1. 线性可分SVM
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
1.1 生成模拟数据
# 导入sklearn模拟二分类数据生成模块
from sklearn.datasets import make_blobs
# 生成模拟二分类数据集
X, y = make_blobs(n_samples=150, n_features=2, centers=2, cluster_std=1.2, random_state=40)
# 设置颜色参数
colors = {0:'r', 1:'g'}
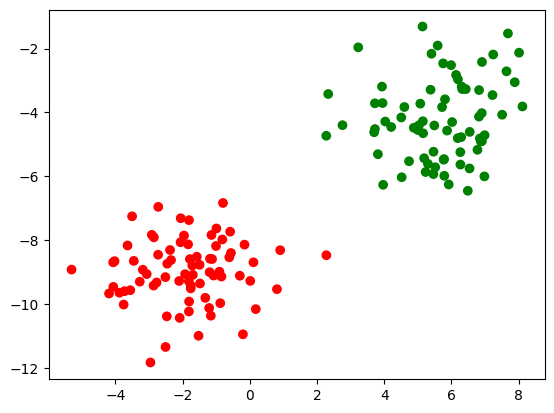
# 绘制二分类数据集的散点图
plt.scatter(X[:,0], X[:,1], marker='o', c=pd.Series(y).map(colors))
plt.show();
# 将标签转换为1/-1
y_ = y.copy()
y_[y_==0] = -1
y_ = y_.astype(float)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_, test_size=0.3, random_state=43)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(105, 2) (105,) (45, 2) (45,)
1.2 线性可分支持向量机
# 导入sklearn线性SVM分类模块
from sklearn.svm import LinearSVC
# 创建模型实例
clf = LinearSVC(random_state=0, tol=1e-5)
# 训练
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
from sklearn.metrics import accuracy_score
# 计算测试集准确率
print(accuracy_score(y_test, y_pred))
1.0
from matplotlib.colors import ListedColormap
### 绘制线性可分支持向量机决策边界图
def plot_classifer(model, X, y):
# 超参数边界
x_min = -7
x_max = 12
y_min = -12
y_max = -1
step = 0.05
# meshgrid
xx, yy = np.meshgrid(np.arange(x_min, x_max, step),
np.arange(y_min, y_max, step))
# 模型预测
z = model.predict(np.c_[xx.ravel(), yy.ravel()])
# 定义color map
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA'])
cmap_bold = ListedColormap(['#FF0000', '#003300'])
z = z.reshape(xx.shape)
plt.figure(figsize=(8, 5), dpi=96)
plt.pcolormesh(xx, yy, z, cmap=cmap_light)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold)
plt.show()
plot_classifer(clf, X_train, y_train)
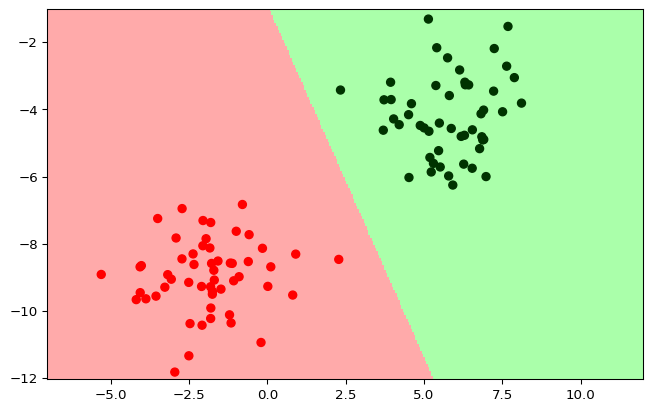
plot_classifer(clf, X_test, y_test)
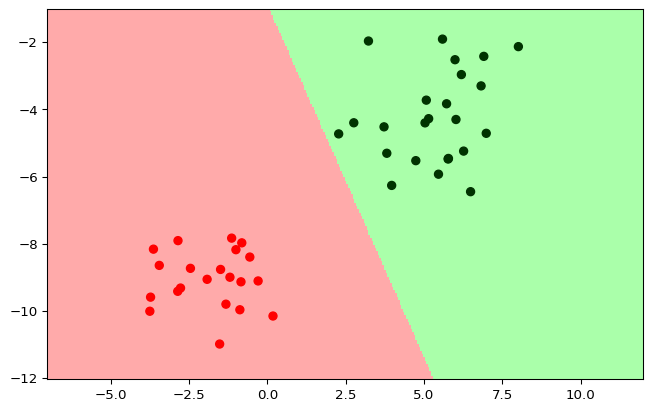
2. 广义线性可分SVM
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
2.1 生成模拟数据
mean1, mean2 = np.array([0, 2]), np.array([2, 0])
covar = np.array([[1.5, 1.0], [1.0, 1.5]])
X1 = np.random.multivariate_normal(mean1, covar, 100)
y1 = np.ones(X1.shape[0])
