出品人:Towhee 技术团队
超级组合:HuggingFace + ChatGPT = HuggingGPT强势来袭。人类仿佛距离真正的AGI又更近了一步。
HuggingGPT是浙江大学与微软亚洲研究院的联手研究,发布之后迅速引发关注,已经开源。
它的使用非常简单,比如给定一个复杂AI任务,如“请生成一个女孩正在读书的图像,她的姿势与图像example.jpg中的男孩相同。 然后请用您的声音描述新图像。”。HuggingGPT能为你自动分析所需AI模型,直接调用HuggingFace上的对应模型,帮助你执行并完成任务。整个过程中,你只需用自然语言表达需求。它就能帮你自动分析需要哪些AI模型,然后直接去调用HuggingFace上的相应模型,来帮你执行直到完成。
HuggingGPT的核心概念是将语言作为LLMs与其他人工智能模型之间的通用接口。这一创新策略使得LLMs可以调用外部模型,进而解决各种复杂的人工智能任务。HuggingGPT的设计强调了任务规划、模型选择、任务执行和响应生成四个阶段,使得整个系统可以高效地协调不同模型,解决多模态信息和复杂数字智能任务。
-
任务规划:使用ChatGPT分析用户请求以了解其意图,并通过提示将其拆分为可能可解决的任务。 -
模型选择:为了解决计划中的任务,ChatGPT根据模型描述从托管在Hugging Face上的专家模型中选择模型。 -
任务执行:调用和执行每个选择的模型,并将结果返回给ChatGPT。 -
响应生成:最后,使用ChatGPT将所有模型的预测整合起来,并为用户生成答案。

在这个例子里,对于输入的指令,“请生成一个女孩正在读书的图像,她的姿势与图像example.jpg中的男孩相同。 然后请用您的声音描述新图像。”
HuggingGPT在第一步,任务规划中,设计了6个任务,pose-control, pose-to-image, image-class, object-det, image-to-text, text-to-speech,并安排了它们的依赖关系。第二步中,ChatGPT根据模型描述从候选在huggingface上的专家模型中选择模型,它们可能是在线的,可能是下载的。第三步,代码去真正执行对应的huggingface上的专家模型。第四步,将所有模型的预测整合起来,并为用户生成最后的返回。可以看到,确实就是去找了姿态相关的模型,生成了一个同样姿态的小女孩读书的图像,真的是非常神奇。
HuggingGPT已经在Hugging Face上成功集成了数百个模型,覆盖了24个任务,例如文本分类、目标检测、语义分割、图像生成、问答、文本转语音和文本转视频。实验结果证明了HuggingGPT在处理多模态信息和复杂人工智能任务方面的强大能力,为实现先进人工智能开辟了新的道路。
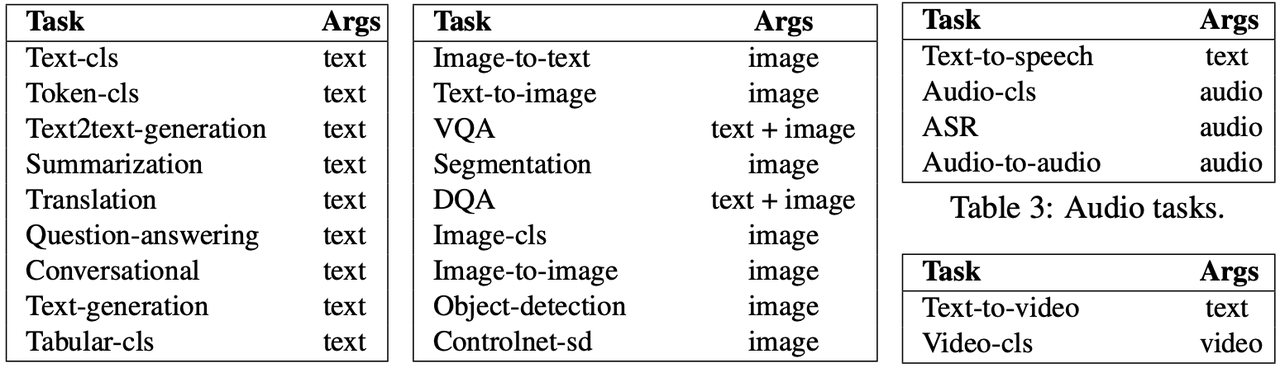
下面放几个论文中的例子,可以看到,对于各种模态组合的复杂任务,HuggingGPT都处理得很好:
 <生成一个名为“宇航员在太空中行走”的视频,并加上配音。
<生成一个名为“宇航员在太空中行走”的视频,并加上配音。
 <给定一组图片A:/examples/a.jpg,B:/examples/b.jpg,C:/examples/c.jpg,请问这些图片中有几只斑马?
<给定一组图片A:/examples/a.jpg,B:/examples/b.jpg,C:/examples/c.jpg,请问这些图片中有几只斑马?
目前在 huggingface官网上已经开放了gradio试用:https://huggingface.co/spaces/microsoft/HuggingGPT,大家可以快去试试。
当然,HuggingGPT也有一些短板。比如效率,效率的瓶颈在于大型语言模型的推理。对于每一轮用户请求,HuggingGPT在任务规划、模型选择和响应生成阶段至少需要与大型语言模型进行一次交互。这些交互大大增加了响应延迟,导致用户体验下降。第二个限制是最大上下文长度。受限于LLM能接受的最大标记数量,HuggingGPT也面临着最大上下文长度的限制。它使用了对话窗口,在任务规划阶段仅跟踪对话上下文以减轻这一限制。第三个是系统稳定性,包括两个方面。一个是大型语言模型推理过程中出现的反叛现象。大型语言模型在推理过程中偶尔无法遵循指示,输出格式可能不符合预期,导致程序工作流中的异常。第二个是Hugging Face推理的专家模型的不可控状态。Hugging Face上的专家模型可能受到网络延迟或服务状态的影响,导致任务执行阶段出错。
相关资料:
-
项目地址:https://github.com/microsoft/JARVIS
-
相关论文:
-
https://arxiv.org/abs/2303.17580
-
本文由 mdnice 多平台发布