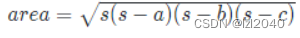声明
主页:元存储的博客_CSDN博客
依公开知识及经验整理,如有误请留言。
个人辛苦整理,付费内容,禁止转载。
内容摘要
2.2 ZNS 的架构实现
先看看 支持zone 存储的 SMR HDD 以及 支持 zonefs 的 nvme ssd 的整个存储栈形态
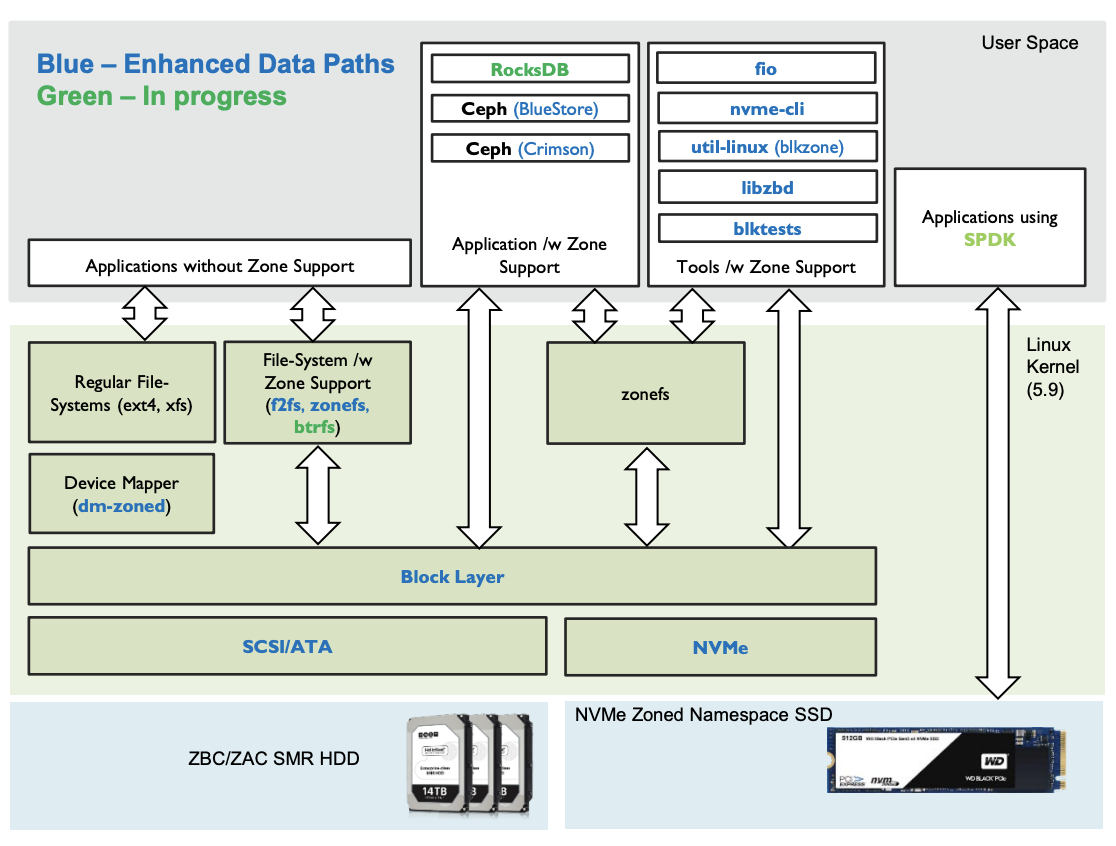
其中对于ceph 这样的应用来说 bluestore或者Seastore 这样的后端引擎是直接管理裸设备的,所以不需要文件系统支持。当然如果需要,也可以通过一个内核支持的小型文件系统zonefs 来进行数据访问。
但是这个小型文件系统过去简单,它将每一个zone空间暴露为一个文件,使用LBA0 来存储superblock,并没有复杂的inode/dentry 这种元数据的管理机制,在这个文件系统上创建/删除/重命名都是不允许的。针对数据的写还是类似zone storage的要求,即通过一个WP来进行写,如果这个zone 空间对应的文件被写满了,则WP 无法写入直到 对这个zone 执行了reset ,才会将WP 重新移动到LBA0,从而可写。
它对于Rocksdb 来说功能还不足,而且Rocksdb 只需要一个文件 用户态的 backend,虽然如是说,但是如何在rocksdb调度写的时候分配一个最优的zone,如何选择合适的时机删除sst文件(重置zone空间)都需要精心的设计在里面。
