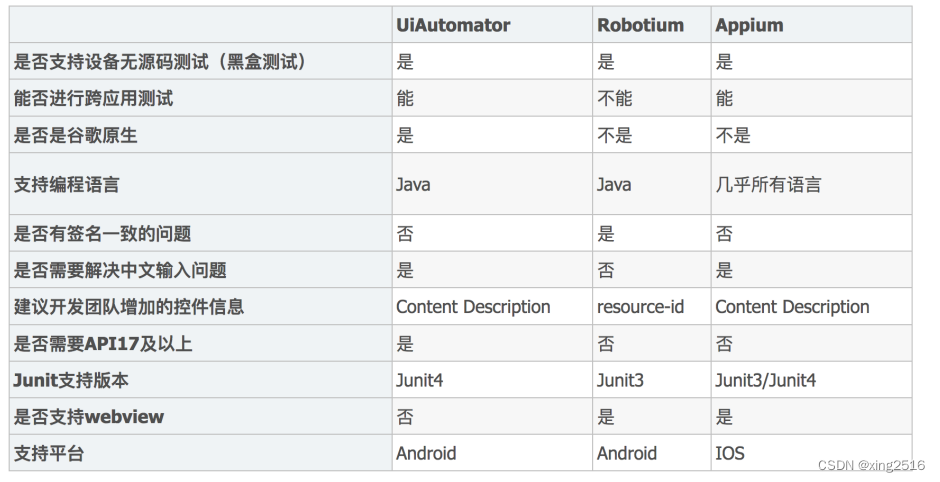
10 年来,DNN 的变革给计算机视觉领域带来了重大发展,促成了各种实时任务的繁荣,如图像分类、目标检测、语义分割等。然而强大的网络通常得益于大的网络容量,这通常以大量的计算和存储为代价,是工业应用所不喜欢的。在工业应用中,广泛采用的是轻量的模型。知识蒸馏是减小这种代价的一个有效方法,它可以把重型模型的知识迁移到轻型模型上,从而提高轻型模型的性能。知识蒸馏的概念最初是 Hinton 在论文 “Distilling the knowledge in a neural network” 中提出的,它通过最小化老师网络和学生网络输出 logit 的 KL 散度来完成知识迁移,见下图 (a)。但是自从 Fitnets 以来,有关知识蒸馏的研究大多都转移到了对中间层的深度特征的知识蒸馏,因为基于特征的蒸馏在各种任务上都性能更加优异。然而基于特征的蒸馏有一个缺点:在训练过程中,会引入大量额外的对计算和存储资源的需求。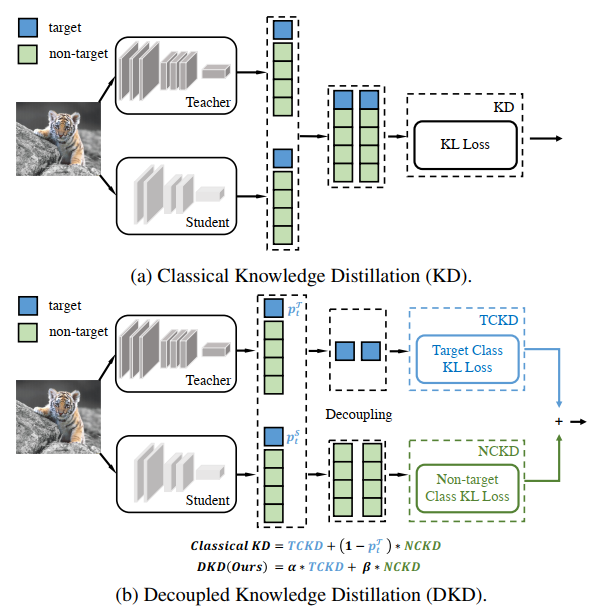
基于 logit 的蒸馏恰恰能解决这一问题,只是经典 KD 性能一般。从直觉上来说,基于 logit 的知识蒸馏应当能达到和基于特征的知识蒸馏相当的性能,因为 logits 相对于深层特征,表达了更高层次的语义。“Decoupled Knowledge Distillation”论文重构了经典知识蒸馏的表达方式,通过新的表达方式分析了经典的基于 logit 的知识蒸馏性能不理想的原因,并提出了解决问题的方法:解耦知识蒸馏(Decoupled Knowledge Distillation, DKD),一种新的基于 logit 的知识蒸馏,见上图 (b)。DKD 在各种任务上能达到 SOTA,比起基于特征的知识蒸馏,有着更高的训练效率和特征迁移性能。
重新思考知识蒸馏
重写知识蒸馏的公式
一些标记符号:
分类概率 ,其中 中的每个元素可以表示为公式(1), 表示第 i 类的 logit 输出。
二元概率 , 表示目标类的概率, 表示所有其他的非目标类的概率,可以按下面的公式进行计算:
非目标类中的独立的模型概率分布
重写公式
表示老师, 表示学生,经典的 KD 使用 KL 散度来计算 loss,忽略温度 T,其 loss 值可以用公式(3)表示。
因为公式(1)和公式(2),我们有:所以公式(3)能表示为公式(4):
公式(4)可以进一步表示为公式(5):
在公式(5)中,KD loss 被表示成为了两项的加权求和的形式。加号左侧表示老师和学生之间对目标类的二元概率分布的相似性,论文把它叫做 Target Class Knowledge Distillation(TCKD)。加号右侧的项表示在非目标类中,老师和学生概率分布的相似程度,叫做 Non-Target Class Knowledge Distillation(NCKD)。故公式(5)可以表示为:
公式(6)是经典 KD 的新的表达方式,通过公式(6),论文研究分析了 TCKD 和 NCKD 对蒸馏的独立影响。
TCKD 与 NCKD 的效果
论文通过一系列的实验,探究了 TCKD 和 NCKD 对蒸馏的影响,总结如下:
单独使用 TCKD 进行蒸馏是没有帮助甚至是有害的。单独使用 NCKD 可以得到和经典 KD 相当或更好的性能。NCKD 和 TCKD 对蒸馏的重要性是不同的。NCKD 更重要。
TCKD 能表示和训练样本难易相关的知识,训练样本越难,TCKD 就能提供更多的知识。
NCKD 提供的非目标类的知识对基于 logit 的蒸馏至关重要, NCKD 是基于 logit 的蒸馏有效果但被性能抑制的主要原因。从公式(6)可以看出,NCKD 与 耦合,其中 表示老师在目标类上的置信度。通常认为老师在训练样本上的置信度越高,它传递的知识越有价值越可靠。然而 NCKD 的损失权重被这样的置信度预测严重抑制,这就限制了知识迁移的效果。
