Elastic Stack 用于大量用例,从操作日志和指标分析到企业和应用程序搜索。 确保你的数据可扩展、持久且安全地传输到 Elasticsearch 非常重要,尤其是对于任务关键型环境。
本文档的目的是强调 Logstash 最常见的架构模式以及如何随着部署的增长而有效扩展。 重点将围绕操作日志、指标和安全分析用例,因为它们往往需要更大规模的部署。 此处提供的部署和扩展建议可能因你自己的要求而异。
让我们开始吧
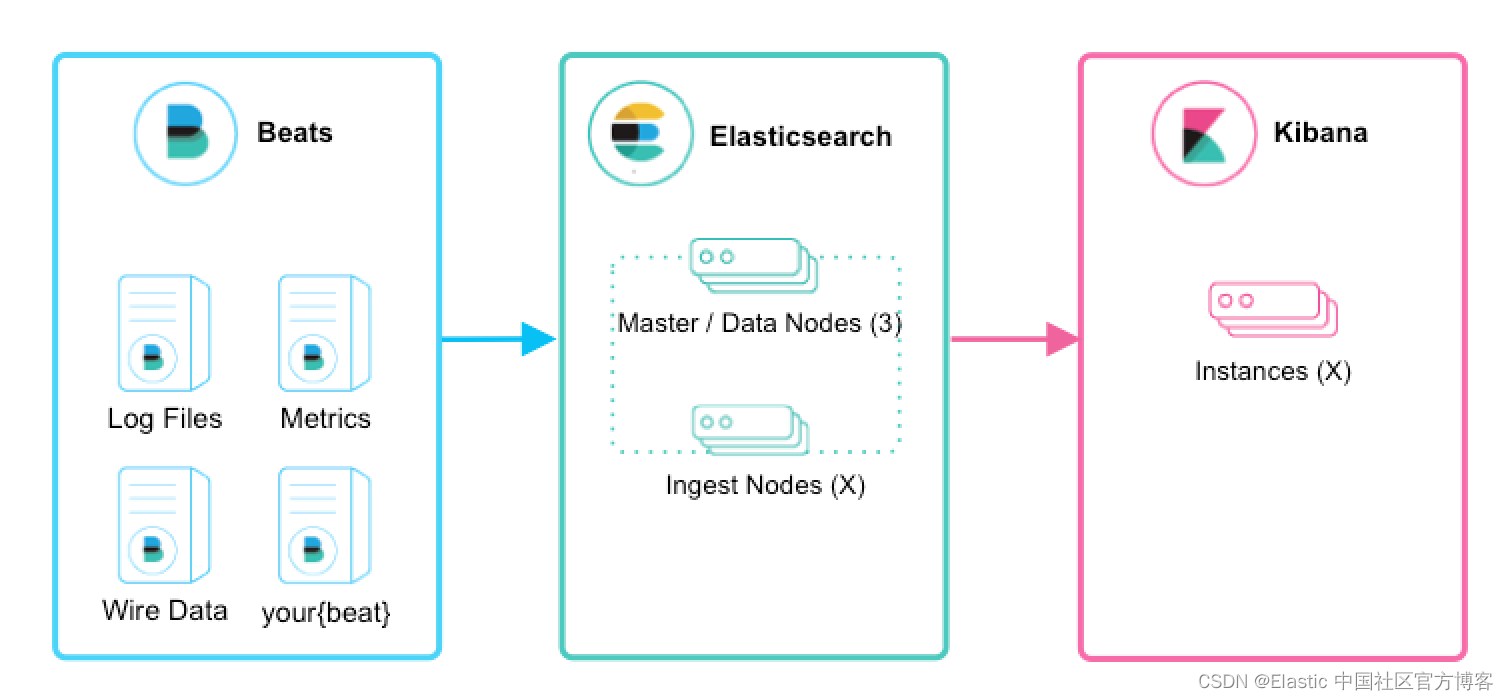
对于初次使用的用户,如果你只是想跟踪日志文件以掌握 Elastic Stack 的强大功能,我们建议你尝试使用 Filebeat Modules。有关 Filebeat 模块的使用,请详细阅读文章 “Beats:Beats 入门教程 (二)”。 Filebeat 模块使你能够快速收集、解析和索引流行的日志类型,并在几分钟内查看预构建的 Kibana 仪表板。 Metricbeat 模块提供了类似的体验,但带有指标数据。 在这种情况下,Beats 会将数据直接发送到 Elasticsearch,其中 Ingest Nodes 将处理和索引你的数据。
Logstash 介绍
将 Logstash 集成到您的架构中有哪些主要好处?
