导言
Content
正如前文windows 10 开启WSL2介绍的,我们可以在windows10中使用linux子系统。今天本文介绍如何在此基础上安装Docker并支持在wsl中使用GPU。
准备工作
- 加入windows insider preview。建议选Dev通道,不要选Beta。
-
安装Nvidia WSL2-compatibile 驱动
打开这个链接-> Get CUDA Driver-> log in -> download
- 管理员身份运行powershell:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
wsl --set-default-version 2
- 更新 wsl
wsl.exe --update
如果update参数无效,没有更新wsl,则说明你没有使用预览版的windows系统,wsl的版本低。也许你从NVIDIA、Docker、Microsoft看到的文档中告诉你大于某个版本号就可以,但我建议你使用当前最新版本。
If you find wsl cannot be updated, please update your windows os to the latest preview version.
安装Docker
下载
去Docker官网下载,请不要使用下面这个脚本。
Don't use the following commend. Please visit Docker offical website.
curl https://get.docker.com | sh
设置
Use the WSL2 based engine
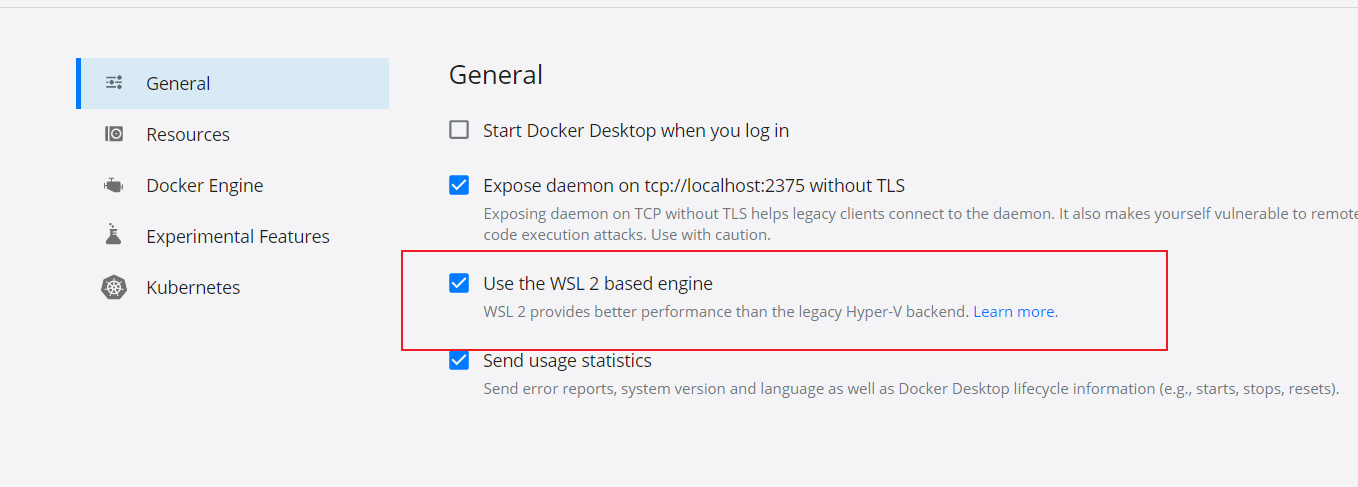
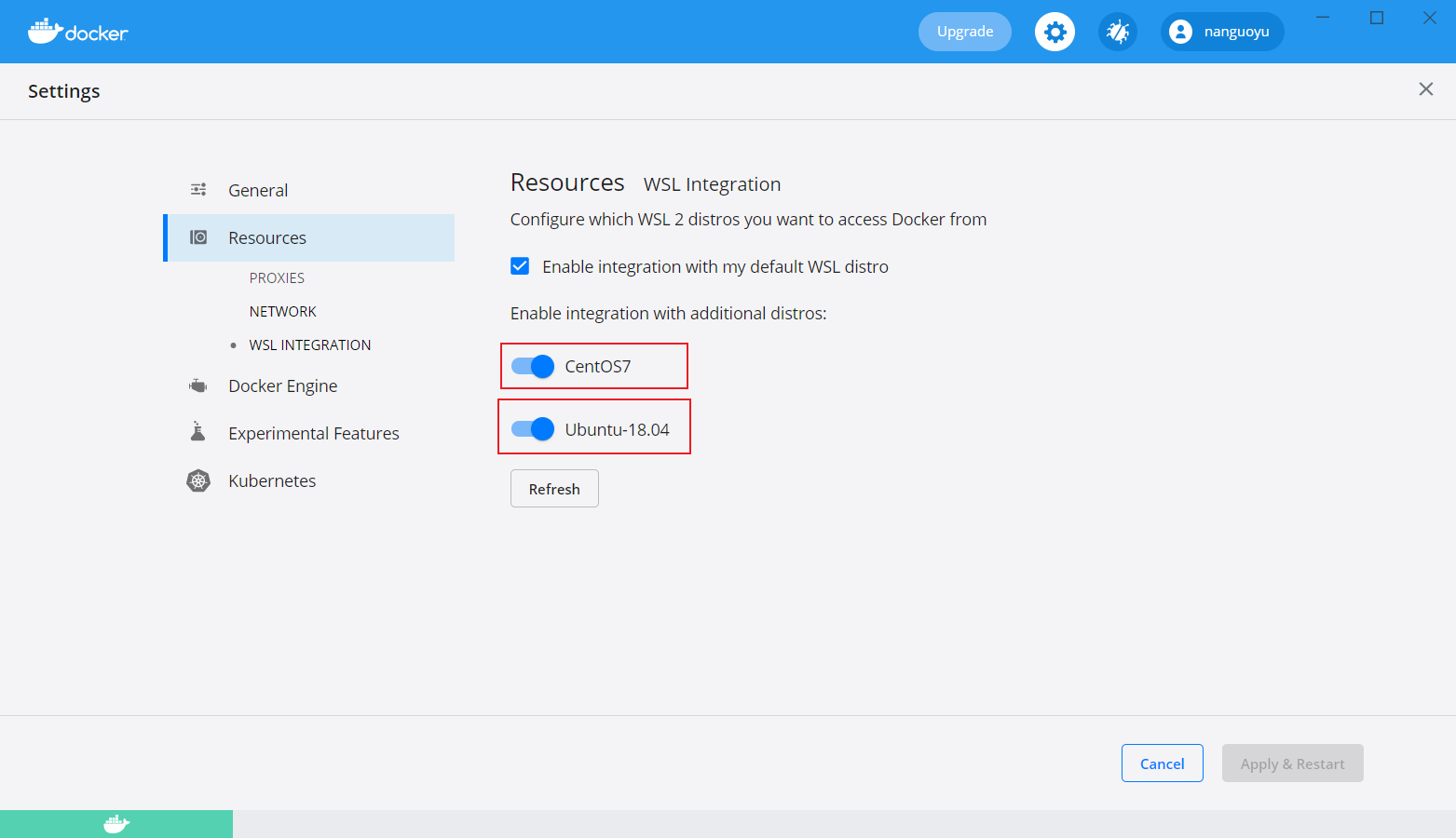
开启你需要使用docker的wsl发行版
安装CUDA Toolkit
在wsl里,这里举例用到微软store下载的Ubuntu-18.04
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
sudo sh -c 'echo "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 /" > /etc/apt/sources.list.d/cuda.list'
sudo apt-get update
sudo apt-get install -y cuda-toolkit-11-0
测试CUDA
cd /usr/local/cuda/samples/4_Finance/BlackScholes
make
./BlackScholes
如果结果看起来如同下列所示,说明是OK的。
GPU Device 0: "Turing" with compute capability 7.5
Initializing data...
...allocating CPU memory for options.
...allocating GPU memory for options.
...generating input data in CPU mem.
...copying input data to GPU mem.
Data init done.
Executing Black-Scholes GPU kernel (512 iterations)...
Options count : 8000000
BlackScholesGPU() time : 0.723174 msec
Effective memory bandwidth: 110.623468 GB/s
Gigaoptions per second : 11.062347
BlackScholes, Throughput = 11.0623 GOptions/s, Time = 0.00072 s, Size = 8000000 options, NumDevsUsed = 1, Workgroup = 128
Reading back GPU results...
Checking the results...
...running CPU calculations.
Comparing the results...
L1 norm: 1.741792E-07
Max absolute error: 1.192093E-05
Shutting down...
...releasing GPU memory.
...releasing CPU memory.
Shutdown done.
[BlackScholes] - Test Summary
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
请注意,使用
nvidia-smi命令不起作用是正常的
安装 NVIDIA Container Toolkit
distribution=(. /etc/os-release;echoIDVERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnvidia-container/experimental/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
启动docker service
sudo service docker restart
测试下docker
docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果结果形如下列所示,则说明是OK的
Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance.
-fullscreen (run n-body simulation in fullscreen mode)
-fp64 (use double precision floating point values for simulation)
-hostmem (stores simulation data in host memory)
-benchmark (run benchmark to measure performance)
-numbodies=<N> (number of bodies (>= 1) to run in simulation)
-device=<d> (where d=0,1,2.... for the CUDA device to use)
-numdevices=<i> (where i=(number of CUDA devices > 0) to use for simulation)
-compare (compares simulation results running once on the default GPU and once on the CPU)
-cpu (run n-body simulation on the CPU)
-tipsy=<file.bin> (load a tipsy model file for simulation)
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
> Windowed mode
> Simulation data stored in video memory
> Single precision floating point simulation
> 1 Devices used for simulation
MapSMtoCores for SM 7.5 is undefined. Default to use 64 Cores/SM
GPU Device 0: "GeForce GTX 1650" with compute capability 7.5
> Compute 7.5 CUDA device: [GeForce GTX 1650]
16384 bodies, total time for 10 iterations: 25.868 ms
= 103.772 billion interactions per second
= 2075.440 single-precision GFLOP/s at 20 flops per interaction
如果你发现使用Nvidia Driver >=465.42 时,有这样的错误信息:
docker: Error response from daemon: OCI runtime create failed:
container_linux.go:367: starting container process caused: process_linux.go:495: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: requirement error: unsatisfied condition:
cuda>=11.2, please update your driver to a newer version, or use an earlier cuda container: unknown.
请更新驱动 Nvidia Driver >=470.76
Ref: Issue
一些问题QA
- Error: only 0 Devices available, 1 requested. Exiting.
- reboot
- IP address of windows host
cat /etc/resolv.conf | grep nameserver | awk '{ print $2 }'
reference
1.https://ocdevel.com/blog/20201207-wsl2-gpu-docker
2.https://docs.nvidia.com/cuda/wsl-user-guide/index.html#installing-nvidia-docker
3.https://docs.microsoft.com/zh-cn/windows/wsl/install-win10
4.https://developer.nvidia.com/blog/announcing-cuda-on-windows-subsystem-for-linux-2/
5.https://docs.docker.com/docker-for-windows/wsl/