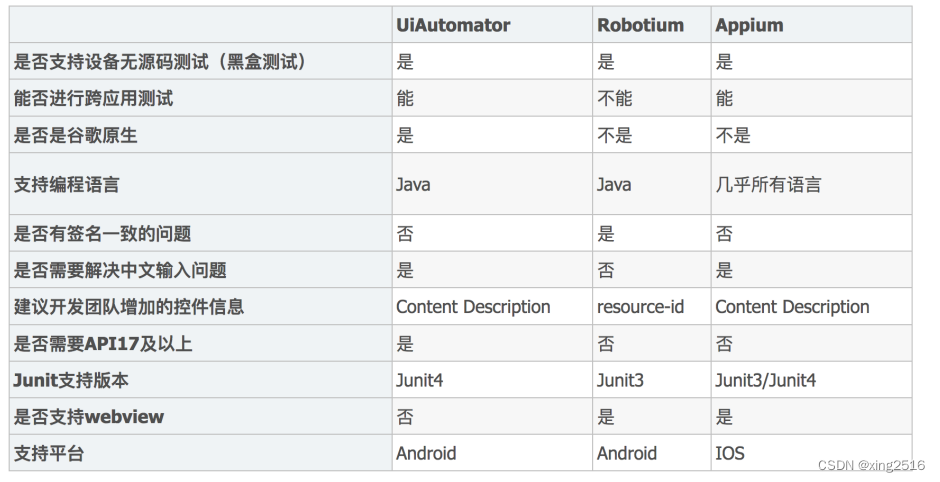
目录
建表 & 添加数据
表结构分析图
连接数据库
题目
1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数
3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩的
5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
6、查询"李"姓老师的数量
7、查询学过"张三"老师授课的同学的信息
8、查询没学过"张三"老师授课的同学的信息
9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
10、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
11、查询没有学全所有课程的同学的信息
12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
16、检索"01"课程分数小于60,按分数降序排列的学生信息
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
18、查询各科成绩最高分、最低分和平均分
19、按各科成绩进行排序,并显示排名
20、查询学生的总成绩并进行排名
21、查询不同老师所教不同课程平均分从高到低显示
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
23、统计各科成绩各分数段人数:课程编号,课程名称, 100-85 , 85-70 , 70-60 , 0-60 及所占百分比
24、查询学生平均成绩及其名次
25、查询各科成绩前三名的记录
26、查询每门课程被选修的学生数
27、查询出只有两门课程的全部学生的学号和姓名
28、查询男生、女生人数
29、查询名字中含有"风"字的学生信息
30、查询同名同性学生名单,并统计同名人数
31、查询1990年出生的学生名单(注:Student表中Sage列的类型是datetime)
32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
35、查询所有学生的课程及分数情况
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
37、查询不及格的课程
38、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名
39、求每门课程的学生人数
40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
42、查询每门功课成绩最好的前两名
43、统计每门课程的学生选修人数(超过5人的课程才统计)
44、检索至少选修两门课程的学生学号
45、查询选修了全部课程的学生信息
46、查询各学生的年龄
47、查询本周过生日的学生
48、查询下周过生日的学生
49、查询本月过生日的学生
50、查询下月过生日的学生
MySQL50题
建表 & 添加数据
/*
创建表
--1.学生表
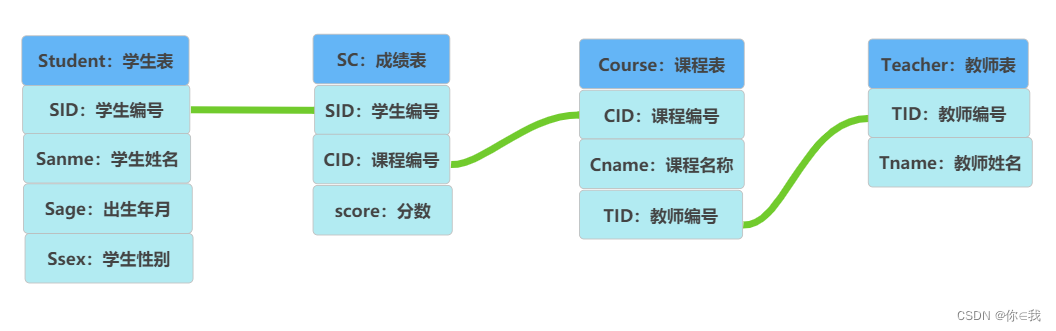
Student(SID,Sname,Sage,Ssex) --SID 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别
--2.课程表
Course(CID,Cname,TID) --CID --课程编号,Cname 课程名称,TID 教师编号
--3.教师表
Teacher(TID,Tname) --TID 教师编号,Tname 教师姓名
--4.成绩表
SC(SID,CID,score) --SID 学生编号,CID 课程编号,score 分数
*/
CREATE TABLE student
(SID VARCHAR(10),Sname VARCHAR(20),Sage DATETIME,Ssex VARCHAR(10));
# 插入数据
INSERT INTO Student VALUES('01' , '赵雷' , '1990-01-01' , '男');
INSERT INTO Student VALUES('02' , '钱电' , '1990-12-21' , '男');