X2 = np.random.multivariate_normal(mean2, covar, 100)
y2 = -1 * np.ones(X2.shape[0])
X_train = np.vstack((X1[:80], X2[:80]))
y_train = np.hstack((y1[:80], y2[:80]))
X_test = np.vstack((X1[80:], X2[80:]))
y_test = np.hstack((y1[80:], y2[80:]))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
print(X_train.shape)
(160, 2) (160,) (40, 2) (40,)
(160, 2)
# 设置颜色参数
colors = {1:'r', -1:'g'}
# 绘制二分类数据集的散点图
plt.scatter(X_train[:,0], X_train[:,1], marker='o', c=pd.Series(y_train).map(colors))
plt.show();
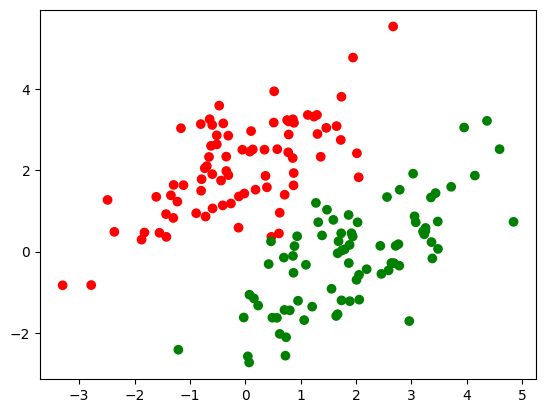
2.2 广义线性可分支持向量机
from sklearn import svm
# 创建svm模型实例
clf = svm.SVC(kernel='linear')
# 模型拟合
clf.fit(X_train, y_train)
# 模型预测
y_pred = clf.predict(X_test)
from sklearn.metrics import accuracy_score
# 计算测试集准确率
print(accuracy_score(y_test, y_pred))
# 计算测试集准确率
print('Accuracy of soft margin svm based on sklearn: ',
accuracy_score(y_test, y_pred))
1.0
Accuracy of soft margin svm based on sklearn: 1.0
2.3 结果可视化
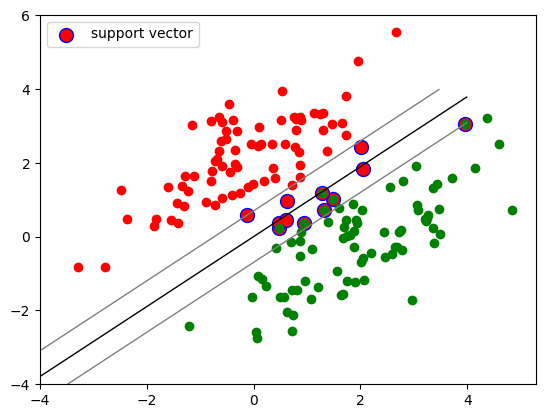
def plot_classifier(X1_train, X2_train, clf):
plt.plot(X1_train[:,0], X1_train[:,1], "ro")
plt.plot(X2_train[:,0], X2_train[:,1], "go")
plt.scatter(clf.support_vectors_[:,0], clf.support_vectors_[:,1],
s=100, c="r", edgecolors="b", label="support vector")
X1, X2 = np.meshgrid(np.linspace(-4,4,50), np.linspace(-4,4,50))
X = np.array([[x1, x2] for x1, x2 in zip(np.ravel(X1), np.ravel(X2))])
Z = clf.decision_function(X).reshape(X1.shape)
plt.contour(X1, X2, Z, [0.0], colors='k', linewidths=1, origin='lower')
plt.contour(X1, X2, Z + 1, [0.0], colors='grey', linewidths=1, origin='lower')
plt.contour(X1, X2, Z - 1, [0.0], colors='grey', linewidths=1, origin='lower')
plt.legend()
plt.show()
plot_classifier(X_train[y_train==1], X_train[y_train==-1], clf)
3. 非线性SVM
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
3.1 生成模拟数据
mean1, mean2 = np.array([-1, 2]), np.array([1, -1])
mean3, mean4 = np.array([4, -4]), np.array([-4, 4])
