1. MySQL数据库cpu飙升的话你会如何分析
重点是定位问题。
- 使用top观察mysqld的cpu利用率
- 切换到常用的数据库
- 使用
show full processlist;查看会话 - 观察是哪些sql消耗了资源,其中重点观察state指标
- 定位到具体sql
- pidstat
- 定位到线程
- 在PERFORMANCE_SCHEMA.THREADS中记录了thread_os_id 找到线程执行的sql
- 根据操作系统id可以到processlist表找到对应的会话
- 在会话中即可定位到问题sql
- 使用show profile观察sql各个阶段耗时
- 服务器上是否运行了其他程序
- 检查一下是否有慢查询
- pref top:使用pref 工具分析哪些函数引发的cpu过高来追踪定位
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oHxCy9GZ-1681639383757)(image-20221106160437906.png)]](https://img-blog.csdnimg.cn/2e84c5f73b5243d489dd9fdc381dc658.png)
2.为什么禁止使用外键:
不得使用外键与级联,一切外键概念必须在应用层解决。
说明:以学生和成绩的关系为例,学生表中的 student_id是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为 级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻 塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
3. 用过processlist吗?
排查mysql的CPU使用率过高时,可以使用show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。
关键的就是state列,mysql列出的状态主要有以下几种:
- Checking table
正在检查数据表(这是自动的)。 - Closing tables
正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。 - Connect Out
复制从服务器正在连接主服务器。 - Copying to tmp table on disk
由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。 - Creating tmp table
正在创建临时表以存放部分查询结果。 - deleting from main table
服务器正在执行多表删除中的第一部分,刚删除第一个表。 - deleting from reference tables
服务器正在执行多表删除中的第二部分,正在删除其他表的记录。 - Flushing tables
正在执行FLUSH TABLES,等待其他线程关闭数据表。 - Killed
发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。 - Locked
被其他查询锁住了。 - Sending data
正在处理Select查询的记录,同时正在把结果发送给客户端。Sending data”状态的含义,原来这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。 - Sorting for group
正在为GROUP BY做排序。 - Sorting for order
正在为ORDER BY做排序。 - Opening tables
这个过程应该会很快,除非受到其他因素的干扰。例如,在执Alter TABLE或LOCK TABLE语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。 - Removing duplicates
正在执行一个Select DISTINCT方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。 - Reopen table
获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。 - Repair by sorting
修复指令正在排序以创建索引。 - Repair with keycache
修复指令正在利用索引缓存一个一个地创建新索引。它会比Repair by sorting慢些。 - Searching rows for update
正在讲符合条件的记录找出来以备更新。它必须在Update要修改相关的记录之前就完成了。 - Sleeping
正在等待客户端发送新请求. - System lock
正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加–skip-external-locking参数来禁止外部系统锁。 - Upgrading lock
Insert DELAYED正在尝试取得一个锁表以插入新记录。= - Updating
正在搜索匹配的记录,并且修改它们。 - User Lock
正在等待GET_LOCK()。 - Waiting for tables
该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, Alter TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。 - waiting for handler insert
Insert DELAYED已经处理完了所有待处理的插入操作,正在等待新的请求。
4. 某个表有数千万数据,查询比较慢,如何优化?说一下思路
- 前端优化 减少查询
- 合并请求:多个请求需要的数据尽量一条sql拿出来
- 会话保存:和用户会话相关的数据尽量一次取出重复使用
- 避免无效刷新
- 多级缓存 不要触及到数据库
- 应用层热点数据高速查询缓存(低一致性缓存)
- 高频查询大数据量镜像缓存(双写高一致性缓存)
- 入口层缓存(几乎不变的系统常量)
- 使用合适的字段类型,比如varchar换成char
- 一定要高效使用索引。
- 使用explain 深入观察索引使用情况
- 检查select 字段最好满足索引覆盖
- 复合索引注意观察key_len索引使用情况
- 有分组,排序,注意file sort,合理配置相应的buffer大小
- 检查查询是否可以分段查询,避免一次拿出过多无效数据
- 多表关联查询是否可以设置冗余字段,是否可以简化多表查询或分批查询
- 分而治之:把服务拆分成更小力度的微服务
- 冷热数据分库存储
- 读写分离,主被集群 然后再考虑分库分表
- 拆表
5. 如果有超大分页改怎么处理?