INSERT INTO Student VALUES('03' , '孙风' , '1990-05-20' , '男');
INSERT INTO Student VALUES('04' , '李云' , '1990-08-06' , '女');
INSERT INTO Student VALUES('05' , '周梅' , '1991-12-01' , '女');
INSERT INTO Student VALUES('06' , '吴兰' , '1992-03-01' , '女');
INSERT INTO Student VALUES('07' , '郑竹' , '1989-07-01' , '女');
INSERT INTO Student VALUES('08' , '王菊' , '1990-01-20' , '女');
CREATE TABLE Course(CID VARCHAR(10),Cname VARCHAR(10),TID VARCHAR(10));
INSERT INTO Course VALUES('01' , '语文' , '02');
INSERT INTO Course VALUES('02' , '数学' , '01');
INSERT INTO Course VALUES('03' , '英语' , '03');
CREATE TABLE Teacher(TID VARCHAR(10),Tname VARCHAR(10));
INSERT INTO Teacher VALUES('01' , '张三');
INSERT INTO Teacher VALUES('02' , '李四');
INSERT INTO Teacher VALUES('03' , '王五');
CREATE TABLE SC(SID VARCHAR(10),CID VARCHAR(10),score DECIMAL(18,1));
INSERT INTO SC VALUES('01' , '01' , 80);
INSERT INTO SC VALUES('01' , '02' , 90);
INSERT INTO SC VALUES('01' , '03' , 99);
INSERT INTO SC VALUES('02' , '01' , 70);
INSERT INTO SC VALUES('02' , '02' , 60);
INSERT INTO SC VALUES('02' , '03' , 80);
INSERT INTO SC VALUES('03' , '01' , 80);
INSERT INTO SC VALUES('03' , '02' , 80);
INSERT INTO SC VALUES('03' , '03' , 80);
INSERT INTO SC VALUES('04' , '01' , 50);
INSERT INTO SC VALUES('04' , '02' , 30);
INSERT INTO SC VALUES('04' , '03' , 20);
INSERT INTO SC VALUES('05' , '01' , 76);
INSERT INTO SC VALUES('05' , '02' , 87);
INSERT INTO SC VALUES('06' , '01' , 31);
INSERT INTO SC VALUES('06' , '03' , 34);
INSERT INTO SC VALUES('07' , '02' , 89);
INSERT INTO SC VALUES('07' , '03' , 98);表结构分析图
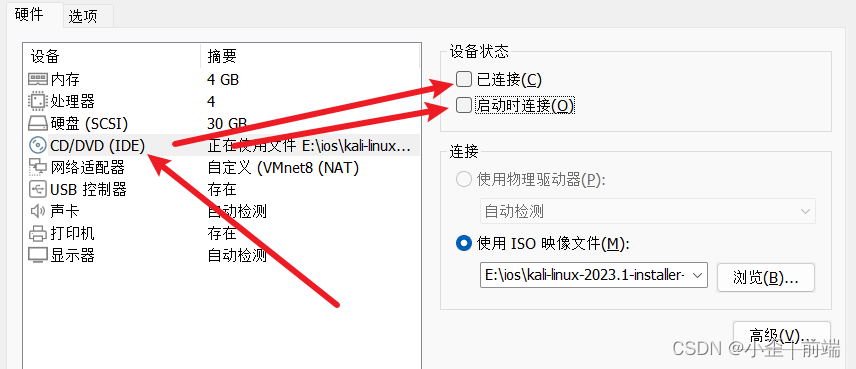
连接数据库
val spark: SparkSession = SparkSession.builder().appName("dataFrameMysql")
.master("local[*]")
.config("hive.metastore.uris", "thrift://192.168.152.192:9083")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val driver = "com.mysql.cj.jdbc.Driver"
val url = "jdbc:mysql://192.168.152.184:3306/students"
val user = "root"
