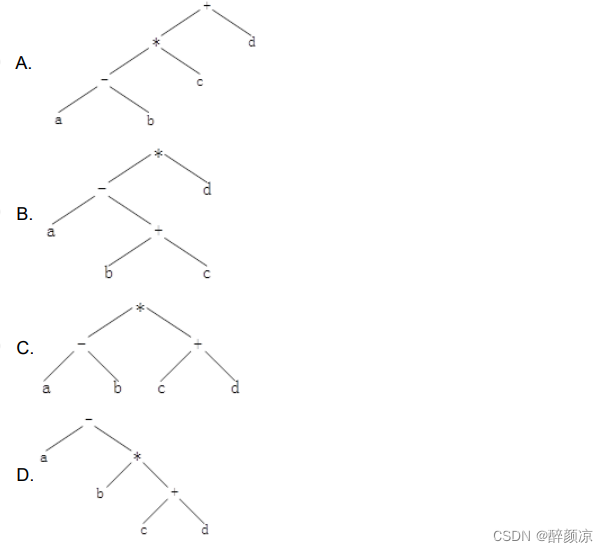
一、课程计划
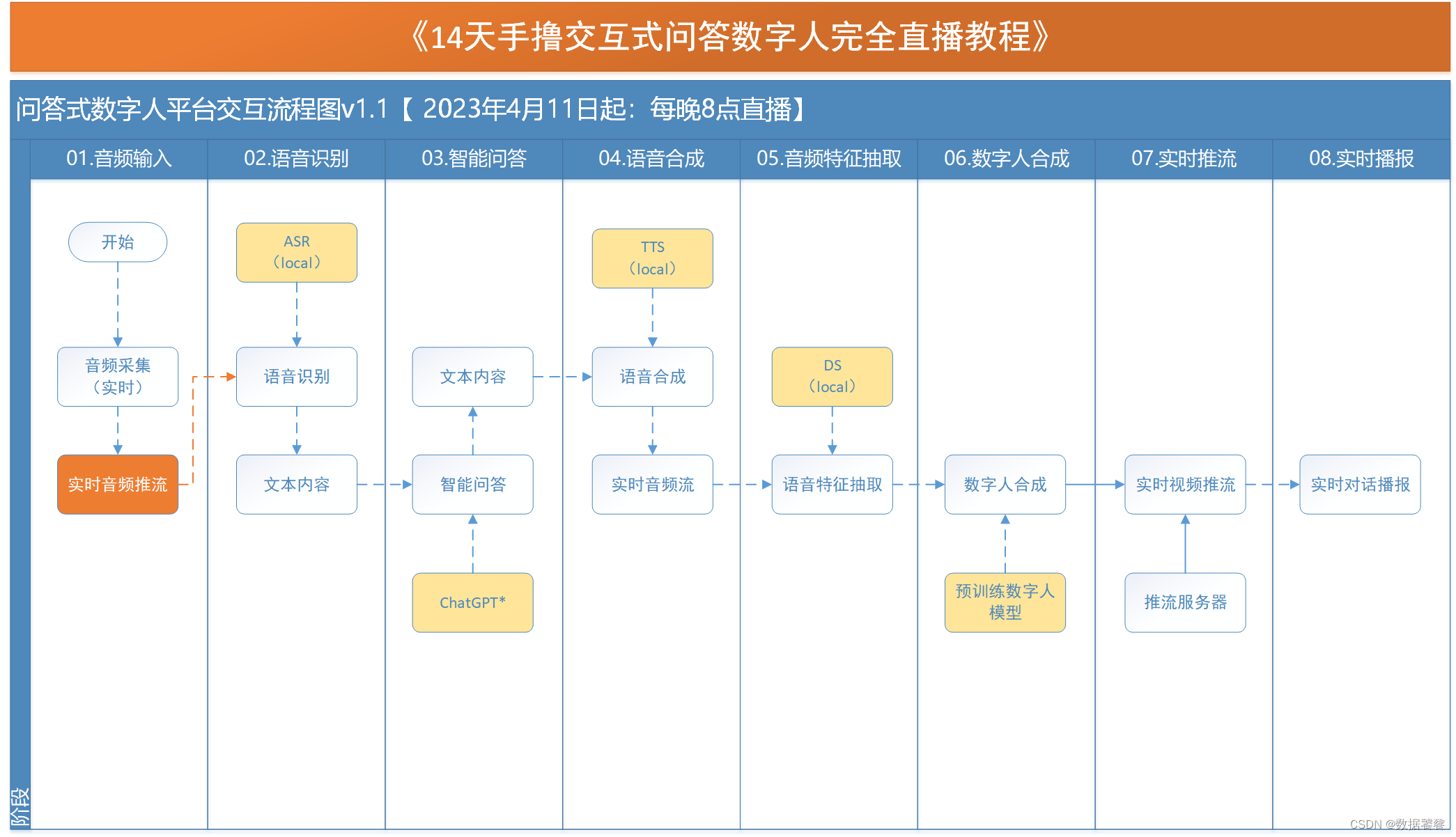
二、时间安排
第01天:交互式问答数字人发展现状
从一个真实案例开始,介绍当前主流的交互式数字人平台,需求和应用场景,引入交互式数字人的交互流程和关键技术。后续整个直播系列的内容安排。
第02天:音频采集和实时音频推流
介绍基于麦克风的音频采集系统,搭建实时音频推流系统,实现音频实时录制、播放和实时推流。
第03-04天:语音识别:本地离线部署
性能原因考虑,交互式数字人的语音识别采用本地离线部署模式。语音识别离线部署技术选型,模型资源和运行演示。
第05-06天:智能问答:本地chatGPT平替产品离线部署
性能、网络和垂类可用性三个原因考虑,交互式数字人智能问答部分采用本地离线部署模式,这部分介绍当前可用的智能问答系统,重点介绍支持增量微调的开源方案。并演示接入效果。
第07-08天:语音合成:离线部署方案
考虑到性能原因,语音合成部分采用离线部署模式,介绍当前可用的开源语音合成系统和预训练模型。重点介绍支持离线部署的开源方案,并演示部署和接入效果。
第09天:音频特征抽取
结合数字人合成输入需求,进行音频特征抽取,并保存。介绍当前主流的音频特征抽取方案,包括:deepspeech、wav2vec和hubert. 并演示音频特征抽取结果。此处有一个难点就是:如何实现流式处理。
第10-11天:数字人合成:性能极限优化策略
数字人合成方案,采用开源/自研的技术方案,重点介绍如何进行数字人合成的性能提升。在保障效果的情况,性能提升作为第一个要求。
第12天:实时推流:搭建实时推流服务器
实时视频推流服务器技术选型,实时视频推流客户端程序设计,系统联调和运行演示。
第13天:实时播报:实时播报系统设计
实时数字人播报客户端技术选型、程序设计、系统链条和运行演示。
第14天:总结和回顾:扬帆起航
问题总结和回顾,QA答疑。




![[ 汇编语言 (一) ] —— 踩着硬件的鼓点,掌握计算机的精髓](https://img-blog.csdnimg.cn/92d3fd43ddee4119ac908369ddef192d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eL5ZCN5bGx56CB5rCR,size_20,color_FFFFFF,t_70,g_se,x_16)