-
select name from user limit 10000,10;在 使用的时候并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行 -
通过索引优化的方案:
- 如果主键自增可以
select name from user where id > 10000 limit 10; - 我们可以修改为
select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快 - 延迟关联
- 需要order by时
- 一定注意增加筛选条件,避免全表排序
- where -》 order by -》 limit
- 减少select字段
- 优化相关参数避免filesort
- 一定注意增加筛选条件,避免全表排序
- 如果主键自增可以
-
一般大分页情况比较少(很少有人跳转到几百万页去查看数据),实际互联网业务中多数还是按顺序翻页,可以使用缓存提升前几页的查询效率,实际上大多数知名互联网项目也都是这么做的
在阿里巴巴《Java开发手册》中的建议:
【推荐】利用延迟关联或者子查询优化超多分页场景。 说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过 特定阈值的页数进行 SQL 改写。
正例:先快速定位需要获取的 id 段,然后再关联:
SELECT a.* FROM 表 1 a,
(select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
6. mysql服务器毫无规律的异常重启如何排查问题?
首先是查看mysql和系统日志来定位错误
最常见的是关闭swap分区后OOM问题:
mysql 分为应用进程和守护进程
当应用进程内存占用过高的时候操作系统可能会kill掉进程,此时守护进程又帮我们重启了应用进程,运行一段时间后又出现OOM如此反复
可以排查以下几个关键点
- 运行时内存占用率
- mysql buffer相关参数
- mysql 网络连接相关参数
异常关机或kill -9 mysql 后导致表文件损坏
- 直接使用备份
- 配置 innodb_force_recovery 跳过启动恢复过程
7. mysql 线上修改表结构有哪些风险?
针对ddl命令,有以下几种方式
-
copy table 锁原表,创建临时表并拷贝数据
-
inplace 针对索引修改删除的优化,不需要拷贝所有数据
-
Online DDL 细分DDL命令来决定是否锁表
-
可能会锁表,导致无法读写
-
ORM中的映射失效
-
索引失效
建议:建个新表,导入数据后重命名
8. 字段为什么要求定义为not null?
null值会占用更多的字节,且会在程序中造成很多与预期不符的情况,比如错误的使用count(),group等。
9. 如果要存储用户的密码散列,应该使用什么字段进行存储?
密码散列,盐,用户身份证号等固定长度的字符串应该使用char而不是varchar来存储,这样可以节省空间且提高检索效率。
10. 大数据量问题解决
10.1 存在的问题
- 单库太大:数据库里面的表太多,所在服务器磁盘空间装不下,IO次数多CPU忙不过来。
- 单表太大:一张表的字段太多,数据太多。查询起来困难。
10.2 单表问题解决办法:
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
- 限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。(阿里BI数据查询时的方式)
- 限定返回的结果字段:只返回需要的字段
- 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
- 缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
- 分库分表:通过分库分表的方式进行优化,主要有垂直分表和水平分表
10.3 主从复制
主从复制流程:将主数据库中的DDL和DML操作通过二进制日志(BINLOG)传输到从数据库上,然后将这些日志重新执行(重做);从而使得从数据库的数据与主数据库保持一致。
10.3.1 主从复制的作用