val pwd = "123456"
val properties = new Properties();
properties.setProperty("user", user)
properties.setProperty("password", pwd)
properties.setProperty("driver", driver)
val studentDF: DataFrame = spark.read.jdbc(url, "student", properties)
val courseDF: DataFrame = spark.read.jdbc(url, "course", properties)
val teacherDF: DataFrame = spark.read.jdbc(url, "teacher", properties)
val scDF: DataFrame = spark.read.jdbc(url, "sc", properties)题目
1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
scDF.as("s1").join(scDF.as("s2"), "sid")
.filter("s1.cid=01 and s2.cid=02 and s1.score>s2.score")
.join(studentDF, "sid").show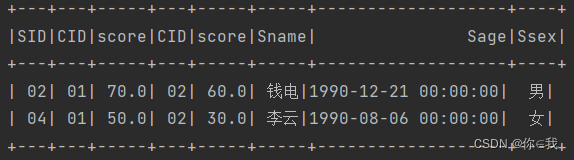
2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数
scDF.as("s1").join(scDF.as("s2"), "sid")
.filter("s1.cid=01 and s2.cid=02 and s1.score<s2.score")
.join(studentDF, "sid").show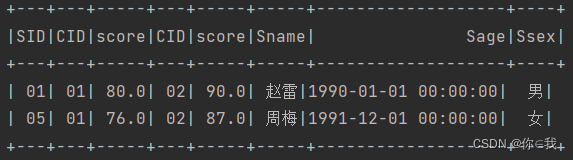
3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
scDF.as("s1").groupBy("sid").avg("score")
.join(studentDF.as("s2"), "sid")
.filter($"avg(score)" >= 60).show()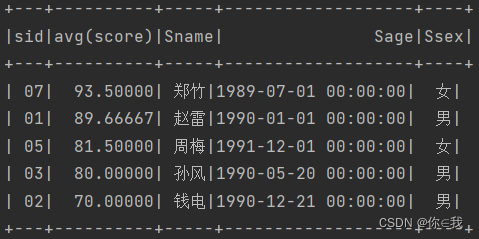
4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩的
scDF.as("s1").groupBy("sid").avg("score")
.join(studentDF.as("s2"), "sid")
.filter($"avg(score)" < 60).show()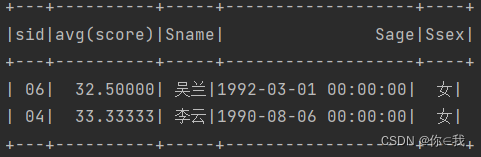
5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
studentDF.join(scDF.groupBy("sid").count(), Seq("sid"), "left_outer")
.join(scDF.groupBy("sid").sum(), Seq("sid"), "left_outer").show()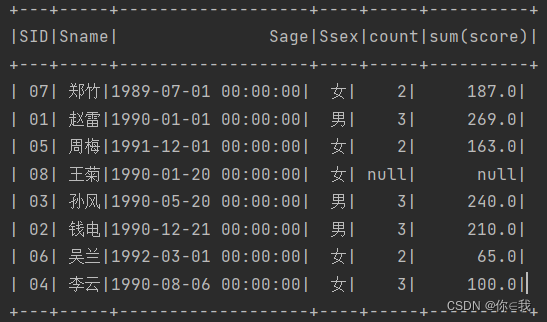
6、查询"李"姓老师的数量
println(teacherDF.filter(x => x.get(1).toString.contains("李")).count())![]()
7、查询学过"张三"老师授课的同学的信息
studentDF.join(teacherDF.where("tname='张三'")
.join(courseDF, "tid")
.join(scDF, "cid"), Seq("sid"), "left_outer")
.where("cid is not null")
.select("sid", "sname", "sage", "ssex", "tname")
.show()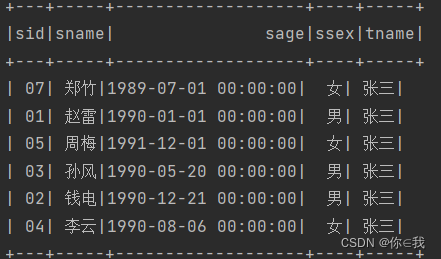
8、查询没学过"张三"老师授课的同学的信息