后来,Hans 主导设计了 Zenfs 来作为Rocksdb 的Backend 来进行端到端的请求调度,且选择最优的数据存储方式 并且在降低写放大(LSM-tree)、SSD 的磨损均衡、降低读长尾 等都做了较多的探索。
大体架构如下:
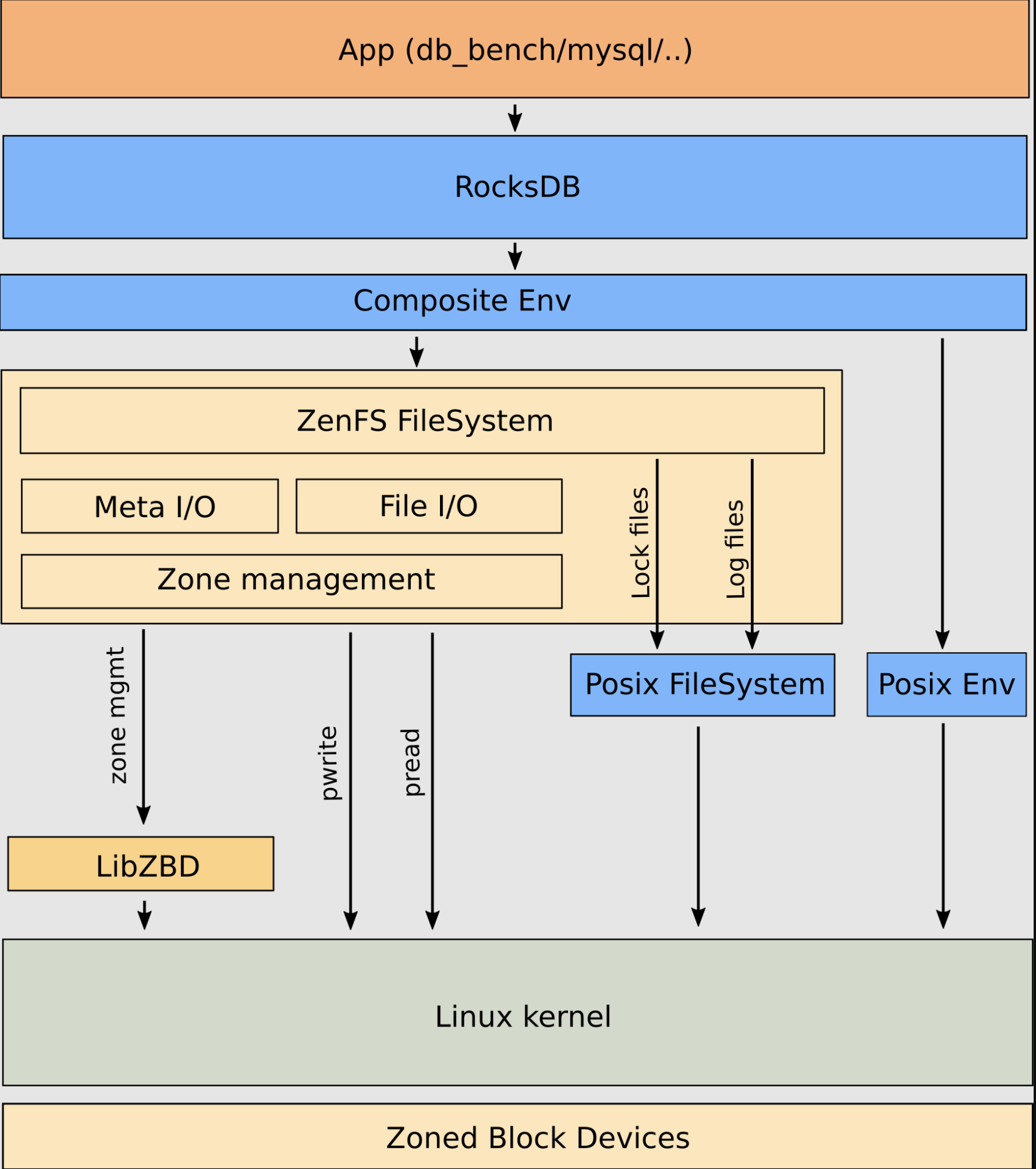
接下来我们仔细看看 ZNS 内部的一些实现的特性 以及 Zenfs 的详细设计实现。
2.2.1 ZNS 实现过程中的一些PR
ZNS的特性 需要内核支持,所以开发了ZBD(zoned block device) 内核子系统 来提供通用的块层访问接口。除了支持内核通过ZBD 访问ZNS之外,还提供了用户API ioctl进行一些基础数据的访问,包括:当前环境 zone 设备的枚举,展示已有的zone的信息 ,管理某一个具体的zone(比如reset)。
在 FIO 内部支持了 对 ZBD的压测。
在近期,为了更友好得评估ZNS-ssd的性能,在ZBD 上支持了暴露 per zone capacity 和 active zones limit。
Zenfs 的设计 并 作为 rocksdb 的一个文件系统backend。
这里是对应修改代码行数的概览:
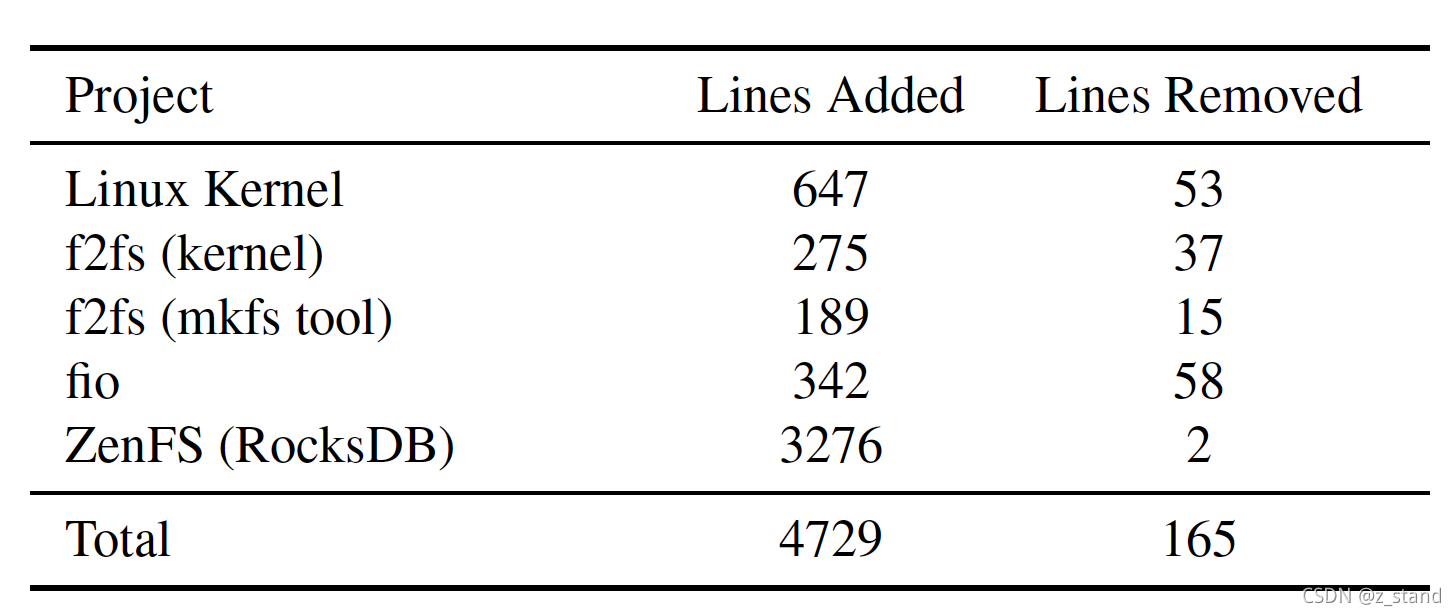
从代码行数上来看,可以说是非常得轻量了。
2.2.2 Zenfs 的设计实现
2.2.2.1 为什么zenfs如此看重rocksdb(LSM-tree 架构)
之所以ZNS 社区对Rocksdb 这么看重,代码行数上的贡献上可以说 在Rocksdb 上投入的精力远超其他方面。
从LSM-tree原理上,我们可以看到几点:
LSM-tree 的写入是append 顺序写,这适配 ZNS 的 zone 架构来说简直再合适不过。
LSM-tree 的compaction 也是顺序写一批数据,然后再集中删除,这也符合 ZNS 的空间回收方式(每一个zone 状态是Full的时候,想要重新写,只有reset了)。在好的配置下相当于 SSD内部的GC 和 rocksdb的compaction 完美结合了。
LSM-tree on 传统 ssd 的痛点比较明显。读方面:LSM-tree分层软件架构对读性能不友好(长尾较为严重),再加上ssd 的FTL GC会间接 让长尾不可预估;引以为傲的顺序写优势也因为SSD 内部的FTL 频繁GC 导致写性能抖动且相比于空载时的下降。这一些痛点在ZNS 下都能够被很好的避免甚至完全解决。
抛开 LSM-tree 本身on ssd 的劣势 之外,Rocksdb 则有一些自身特有的优势,值得 ZNS 社区持续投入:
k/v 存储领域里应用广泛,适合用于高速存储介质(NVMe-ssd)
