摩尔定律最早由英特尔创始人之一戈登·摩尔在1965年提出,他认为集成电路上可以容纳的晶体管数目在大约每经过18到24个月便会增加一倍。20年后的今天,面对日新月异的社会和突飞猛进的数字化需求,摩尔定律也随着社会的进步而被赋予了新的定义。LiveVideoStackCon 2022北京站邀请到了网心科技CEO李浩为我们分享了如何构建新摩尔定律下的算力分发网络。
文/李浩
编辑/LiveVideoStack
我今天演讲的主题是《构建新摩尔定律下的算力分发网络》

1.算力奇点及对音视频内容的影响
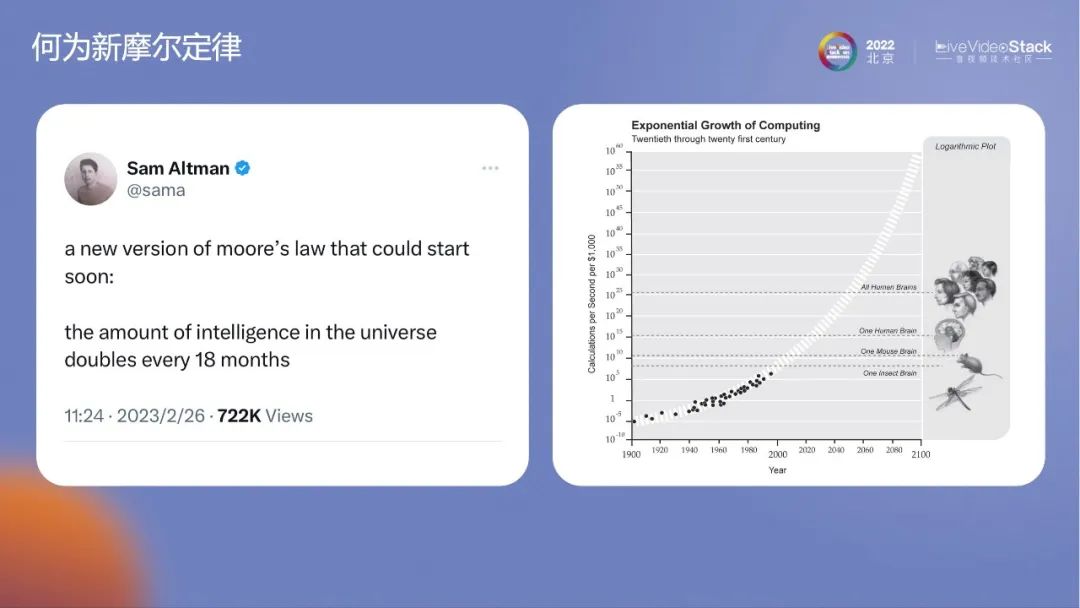
狭义的摩尔定律是指芯片、晶元和密度。现在,万物皆可摩尔定律。Sam Altman在推特上发表了一个颇具争议的话题——宇宙智能体会以18个月为周期翻倍。我个人对宇宙智能体的理解就是AI算力。右边的图是知名社会学家雷库兹韦尔在2005年出版一本书上的插图。该时间点出奇的吻合。2020年左右相当于一只老鼠的智商,而现在GPT-4的连接数在1万亿左右。人类的神经元连接数大约170万亿。1万亿是啮齿类动物的水平,典型的代表就是松鼠。按照摩尔定律GPT-4 用20年的时间就可以达到人类的水平。但如果按照GPT-3.5到GPT-4的速度来算,只需要2年的时间。没有人清楚真正到达170万亿以后会引起什么样的社会改变。现在,我们正处在一个巨大的历史变革时间点。