- 主数据库出现问题,可以切换到从数据库。
- 可以进行数据库层面的读写分离。
- 可以在从数据库上进行日常备份。
10.3.2 MySQL主从复制解决的问题
- 数据分布:随意开始或停止复制,并在不同地理位置分布数据备份
- 负载均衡:降低单个服务器的压力
- 可用和故障切换:帮助应用程序避免单点失败
- 升级测试:可以用更高版本的MySQL作为从库
10.3.3 MySQL主从复制工作原理
3个线程以及之间的关联:
- 主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
- 从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中;
- 从:sql执行线程——执行relay log中的语句;
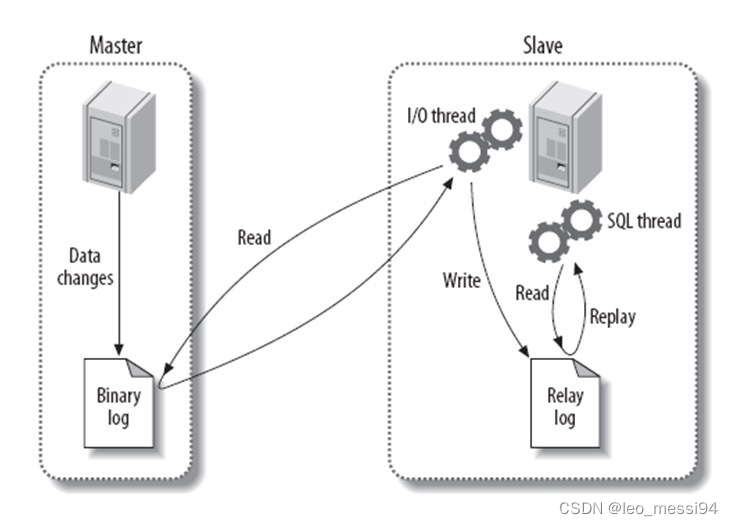
Binary log:主数据库的二进制日志
Relay log:从服务器的中继日志
- master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
- salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
- SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
10.3.4 读写分离有哪些解决方案?
读写分离是依赖于主从复制,而主从复制又是为读写分离服务的。因为主从复制要求slave不能写只能读(如果对slave执行写操作,那么show slave status将会呈现Slave_SQL_Running=NO,此时你需要按照前面提到的手动同步一下slave)。
- 使用mysql-proxy代理
- 优点:直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号,mysql官方不建议实际生产中使用
- 缺点:降低性能, 不支持事务
- 使用AbstractRoutingDataSource+aop+annotation在dao层决定数据源。
- 如果采用了mybatis, 可以将读写分离放在ORM层,比如mybatis可以通过mybatis plugin拦截sql语句,所有的insert/update/delete都访问master库,所有的select 都访问salve库,这样对于dao层都是透明。 plugin实现时可以通过注解或者分析语句是读写方法来选定主从库。不过这样依然有一个问题, 也就是不支持事务, 所以我们还需要重写一下DataSourceTransactionManager, 将read-only的事务扔进读库, 其余的有读有写的扔进写库。
- 使用AbstractRoutingDataSource+aop+annotation在service层决定数据源,
- 可以支持事务.
- 缺点:类内部方法通过this.xx()方式相互调用时,aop不会进行拦截,需进行特殊处理。
10.3.5 读写分离带来的问题
- 写操作拓展起来比较困难,因为要保证多个主库的数据一致性。
- 复制延时:意思是同步带来的时间消耗。
- 锁表率上升:读写分离,命中率少,锁表的概率提升。
- 表变大,缓存率下降:此时缓存率一旦下降,带来的就是时间上的消耗。
注意,此时主从复制还是单库单表,只不过复制了很多份并进行同步。
主从复制架构随着用户量的增加、访问量的增加、数据量的增加依然会带来大量的问题,那就要考虑换一种解决思路。就是分库分表。
10.4 分表
又分为垂直分表和水平分表
10.4.1 垂直分表
根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。
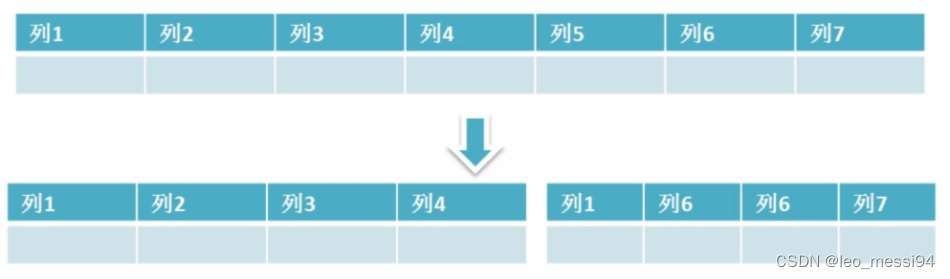
- 优点:
- 适用于一个表中某些列常用,另外一些列不常用
- 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数
- 可以简化表的结构,易于维护
- 缺点:
- 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决