studentDF.join(teacherDF.where("tname='张三'")
.join(courseDF, "tid")
.join(scDF, "cid"), Seq("sid"), "left_outer")
.where("cid is null")
.select("sid", "sname", "sage", "ssex")
.show()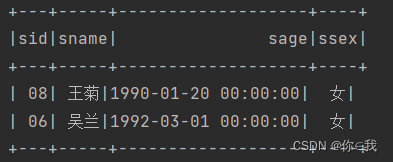
9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
scDF.join(scDF, "sid")
.filter(x => x.get(1).toString == "01" && x.get(3).toString == "02")
.join(studentDF, "sid")
.show()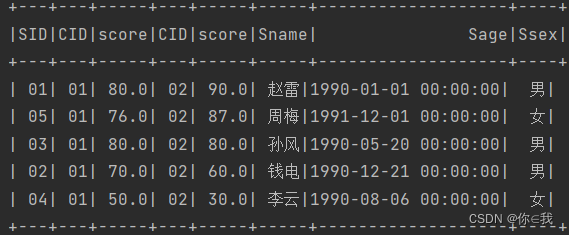
10、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
studentDF.join(scDF.where("cid = '02'"), Seq("sid"), "left_outer").as("s1")
.where("s1.cid is null")
.join(scDF.where("cid ='01'"), "sid")
.select("sid", "sname", "sage", "ssex")
.show()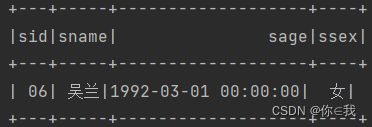
11、查询没有学全所有课程的同学的信息
val num: Int = courseDF.count().toInt
studentDF.join(scDF, Seq("sid"), "left_outer")
.groupBy("sid").count()
.where(s"count != $num")
.join(studentDF, "sid")
.show() 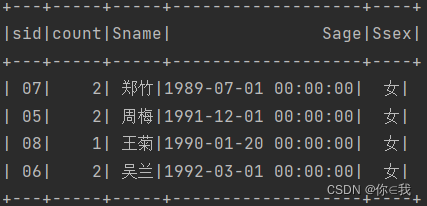
12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
scDF.filter(x => x.get(0).toString == "01").select("cid")
.join(scDF, "cid").select("sid").distinct()
.join(studentDF, "sid").show()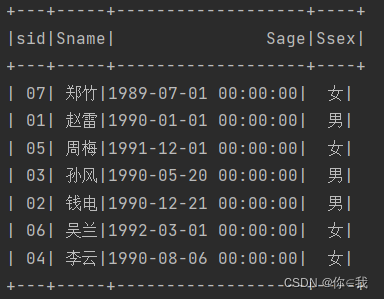
13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
scDF.join(scDF.select("cid").where("sid=01"), "cid")
.groupBy("sid").count()
.where(s"count=${scDF.where("sid=01").count()} and sid !=01")
.join(studentDF, "sid")
.show()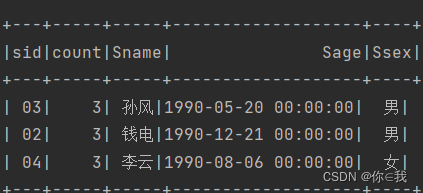
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
studentDF.join(scDF.join(courseDF.join(teacherDF, "tid")
.where("tname='张三'"), "cid")
.select("sid", "tname"), Seq("sid"), "left_outer")
.where("tname is null")
.select("sname")
.show()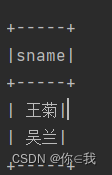
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
scDF.where("score<60").groupBy("sid").count()
.where("count>=2")
.join(scDF, "sid")
.groupBy("sid").avg("score")
.join(studentDF, "sid")
.show()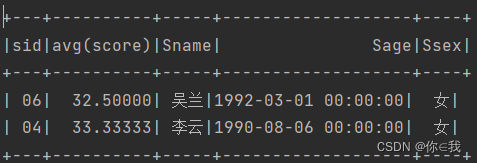