- 通过摄取峰值进行扩展 —— Logstash 有一个自适应的基于磁盘的缓冲系统,可以吸收传入的吞吐量,从而减轻背压
- 从数据库、S3 或消息队列等其他数据源获取
- 将数据发送到多个目的地,如 S3、HDFS,或写入文件
- 使用条件数据流逻辑组成更复杂的处理管道
有关 Beats 和 Logstash 的比较,请详细阅读文章 “Beats:Elastic Beats 介绍 及和 Logstash 的比较”。
摄取扩容
Beats 和 Logstash 让 ingest 变得很棒。 它们共同提供了一个可扩展且有弹性的综合解决方案。 你能期待什么?
- 水平可扩展性、高可用性和可变负载处理
- 具有至少一次传递保证的消息持久性
- 具有身份验证和线路加密的端到端安全传输
Beats 和 Logstash
Beats 在数以千计的边缘主机服务器上运行,收集、跟踪日志并将其发送到 Logstash。 Logstash 用作数据统一和丰富的集中式流引擎。 Beats 输入插件公开了一个安全的、基于确认的端点,供 Beats 将数据发送到 Logstash。
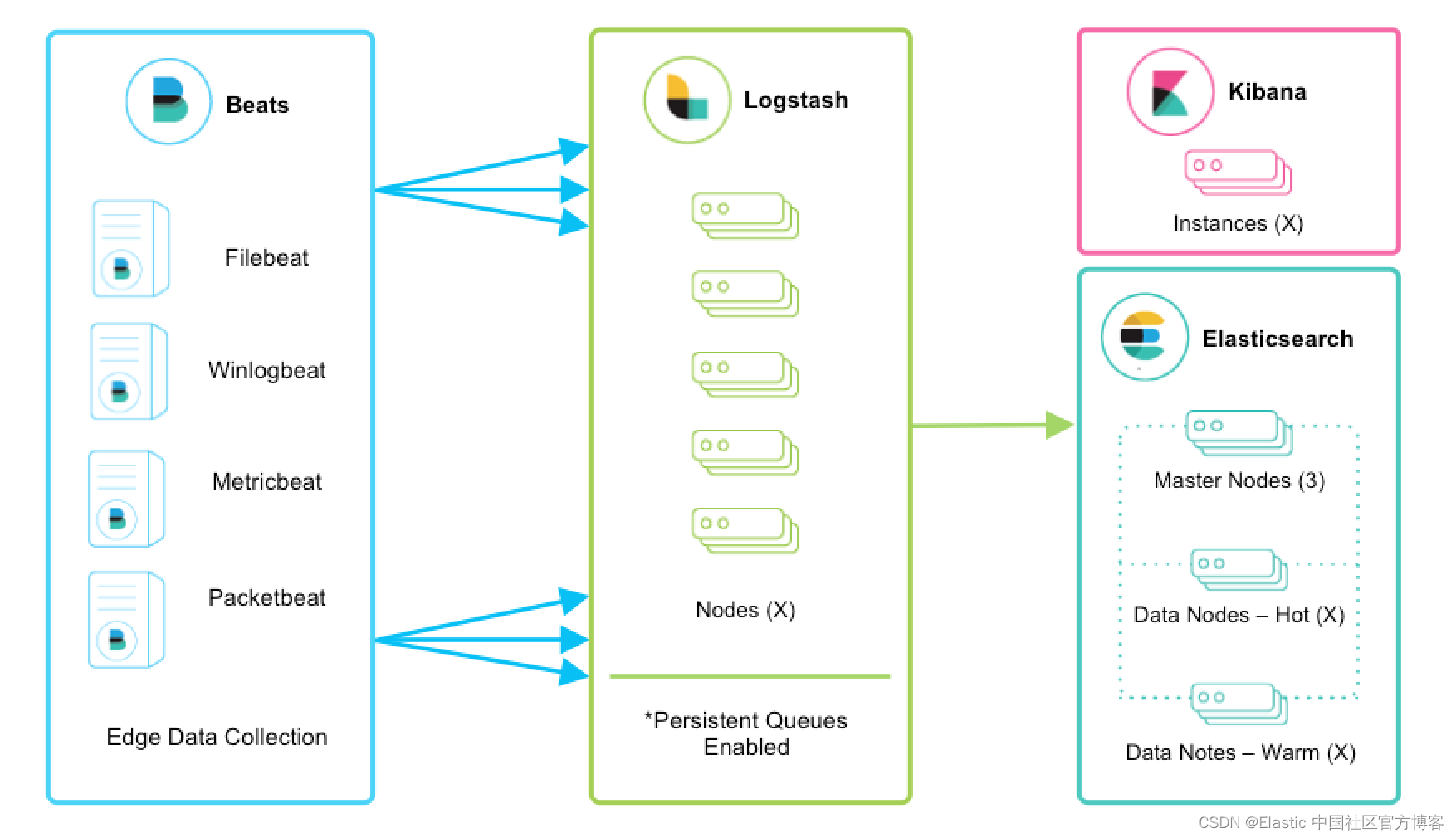
注意:强烈建议启用持久队列,并且这些架构特征假定它们已启用。 我们鼓励你查看持久队列 (PQ) 文档以获得功能优势和有关弹性的更多详细信息。
可扩展性
Logstash 是水平可扩展的,可以形成运行相同管道的节点组。 Logstash 的自适应缓冲功能即使在可变吞吐量负载下也能促进流畅的流式传输。 如果 Logstash 层成为摄取瓶颈,只需添加更多节点以进行横向扩展。 以下是一些一般性建议:
- Beats 应该在一组 Logstash 节点之间进行负载平衡。
- 建议至少使用两个 Logstash 节点以实现高可用性。
- 每个 Logstash 节点只部署一个 Beats 输入是很常见的,但也可以为每个 Logstash 节点部署多个 Beats 输入,以便为不同的数据源公开独立的端点。
韧性
在此摄取流中使用 Filebeat 或 Winlogbeat 进行日志收集时,可以保证至少一次交付。 从 Filebeat 或 Winlogbeat 到 Logstash,以及从 Logstash 到 Elasticsearch,这两种通信协议都是同步的并且支持确认。 其他 Beats 尚不支持这种机制。
Logstash 持久队列提供跨节点故障的保护。 对于 Logstash 中的磁盘级弹性,确保磁盘冗余很重要。 对于本地部署,建议你配置 RAID。 在云端或容器化环境中运行时,建议你使用具有反映数据 SLA 的复制策略的永久性磁盘。
注意:确保 queue.checkpoint.writes: 1 设置为至少一次保证。 有关更多详细信息,请参阅持久队列持久性文档。
数据处理
Logstash 通常会使用 grok 或 dissect 提取字段,增加地理信息,并可以使用文件、数据库或 Elasticsearch 查找数据集进一步丰富事件。更多关于丰富数据的过滤器,请参考 “Logstash:通过 lookups 来丰富数据”。 请注意,处理复杂性会影响整体吞吐量和 CPU 利用率。 确保检查其他可用的过滤器插件。