covar = np.array([[1.0, 0.8], [0.8, 1.0]])
X1 = np.random.multivariate_normal(mean1, covar, 50)
X1 = np.vstack((X1, np.random.multivariate_normal(mean3, covar, 50)))
y1 = np.ones(X1.shape[0])
X2 = np.random.multivariate_normal(mean2, covar, 50)
X2 = np.vstack((X2, np.random.multivariate_normal(mean4, covar, 50)))
y2 = -1 * np.ones(X2.shape[0])
X_train = np.vstack((X1[:80], X2[:80]))
y_train = np.hstack((y1[:80], y2[:80]))
X_test = np.vstack((X1[80:], X2[80:]))
y_test = np.hstack((y1[80:], y2[80:]))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(160, 2) (160,) (40, 2) (40,)
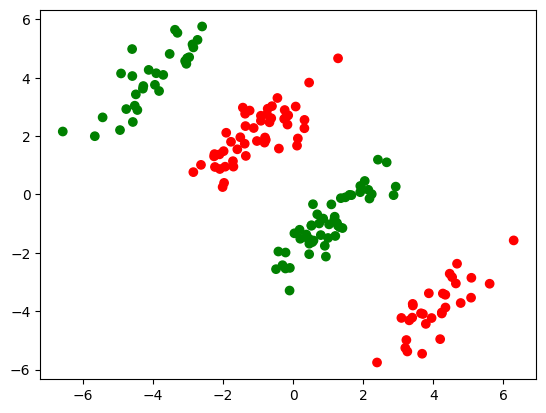
# 设置颜色参数
colors = {1:'r', -1:'g'}
# 绘制二分类数据集的散点图
plt.scatter(X_train[:,0], X_train[:,1], marker='o', c=pd.Series(y_train).map(colors))
plt.show();
3.2 非线性SVM
from sklearn import svm
# 创建svm模型实例
clf = svm.SVC(kernel='rbf')
# 模型拟合
clf.fit(X_train, y_train)
SVC()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC()
# 导入sklearn准确率评估函数
from sklearn.metrics import accuracy_score
# 模型预测
y_pred = clf.predict(X_test)
# 计算测试集准确率
print('Accuracy of soft margin svm based on cvxopt: ',
accuracy_score(y_test, y_pred))
Accuracy of soft margin svm based on cvxopt: 1.0
3.3 结果可视化
### 绘制非线性可分支持向量机
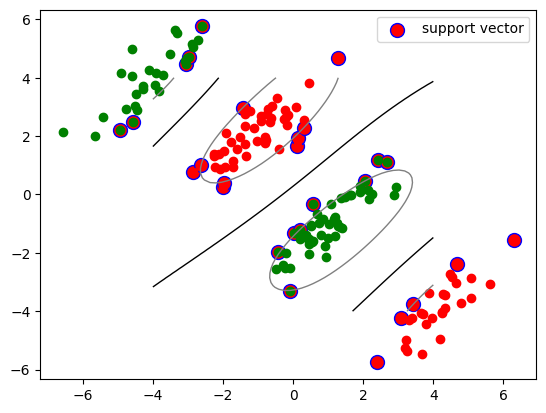
def plot_classifier(X1_train, X2_train, clf):
plt.plot(X1_train[:,0], X1_train[:,1], "ro")
plt.plot(X2_train[:,0], X2_train[:,1], "go")
plt.scatter(clf.support_vectors_[:,0], clf.support_vectors_[:,1],
s=100, c="r", edgecolors="b", label="support vector")
X1, X2 = np.meshgrid(np.linspace(-4,4,50), np.linspace(-4,4,50))
X = np.array([[x1, x2] for x1, x2 in zip(np.ravel(X1), np.ravel(X2))])
Z = clf.decision_function(X).reshape(X1.shape)
plt.contour(X1, X2, Z, [0.0], colors='k', linewidths=1, origin='lower')
plt.contour(X1, X2, Z + 1, [0.0], colors='grey', linewidths=1, origin='lower')
plt.contour(X1, X2, Z - 1, [0.0], colors='grey', linewidths=1, origin='lower')