16、检索"01"课程分数小于60,按分数降序排列的学生信息
scDF.where("score < 60 and cid = 01")
.join(studentDF, "sid")
.orderBy(desc("score"))
.show()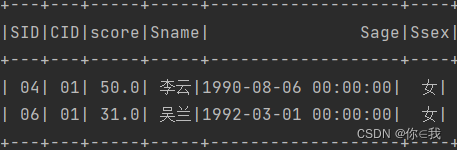
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
scDF.join(scDF.groupBy("sid").avg("score"), Seq("sid"), "left_outer")
.join(studentDF, "sid")
.orderBy(desc(avg("score").toString()))
.show()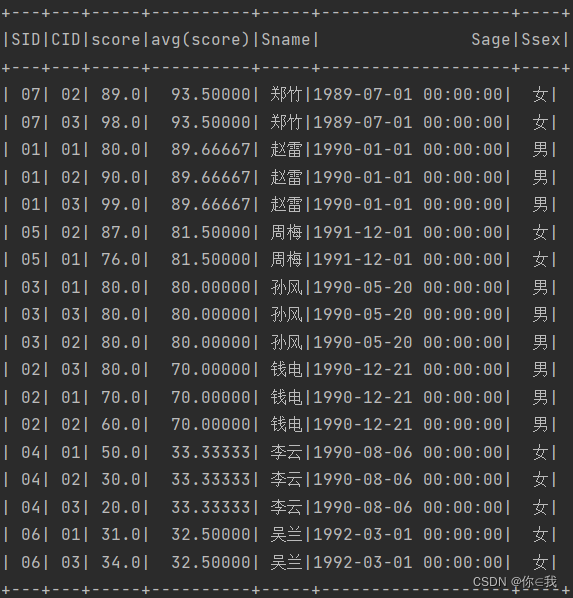
18、查询各科成绩最高分、最低分和平均分
以如下形式显示:
课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
// 第一步:按照课程分组,求及格的人数
val dfcount = scDF.groupBy("cid").count()
val dfpas = scDF.where($"score" >= 60).groupBy("cid").count().withColumnRenamed("count", "pas")
val dfmid = scDF.where($"score" >= 70 && $"score" < 80).groupBy("cid").count().withColumnRenamed("count", "mid")
val dfpre = scDF.where($"score" >= 80 && $"score" < 90).groupBy("cid").count().withColumnRenamed("count", "pre")
val dfsup = scDF.where($"score" >= 90).groupBy("cid").count().withColumnRenamed("count", "sup")
// 第二步:两列合并,及格人数/总人数,求及格率
val pas = dfcount.join(dfpas, "cid").withColumn("pas", col("pas") / col("count")).select("cid", "pas")
val mid = dfcount.join(dfmid, "cid").withColumn("mid", col("mid") / col("count")).select("cid", "mid")
val pre = dfcount.join(dfpre, "cid").withColumn("pre", col("pre") / col("count")).select("cid", "pre")
val sup = dfcount.join(dfsup, "cid").withColumn("sup", col("sup") / col("count")).select("cid", "sup")
// 第三步:将得到的数据进行汇总
scDF.join(courseDF, "cid")
.join(courseDF, "cid")
.groupBy("cid").agg(
max("score").as("max"),
min("score").as("min"),
avg("score").as("avg")
)
.join(pas, Seq("cid"), "left_outer")
.join(mid, Seq("cid"), "left_outer")
.join(pre, Seq("cid"), "left_outer")
.join(sup, Seq("cid"), "left_outer")
.orderBy($"avg".desc)
.show()
19、按各科成绩进行排序,并显示排名
scDF.join(studentDF.select("sid", "sname"), "sid")
.selectExpr("*", "row_number() over(partition by cid order by score desc) as rank").show()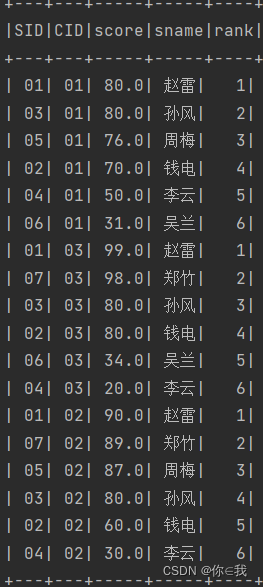
20、查询学生的总成绩并进行排名
scDF.selectExpr("*", "sum(score) over(partition by sid) as sum_score")
.drop("score", "cid").distinct()
.selectExpr("*", "row_number() over(order by sum_score) as rank")
.show() 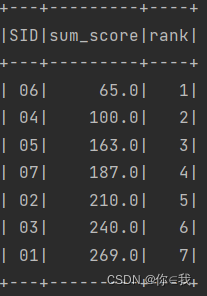
21、查询不同老师所教不同课程平均分从高到低显示
teacherDF.join(courseDF, "tid").join(scDF, "cid")
.groupBy("cid", "tid").agg(avg("score").as("avg"))
.orderBy($"avg".desc)
.show()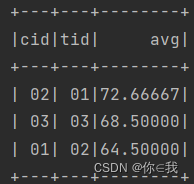
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
scDF.selectExpr("*", "row_number() over(partition by cid order by score desc) rank")
.where($"rank" between(2, 3))
.join(studentDF, "sid").show()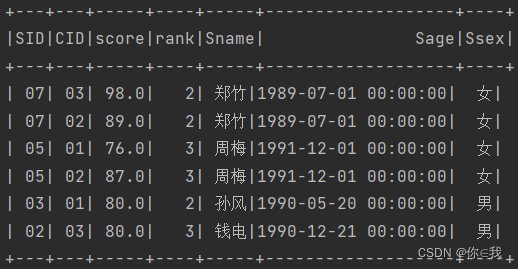
23、统计各科成绩各分数段人数:课程编号,课程名称, 100-85 , 85-70 , 70-60 , 0-60 及所占百分比
scDF.groupBy("cid").agg(
count("score"),
count(when($"score".between(85, 100), 1)),
count(when($"score".between(70, 85), 1)),
count(when($"score".between(60, 70), 1)),
count(when($"score".between(0, 60), 1))
)
.withColumnRenamed("count(score)", "count")
.withColumnRenamed("count(CASE WHEN ((score >= 85) AND (score <= 100)) THEN 1 END)", "min60")
.withColumnRenamed("count(CASE WHEN ((score >= 70) AND (score <= 85)) THEN 1 END)", "60-70")
.withColumnRenamed("count(CASE WHEN ((score >= 60) AND (score <= 70)) THEN 1 END)", "70-85")
.withColumnRenamed("count(CASE WHEN ((score >= 0) AND (score <= 60)) THEN 1 END)", "85-100")
.withColumn("min60", $"min60" / $"count")
.withColumn("60-70", $"60-70" / $"count")
.withColumn("70-85", $"70-85" / $"count")
.withColumn("85-100", $"85-100" / $"count")
.join(courseDF, "cid")
.select("cid", "cname", "min60", "60-70", "70-85", "85-100")
.show()
24、查询学生平均成绩及其名次
scDF.groupBy("sid").avg("score")
.selectExpr("*", s"row_number() over(order by 'avg(score)') as rank").show()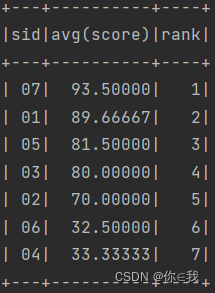
25、查询各科成绩前三名的记录
scDF.selectExpr("*", "row_number() over(partition by cid order by score desc) as rank")
.filter("rank<=3")
.show()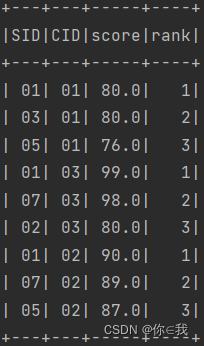
26、查询每门课程被选修的学生数
scDF.groupBy("sid").count()
.show()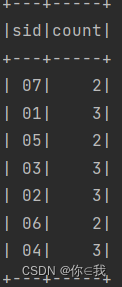
27、查询出只有两门课程的全部学生的学号和姓名
scDF.groupBy("sid").count().where("count=2")
.join(studentDF, "sid")
.show()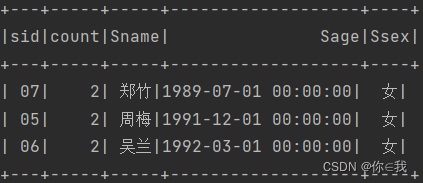
28、查询男生、女生人数
studentDF.groupBy("ssex").count().show()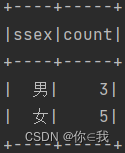
29、查询名字中含有"风"字的学生信息
studentDF.where("sname like '%风%'").show()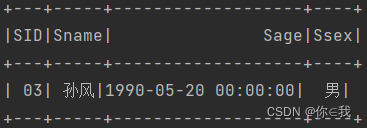
30、查询同名同性学生名单,并统计同名人数
studentDF.as("s1").join(studentDF.as("s2"))
.where(" s1.Sname = s2.Sname and s1.Ssex = s2.Ssex and s1.SID != s2.SID")
.show()输出结果:没有同名同性学生
31、查询1990年出生的学生名单(注:Student表中Sage列的类型是datetime)
studentDF.where(year($"sage") === 1990).show()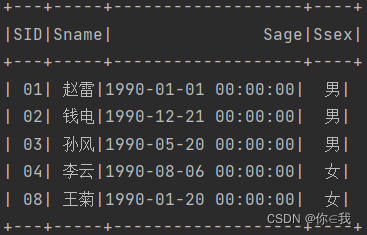
32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
scDF.groupBy("cid").agg(avg("score").as("avg"))
.orderBy($"avg".desc, $"cid".asc)
.show()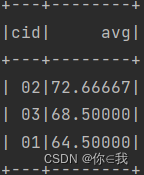
33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
scDF.groupBy("sid").avg("score")
.where($"avg(score)" >= 85)
.join(studentDF, "sid")
.show()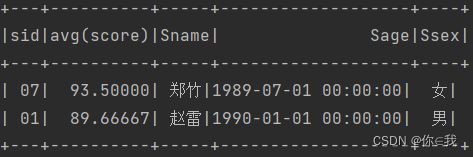
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
scDF.join(courseDF, "cid").join(studentDF, "sid")
.where($"cname".equalTo("数学") && $"score" < 60)
.show()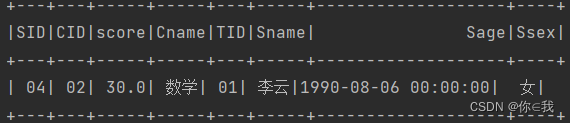
35、查询所有学生的课程及分数情况
studentDF.join(scDF, Seq("sid"), "left_outer")
.show()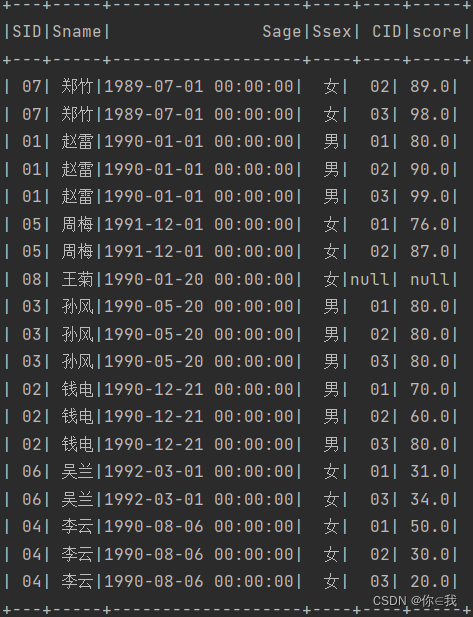
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
scDF.filter("score>=70")
.join(studentDF.select("sid", "sname"), "sid")
.join(courseDF, "cid")
.show()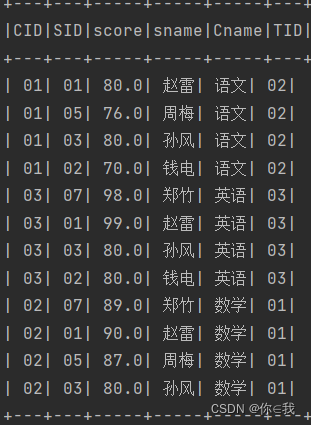
37、查询不及格的课程
scDF.where("score<60").join(studentDF, "sid")
.show()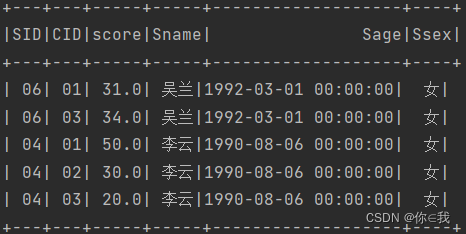
38、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名
scDF.where("cid=01 and score>=80")
.join(studentDF, "sid")
.show()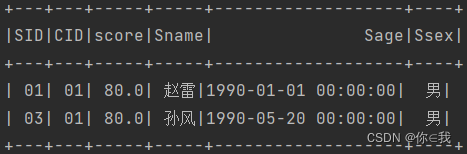
39、求每门课程的学生人数
scDF.groupBy("cid").agg(count("cid"))
.show()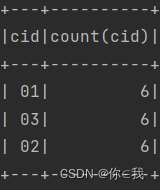
40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
teacherDF.filter(x => x.getString(1).equals("张三")).join(courseDF, "tid")
.join(scDF, "cid")
.join(studentDF, "sid")
.groupBy("tid").max("score")
.show()
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
scDF.as("s1").join(scDF.as("s2"), "score")
.filter("s1.sid!=s2.sid and s1.cid!=s2.cid")
.join(studentDF, "sid")
.show()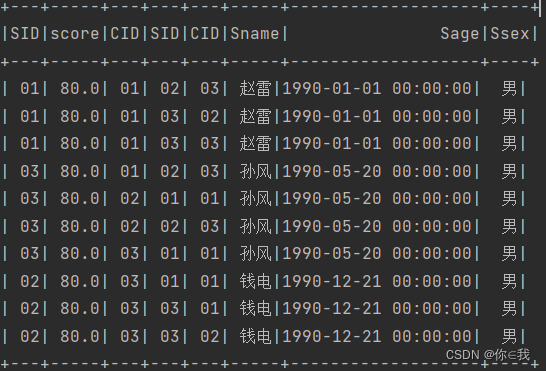
42、查询每门功课成绩最好的前两名
scDF.selectExpr("*", "row_number() over(partition by cid order by score desc) rank")
.filter("rank<=2")
.join(studentDF, "sid")
.show() 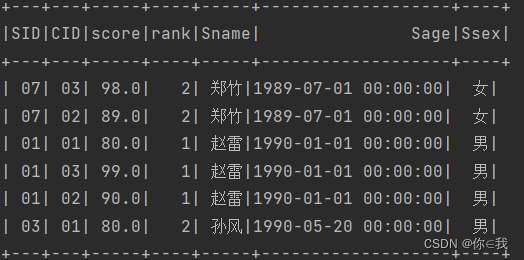
43、统计每门课程的学生选修人数(超过5人的课程才统计)
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
scDF.groupBy("cid").count().filter("count>5")
.orderBy(desc("count"), asc("cid"))
.show() 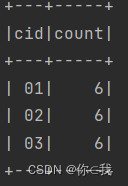
44、检索至少选修两门课程的学生学号
scDF.groupBy("sid").count().filter("count>=2")
.join(studentDF, "sid")
.select("sid")
.show()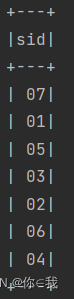
45、查询选修了全部课程的学生信息
scDF.groupBy("sid").count().filter("count=3")
.join(studentDF, "sid")
.show()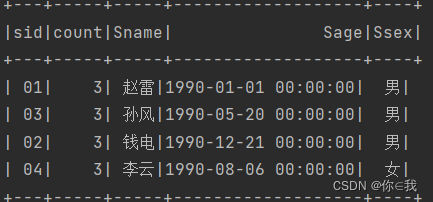
46、查询各学生的年龄
studentDF.withColumn("sage", year(current_date()) - year($"sage"))
.show()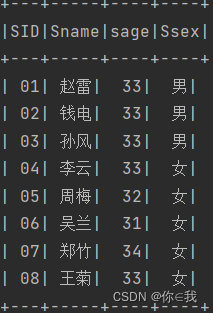
47、查询本周过生日的学生
studentDF.where(weekofyear(current_date()) === weekofyear($"sage"))
.show()
输出结果:数据中没有本周学生(4.16-4.22)
48、查询下周过生日的学生
studentDF.where(weekofyear(current_date() + 1) === weekofyear($"sage"))
.show()输出结果:数据中没有本周学生(4.9-4.15)
49、查询本月过生日的学生
studentDF.where("month(sage)=month(current_date)")
.show()输出结果:数据中没有本月学生(4月)
50、查询下月过生日的学生
studentDF.where("month(sage)==if(month(current_date())==12,1,(month(current_date())+1))")
.show()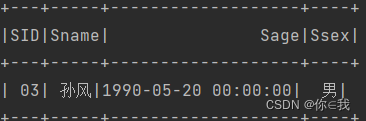







![[Netty源码] 服务端启动过程 (二)](https://img-blog.csdnimg.cn/09ce0283fb784650a30d1b442018e098.png)