这篇文章,主要介绍Redis运行环境之Cluster集群模式。
目录
一、Cluster集群模式
1.1、集群模式原理
(1)普通集群
(2)什么是分片???
(3)如何分片存储???
1.2、集群环境搭建
(1)基础环境
(2)创建配置文件
(3)启动集群结点实例
(4)关联集群结点
(5)测试集群
一、Cluster集群模式
前面几篇文章介绍了Redis如何搭建主从模式、Sentinel哨兵模式,主从模式解决了Redis的读写能力,采用读写分离的策略提高了redis服务的性能,但是它不能解决高可用性;Sentinel哨兵模式解决了主从模式中的高可用性问题;但是,这两种方式都不能解决数据的冗余问题,而redis集群模式则既可以实现高可用性,又可以解决数据的冗余问题。
1.1、集群模式原理
(1)普通集群
最简单的集群模式,就是将所有的redis结点互相连接起来,这样即使其中任意一个结点发生故障,也不会导致整个服务不可用,大致结构如下所示:
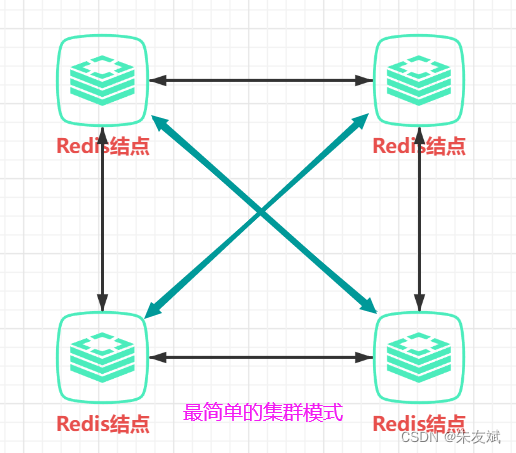
这种模式虽然可以解决高可用性,但是这种模式会导致数据的冗余,什么意思呢???也就是说,客户端保存数据到任意一台redis结点,其他的redis结点都将进行数据的同步,这样整个redis集群中每一台都将保存着相同的一份数据,n个结点就会保存n份数据。
redis中的集群不是采用这种模式,而是采用的了分片集群的思想。
(2)什么是分片???
分片是指:将数据拆分成n份,然后将每一份数据分散的保存到每一台redis结点服务中,这样就可以大大提高redis结点保存更多的数据信息,并且也不会存在冗余的数据。
- 举个例子:
- 假设现在有三条数据,A,B,C;集群中存在三个结点AA、BB、CC;分片是指将A数据存储在AA结点,数据B存储在BB结点上面,C数据存储在CC结点上,这就是数据分片存储的思想。
(3)如何分片存储???
既然要将数据分片存储到不同的redis结点里面,那就需要有一个规则,这个规则要知道如何将某一条数据保存到哪一个redis结点里面。Redis中采用的是【哈希插槽】的思想,它是将整个redis集群分为16384个插槽,然后根据集群中redis结点的数量,将这些插槽平均的分配给每一个结点。
假设,现在有三个结点:A、B、C,总共 16384 个插槽,所以平均分配如下所示:
- A 结点将管理:0 - 5500 号插槽。
- B 结点将管理:5501 - 11000 号插槽。
- C 结点将管理:11001 - 16384 号插槽。
这里只是将每一个redis结点管理哪些插槽指定好了,但是还不知道怎么把redis数据映射到哪个插槽上面。Redis是采用的CRC16算法,对key进行哈希操作,计算出对应的插槽位置,然后从本地维护的集群信息中找出这个插槽对应哪一台redis结点,将数据保存到这一台结点当中。
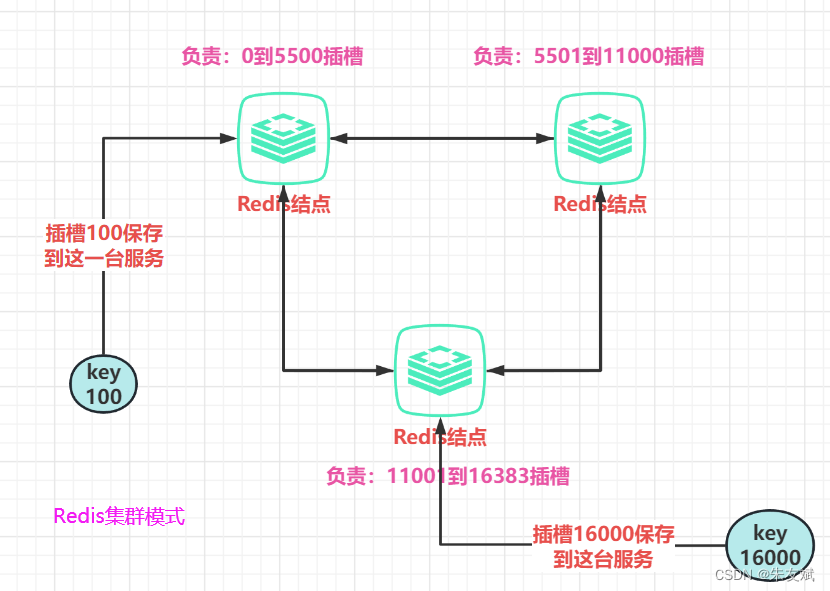