安全传输
在整个交付链中提供企业级安全性。
- 建议对从 Beats 到 Logstash 的传输以及从 Logstash 到 Elasticsearch 的传输使用有线加密。
- 与 Elasticsearch 通信时有很多安全选项,包括基本身份验证、TLS、PKI、LDAP、AD 和其他自定义领域。 要启用 Elasticsearch 安全性,请参阅保护集群。
监控
运行 Logstash 5.2 或更高版本时,监控 UI 提供对部署指标的深入可见性,有助于观察性能并在扩展时缓解瓶颈。 监控是基本许可证下的一项 X-Pack 功能,因此可以免费使用。 要开始使用,请参阅监控 Logstash。
如果首选外部监控,可以使用返回时间点指标快照的监控 API。
添加其他流行源
用户可能有其他收集日志数据的机制,并且很容易将它们集成并集中到 Elastic Stack 中。 让我们来看看几个场景:
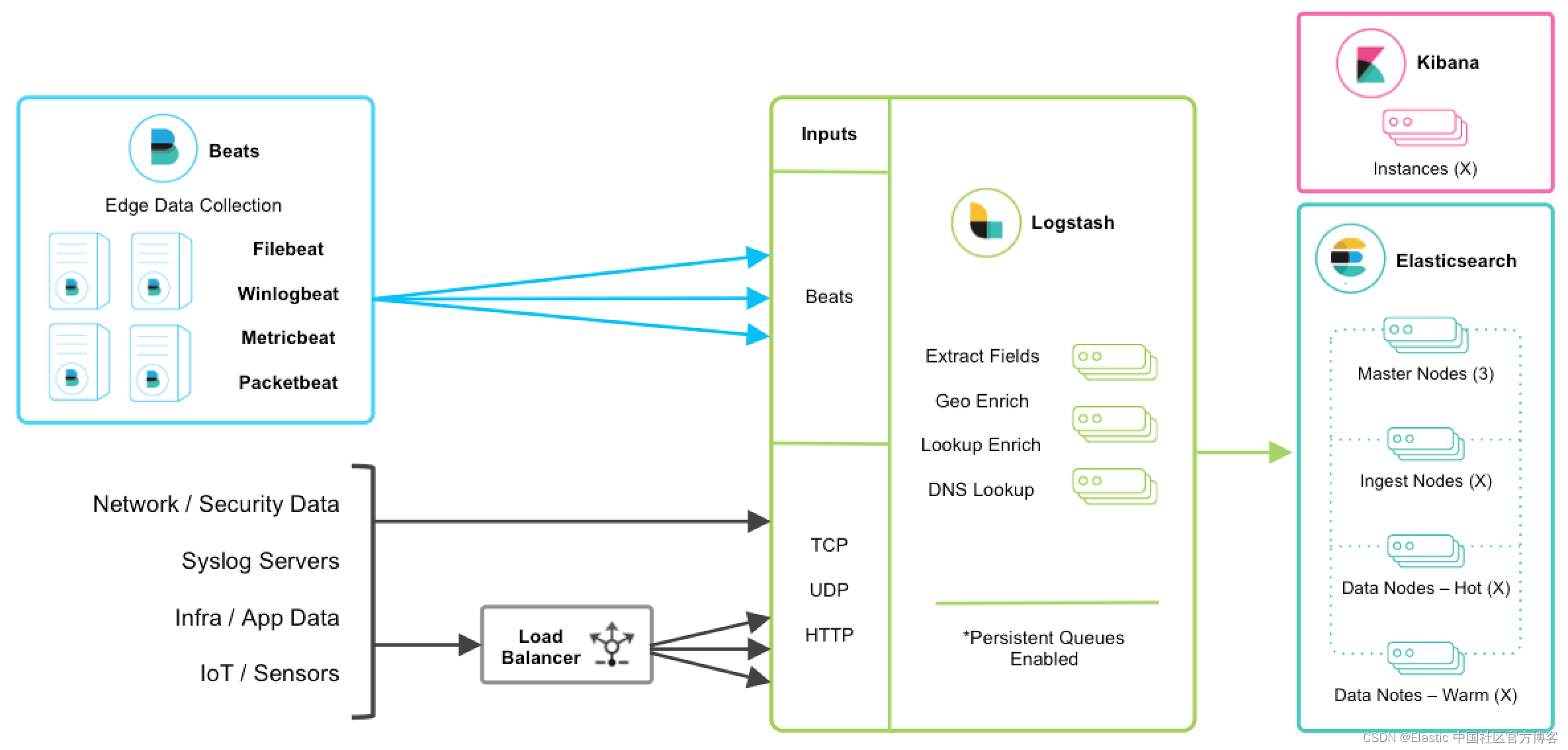
TCP、UDP 和 HTTP 协议
TCP、UDP 和 HTTP 协议是将数据馈送到 Logstash 的常用方法。 Logstash 可以使用相应的 TCP、UDP 和 HTTP 输入插件公开端点侦听器。 下面列举的数据源通常是通过这三种协议之一获取的。
注意:TCP 和 UDP 协议不支持应用程序级别的确认,因此连接问题可能会导致数据丢失。
对于高可用性场景,应添加第三方硬件或软件负载均衡器,如 HAProxy,将流量扇出到一组 Logstash 节点。
