| 🍿*★,°*:.☆欢迎您/$:*.°★* 🍿 | |
| | |
正文
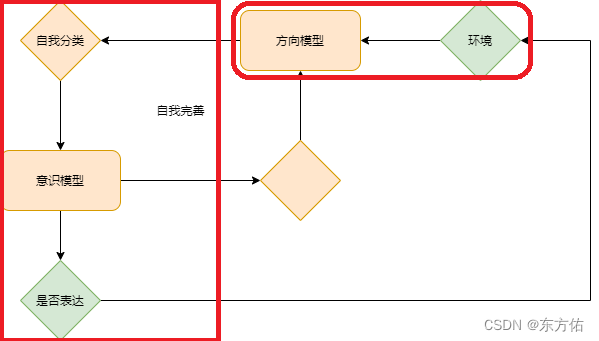
如图一所示 目前深度学习缺少的是 红色大框的部分 智能没有自我意识
同时 训练的方法也是不对的
直到最近的扩散模型 才刚刚有了一点起色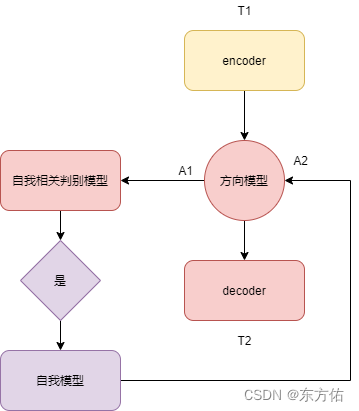
具体的训练方法 类似图二所示 假设人类获取信息只是通过眼睛 那么眼睛每次的 输入速度是
1/24 甚至更快 所以连续两次的输入差距不会很大 同时 是类似序列输入的
假设输入是 A B C D 四个图片 那么 参与训练的 输入输出(label )是 AB BC CD
同时中间会生成
隐藏变量 Action 输入到自我关系 模型中判断与自己的相关度 如果相关度高那么择 取完整的信息
AB 进行自我数据 建模
同时 和外界交互和内部方向模型进行交互完善自己
理论上方向模型应具有 模仿能力和 查找能力 和记忆能力
说起来自我模型更像是现在我们所使用的深度模型
而我们缺一个 具有模仿能力 记忆能力 尤其是记忆能力的模型
而目前的超大模型具备了 这个能力 所以 自己的模型更像是目前的 徒弟模型
区别在于当前的方法是直接的与大模型进行交互 同时 也不会对外界进行交互
只是输入 输出 没有 进行学习
事实上貌似这样解释 更合理 人类在清醒的时候 使用 小模型进行交互 使用 学习和睡觉的时候进行大模型交互
同时记忆是单独运行的 对外界的交互 实质性的输出 是小模型的事情 大模型负责的是 提供帮助
这样提高了运行效率,在我们思考的时候其实是和自己的大模型在沟通交互
脑子里面存在两个我 一是世界模型 一个是 自我模型 每次将小模型 带入大模型 大模型会给出指导
小模型决定输入输出
总结
有模有样的胡说八道,除了大小模型 还有一些相似度 和 数据增强的一些模型其实模仿
是一个数据增强的例子 在原来的基础上进行适当的加噪声 方可实现 就如同今天很好的
扩散模型一样 数据增强 来模仿 这其实也是大模型的一个分支 故而 利用大模型 训练不同
功能性的 小模型 来单独的使用 或者组合起来使用才是关键 就拿自我分别模型来说 本身大模
型就已经可以 将角色全部分开 但是 我只要将自己和其他分开就好 故而没有必要使用这个
模型 所提提取出训练一个单独的模型 同时 将这些数据带入到这大模型 中 不断的推导 交互
得到一个 所有和自己相关的 数据 从而得到 了自己这个模型。大模型是一个自回归 模型
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由东方佑原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨








![[附源码]计算机毕业设计springboot安防管理平台](https://img-blog.csdnimg.cn/4e22be9bbe0946d3bf1b4dd351882e1b.png)