- 会让事务变得更加复杂
- 对于应用层来说,逻辑算法增加开发成本
10.4.2 水平分表
单表的数据量太大。按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。这种情况是不建议使用的,因为数据量是逐渐增加的,当数据量增加到一定的程度还需要再进行切分,比较麻烦。所以 水平拆分最好分库
- 优点:
- 能够支持非常大的数据量存储,应用端改造也少
- 缺点:
- 分片事务难以解决
- 跨界点Join性能较差,逻辑复杂,查询所有数据都需UNION操作
- 在许多数据库应用中,这种复杂度会超过它带来的优点,查询时会增加读一个索引层的磁盘次数
数据库分片(水平拆分)的两种常用方案:
- 客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
- 中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
10.5 分库
10.5.1 垂直分库
一个数据库的表太多。此时就会按照一定业务逻辑进行垂直切,比如用户相关的表放在一个数据库里,订单相关的表放在一个数据库里。注意此时不同的数据库应该存放在不同的服务器上,此时磁盘空间、内存、TPS等等都会得到解决。
10.5.2 水平分库
水平分库理论上切分起来是比较麻烦的,它是指将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
10.6 分库分表之后的问题
- 事务支持:
- 分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
- 跨库join
- 只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。 分库分表方案产品
- 跨节点的count,order by,group by以及聚合函数问题
- 这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
- 数据迁移,容量规划,扩容等问题
- 来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了Sharding扩容的难度。
- ID问题
- 一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由
11. 数据库分布式ID生成策略
分库分表的情况下,保证表中id的全局唯一性
11.1 UUID
UUID 使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。
11.2 雪花算法id
Twitter的分布式自增ID算法Snowflake 在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位 机器ID 10位 毫秒内序列12位。
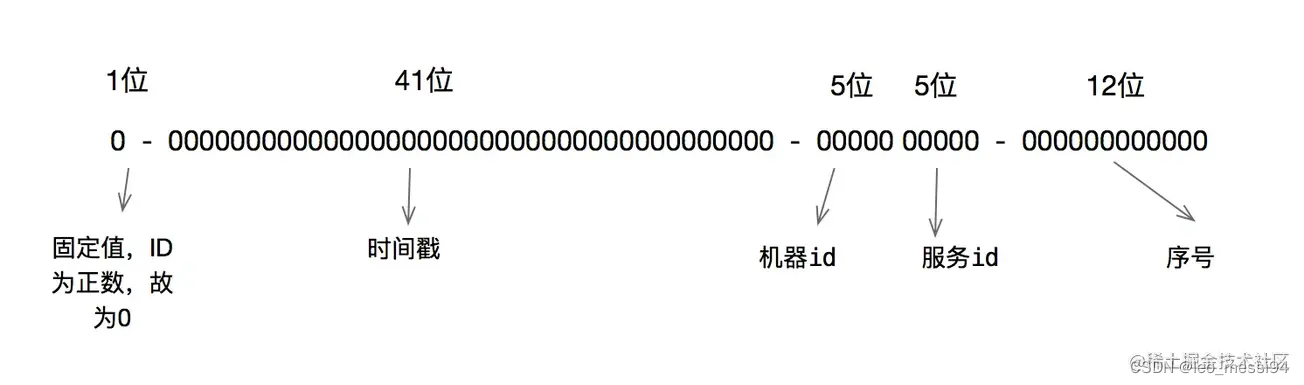
雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
- 最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
- 接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。
- 再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
- 最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
11.2.1 雪花算法优点
- 高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
- 基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
- 不依赖第三方库或者中间件。
- 算法简单,在内存中进行,效率高。
11.2.2 雪花算法缺点
- 依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。