开源 且 拥有活跃的社区,社区也在持续跟进新的存储技术。包括:io_uring / spdk 等
可插拔的存储后端设计,实现一个fs backend,移植就非常容易(将zenfs 编译到rocksdb 代码中就可以看出来)。
2.2.2.2 zenfs 详细设计
先看一下总体Zenfs的系统架构概览,这个图是论文中的图,更简洁一些:
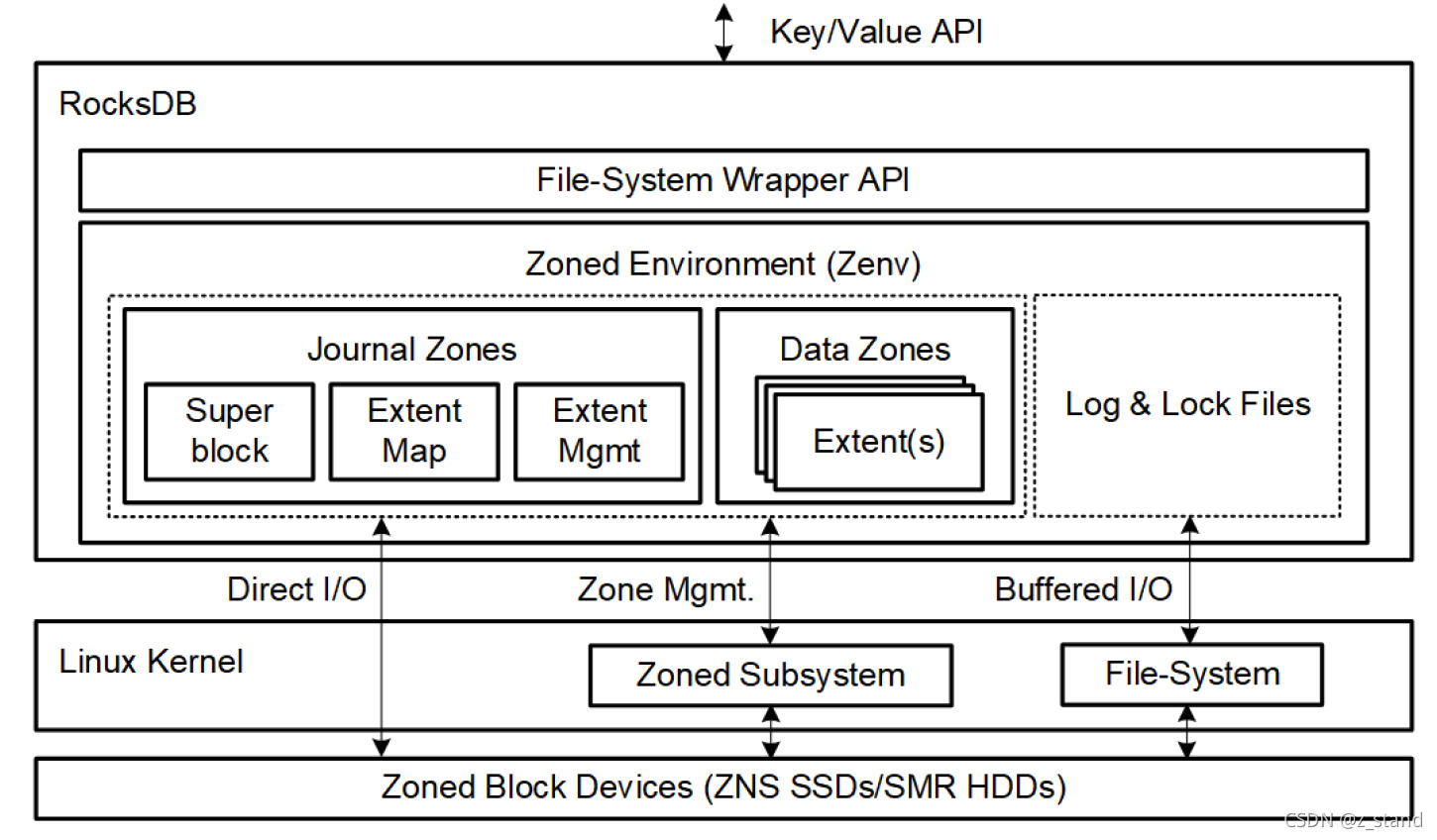
因为它要作为Rocksdb 的fs backend,负责和zoned block devcei 进行交互,那其继承自FileSystemWrapper类的基本接口肯定是都实现了。
主要的组件如下几个:
Journaling and Data.
Zenfs 定义了两种类型的zones: journal 和 data. 代码中ZonedBlockDevice 类管理的也就是两个vector , meta_zones和io_zones,下文统一称为Journal Zones 和 Data Zones。
其中 Journal Zones 用来管理文件系统的元数据,包括异常时恢复文件系统的一致性状态,维护文件系统的superblock 以及 映射 wal 和 数据文件到 zone中。
Data zones 则主要用于保存 sst 这样的数据文件。
Extents.
Rocksdb 的数据文件会被映射 写入到一个extents 集合中 std::vector<ZoneExtent*> extents_。其中一个extent 时一个变长但block对齐的连续LBA地址,而且会拿着一个标识当前sst的信息 顺序写入到一段zone空间中,会用ZoneFile这个数据结构标识文件以及属于这个文件的extents 数组。每一个 zone空间能够存储多个extents,但是一个extent 不会跨越多个zone而存在。
Extent 的分配和释放都是一个内存数据结构来管理的,当一个文件变比或者这个extent的数据要持久化到磁盘 调用Fsync/Append时,内存的数据结构也会对应持久化到journal_zone之中。而且内存中这个数据结构会持续跟踪extents的分配情况,当一个zone内的所有extents 所属的文件都被删除,这个zone就可以被reset了,方便后续的 reuse。
Superblock.
Superblock 主要用来初始化Zenfs 或者 从磁盘异常恢复Zenfs 的状态。Superblock 会通过unique id, 魔数和用户选项 来标识属于当前磁盘的Zenfs。这个唯一标识 是 UUID(unique identifier),允许用户识别对应磁盘上的文件系统,即当磁盘的盘符重启或者外部插拔发生变化的时候仍然能够识别到这上面的文件系统。
Journal.