plt.legend()
plt.show()
plot_classifier(X_train[y_train==1], X_train[y_train==-1], clf)
4. SVR
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
4.1 生成模拟数据
np.random.seed(0)
X = np.sort(np.random.uniform(0,6,50),axis=0)
y = 2*np.sin(X)+0.1*np.random.randn(50)
X = X.reshape(-1,1)
4.2 SVR建模
from sklearn import svm
svr_rbf = svm.SVR(kernel='rbf',gamma=0.4,C=100)
svr_rbf.fit(X,y)
SVR(C=100, gamma=0.4)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVR(C=100, gamma=0.4)
svr_linear = svm.SVR(kernel='linear',C=100)
svr_linear.fit(X,y)
SVR(C=100, kernel='linear')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVR(C=100, kernel='linear')
svr_poly = svm.SVR(kernel='poly',degree=3,C=100)
svr_poly.fit(X,y)
SVR(C=100, kernel='poly')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVR(C=100, kernel='poly')
4.3 生成测试数据集
X_test = np.linspace(X.min(), 1.5*X.max(), 50)
np.random.seed(0)
y_test = 2*np.sin(X_test) + 0.1*np.random.randn(50)
X_test=X_test.reshape(-1,1)
4.4 预测并可视化
y_rbf = svr_rbf.predict(X_test)
y_linear = svr_linear.predict(X_test)
y_poly = svr_poly.predict(X_test)
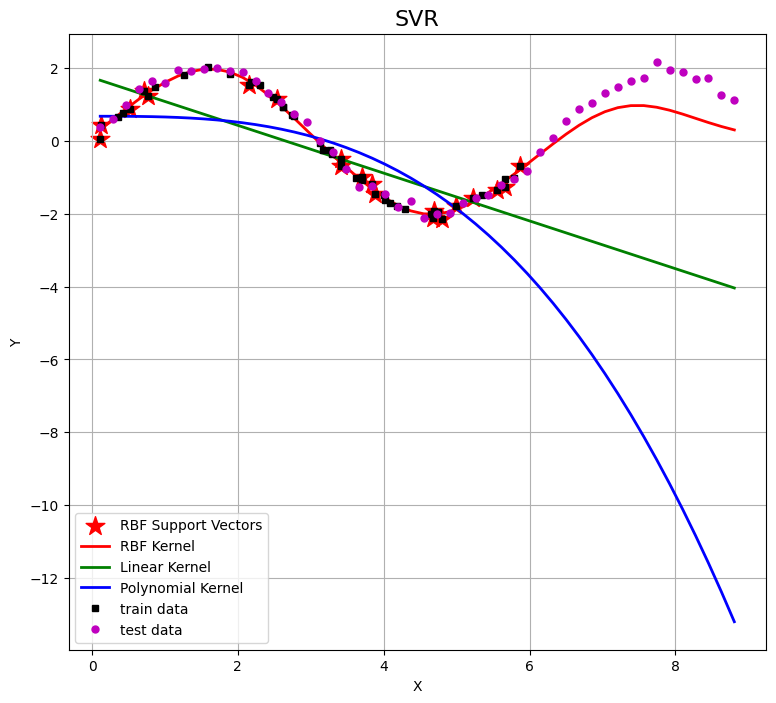
sp = svr_rbf.support_
plt.figure(figsize=(9, 8),facecolor='w')
plt.scatter(X[sp], y[sp], s=200, c='r', marker='*', label='RBF Support Vectors')
plt.plot(X_test, y_rbf, 'r-', linewidth=2, label='RBF Kernel')
plt.plot(X_test, y_linear, 'g-', linewidth=2, label='Linear Kernel')
plt.plot(X_test, y_poly, 'b-', linewidth=2, label='Polynomial Kernel')
plt.plot(X, y, 'ks', markersize=5, label='train data')
plt.plot(X_test, y_test, 'mo', markersize=5, label='test data')
plt.legend(loc='lower left')
plt.title('SVR', fontsize=16)
plt.xlabel('X')
plt.ylabel('Y')
plt.grid(True)
plt.show()






![[ 汇编语言 (一) ] —— 踩着硬件的鼓点,掌握计算机的精髓](https://img-blog.csdnimg.cn/92d3fd43ddee4119ac908369ddef192d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eL5ZCN5bGx56CB5rCR,size_20,color_FFFFFF,t_70,g_se,x_16)