网络和安全数据
尽管 Beats 可能已经满足你的数据摄取用例,但网络和安全数据集有多种形式。 让我们谈谈其他一些摄取点。
- 网络线路数据 - 使用 Packetbeat 收集和分析网络流量。
- Netflow v5/v9/v10 - Logstash 使用 Netflow 编解码器理解来自 Netflow/IPFIX 导出器的数据。
- Nmap - Logstash 使用 Nmap 编解码器接受和解析 Nmap XML 数据。
- SNMP 陷阱 - Logstash 有一个本机 SNMP trap input。
- CEF - Logstash 使用 CEF 编解码器接受和解析来自 Arcsight SmartConnectors 等系统的 CEF 数据。 有关更多详细信息,请参阅此博客系列。
基础设施和应用程序数据和物联网
可以使用 Metricbeat 收集基础设施和应用程序指标,但应用程序也可以将 webhook 发送到 Logstash HTTP 输入或使用 HTTP 轮询器输入插件从 HTTP 端点轮询指标。
对于使用 log4j2 记录的应用程序,建议使用 SocketAppender 将 JSON 发送到 Logstash TCP 输入。 或者,log4j2 也可以将日志记录到文件中,以便使用 FIlebeat 进行收集。 不推荐使用 log4j1 SocketAppender。
Raspberry Pi、智能手机和联网车辆等物联网设备通常通过其中一种协议发送遥测数据。
与消息队列集成
