以下来自湖科大计算机网络公开课笔记及个人所搜集资料
目录
- 一、拥塞控制与流量控制
- 1.1 拥塞控制的目的
- 1.2 区分拥塞控制与流量控制
- 二、四种拥塞控制算法
- 2.1 慢开始和拥塞避免
- 2.2 快重传
- 2.3 快恢复
一、拥塞控制与流量控制
1.1 拥塞控制的目的
先看一下什么是拥塞:
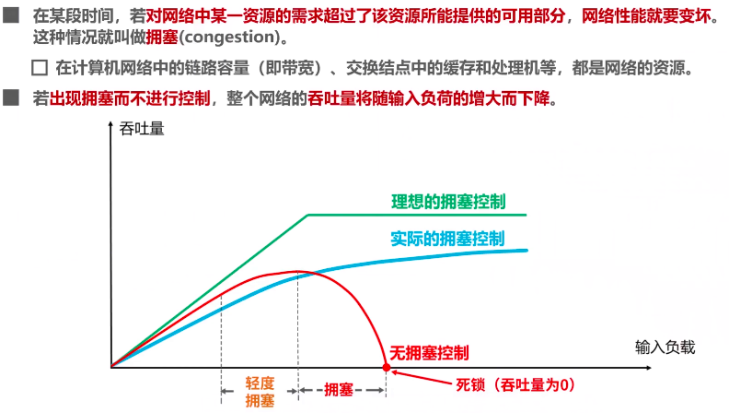
上图中,绿线,理想的拥塞控制,在吞吐量达到饱和之前,网络吞吐量应等于所输入的负载,那么随着输入负载逐渐增大,吞吐量也等比增大。但当输入负载超过某一限度时,由于网络资源受限,吞吐量就不再增长,而保持水平线,也就是吞吐量达到饱和,这就表明输入的负载中有一部分损失掉了——即理想的拥塞控制也一样会损失负载,毕竟网络的可用资源是固定的。
先看红线,无拥塞控制,则不会是等比的45度斜线,而是在网络吞吐量还未达到饱和时,就已经有一部分的输入分组被丢弃了;当网络的吞吐量明显的小于理想的吞吐量时,网络就进入了轻度拥塞的状态;当输入负载到达某一数值时,网络的吞吐量反而随输入负载的增大而减小,这时网络就要进入了拥塞状态,当输入负载继续增大到某一数值时,网络吞吐量减小为零,此时网络就要无法工作了,这就是所谓的死锁!!!
实际的拥塞控制效果应该接近理想的,因此得到中间蓝色线。
即我们需要对红色线往下掉的位置进行控制,使其达到蓝色线的效果。
为什么无拥塞控制会出现输入负载增大而网络吞吐量减小的现象?(上图红色线)
试想一下,在网络已经出现轻度拥塞时,如果依然发送大量的数据包,那么数据到达时延和丢失的概率就会增大,这个时候由于超时重传机制,发送方需要重传没有按期达到的数据,这样网络上的数据就更多了,网络的负担也就增大了(拥塞程度增加),而更大的拥塞程度又使得数据更容易延时达到或丢失,从而进入恶性循环:
延时/丢失 ——> 重传——>延时/丢失——>重传…
1.2 区分拥塞控制与流量控制
流量控制解决的是TCP收发双方速度不同而导致的数据丢失问题,流量控制要达到的目的是让接收方不会来不及处理;而拥塞控制是防止发送方这边把过多数据输送到网络。
直观的区别是:
两者的窗口控制都是针对数据的发送方,但是流量控制是为了接收方,而拥塞控制是为了网络。
