随时有八股思考都更新一下,理解的学一下八股。谢谢大家的阅读,有错请大家指出。
bean的生命周期
实际上只有四步
实例化 ----> 属性赋值 ---> 初始化 ---> 销毁
但是在实例化前后 初始化前后 会存在一些前置后置的处理,目的是增强bean在初始化完成后的功能,或者是增强bean在创建过程中的日志记录。
总体流程为 IOC容器启动--》创建beanFactory---》读取xml配置文件--》实例化bean---》属性注入--》初始化bean--》使用---》销毁
单例模式思考
bean被声明为单例的时候,在处理多次请求的时候在Spring容器里只实例化出一个bean。目的是为了我们全局使用的都是一个bean对象,不会存在每调用一次就会创建一个bean的情况,
目的是以下几点:1、减少内存占用,每次都创建bean,占用过多不必要的资源 2、减少JVM的垃圾回收,在创建过的的bean的时候,此时内存会进行垃圾回收,影响系统效率。 3、若容器中已经有对应的bean,这时候就直接获取,减少创建过程。
工厂模式使用思考
在spring创建bean中,首先我们要通过读取xml文件,或者commentScan方法读取注解,找到我们想要创建的bean的定义。这时候如果我们只是通过没扫描到一个bean就new的方法,扩展性不强,而且代码耦合性高,无法对外扩展。使用工厂模式,我们只需要传入bean的名称,或者bean 的类型,只由工厂对外提供创建方法,扫描到bean的时候,调用工厂的创建方法即可。
springboot自动装配粗略流程
springboot 对比spring优化地方在于,基础组件在导入时候会自动创建bean,但是器本质上还是读取文件,找到bean定义。
以自动装配redis为例:
1、容器启动 依靠SpringApplication 注解,开启自动装配功能
2、扫描所有的spring.factories 文件,里边定义了各种自动装配类的类全路径例如
org.springframework.boot.autoconfigure.EnableAutoConfiguration=
org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration,\3、拿到RedisAutoConfiguration类之后会根据条件判断,是否导入了redis 依赖,导入依赖呢么就会绑定redis的属性文件,redis的属性文件又和application.properties文件的属性值绑定,因此自动创建出了redis
ThreadlLocal
ThreadLocal 用于实现线程本地存储,为每个线程提供独立的变量副本,具备线程隔离特性,可存储线程上下文信息,典型应用是存储每个请求携带的用户信息。
实现原理
ThreadLocal 的实现基于 Thread 类中的 ThreadLocalMap 成员变量。每个 Thread 对象都有自己的 ThreadLocalMap,该 ThreadLocalMap 中存储数据的键(key)是 ThreadLocal 对象。
set方法:调用ThreadLocal的set方法时,会获取当前线程的ThreadLocalMap,并将ThreadLocal实例作为键,要设置的值作为值存储在ThreadLocalMap中。get方法:调用get方法时,同样会获取当前线程的ThreadLocalMap,并根据ThreadLocal实例作为键来获取对应的值。
内存泄漏问题
弱引用设计目的
ThreadLocalMap 的键是弱引用(WeakReference),值是强引用。弱引用是一种较弱的引用关系,当一个对象只被弱引用所引用时,在垃圾回收时,无论当前内存是否充足,该对象占用的内存都会被回收。这样设计的主要目的是,当外部没有对 ThreadLocal 实例的强引用时,让 ThreadLocal 实例可以被垃圾回收。
内存泄漏原因
如果 ThreadLocal 对象被回收(例如将其定义为局部变量,使用完后局部变量作用域结束),但线程仍然存活,ThreadLocalMap 中的值不会被回收,从而导致内存泄漏。具体过程如下:
当 ThreadLocal 实例没有外部强引用时,由于它在 ThreadLocalMap 中是以弱引用的形式存在,在垃圾回收时,ThreadLocal 实例会被回收,此时 ThreadLocalMap 中的键就会变成 null。但 ThreadLocalMap 中的值(value)是通过强引用存储的,只要当前线程还存在,ThreadLocalMap 就不会被销毁,这些值就不会被回收,即使这些值已经没有实际使用意义。
线程池场景下的内存泄漏隐患
线程池的核心特性是线程复用。当任务提交到线程池,线程池会获取空闲线程执行任务,任务执行完毕后,线程不会被销毁,而是放回线程池等待下一个任务。
在某个任务中使用 ThreadLocal 存储数据,任务执行结束后,由于线程复用,ThreadLocalMap 仍存在于线程中。若此时 ThreadLocal 对象的强引用被释放(如局部变量作用域结束),ThreadLocal 对象只能通过 ThreadLocalMap 中的弱引用(Entry 的 key)引用,下次垃圾回收时,ThreadLocal 对象会被回收,导致 Entry 中的 key 变为 null。
由于线程未被销毁,ThreadLocalMap 一直存在,Entry 中的 value 不会被回收(除非手动清除)。随着线程不断复用并使用 ThreadLocal,内存中会积累大量无法回收的 value,进而引发内存泄漏。
在一个Thread中他的ThreadLocalMap只有一个,但是ThreadLocal可以有多个。
public static final ThreadLocal<String> tl1 = new ThreadLocal<>();
public static final ThreadLocal<Long> tl2 = new ThreadLocal<>();
public static final ThreadLocal<Integer> tl3 = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(()->{
tl1.set("1");
tl2.set(2L);
tl3.set(3);
System.out.println(tl1.get());
System.out.println(tl2.get());
System.out.println(tl3.get());
}).start();
}Map
1.8之前数组+链表 1.8 之后数组+链表+红黑树变形
1、为什么长度为2的次方
由于在放入元素时候是利用key的hash值做取余操作,但是计算机运算是利用位运算来实现取余操作,而位运算都是以2为底的运算
2、为什么计算hash要用hashcode
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}如果使用直接使用hashCode对数组大小取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的,所以我们的思路就是让 hashCode取值出的高位也参与运算,进一步降低hash碰撞的概率,使得数据分布更平均,使得到的 hash 值更加散列,尽可能减少哈希冲突,提升性能
3、put操作流程
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值
对,否则转向⑤;
⑤.遍历table[i],并记录遍历长度,如果遍历过程中发现key值相同的,则直接覆盖value,没有相同的key则在链表尾部插入结点,插入后判断该链表长度是否大等于8,大等于则考虑树化,如果数组的元素个数小于64,则只是将数组resize,大等于才树化该链表;
⑥.插入成功后,判断数组中的键值对数量size是否超过了阈值threshold,如果超过,进行扩容
4、get
首先根据 hash 方法获取到 key 的 hash 值
然后通过 hash & (length - 1) 的方式获取到 key 所对应的Node数组下标 ( length对应数组长度 )
首先判断此结点是否为空,是否就是要找的值,是则返回空,否则判断第二个结点是否为空,是则返回空,不是则判断此时数据结构是链表还是红黑树