以上,就是redis集群模式大致的原理。
1.2、集群环境搭建
这里基于windows操作系统搭建一个redis集群模式,由于真正的集群模式都是部署在多台服务器上面,但是我这里只有一台电脑,所以就采用不同的端口来区分不同的redis结点。
(1)基础环境
这里就创建6台redis服务结点,端口和IP分别如下所示:
| 配置文件名称 | IP地址 | 端口 |
|---|---|---|
| master-cluster16379 | 127.0.0.1 | 16379 |
| master-cluster16380 | 127.0.0.1 | 16380 |
| master-cluster16381 | 127.0.0.1 | 16381 |
| slave-cluster36379 | 127.0.0.1 | 36379 |
| slave-cluster36380 | 127.0.0.1 | 36380 |
| slave-cluster36381 | 127.0.0.1 | 36381 |
(2)创建配置文件
创建上面6个集群结点的配置文件,内容如下所示:
# 启动端口
port 16379
# 开启后台启动模式,在linux下生效,windows下不生效
# daemonize yes
# 将当前redis实例作为集群结点启动
cluster-enabled yes
# 集群结点配置文件,每一个集群结点都必须有一个不同的配置文件名称
# 这个文件是redis主动生成的,不需要我们手动配置内容
cluster-config-file nodes-16379.conf
# 集群结点超时时间,单位是:毫秒(ms)
cluster-node-timeout 15000- 注意:6个集群结点的配置文件中,除了port端口号、集群结点cluster-config-file配置文件两个不同之外,其余的都相同。
需要注意的是,在启动redis实例之前,先把redis目录中的dump.rdb文件删掉,这样可以避免之前数据的干扰 (我搭建时候,因为没有删除dump.rdb文件,集群搭建失败了,删掉重新启动,发现成功了)。
(3)启动集群结点实例
配置文件创建好了之后,就可以启动每一台redis集群结点啦,打开CMD命令行窗口,依次执行下面命令即可启动服务。
redis-server.exe master-cluster16379.conf
redis-server.exe master-cluster16380.conf
redis-server.exe master-cluster16381.conf
redis-server.exe slave-cluster36379.conf
redis-server.exe slave-cluster36380.conf
redis-server.exe slave-cluster36381.conf为了方便,我这里写了一个bat批处理命令,一起执行上面6个命令,命令如下所示:
@echo off
start cmd /k "redis-server.exe master-cluster16379.conf"
start cmd /k "redis-server.exe master-cluster16380.conf"
start cmd /k "redis-server.exe master-cluster16381.conf"
start cmd /k "redis-server.exe slave-cluster36379.conf"
start cmd /k "redis-server.exe slave-cluster36380.conf"
start cmd /k "redis-server.exe slave-cluster36381.conf"
pause将上面的bat批处理代码保存到一个【.bat】结尾的文件,然后双击这个文件即可启动redis结点。
(4)关联集群结点
前面几个步骤已经启动好了redis集群结点,但是还没有关联起来,需要执行下面的命令。
redis-cli.exe --cluster create 127.0.0.1:16379 127.0.0.1:16380 127.0.0.1:16381 127.0.0.1:36379 127.0.0.1:36380 127.0.0.1:36381 --cluster-replicas 1上面参数:--cluster-replicas 表示集群结点的从结点数量。 redis会根据你执行的命令中,哪些IP和端口的顺序,依次选择master结点,其余的结点就依次作为master结点的slave从结点。
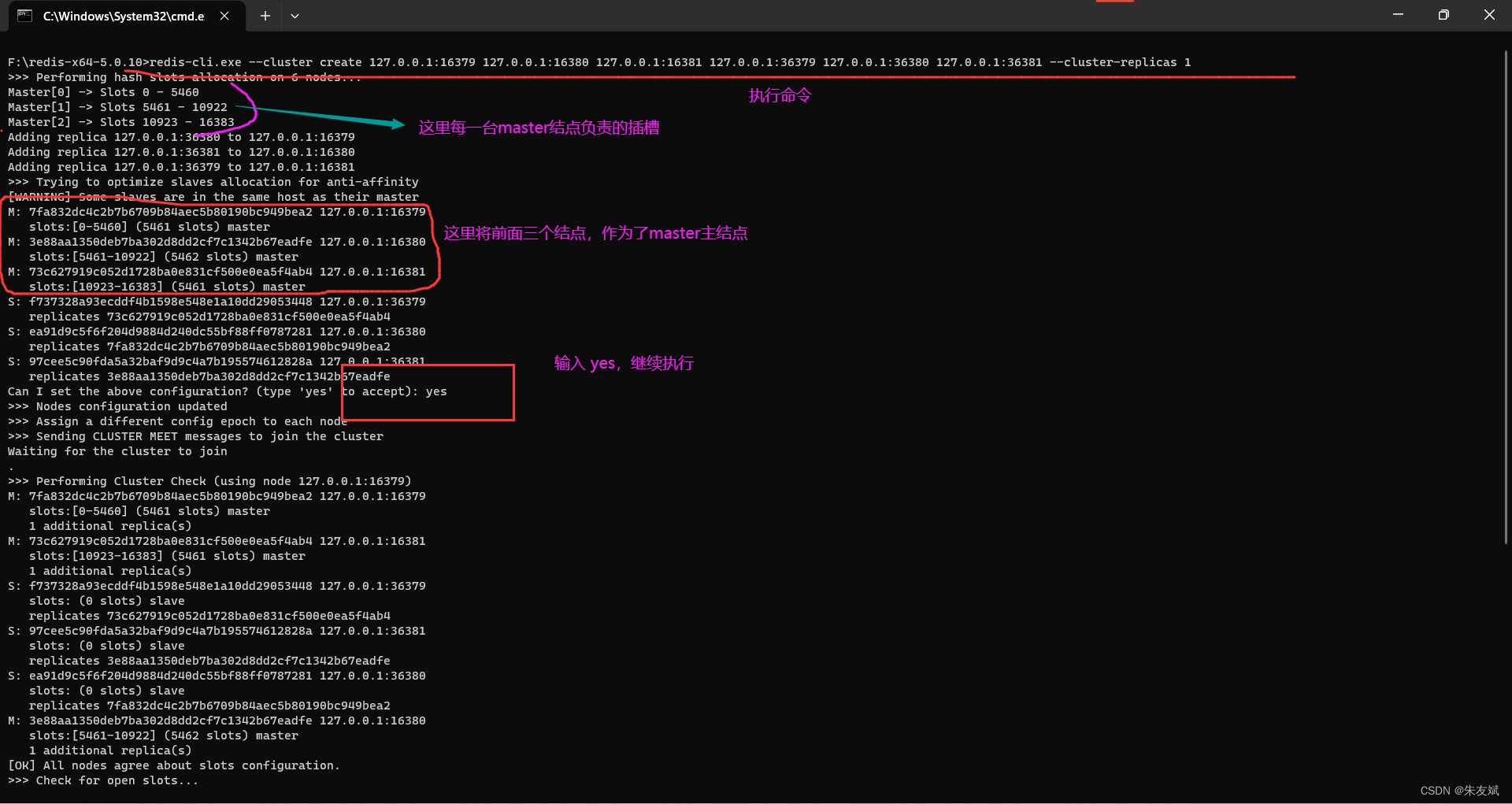
- 注意:执行上面关联集群结点的命令,redis会按照设置的slave从节点数量,计算主节点有多少个,然后从第一个IP地址开始将对应的【n】个结点作为master结点。

(5)测试集群
三种集群结点,随便连接哪一个都可以,为了测试集群是否搭建成功,我们可以连接一个结点,保存一些数据。 然后连接另一个结点,查询刚刚保存的数据,看是否能够查询出数据,如果能够查出,则表示集群搭建成功。
redis-cli.exe -c -p 127.0.0.1 -p 16379- 注意:客户端连接集群结点的时候,需要加上【-c】属性,c是cluster集群的缩写,这个属性表示采用集群的方式连接结点。
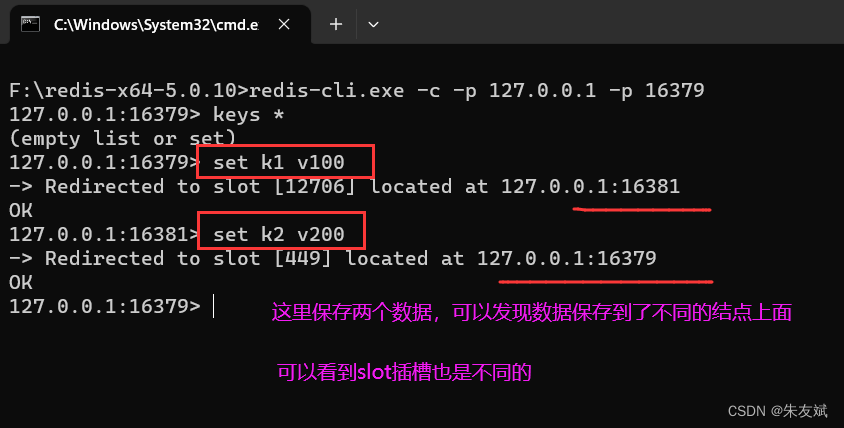
到此,Redis中的集群模式就介绍完啦。
综上,这篇文章结束了,主要介绍Redis运行环境之Cluster集群模式【配置文件下载】。



![[ 应急响应篇基础 ] 日志分析工具Log Parser配合login工具使用详解(附安装教程)](https://img-blog.csdnimg.cn/6732169e2881495e8199b16c7e16864f.png)