两者都是基于滑动窗口实现的,但流量控制的窗口调整是由接收方来对发送方进行调控的;拥塞控制的窗口调整是由拥塞控制算法来对发送方进行调控的。
两者的联系:
前面在流量控制那节说过:
发送方的发送窗口 = min(自身拥塞窗口,TCP接收方的接收窗口)
二、四种拥塞控制算法
前面讨论流量控制时不考虑拥塞控制,那么下面讨论拥塞控制时也不考虑流量控制
四种算法:
慢开始(slow-start)、拥塞避免(congestion avoidance)、快重传(fast retransmit)、快恢复(fast recovery)
2.1 慢开始和拥塞避免
这两个是最早的算法,被称为TCP Tahoe版本;后面又增加了快重传和快恢复进行改进,称为TCP Reno版本。
有几点注意:
-
拥塞窗口控制值cwnd是多少,就能一次性发送多少数据报文段(即多少个TCP数据报文),在讨论拥塞控制中,发送方仅将拥塞窗口作为发送窗口,动态变化。
在讨论流量控制时,我们用的单位是字节,而讨论拥塞控制时用的单位是MSS,这个其实后者可以转换成字节,比如这篇帖子里,说一个MSS大约是1KB(即使局域网和internet中的MSS不一样大),因此它的拥塞控制示意图里是以1KB为单位。 -
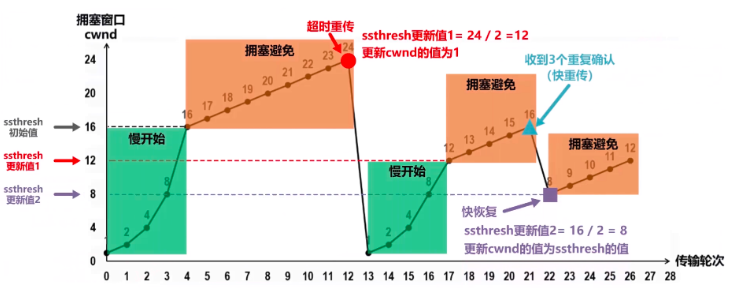
从慢开始算法到拥塞避免算法。其实大致原理就是:TCP不是每次都发送一样数量的报文,而是逐渐增多的,这样才是有对拥塞进行控制。一开始发送方能发的报文段数量都比较小(这个是慢开始的含义,开始可发送报文数量少,而不是增长慢),这个时候可以按照慢开始算法,以指数增长(比如翻倍)来主键增大cwnd,也是一次能发送的报文段数量;当数量达到设置的慢开始门限值cwnd 16时候,认为这个时候一次发送的报文数量有点大了,就要注意了,此时换拥塞避免算法,不再成倍增长每次发送的数据报文段(这个是通过调整cwnd),而是比如每次增加1个,上次可以发16,下次可以发17……
-
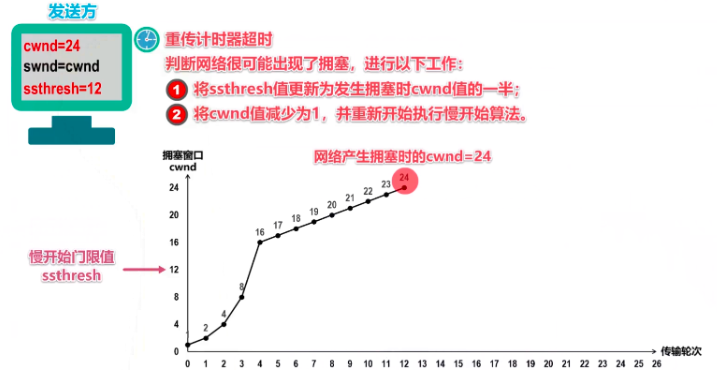
在本例中,如果cwnd=24,即每次可发送的报文段数量达到24时,有些报文丢失了,接收方没收齐。那么发送方就会对这些丢失报文段开启超时重传(这个数据链路都有的协议),并且判断这个时候出现网络拥塞了。这个时候就要做两件事:
- 将慢开始门限减小为此时cwnd的一半,即24/2 == 12
- 将cwnd直接减小为1(此时一次只能发1个TCP报文段了),重新开始慢开始算法
注意下图中,横坐标是传输轮次,即发送方发了多少次TCP报文
图中的纵坐标1,24这些数字是MSS的数量,即TCP最大报文段的数量;
横坐标每个传输轮次是指一个来回,发送出去并且得到了对方的确认报文。
所以下图每个点就是一个轮次传输多少个TCP分段。
调控后如下:
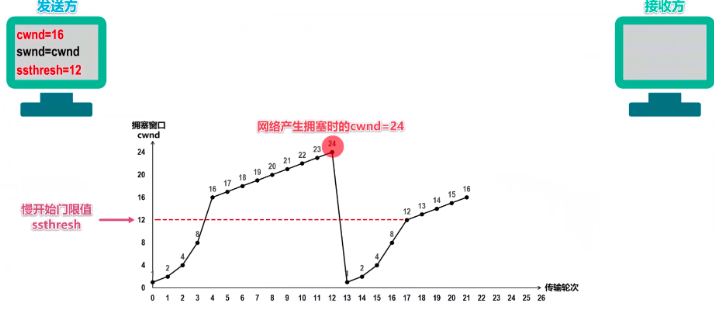
整个过程如下图:
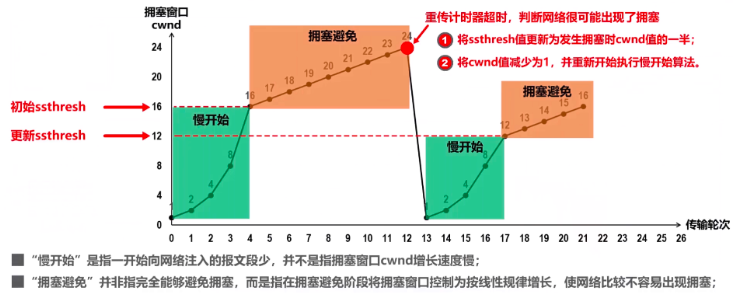
上面的漏洞就是,报文丢失就说明网络拥塞了????
显然不是,有时候丢失了个别报文段,但实际上网络并未发生拥塞!而且这种把窗口又改为1的行为,大大降低了传输效率
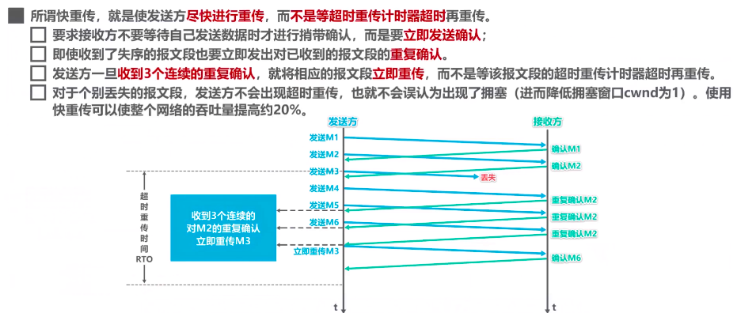
2.2 快重传
这个对上面的改进在于,别等超时重传计时器超时再重传,而是尽快重传。因为之前等超时重传,会误以为是网络发生了拥塞,而快重传就不会触发超时重传,就不会误认为是发生了拥塞(说明发生拥塞的判断是触发了超时重传)
需要接收方发送3次重复确认,发送方再立即重传。这个重复确认是说我收到了报文,并不是说收到了准确的报文,不然也不需要重传了,比如收到的是乱序的,就给发送方说我收到报文,但是不是我要的3号报文段(这说明3号报文段丢失了)。
2.3 快恢复
不止快重传加入了,快恢复算法也同时起作用。它是将慢开始门限和拥塞窗口cwnd都调整为当前拥塞窗口的一半,然后执行拥塞避免算法,而不是重新搞慢开始算法直接掉到1——不搞慢开始了,直接拥塞避免,1个字节
也有的快恢复实现,是把快恢复开始时的拥塞窗口值再增大一些,等于新的慢开始门限值+3。这样做的理由是:
- 既然发送方收到三个重复的确认,就要表明有三个数据报文段已经离开了网络,
- 这三个报文段不再消耗网络资源,而是停留在接收方的接收缓存中。
- 可见现在网络中不是堆积的报文段,而是减少了三个报文段,因此可以适当把用塞窗口值扩大一些。
最后,TCP拥塞控制算法作用过程如下:
主要看右边第二个绿色框开始: