文章目录
- 一、数据集
- 1.1 下载数据集
- 1.2 字段含义说明
- 1.3 导入数据集
- 二、初步分析
- 2.1 缺失值分布查看
- 2.2 异常值分布查看
- 2.3 查看变量分布
- 三、数值变量分析
- 3.1 `replot()`:多个变量之间的关联关系
- 3.2 `lmplot()/regplot`:分析两个变量的线性关系
- 3.3 `displot()`:两个变量的联合分布
- 3.4 `jointplot()`:绘制两个变量的联合分布和各自分布
- 3.5 `pairplot()`:成对绘制所有数值变量的联合分布
- 3.6 `corr()`与`heatmap()`
- 四、类别型变量分析
- 4.1 `countplot()函数`与`histplot()函数`
- 4.2 类别变量与数值变量的关系
- 4.2.1 不同类别中数值变量的均值/中值估计
- 4.2.2 不同类别中数值变量的取值范围
- 4.2.3 不同类别中数值变量的分布图
当处理一个数据集的时候,我们经常会想要先看看特征变量是如何分布的。这会让我们对数据特征有个很好的初始认识,同时也会影响后续数据分析以及特征工程的方法
一、数据集
1.1 下载数据集
使用经典的泰坦尼克号数据集
1.2 字段含义说明
PassengerId:用户id
Survival:是否生还,0-否,1-是
Pclass:舱位,1-头等舱,2-二等,3-三等
Name:姓名
Sex:性别
Age:年龄
sibsp:在船上的兄弟/配偶数
parch:在船上父母/孩子数
Ticket:票号
Fare:票价
cabin:Cabin number;客舱号
Embarked:登船地点
类别型字段:Survived, Sex, and Embarked. Ordinal: Pclass连续型字段:Age, Fare. Discrete: SibSp, Parch
1.3 导入数据集
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 在 Jupyter 中正常显示图形,若没有这行代码,图形显示不出来的
%matplotlib inline
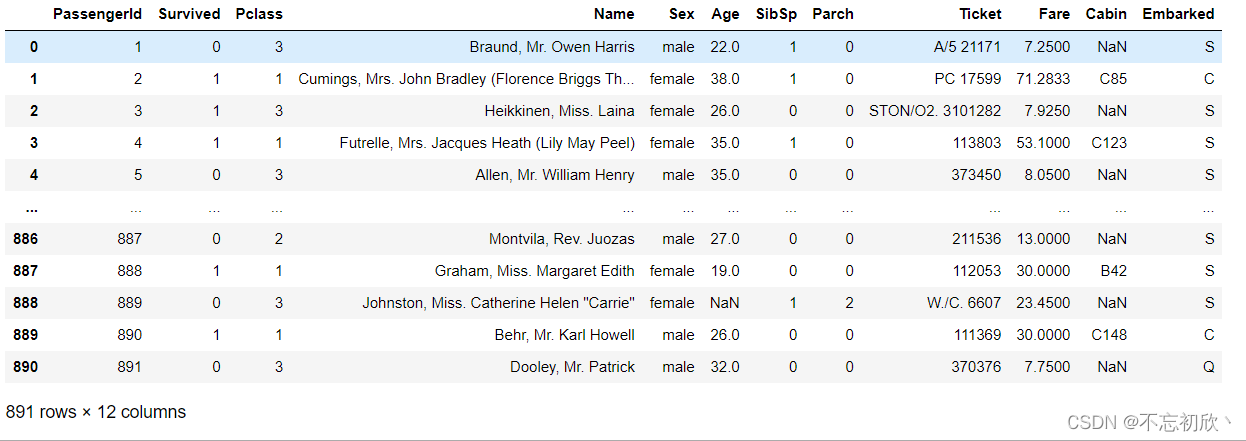
df = pd.read_csv(r'E:\data\train.csv')
df
二、初步分析
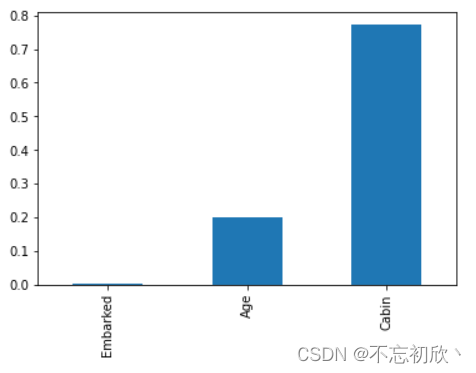
2.1 缺失值分布查看
missing = df.isnull().sum()/len(df)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
2.2 异常值分布查看
通过箱线图查看变量age的异常值分布
# 定义数据和变量名,如果设置x='Age',分布图将横着显示
sns.boxplot(data=df, y='Age')
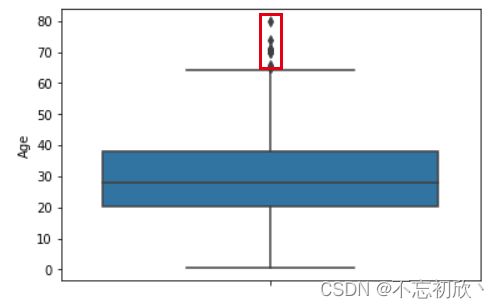
红色框内的数据即为变量age的异常值
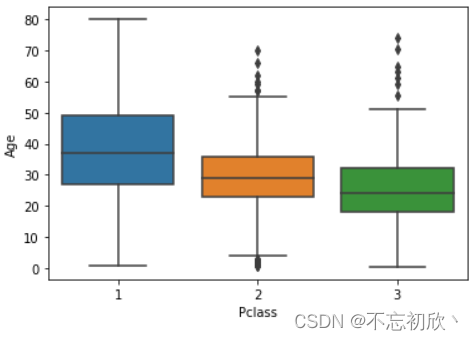
不同的Pclass’(船舱)下的乘客的Age(年龄)的异常值分布
# 调换x/y轴,可以实现箱线图的横向显示
sns.boxplot(x='Pclass',y='Age',data=df)
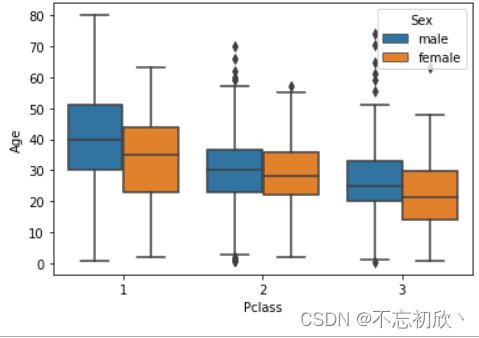
不同船舱和不同性别下年龄的异常值箱线图分布:
# 调换x/y轴,可以实现箱线图的横向显示
ns.boxplot(x='Pclass',y='Age',hue='Sex',data=df)
2.3 查看变量分布
直方图:distplot()
kde:控制密度估计曲线的参数,默认为 True,不设置会默认显示bins:控制分布矩形数量的参数,通常我们可以增加其数量,来看到更为丰富的信息reg: 控制是否生成观测数值的小细条。
先分箱,然后计算每个分箱频数的数据分布。和条形图的区别,条形图有空隙,直方图没有,条形图一般用于类别特征,直方图一般用于数字特征(连续型)。多用于y值和数字(连续型)特征的分布画图
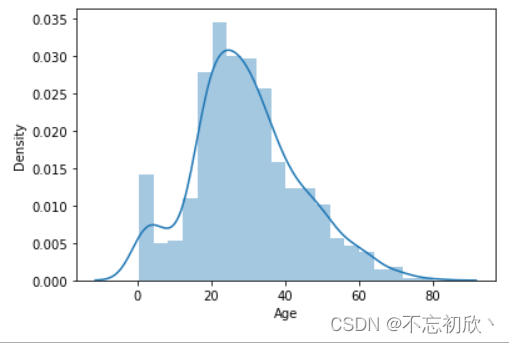
#去除'age'中的缺失值,distplot不能处理缺失数据
df['Age'].dropna(inplace=True)
sns.distplot(df['Age'])
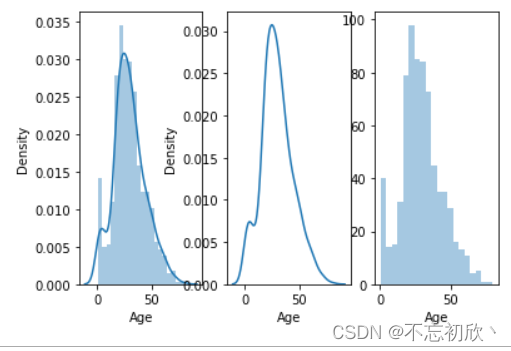
#创建一个1行三列的图片
fig,axes=plt.subplots(1,3)
# 默认
sns.distplot(df['Age'],ax=axes[0])
# 不显示直方图
sns.distplot(df['Age'],hist=False,ax=axes[1])
# 不显示核密度
sns.distplot(df['Age'],kde=False,ax=axes[2])
fig,axes=plt.subplots(1,2)
# 分成20个区间
sns.distplot(df['Age'],kde=False,bins=20,ax=axes[0])
# 以0,1,2,3为分割点,形成区间[0,1],[1,2],[2,3],区间外的值不计入。
sns.distplot(df['Age'],kde=False,bins=[x for x in range(4)],ax=axes[1])
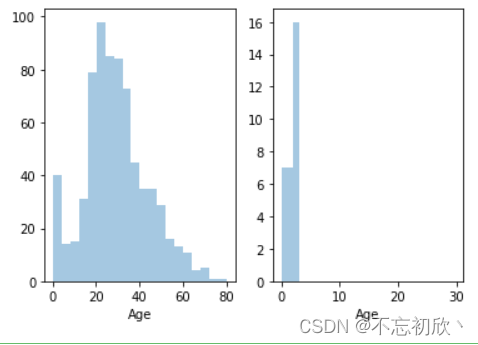
计数图:countplot()
计数图,可将它认为一种应用到分类变量的直方图,也可认为它是用以比较类别间计数差。当你想要显示每个类别中的具体观察数量时,countplot 很容易实现
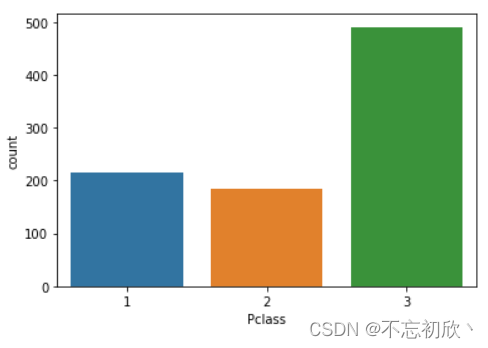
sns.countplot(x="Pclass", data=df)
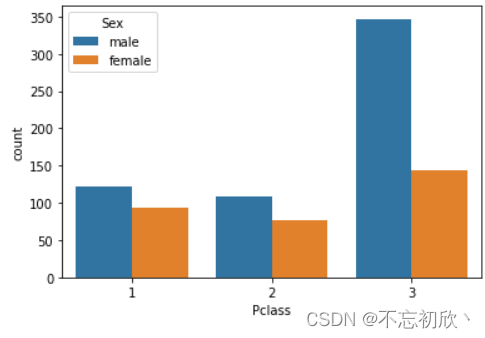
# 查看不同船舱不同性别的人数分布
sns.countplot(x="Pclass", hue="Sex", data=df)
三、数值变量分析
3.1 replot():多个变量之间的关联关系
replot()函数用来表示多个变量之间的关联关系。默认情况下是绘制散点图,也可以绘制线性图,具体绘制什么图形是通过kind参数来决定的。
散点图
"""
x --> 代表x轴数据
y --> 代表y轴数据
data --> 数据集
kind --> 选择绘图类型 默认为scatter,还有line等
"""
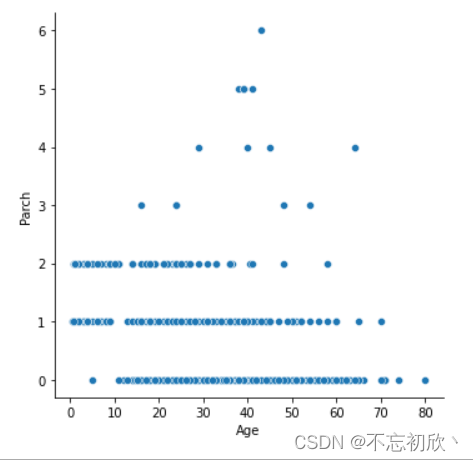
# 年龄与票价之间的关系
sns.relplot(x="Age", y="Fare", data=df, kind="scatter")
"""
x --> 代表x轴数据
y --> 代表y轴数据
data --> 数据集
kind --> 选择绘图类型 默认为scatter,还有line等
"""
# 不同船舱下 年龄与票价之间的关系
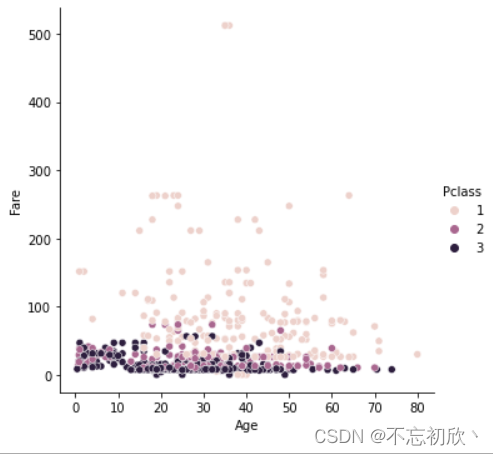
sns.relplot(x="Age", y="Fare", hue='Pclass', data=df, kind="scatter")
线形图
# 年龄与票价之间的关系,阴影部分表示置信区间
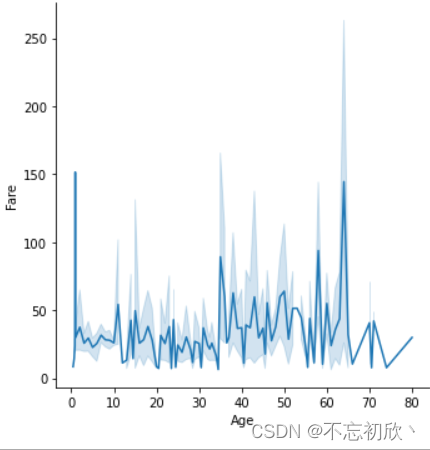
sns.relplot(x="Age", y="Fare", data=df, kind="line")
# 不同船舱下 年龄与票价之间的关系
sns.relplot(x="Age", y="Fare", hue='Pclass', data=df, kind="line")
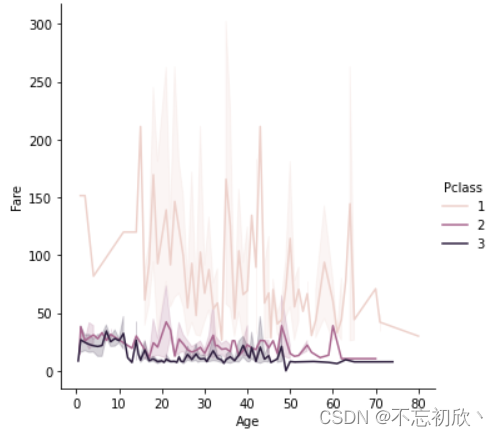
从以上散点图和线形图可以观察到年龄与票价没有关系
3.2 lmplot()/regplot:分析两个变量的线性关系
lmplot是用来绘制回归图的,通过lmplot我们可以直观地总览数据的内在关系
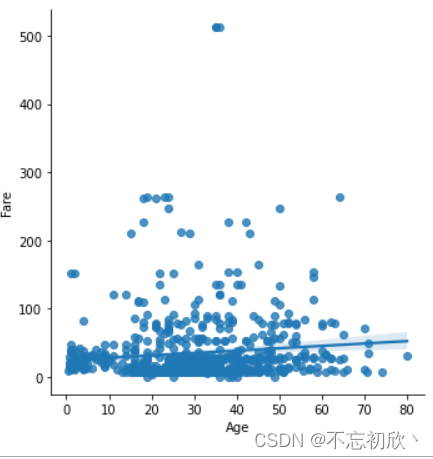
sns.lmplot(data=df, x='Age', y='Fare')
# 添加类别,不同船舱下,年龄与票价的回归线
sns.lmplot(data=df, x='Age', y='Fare', hue='Pclass')
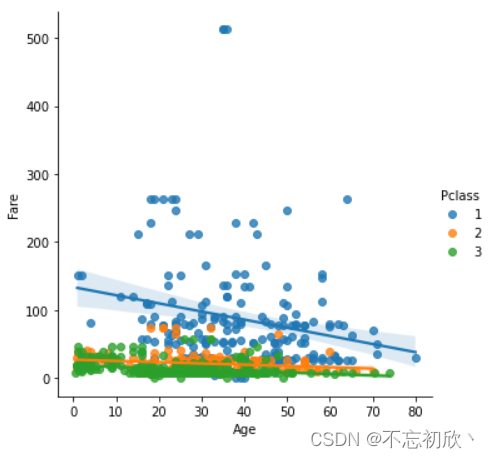
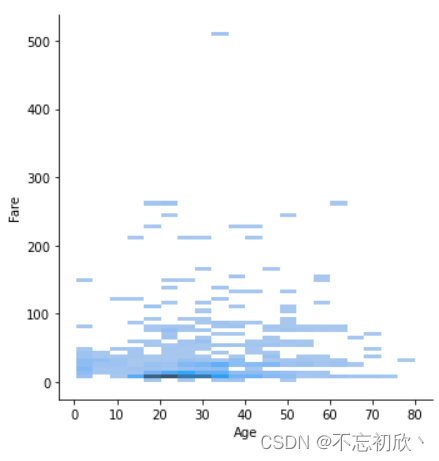
3.3 displot():两个变量的联合分布
# 默认直方图
sns.displot(data=df, x='Age', y='Fare')
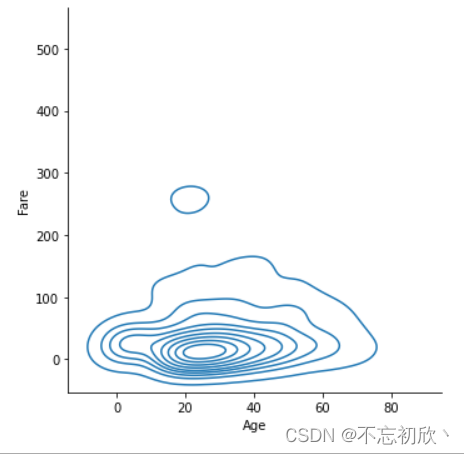
# kde曲线
sns.displot(data=df, x='Age', y='Fare', kind='kde')
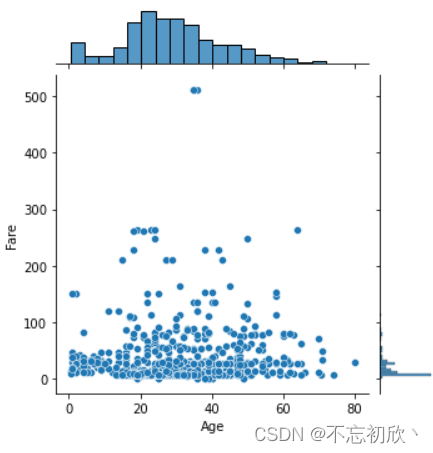
3.4 jointplot():绘制两个变量的联合分布和各自分布
默认情况下,联合分布是散点图,可以通过kind进行设置。kind is one of [‘scatter’, ‘hist’, ‘hex’, ‘kde’, ‘reg’, ‘resid’]
# 设置x、y轴数据,设置高度
sns.jointplot(x='Age',y='Fare',data=df,height=5)
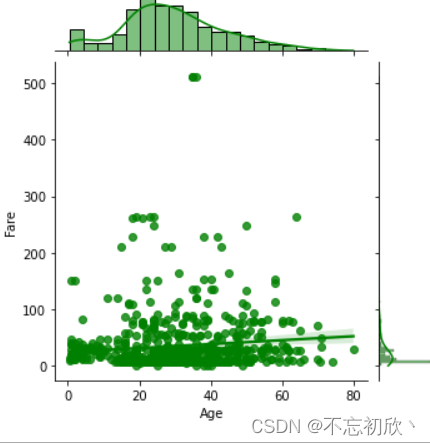
设置绘图种类为reg,颜色为green
sns.jointplot(x='Age',y='Fare',data=df,kind='reg',height=5,color='green')
3.5 pairplot():成对绘制所有数值变量的联合分布
pairplot()函数是用来展现变量两两之间的关系,线性、非线性、相关等等
# 全部变量都放进去
sns.pairplot(df)
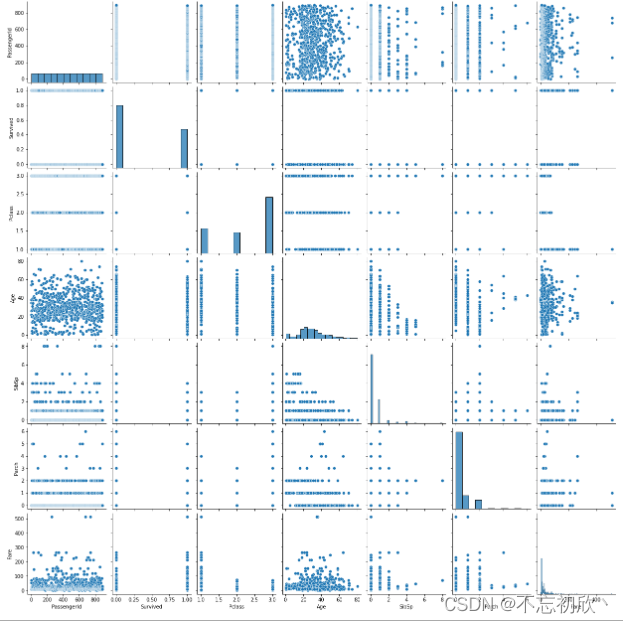
可以看到对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图。
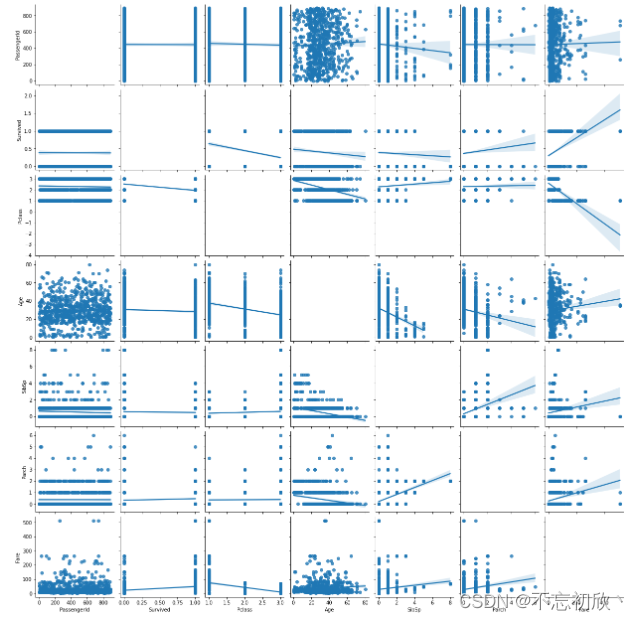
# kind:用于控制非对角线上图的类型,可选'scatter'与'reg'
# diag_kind:用于控制对角线上的图分类型,可选'hist'与'kde'
sns.pairplot(df, kind='reg',diag_kind='ked')
# sns.pairplot(df, kind='reg',diag_kind='hist')
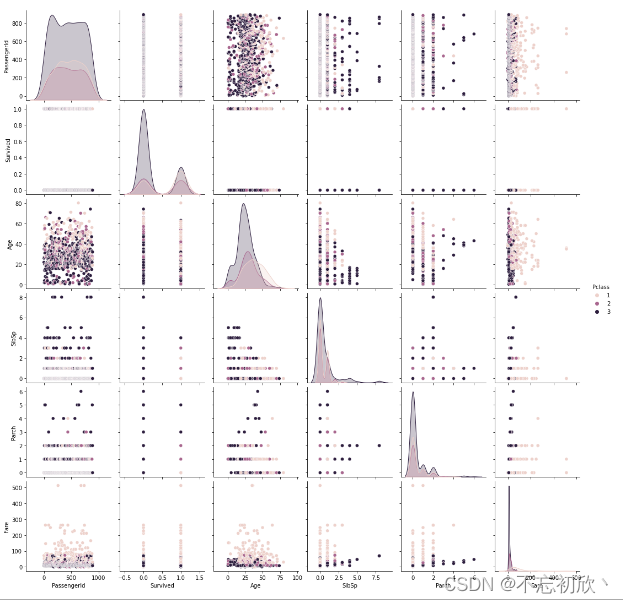
针对某一字段进行分类
# hue:针对某一字段进行分类
sns.pairplot(df, hue='Pclass')
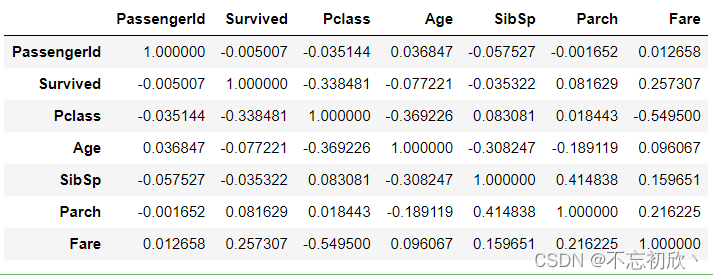
3.6 corr()与heatmap()
corr函数
在数据相关性分析中,corr()函数表示了data中的两个变量之间的相关性,取值范围为[-1,1],取值接近-1,表示反相关,类似反比例函数,取值接近1,表正相关。
car_cor = df.corr()
car_cor
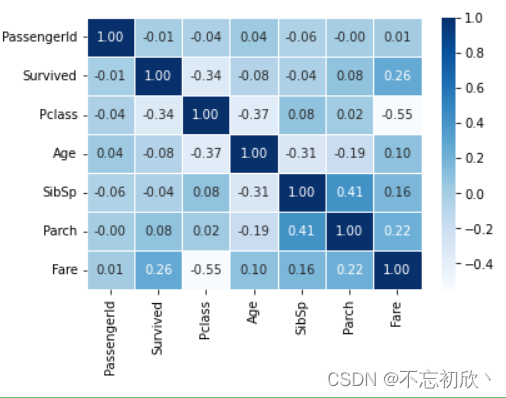
heatmap()函数
热力图是用颜色编码的矩阵来绘制矩形数据,把求到的相关系数表示出来
sns.heatmap(car_cor, cmap='Blues', annot=True, fmt='.2f', linewidth=0.5)
四、类别型变量分析
4.1 countplot()函数与histplot()函数
sns.countplot():计数图,用于画类别特征的频数条形图
sns.histplot():直方图,也是关于类别特征的频率分布,与countplot()函数功能类似
# 对船舱类别变量分析
sns.distplot(df['Pclass'])
其他用法类似countplot()函数
4.2 类别变量与数值变量的关系
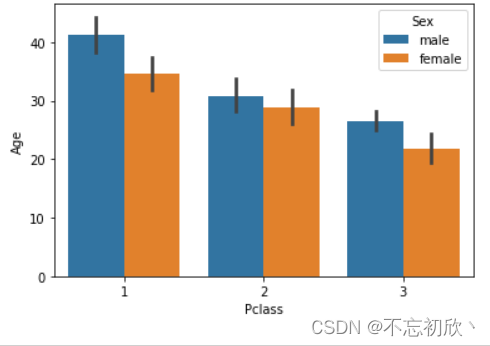
4.2.1 不同类别中数值变量的均值/中值估计
barplot: 条形图,利用矩阵条的高度反映数值变量的集中趋势,以及使用errorbar功能(差棒图)来估计变量之间的差值统计(置信区间)。需要提醒的是 barplot() 默认展示的是某种变量分布的平均值(可通过参数修改为 max、median 等)。
sns.barplot(x='Pclass', y='Age', hue='Sex',data=df)
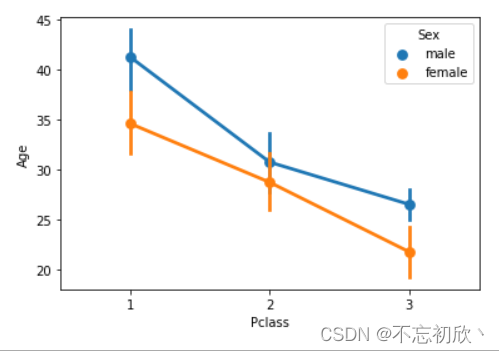
pointplot:点图,点图代表散点图位置的数值变量的中心趋势估计,并使用误差线提供关于该估计的不确定性的一些指示。点图比条形图在聚焦一个或多个分类变量的不同级别之间的比较时更为有用。
点图尤其善于表现交互作用:一个分类变量的层次之间的关系如何在第二个分类变量的层次之间变化。
重要的一点是点图仅显示平均值(或其他估计值),但在许多情况下,显示分类变量的每个级别的值的分布可能会带有更多信息。在这种情况下,其他绘图方法,例如箱型图或小提琴图可能更合适。
sns.pointplot(x='Pclass', y='Age', hue='Sex',data=df)
4.2.2 不同类别中数值变量的取值范围
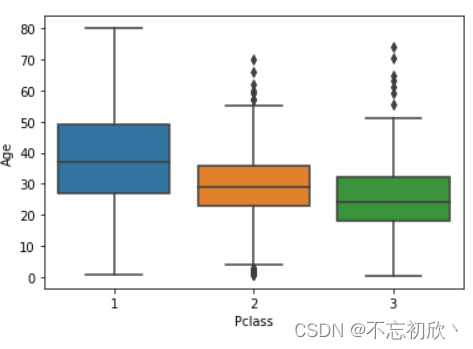
boxplot:箱线图,是一种用作显示一组数据分散情况的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。因形状如箱子而得名。这意味着箱线图中的每个值对应于数据中的实际观察值。
sns.boxplot(x='Pclass',y='Age',data=df)
4.2.3 不同类别中数值变量的分布图
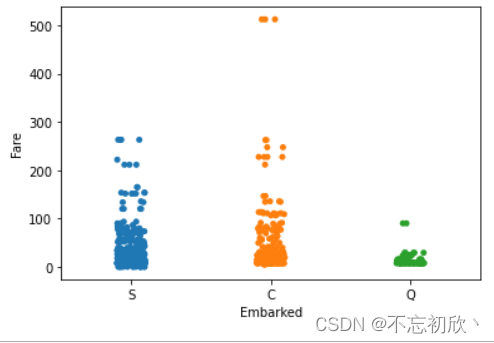
stripplot/swarmplot:散点图,在seaborn中有两种不同的分类散点图。stripplot() 使用的方法是用少量的随机“抖动”调整分类轴上的点的位置,swarmplot() 表示的是带分布属性的散点图。
# 设置'jitter'参数控制抖动的大小
sns.stripplot(x='Embarked',y='Fare', data=df,jitter=1)
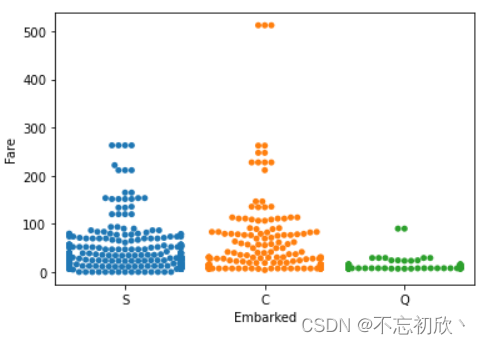
swarmplot() 方法使用防止它们重叠的算法沿着分类轴调整点。它可以更好地表示观测的分布,它适用于相对较小的数据集。
sns.swarmplot(x='Embarked',y='Fare',data=df)
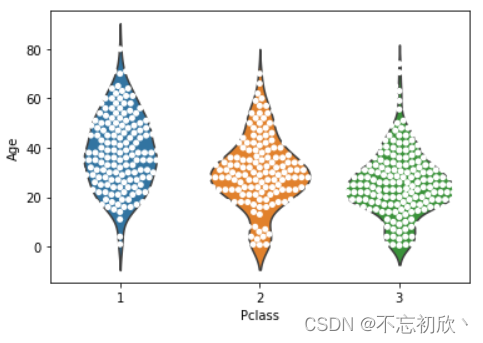
violinplot:小提琴图,小提琴图其实是箱线图与核密度图的结合,箱线图展示了分位数的位置,小提琴图则展示了任意位置的密度,通过小提琴图可以知道哪些位置的密度较高。
sns.violinplot(x='Pclass',y='Age',data=df)
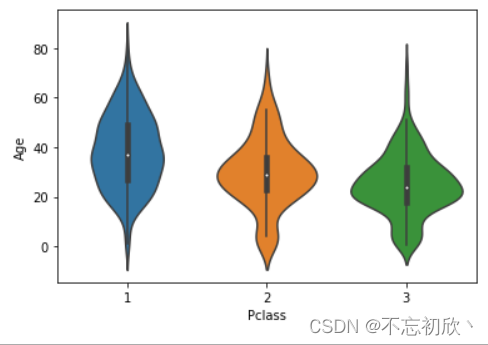
在图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,细黑线表示须。外部形状即为核密度估计。
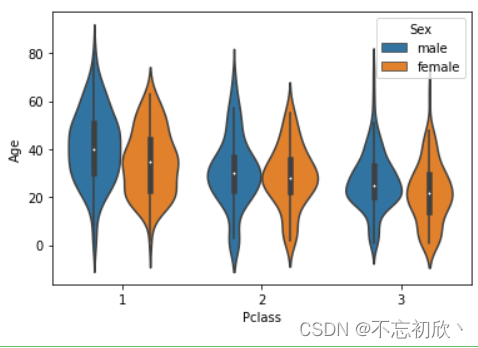
设置hue参数,对字段进行细分。
# 置'hue'参数,对字段进行细分。
sns.violinplot(x='Pclass',y='Age',hue='Sex',data=df)
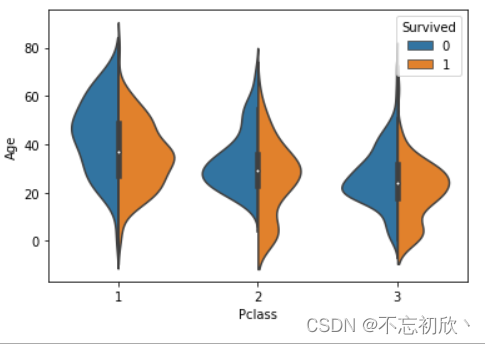
当hue参数只有两个级别时,也可以通过设置split参数为True,“拆分”小提琴,提琴两边分别表示两个分类的情况,这样可以更有效地利用空间。
sns.violinplot(x='Pclass',y='Age',hue='Alive',data=df,split=True)
把上面提到的散点图加入小提琴图中:
sns.violinplot(x='Pclass',y='Age',data=df,inner=None)
sns.swarmplot(x='Pclass',y='Age',data=df,color='white')