Journal的主要工作是维护 superblock 和 WAL 以及 sst 和 存储于zone中的extents的映射。
Journal的数据主要存储在上图中的 Journal Zones中,也就是 代码中的 meat_zones,而且journal zone 是位于整个存储设备上的前三个永远不会offline的 zone ZENFS_META_ZONES。其中任何时刻,总会有一个zone是处于active的, 也就是必须可写的,不然这两个zone 被closed 的话就无法跟踪元数据了的更新了。
其中最开始的那个active zone 会有一个header,包含:sequence number(每当有一个journal zone被初始化的时候都会自增),superblock 数据结构,当前journal 状态的一个snapshot。初始化的时候,header被持久化完成,整个zone剩下的capacity就可以开始接受新的data 数据更新了。
我们从一个 ZNS 磁盘初始化一个Zenfs的过程需要执行:
.plugin/zenfs/util/zenfs mkfs --zbd=$DEV --aux_path=/tmp/$AUXPATH --finish_threshold=10 --force
注意:在 $DEV 的设备名称只能是 nvme0n1 或者 nvme1n这种,不能加 /dev/nvme0n1,zenfs 会自己去环境中找 nvme0n1,不需要用户指定路径。
1 Zenfs::MkFS 所有的meta zone都会reset,并且在第一个meta zone上创建一个zenfs文件系统,执行如下内容
写一个superblock 的数据结构,包括sequence 的初始化 并持久化
初始化一个空的snapshot,并持久化。
2 Zenfs::Mount 从磁盘 Recovery 一个已经存在的zenfs 的几个步骤如下:
现在是三个journal zones,最开始的时候需要先读取三个 journal zones 的第一个LBA内容,从而确定每一个zone 的sequence,其中seq 最大的是当前的active zone(拥有最全的元数据新的zone)。
读取active zone的header 内容,并且初始化 superblock 和 jourace state。
对 journal 的更新都会同步到到 header 的snapshot 中。
这两步操作基本就构建好了一个完整的Zenfs 状态,后续就会持续接受用户的写入。
写入过程中 sst 的数据存储是通过 保存着extent 并由extent持久化到对应的zone空间中,那 如何选择一个Data zone 来作为存储当前文件数据的呢? 因为不同的zone 在实际接受数据存储时其 capacity 的容量是变化的。如果一个sst 文件的存储是跨zone的,那最后对一个zone的 reset 还需要考虑这个文件 是否被删除。
Best-Effort Alogthrim for Zone Selection
Zenfs 这里开发了 Best-effort 算法来选择zone 作为 rocksdb sst 文件的存储。Rocksdb 通过对 WAL 和 不同 level 的 sst 设置不同的 write_hint 来表示这一些文件的生命周期。
选择哪一种 write_hint, 则通过如下逻辑进行:
Env::WriteLifeTimeHint ColumnFamilyData::CalculateSSTWriteHint(int level) {
if (initial_cf_options_.compaction_style != kCompactionStyleLevel) {
return Env::WLTH_NOT_SET;
}
if (level == 0) {
return Env::WLTH_MEDIUM;
}
int base_level = current_->storage_info()->base_level();
// L1: medium, L2: long, ...
if (level - base_level >= 2) {
return Env::WLTH_EXTREME;
} else if (level < base_level) {
// There is no restriction which prevents level passed in to be smaller
// than base_level.