链表结构进行顺序遍历查找操作,每次用 == 符号 和 equals( ) 方法来判断 key 是否相同,满足条件则直接返回该结点。链表遍历完都没有找到则返回空。
红黑树结构执行相应的 getTreeNode( ) 查找操作。
5、为什么链表长度为8 才转为红黑树
通常使用链表来处理key冲突的情况,但是随着数据增长,链表会长,所以为了保持查询效率,长度为8时候转为红黑树,退回6时候,在转为链表。选8的原因是,数据分布经过hash函数的计算后,不会出现很大程度上的堆积,并且我们用map时候也不会存非常多数据,所以这种情况概率很小。
6、扩容
1.7扩容 1、当前存储的数量大于等于阈值 2、发生hash碰撞
就是hashmap在存值的时候(默认大小为16,负载因子0.75,阈值12),可能达到最后存满16个值的时候,再存入第17个值才会发生扩容现象,因为前16个值,每个值在底层数组中分别占据一个位置,并没有发生hash碰撞。
当然也有可能存储更多值(超多16个值,最多可以存26个值)都还没有扩容。原理:前11个值全部hash碰撞,存到数组的同一个位置(这时元素个数小于阈值12,不会扩容),后面所有存入的15个值全部分散到数组剩下的15个位置(这时元素个数大于等于阈值,但是每次存入的元素并没有发生hash碰撞,所以不会扩容),前面11+15=26,所以在存入第27个值的时候才同时满足上面两个条件,这时候才会发生扩容现象
先扩容后添加
1.8扩容:先添加后扩容 1、当前存储的数量大于等于阈值 2、当某个链表长度>=8,但是数组存储的结点数size() < 64时
扩容是同步的
concurrenthashmap
concurrenthashmap是线程安全的,过原子操作和局部加锁的方法保证了多线程的线程安全。
hashtable 是线程安全的,但只是在put方法上加上synchronized,但是也因此性能低下。
1.7时
JDK 1.7 中它使用的是分段数组加链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。分段就是一个分片,标识hash值的范围
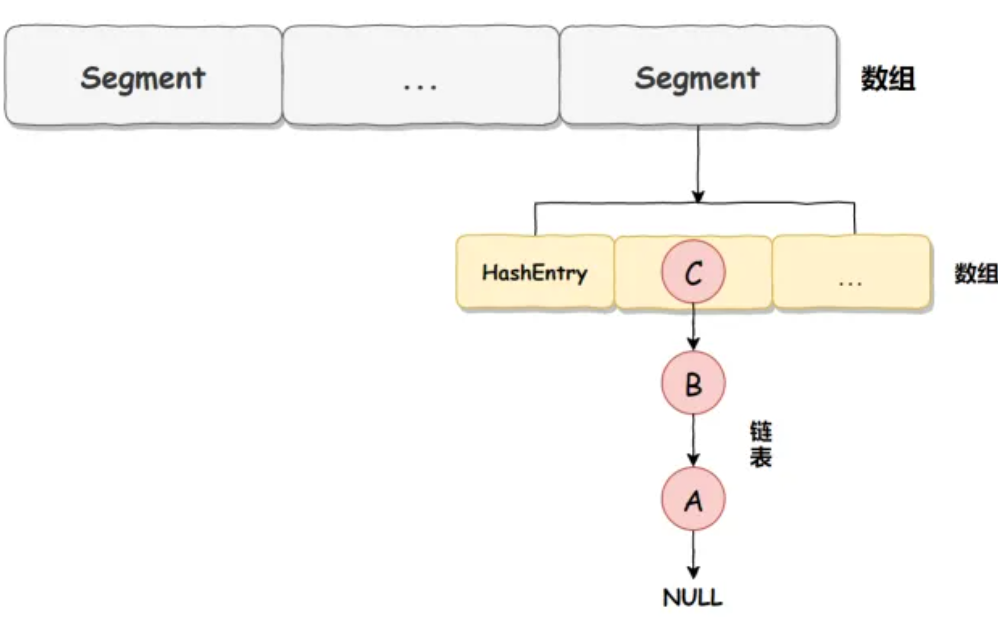
基于ReentrantLock 加分段锁
1.8
使用CAS+synchronized 。
查到空节点使用CAS去插入数据,不为空则使用 synchronize 加锁,遍历链表中的数据,替换或新增节点到链表中
List
ArrayList
数组实现,线程不安全的。底层是数组,初始大小默认10。添加元素时,若元素个数加1大于当前数组长度则扩容,扩容后大小约为原数组的1.5倍。还分析了按约1.5倍扩容的原因,是为避免频繁扩容和空间浪费,且能利用移位操作。
int newCapacity = oldCapacity + (oldCapacity >> 1)LinkedList
双向链表,不需要连续的空间
CopyOnWriteArrayList
是通过数组实现的,但确是线程安全容器。CopyOnWriteArrayList的增删改都需要获得锁,并且锁只有一把,而读操作不需要获得锁,支持并发。在增删改的过程中都会创建一个新的数组,操作完成之后再赋给原来的引用,这是为了保证get的时候都能获取到元素,如果在增删改过程直接修改原来的数组,那么可能会造成执行读操作获取不到数据。因此在增删改的过程中都会先创建一个数组。待操作完成之后再将新数组的引用赋值给array。
使用每个方法内用synchronized、和Volatile 修饰数组
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1);
es[len] = e;
setArray(es);
return true;
}
}
final transient Object lock = new Object();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;因为在写操作中,都使用了synchronized,会影响效率,所以使用写时复制技术,写操作是原子操作,array是volatile的,在读的时候,只要写好了,就可以读最新值,没写好,也不会影响读操作的进行。