如果你正在利用消息队列技术作为现有基础设施的一部分,那么将该数据导入 Elastic Stack 将很容易。 对于使用外部队列层(如 Redis 或 RabbitMQ)仅用于 Logstash 数据缓冲的现有用户,建议使用 Logstash 持久队列而不是外部队列层。 这将通过消除摄取架构中不必要的复杂层来帮助整体简化管理。
对于想要从现有 Kafka 部署中集成数据或需要临时存储的底层使用的用户,Kafka 可以充当数据中心,Beats 可以持久保存在其中,Logstash 节点可以从中使用数据。
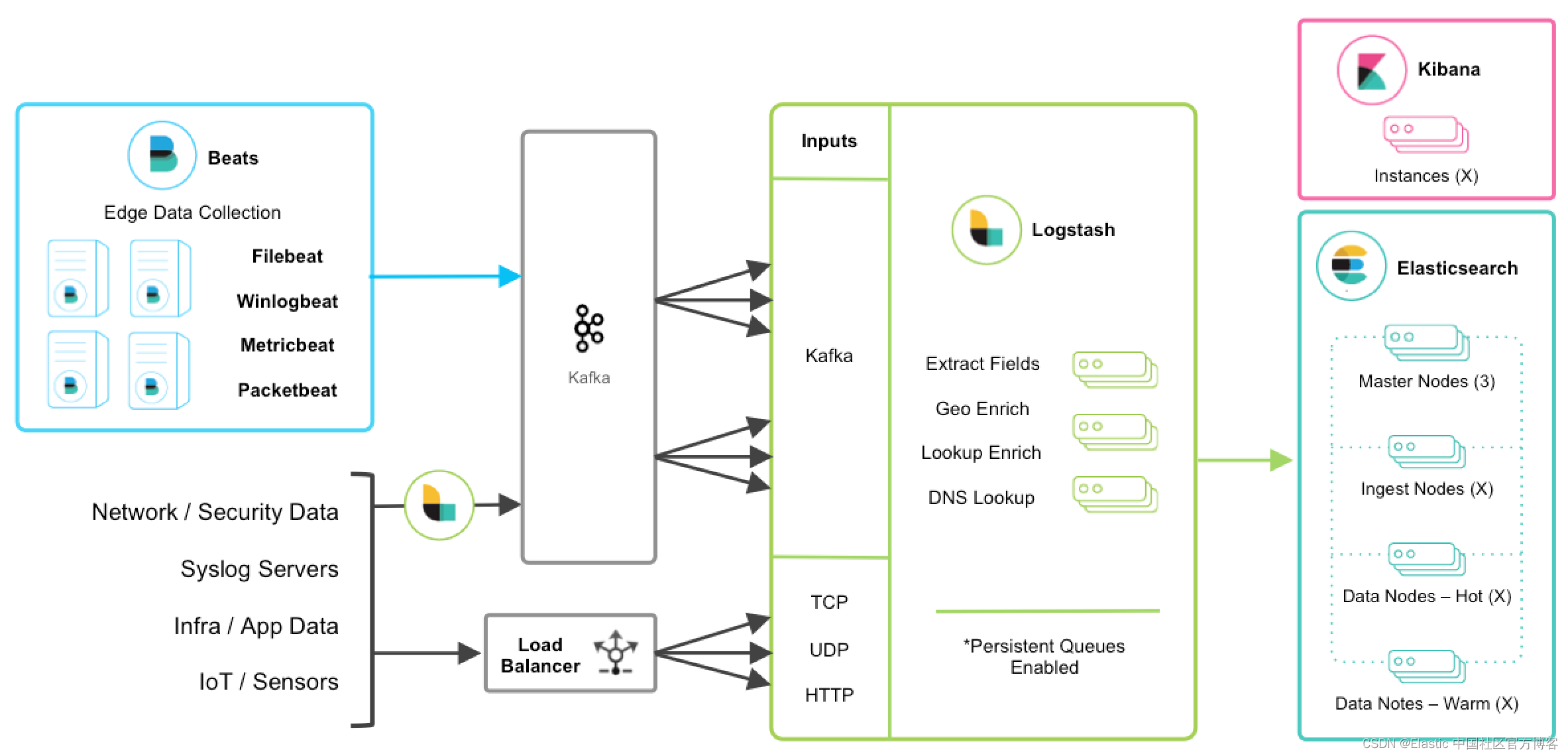
其他 TCP、UDP 和 HTTP 源可以使用 Logstash 作为管道持久保存到 Kafka,以代替负载均衡器实现高可用性。 然后,一组 Logstash 节点可以使用 Kafka 输入从主题中消费,以进一步转换和丰富传输中的数据。
韧性和恢复
当 Logstash 从 Kafka 消费时,应该启用持久队列并将增加传输弹性以减轻 Logstash 节点故障期间重新处理的需要。 在这种情况下,建议使用默认的持久队列磁盘分配大小 queue.max_bytes:1GB。
如果 Kafka 配置为长时间保留数据,在容灾和对账的情况下,可以从 Kafka 重新处理数据。
其他消息队列集成
虽然不需要额外的队列层,但 Logstash 可以使用无数其他消息队列技术,如 RabbitMQ 和 Redis。 它还支持从 Pub/Sub、Kinesis 和 SQS 等托管队列服务中摄取数据。