用于全文搜索的长文本,支持分析和索引。
关键字类型(Keyword):用于精确匹配的短文本,不支持分析和索引。
数值类型(Numeric):用于数值的存储和范围查询,支持整数、浮点数和双精度浮点数。
日期类型(Date):用于日期和时间的存储和范围查询。
布尔类型(Boolean):用于布尔值的存储和查询。
二进制类型(Binary):用于二进制数据的存储和查询。
地理位置类型(Geo):用于地理位置的存储和查询,支持点、线、多边形等多种类型的位置。
IP地址类型(IP):用于IP地址的存储和查询。
嵌套类型(Nested):用于嵌套的文档结构的存储和查询。
此外,Elasticsearch还支持自定义数据类型,可以通过插件或自定义分析器等方式进行扩展。
Elasticsearch的优点包括:
分布式架构:可以水平扩展,处理大量数据;
实时搜索和分析:能够快速地搜索和分析大规模数据集;
多种查询方式:支持全文搜索、短语搜索、模糊搜索、正则表达式搜索等;
多种数据类型支持:支持文本、数字、日期、地理位置等多种数据类型;
易于使用:提供简单的RESTful API和丰富的客户端库;
开源:遵循Apache 2.0许可证。
Elasticsearch是一个功能强大的搜索和分析引擎,具有广泛的应用领域,适用于各种规模和类型的应用程序。
Solr 和Elasticsearch怎么选
Solr和Elasticsearch都是流行的开源搜索引擎,具有许多相似之处,但也有一些不同之处。选择哪个搜索引擎取决于您的需求、技术能力和预算。
以下是一些可能帮助您选择的因素:
数据存储:Elasticsearch具有分布式数据存储的能力,可以处理大规模数据集。Solr则更适合小型或中型数据集,因为它使用单个节点存储数据。
查询功能:Elasticsearch在复杂查询方面表现更好。它使用lucene引擎,支持更多的查询类型,如嵌套查询、聚合查询等。Solr也具有强大的查询功能,但它没有像Elasticsearch那样的内置聚合。
可扩展性:Elasticsearch天生就具有水平扩展性,可以很容易地添加或删除节点。Solr也可以扩展,但需要手动配置和管理。
实时搜索:Elasticsearch是一个实时搜索引擎,能够在毫秒级别内返回查询结果。Solr也具有实时搜索功能,但查询速度可能较慢。
社区支持和文档:Elasticsearch在这方面的表现更好,拥有更广泛的社区和更完整的文档。Solr也有一个庞大的社区,但Elasticsearch的社区更加活跃。
如果您处理大型数据集,需要高级查询和实时搜索功能,并且具有足够的技术能力和预算,Elasticsearch可能是更好的选择。如果您处理的是小型或中型数据集,需要更简单的查询,并且预算较低,Solr可能更适合。
倒排索引和正排索引
倒排索引:
倒排索引(Inverted Index)是一种常见的文本索引技术,用于加快文本搜索的速度和效率。在倒排索引中,对于每个单词,记录它出现在哪些文档中以及出现的位置信息。
举个例子,假设有3个文档:
文档1:the quick brown fox jumps over the lazy dog
文档2:the quick brown fox jumps over the brown dog
文档3:the quick brown fox jumps over the brown dog again
对于每个单词,我们可以记录它出现在哪些文档中,以及在文档中出现的位置。例如,单词“quick”出现在文档1、文档2和文档3中,分别在第1个、第1个和第1个位置。因此,我们可以将它们记录在一个倒排索引表中:
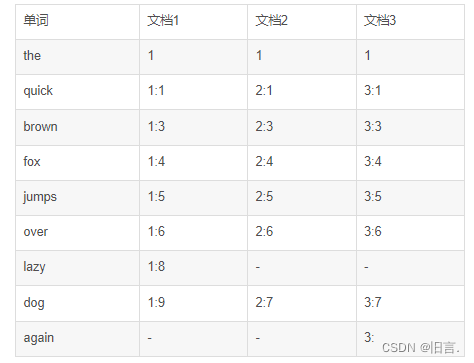
在这个倒排索引表中,每一行代表一个单词,每个单词出现在哪些文档中以及在文档中的位置都被记录下来。例如,“quick”的记录“1:1”表示它出现在文档1中,出现在文档1的第1个位置。通过这种方式,当我们需要搜索某个单词时,我们可以很快地找到包含该单词的所有文档和它们在文档中的位置,从而实现高效的文本搜索
正排索引:
正排索引(Forward Index)是指根据文本内容建立的索引,通常用于实现全文检索。正排索引将文本按照一定的格式(如文档、段落或句子等)分块存储,并为每个块分配一个唯一的标识符,以便后续检索和显示。在正排索引中,每个文本块还包含了该块的一些元信息,如文本的标题、作者、时间戳等等。
正排索引通常是由搜索引擎等系统在建立文本索引时所使用的一种索引结构,它将文本中的每个块(如单词、短语、句子等)都存储在索引结构中,并对每个块建立倒排索引,以支持快速的检索和排序。正排索引在搜索引擎等系统中扮演着非常重要的角色,它可以提高搜索的效率、准确性和可靠性,从而提高用户的搜索体验。