版权声明
- 本文原创作者:谷哥的小弟
- 作者博客地址:http://blog.csdn.net/lfdfhl
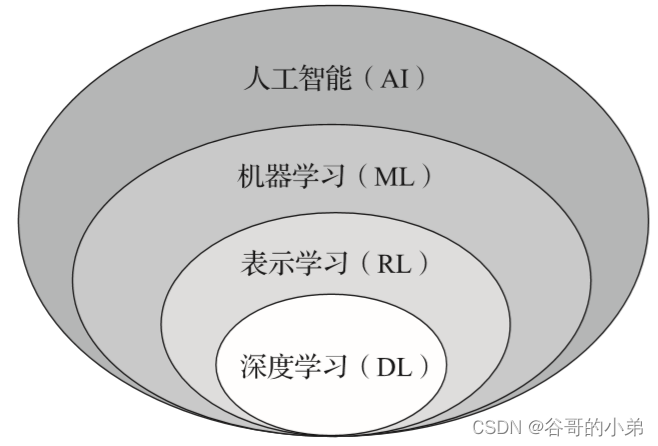
机器学习

机器学习(Machine Learning,ML)是指从数据中自动学习规律和模式,并利用这些规律和模式,在新的数据中完成类似任务的技术和方法。它属于人工智能(Artificial Intelligence)的一个分支。
机器学习的核心思想是使用数据来训练计算机算法,让其从中学习规律和模式,并通过预测、分类、聚类等方式对未知的数据进行处理。它的主要任务包括监督学习、无监督学习、半监督学习和强化学习等。
监督学习是指通过给定的训练数据集,学习一个从输入到输出的映射关系,让计算机能够对新的输入数据进行分类或预测。无监督学习则是在没有标签(即输出结果)的情况下,让计算机对数据进行聚类或降维等操作。而半监督学习则是介于监督学习和无监督学习之间的一种技术,同时使用带有标签和不带标签的数据进行学习。强化学习是指让计算机通过与环境的交互,学习如何最大化某种型号的累积奖励。
机器学习涉及的算法种类繁多,其中包括深度学习、支持向量机、朴素贝叶斯、决策树、随机森林等。这些算法在不同的数据集和任务上表现出了不同的优劣势,其选择需要考虑具体情况。
概括而言,机器学习是一种能够利用数据自动完成任务的技术和方法,其应用广泛,如人脸识别、语音识别、自然语言处理、推荐系统等。随着数据不断增加和硬件算力的提升,机器学习的发展前景也越来越广阔。
大语言模型
大语言模型(Large Language Model,LLM)是一种基于深度学习技术的自然语言处理模型,可以通过大量的未标记文本数据进行自我监督训练,从而获得对语言的深刻理解和表达能力。与传统的人工设计的特征模型不同,LLM使用神经网络模型在短时间内完成了对海量语料库的学习,并获得了更加丰富、准确的语言知识。
目前,LLM的发展主要集中在两个方面:预训练和微调。预训练是指将大量无标签的文本数据用于训练LLM,在此过程中,LLM会尝试从数据中提取出一些通用的语言知识,例如句子结构、语法规则和常见词汇等,以及针对具体任务所需要的特定知识。而微调则是指在具体的应用场景中,使用有标签的数据对LLM进行进一步的调整和训练,以使其更加适合某个特定的应用场景。
近年来,由于大量的新算法和硬件支持的到位,LLM在自然语言处理领域中取得了许多重大突破,如Google的BERT模型和OpenAI的GPT-3模型等。这些模型不仅在各种任务上都取得了极好的表现,而且也为语言理解、生成和对话等领域开辟了更加广阔的应用前景。
大语言模型应用

目前,主流的大语言模型包括:
-
GPT-4:由OpenAI公司开发,是目前最大的语言模型,它拥有2350亿个参数,能够生成高质量的自然语言文本。
-
BERT:由Google公司开发,是一种基于双向编码器的预训练语言模型,其参数量达到了3亿。
-
XLNet:由CMU和谷歌公司共同研发,是一种使用全局自回归和自注意力机制的预训练语言模型。
-
T5:由Google研发,它采用了“Text-to-Text Transfer Transformer”(T5)框架,可以在多个自然语言处理任务上进行迁移学习。
-
RoBERTa:由Facebook AI Research(FAIR)研发,是对BERT模型的改进和优化,可用于多项自然语言处理任务。
以上这些大语言模型都是通过预先训练来学习语言知识并能够生成高质量的自然语言文本,已经被广泛应用于自然语言处理、语音识别、机器翻译等领域。




![[ 应急响应篇基础 ] 日志分析工具Log Parser配合login工具使用详解(附安装教程)](https://img-blog.csdnimg.cn/6732169e2881495e8199b16c7e16864f.png)