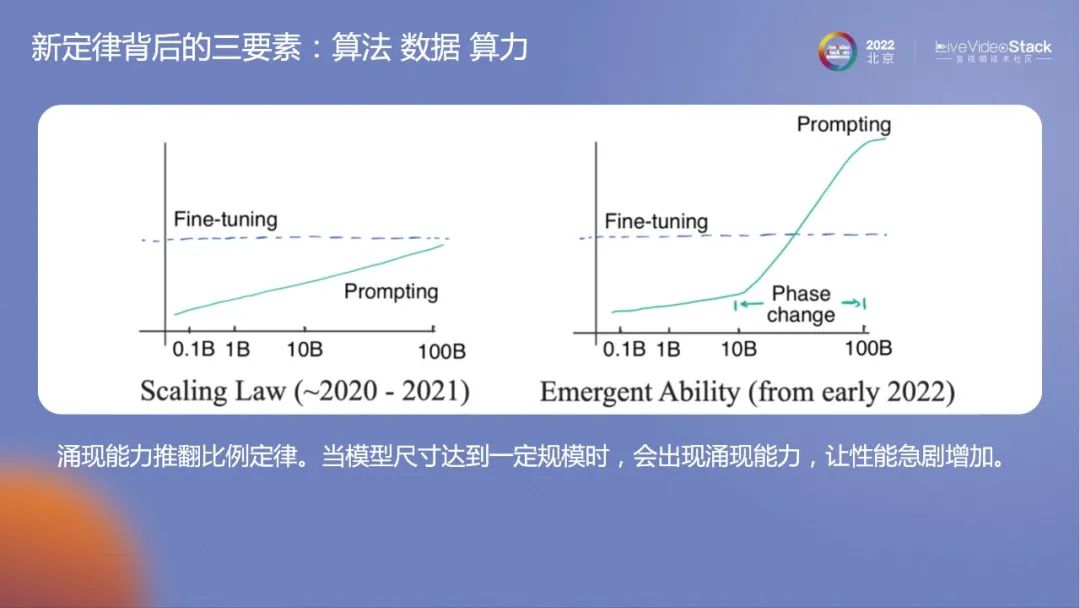
大模型有一个比例定律,其增长符合对数曲线。模型参数指数级增长,模型性能线性增长。因为这样的思维,我们还认为模型在行为智能性上达到人类水平还很遥远。
但当超过10billion以后,学者发现了有快速增长的相变曲线,出现了涌现能力。我认为这应该是OpenAI公司对人类最大的贡献,它证实了迭代大模型道路的可行性。模型越大,性能提升的速度越快。

下面简单介绍一下云计算行业。2010年左右云计算刚开始的时候,团队探讨过远景,我们认为云计算会分为以下三个阶段:
第一个阶段是资源维度,需要自己掌握机器、掌握DB、掌握网络以及掌握存储等,自己搭建出自己的服务。
第二个阶段是无服务化阶段,只需要用代码调度即可,更加面向开发者。当网络和服务都成熟以后,会进入到第三个阶段,面向使用者。
但第三个阶段形态较为复杂,使用困难,一直没有讨论出结果。但当大模型出现以后,一切都变得迎刃而解,自然语言就是最好的办法。当模型很好地理解自然语言时,算力调度逻辑就会变得平民化。这将对整个云计算行业来说都是一个巨大的突破。

对于音视频行业而言,不管是智能配音还是生成AI宣讲视频,现在自己完全可以构想出创意和文案,通过再现和智能配音,最后再生成一些视频,一整套下来仅需要半天时间。相比之前需要一整个团队做一个星期,现在非专业人士半天的时间就可以完成,生产力可以得到大幅提升。
对于传统的音视频内容,其在终端产生,在云端处理后分发给其他观众。中间的过程简单明了。在有了AGI以后,整体需要加工的内容变多。假设很多人在看《狂飙》,那么电视剧在分发给我的过程中,会根据我的喜好进行了一些改变,那么其算力的提升是不可避免的。数据的产生在边缘侧和云端会更多,这也导致内容生产分发源头出现了变化。

左边的图是IDC在2020年的预测,但我认为其数据较为保守,2025年绝大多数的数据都将储存在核心和边缘,远超于80%。以后一定会出现新的机会,对于个人数据节点,人工智能出现以后,会加速社会的数字化,个人数据将会成为最大的隐私财产。
2.边缘云成为新数据源头及引发架构变革
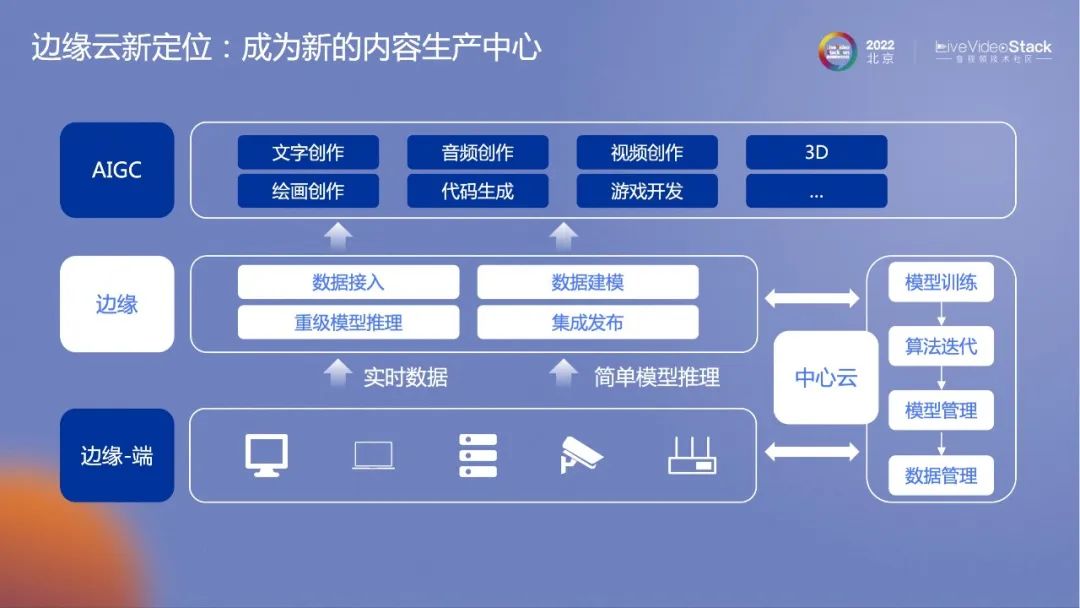
我认为边缘云会成为新的数据源头,同时也会引发新一轮的架构变革。数据运算需求的提升,运算将很难在终端完成,只能在边缘端和云端完成。随着需求增大,边缘端速度快、成本低,一定是云端很好的补充。云和边一起构建了泛化的云计算网络,未来将会承担大部分的数据生成和数据计算。而用户只需要很小的样本,即可生成个性化数据,一些本地化的工具也一定要云端化。目前包括Adobe等公司也已经开始着手去做了。
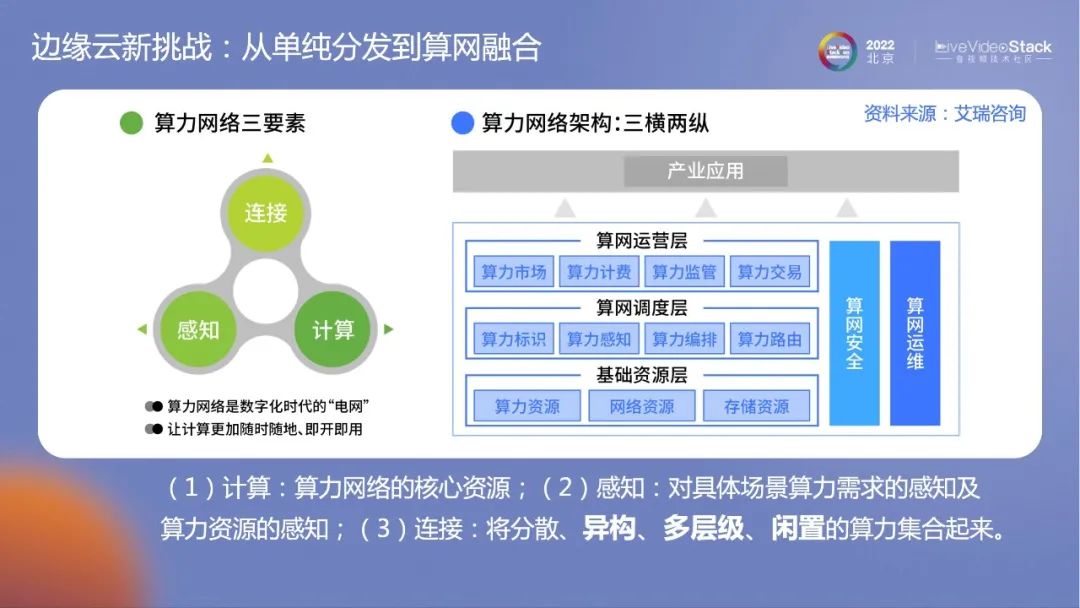
机会和挑战总是并存的。从技术角度出发,传统的网络结构中,可以像快递包裹一样分地很小很细,差异化不大。但是一旦叠加上算力,差异化就会非常大。GPT-4的参数量可以在6000到10000亿之间,需要一个多T的显存才可以加载,而一些小模型,几个G就可以加载。一些东西不可以原子分割,会导致分布变得复杂,需要根据需求调整分割。这里引用艾瑞咨询的报告来展开算力网络的三大要素。
算力网络有三大组成要素:
(1)计算:算力网络的核心资源。
(2)感知:对具体场景算力需求的感知及算力资源的感知。
(3)连接:将分散、异构、多层级、闲置的算力集合起来。
以上三大要素赋予算力网络功能属性和服务属性,让其能高效盘活全社会算力资源,并赋能产业应用。从算力网络的技术架构上看,从下到上可分为基础资源层、算网调度层和算网运营层,同时算网运维和算网安全贯穿全程,形成“三横两纵”的支撑形态。最终,算力网络会以产品或能力的形式,赋能产业应用。

未来,在边缘侧会有大量的内容生产过程。只需要叠加一些源数据,包括数字人、特效等都可以在边缘侧生成。下发的图片因为有强延时的需求,只能在边缘侧生成。
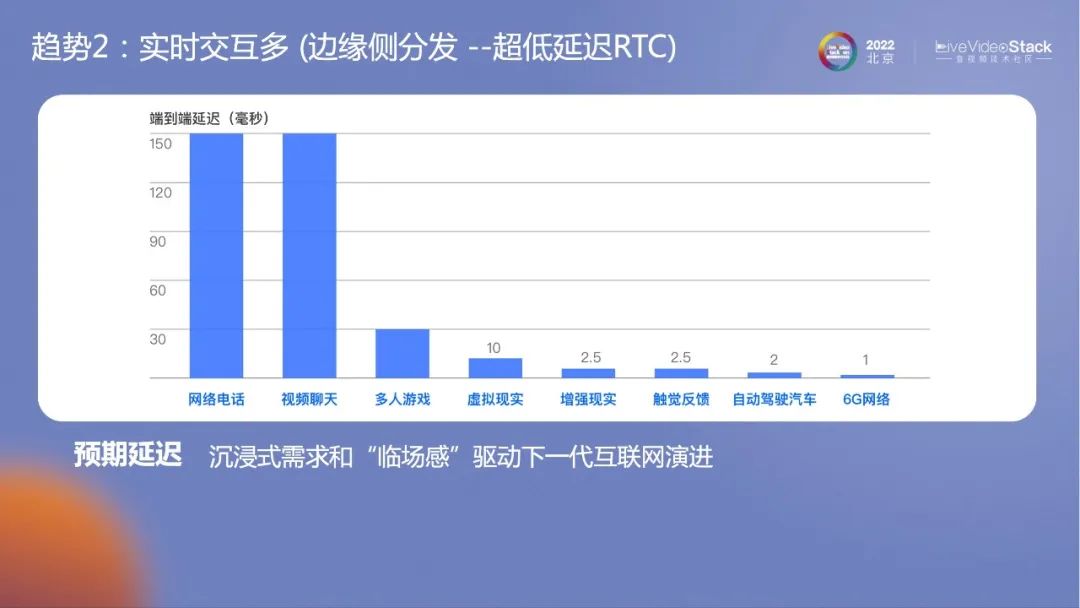
其次,实时交互也会更多。很多本地化的交互都会变成和云端的交互。目前云端交互最苛刻的应该是RTC场景视频对话。下一个潜在场景是云游戏。云游戏的交互所需要的延迟仅为视频的一半,不能超过100ms,再之后是10ms以内的虚拟现实等。随着演变,对网络分发算力的稳定性的要求会越来越苛刻,边缘侧分发必须具备超低延迟的能力。
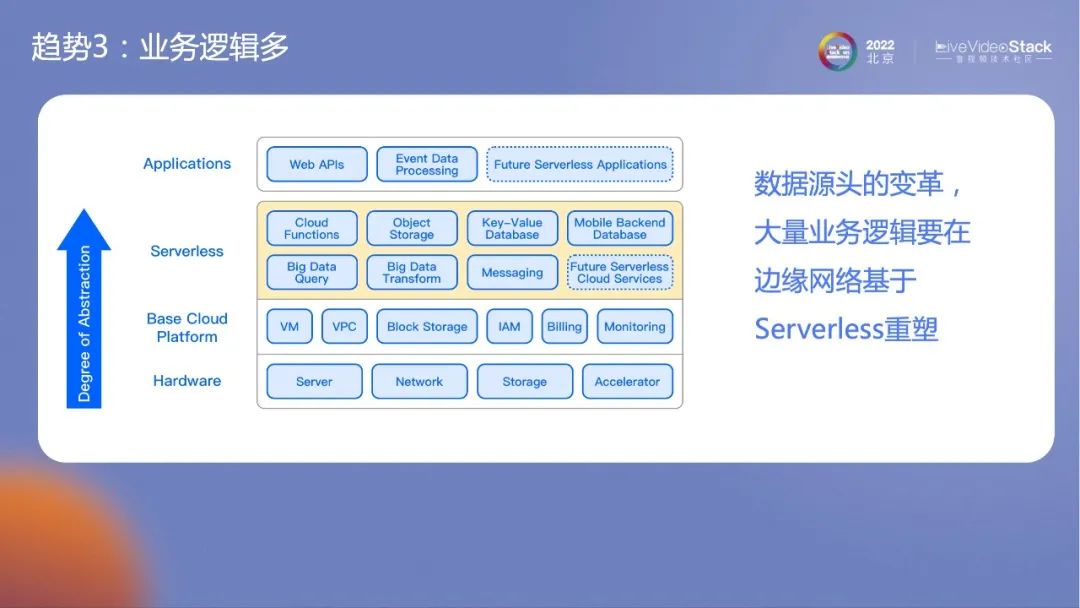
最后,业务逻辑也会增多。一旦数据源头发生变革,所有数据逻辑都需要重写。这和云计算最大的区别是不能以资源维度调动边缘,这样会过于复杂。所以边缘侧一定要以服务化为核心,要建立在Severless基础上重构业务逻辑。
3.网心音视频服务架构演进
网心针对上述提到的种种问题,做了很多的尝试。我们也推出了基于未来算力,为服务好音视频客户的产品。所以,我们的价值更加聚焦于如何给客户提供更低延时,更优、更便宜的算力,更加便捷的操作的服务。
先简单介绍一下网心科技。网心科技是国内最早做云计算的公司,也是全球最大、最下沉的边缘网络运营商。网心的理念是边缘云计算一定是一个平台模型。无论是自建、共建、合建,都要多层级碎片化的资源进行高效的整合,同时做到技术上的分装,让对外的接口标准化,服务好产业中的客户。现在网心主要的服务对象是音视频行业头部公司,同时也在AI、超低延时等场景中布局。现在网心的边缘节点数量规模已超过500万,通过自己的SDK覆盖了超过6亿的中国用户。
首先,看一下我们利用边缘闲置的主机构建的云游戏体验,整体的画面体验以及延时完全可以满足游玩的需求。
