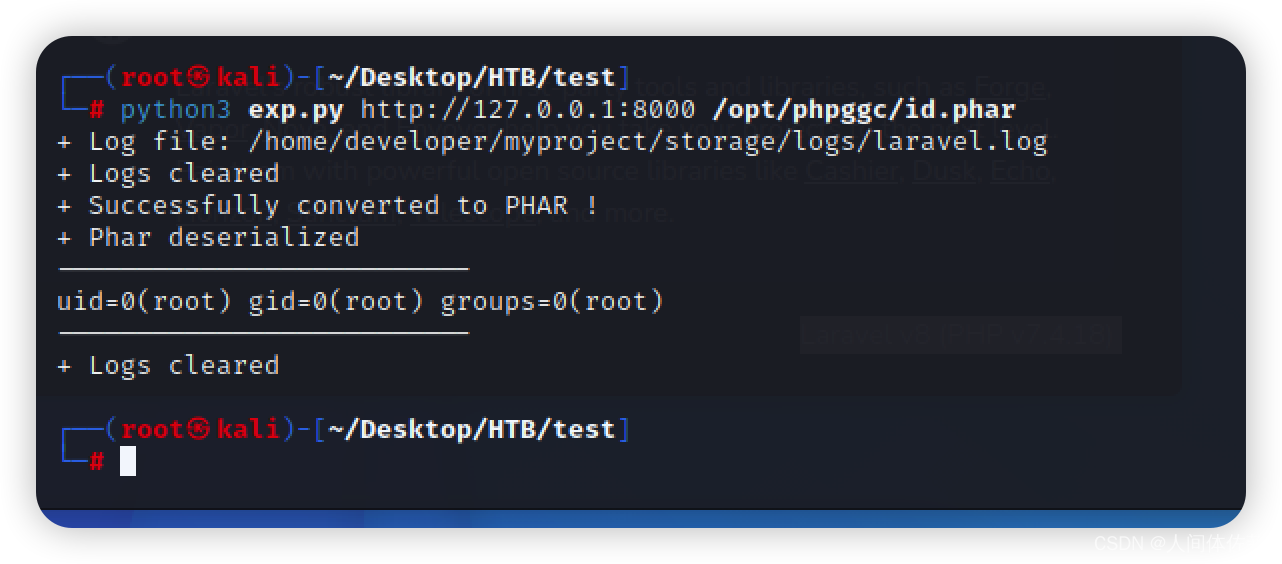
Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。如图4-14所示。
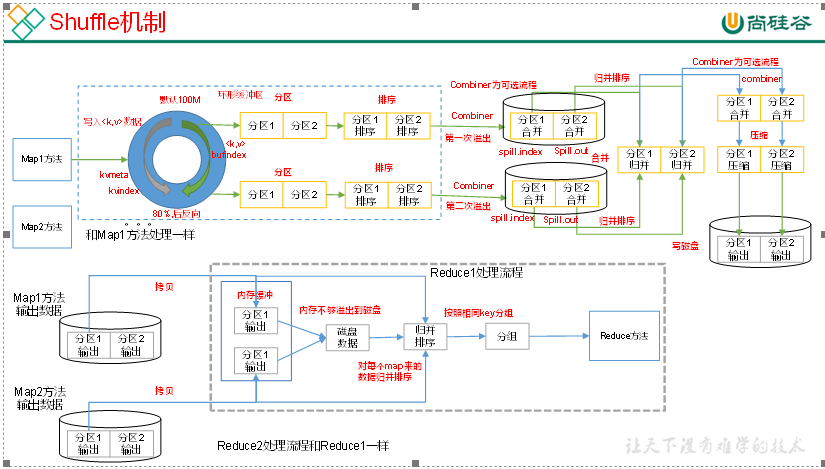
图4-14 Shuffle机制
2 Partition分区
1、问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统充结果
按照手机归属地不同省份输出到不同文件中(分区)
2、默认Partitioner分区
public class HashPartitioner extends Partitioner{
public int getPartition (K key,v value, int numReduceTasks){
return (key.hashcode() & 工nteger.MAx_VALUE) % numReduceTasks ;
}
默认分区是根据key的ashCode又ReduceTasks个数取模得到的。用户没法
控制哪个key存储到哪个分区。

4、分区总结
(1)如果ReduceTask的数量>getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如果ReduceTask:的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个
ReduceTask,最终也就只会产生一个结果文件part-r-o0000 ;
(4)分区号必须从零开始,逐一累加。
5、案例分析
例如∶假设自定义分区数为5,则
(1) job.setNumReduceTasks(1);会正常运行,只不过会产生一个输出文什
(2)job.setNVumReduceTasks(2);会报错
(3) job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件。










![[附源码]计算机毕业设计springboot安防管理平台](https://img-blog.csdnimg.cn/4e22be9bbe0946d3bf1b4dd351882e1b.png)