HashMap:
为什么经常深入考察?
基于java写的代码会访问很多东西,比如数据库,缓存,消息中间件。
HashMap数据结构
底层是数组 原本已经有很多个位置了 原本是取模但是优化成了性能更高的hash&(n-1)
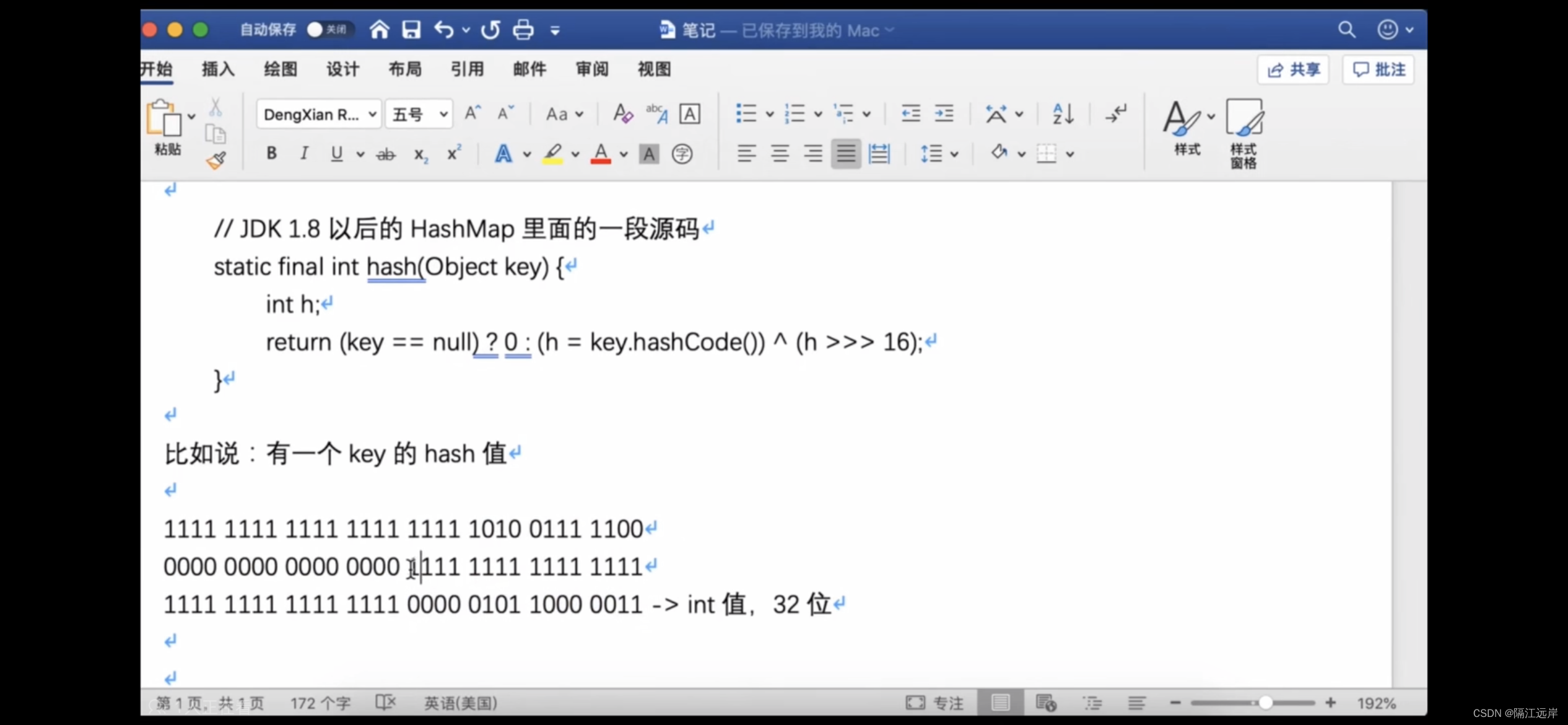
让哈希值高十六位和低十六位异或一下 融合一下特征 然后再去做寻址
寻址算法优化:hash&(n-1) 效果跟hash对n取模是一样的,但是与运算的性能比hash对n取模要高很多,数学问题 数组的长度会一直是2的n次方,只要他保持数组长度是2的n次方
核心点是低十六位的与运算
总结:对每个hash值,在他的低十六位中,让高低十六位进行了异或,让他的低十六位保持了高低十六位的特征,尽量避免一些hash值出现冲突,大家可能会进入数组的同一个位置。
寻址算法优化:用与运算代替取模,提升性能
hash冲突问题:
算出key的hash值,到数组中寻址,找到一个位置,把key-value放入数组,或者从组里取出来,
两个key,多个key与n-1做了与运算后,定位出来的数组还是有一样的可能,这就是hash碰撞
解决方式:链表+红黑树 O(n)和O(logn)
链表达到一定长度后,会转换为红黑树,遍历性能会高于链表
hashMap的扩容:
底层是数组,数组满了之后会自动扩容,变成一个更大的数组,让你在里面可以存放更多的元素
两倍扩容
比如从16扩容到32
rehash的策略
判断二进制结果中是否多出了一个bit的1,如果没多,那就是原来的index,如果多了出来,那么就是index+oldCap,通过这个方式,就避免了rehash的时候,用每个hash对新数组length取模,取模性能不高,位运算性能更高
体悟:他的意思是这样的,当长度扩容成32后,我们是不是要把之前的元素打散?那么我们把第一个元素放在1,而第二个元素放在17,第三个元素放在2,第四个元素放在18.
这样元素就更加分散了