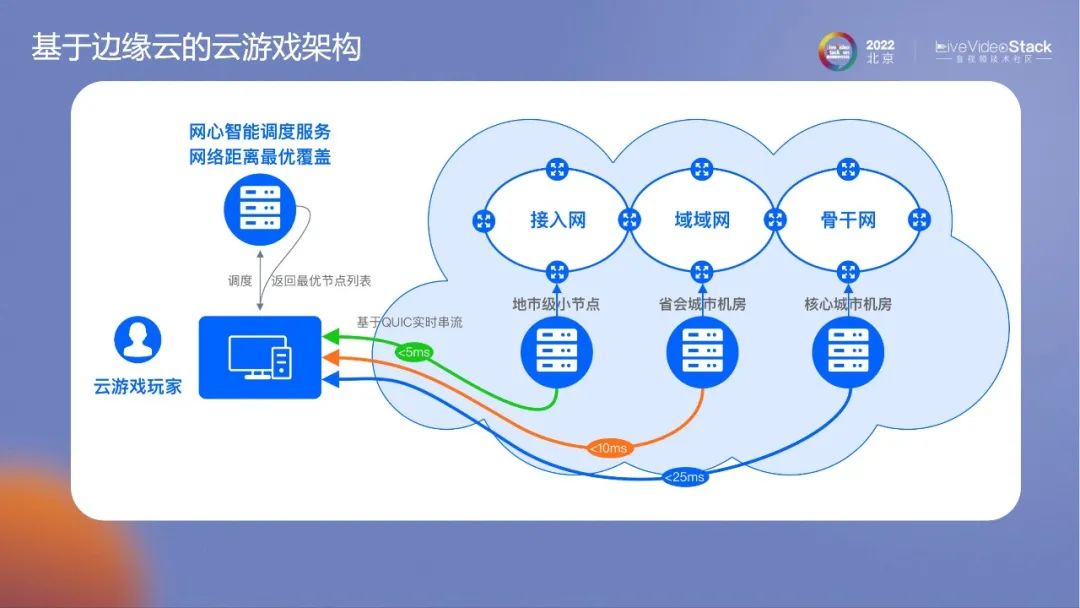
相比传统厂商,网心的云游戏架构最大的区别在于采用的是边缘侧的节点,覆盖密度更高。如果用中心云去做云游戏不仅成本不可控,延时也非常高,实现不了低于70ms的体验。通过构建的边缘网络,找到距离用户最近的节点将渲染和串流的体验做到最优。
网心提出了几个技术创新点。第一个是边缘网络独有的,正因为具有海量的边缘节点,所以可以非常清晰地感知到网络的状态,这是很多云计算厂商难以做到的。第二,所有的端到端协议都是网心自己做的。现在的RTC行业核心要解决双端交互的问题,但是云游戏是单端超低延时交互,高码率、高帧率、低延时是云游戏的三个基础特征。网心通过使用QUIC协议,将数据面和控制面分离。在应对高码率、高帧率、超低延时也引入新的拥塞控制和RS FEC等技术。
基于上述创新技术,我们看到在可用带宽快速恢复上,在出现网络大丢包情况下500ms就可以恢复到理想的数值。弱网表现的测试结果显示,OT QUIC 丢包最优,延时优于indigo。
我们再来看下AIGC文本生成图片场景。边缘主要以小算力为主,这类的小模型非常适合在边缘跑,并且其单任务、少交互的方式更加契合边缘的算法。
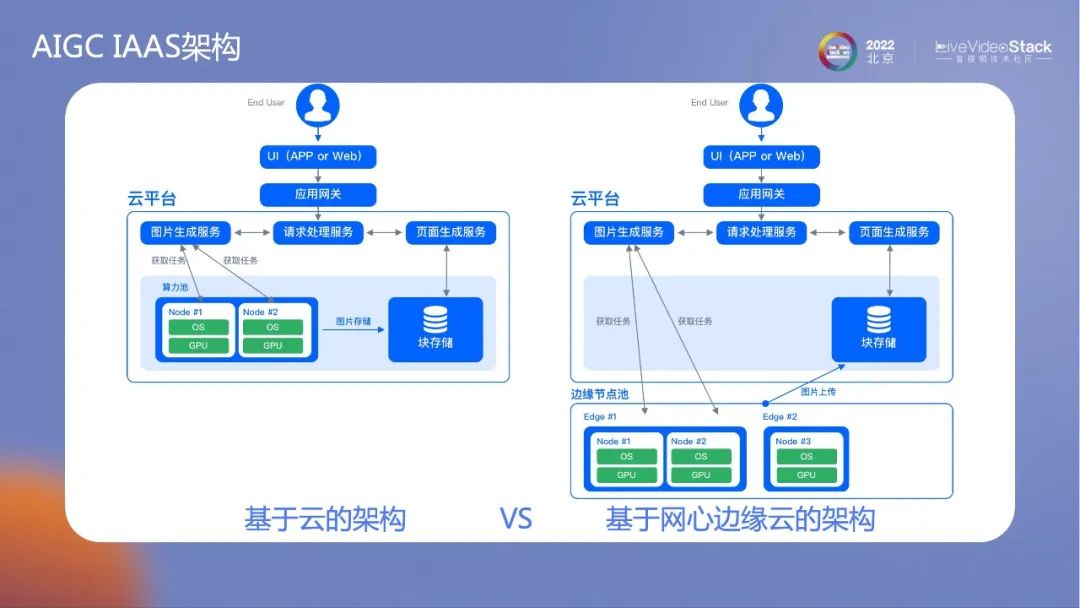