解耦知识蒸馏(DKD)
TCKD 和 NCKD 都是重要且不可缺少的。然而经典 KD 中,TCKD 和 NCKD 存在如下两方面的耦合:
NCKD 与 耦合,当 TCKD 展现很好的预测效果时,NCKD 是被抑制的。
NCKD 和 TCKD 在蒸馏中的作用不同,在经典 KD 中是耦合的,不能对每一项的权重进行单独调整。
论文提出了一种新颖的基于 logit 的蒸馏,叫 DKD,公式如下,可以通过两个超参 和 平衡 TCKD 和 NCKD 的重要性。
通过 DKD,可以在 CIFAR-100 数据集和 ImageNet 数据集上,取得和最先进的特征蒸馏 ReviewKD 相当的效果。ReviewKD 和 DKD 结合,在 COCO 上可以取得 SOTA 的性能。
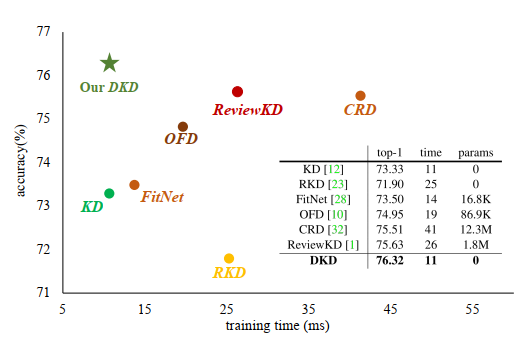
DKD 的优点:1.训练效率 DKD 的训练效率和经典 KD 是相当的,不需要很多额外的计算和存储资源,但是性能却非常优秀。下图横坐标是每个 batch 的训练时间,纵坐标是模型的 accuracy。老师模型是 ResNet32×4,学生模型是 ResNet8×4。该图很好的展示了 DKD 能够在模型性能和训练代价(如训练时间,额外的参数)之间取得很好的平衡。
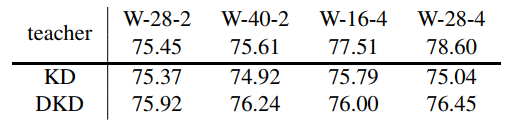
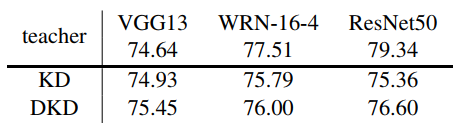
初步分析
知识蒸馏是模型压缩中一个非常有潜力的方向,他可以把大模型的知识迁移到小模型上,提升小模型的性能。小模型根据需要,可以部署到边缘设备或移动设备上。自从 Fitnets 以来,有关知识蒸馏的研究大多都转移到了对中间层的深度特征的知识蒸馏,但在训练过程中,会引入大量额外的对计算和存储资源的需求。基于 logit 的蒸馏训练快,消耗资源少,有其独特的优势。模型优化方向需要跟踪研究提升 logit 蒸馏性能的方法。我们在 ImageNet 数据集上对 DKD 的效果进行了简单探索,见下表。试验中,学生模型是 ResNet-50,老师模型是 convnext_base_in22ft1k。通过 DKD 的方式,可把学生模型的精度提升到 81.65%,比 KD 提高了 0.21%,可见 DKD 方式确实能提供比经典 KD 更加优越的性能。DKD 对每一项的权重进行单独调整,这是它的优势,但与经典 KD 相比多了一个超参需要调整,从某一个角度说也是它的不足,因为在调参时需要花费更多的精力。
| teacher | convnext_base_in22ft1k (85.82%) |
|---|---|
| KD | 81.44% |
| DKD | 81.65% |
好了,有关 DKD 的介绍就到这里。期待大家继续支持和关注 Adlik 的 Github 仓库。

参考文献
【1】Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. arXiv:1503.02531 [stat.ML], 2015.
【2】Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, Jiajun Liang. Decoupled Knowledge Distillation. arXiv:2203.08679 [cs.CV], 2022
【3】Pengguang Chen, Shu Liu, Hengshuang Zhao, and Jiaya Jia. Distilling knowledge via knowledge review. arXiv:2104.09044 [cs.CV], 2021

![[Netty源码] 服务端启动过程 (二)](https://img-blog.csdnimg.cn/09ce0283fb784650a30d1b442018e098.png)