return Env::WLTH_MEDIUM;
}
return static_cast<Env::WriteLifeTimeHint>(level - base_level +
static_cast<int>(Env::WLTH_MEDIUM));
}
也就是从当前总层数开始,倒数两层的sst 文件拥有最长的生命周期,level0 拥有 WITH_MEDIUM 的生命周期,WAL 则拥有最短的生命周期WITH_SHORT。
回到Zenfs 选择zone 的过程,总的来说就是让 life_time 小的文件尽量存放在和它 life_time接近的zone中,这样更大概率得统一对整个zone 进行 reset :
(1) 对于新的写入,直接分配一个新的zone
(2) 优先从 active zones 中进行分配,如果能够找到合适的zone,则直接Reset 这个zone,并作为当前文件的存储。合适的zone 的条件是:如果当前文件的lifetime 比 active zone 中最老的数据 还小,则当前zone 比较合适作为当前文件的存储;如果有多个active zone满足这个条件,则选择一个最近比较的active zone。
(3) 如果从active zone中没有找到合适的zone,那直接分配一个新的zone。当然,分配的过程也就意味着判断active zone个数有没有超过 max_nr_active_io_zones_ ,超过了则需要关闭一个 active zone,然后才能分配一个新的zone。
逻辑如下:
Zone *ZonedBlockDevice::AllocateZone(Env::WriteLifeTimeHint file_lifetime) {
...
// best effort 算法的逻辑
for (const auto z : io_zones) {
if ((!z->open_for_write_) && (z->used_capacity_ > 0) && !z->IsFull()) {
// 主要就是拿着当前 zone 的lifetime 和当前文件的file_lifetime (也就是write_hint)进行对比
// 如果文件的life_time小,则当前zone 满足存储需求。
unsigned int diff = GetLifeTimeDiff(z->lifetime_, file_lifetime);
if (diff <= best_diff) {
allocated_zone = z;
best_diff = diff;
}
}
}
...
// 如果从没有为当前文件找到找到合适的zone,那就得分配一个新的了
if (best_diff >= LIFETIME_DIFF_NOT_GOOD) {
/* If we at the active io zone limit, finish an open zone(if available) with
* least capacity left */
if (active_io_zones_.load() == max_nr_active_io_zones_ &&
finish_victim != nullptr) {
s = finish_victim->Finish();
if (!s.ok()) {
Debug(logger_, "Failed finishing zone");
}
active_io_zones_--;
}
if (active_io_zones_.load() < max_nr_active_io_zones_) {
for (const auto z : io_zones) {
if ((!z->open_for_write_) && z->IsEmpty()) {
z->lifetime_ = file_lifetime;
allocated_zone = z;
active_io_zones_++;
new_zone = 1;
break;
}
}
}
}
...
}
AllocateZone 完成之后就可以 更新当前文件在 分配的zone 中的extent(主要存放偏移地址和length),通过IOStatus Zone::Append 进行文件数据的实际写入了。
总的来说,Zenfs 通过 Best-effort 算法,根据 Rocksdb 配置的write_hint_存储 data文件和zone 接近的生命周期 来加速过期zone的回收,极大得减少了 ZNS 的空间放大问题,根据论文中的数据,说能够保持空间放大在10% 左右(可以说是整个LSM-tree + SSD 的空间放大,数据没问题的话已经很了不起了)。
当然,想要有这样的测试数据,需要对rocksdb 的参数配置进行调整,可以通过执行 Zenfs下的一个脚本来达到这个目的: ./zenfs/tests/get_good_db_bench_params_for_zenfs.sh nvme2n1 可以获取到官方推荐的一个配置,建议让 target_file_size 和 zone 配置的大小对齐。
Zenfs 也有active_zone_limits 的限制,即我们在AllocateZone 函数中可以看到,分配一个新的zone 的话如果当前active zone 的个数达到了max_nr_active_io_zones_ ,需要先关闭之前的一个zone才行,也就是在 Rocksdb 中也会有 active zone个数的限制。当然这方面 Zenfs 也做了对应的测试,发现 active zone 的个数小于6的话 会对写性能有影响, 但是达到12的话后面再增加对写性能没有太大的影响。
————————————————
版权声明:本文为CSDN博主「z_stand」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Z_Stand/article/details/120933188
参考

免责声明:
本文根据公开信息整理,旨在介绍更多的存储知识,所载文章仅为作者观点,不构成投资或商用建议。本文仅用于学习交流, 不允许商用。若有疑问或有侵权行为请联系作者处理。