AIGC IAAS架构整体变化不大。网心已经可以构建出完善的边缘网络虚拟GPU容器。一些容器较大,需要切开,而另一些较小的则不需要切开。归根到底还是使用图片生成式的服务调动共有的边缘节点,这样做可以极大地节省成本。
为了使边缘云计算更好的应对未来的场景,网心科技提出了“三步走”发展策略:
第一步,降本增效。目前立足于能产生经济收益的场景以及客户的实际需求,利用客户扩大网络规模,提升网络水平,降低成本,提高效率,推助企业良性扩张。
第二步,功能迭代。逐渐丰富业务场景,推助云游戏、AIGC等业务的完善与推广;坚持对算力类需求的研发与覆盖;持续提升算力布局和能力。
第三步,构建生态。推动边缘网络和算力叠加,对接产业场景并实现产业场景产品化;以车联网、车路协同为切入点,适配消费类客户需求;构建开放网络平台,吸引开发者、合作伙伴共同构建生态。
我们有信心在未来8到10年里逐步实现三步走的规划。今年AGI的快速发展,很有可能会将需要的时间大幅压缩。
这是我今天的分享,谢谢大家。

LiveVideoStackCon 2023上海讲师招募中
LiveVideoStackCon是每个人的舞台,如果你在团队、公司中独当一面,在某一领域或技术拥有多年实践,并热衷于技术交流,欢迎申请成为LiveVideoStackCon的讲师。请提交演讲内容至邮箱:speaker@livevideostack.com。