博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
背景介绍
什么是目标检测
目标检测的难点
目标检测的基础知识
候选框
交并比
非极大值抑制
传统目标检测基本流程
目标检测效果评估
背景介绍
目标检测作为计算机视觉中承上启下的一步,至关重要,可以说,实现了目标检测就实现了计算机视觉基本任务。目标检测急需要对物体进行识别,又要检测出物体的位置,难度较大,网络结构也层出不穷,在深度领域,从R-CNN到SPP-NET再到YOLO最后到SSD,可以说是百家争鸣,各有千秋。
另一方面,目标检测应用非常广泛,例如生活中常见的人脸检测、车牌识别等;在自动驾驶领域,有行人识别、车道线识别;还有智能视频监控、机器人导航、飞机航拍等多种多样的应用。
目标检测可以分解为两个步骤,第一个步骤是寻找物体框的位置,有传统的选择搜索算法,也有基于深度学习的方法;第二个步骤就是对物体框的类别进行判别。所以,目标检测算法也分为一阶段算法和二阶段算法两种。如果将两个步骤分两个网络训练,则称其为二阶段算法,反之,如果将两个步骤合并用一个网络训练,则称其为一阶段算法。本节我们会详细介绍两阶段目标检测算法,下一节我们继续介绍一阶段目标检测算法。
什么是目标检测
对于目标检测,不但要识别处物体的位置,还要检测处物体的类别。一般来说,我们用把一个矩形框来外接一个物体。我们要做的就是检测出这个矩形框(也叫groundtruth)的位置参数,例如中心坐标(x,y),矩形框宽w和矩形框的高h等。
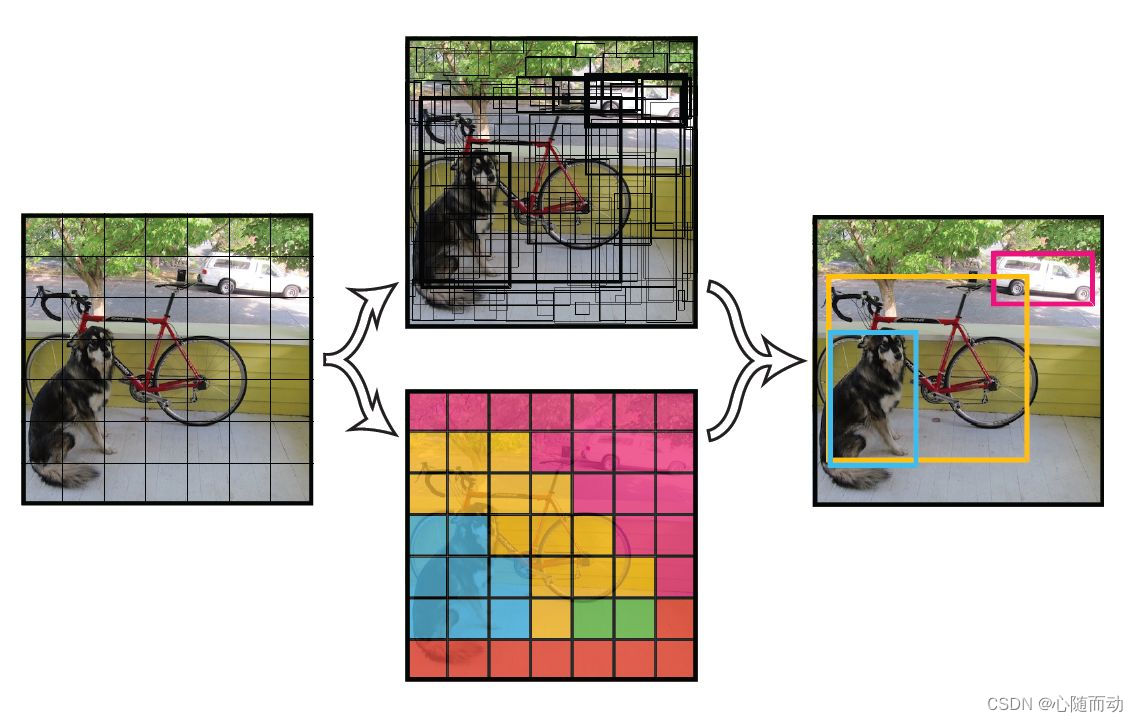
目标检测的难点
对于识别物体来说,难度不大,在目标识别方面,卷积神经网络的正确率已经超过人类的识别水准了,但是想要精确的定位物体,却是非常困难的,我们人类判断照片上人物的位置一般就是说在中间,或者左上等位置名词,但是对于计算机来说,就有点困难,他需要精确的位置坐标。
更难的是,一张图片中往往有多个物体,特别是小物体,在做目标识别的时候,我们对一张图片只需要输出一个物体,而对于检测问题,需要输出多个物体,难度也极具增大。
最后,网络速度和准确率很难兼顾,一般来说,速度较快的网络,也就是每秒能处理的图片较多,效果就会较差,这是由于速度快的网络会降低物体位置的精度,同时也会减少候选框的数量。
目标检测的基础知识
在进行目标检测实战项目前,我们先来了解一下目标检测的基础知识。
候选框
什么是候选框:候选框就是有可能存在物体的框,对于一个物体来说,可能有很多的候选框,一般5~9个都是正常的。对于二阶段目标检测算法,一般候选框生成算法会生成几千个候选框,但是真正有物体的候选框可能就很少了。

交并比
我们有这么多候选框,那么我们如何判断一个候选框的好坏?很明显,与真实物体框越接近,候选框就越好。我们一般用交并比(IOU)来表示候选框的好坏,计算方式:
IOU=(物体框∩候选框)的面积/(物体框∪候选框)的面积。
为什么我们不直接用物体框和候选框的交集2的面积喃?这是因为,对于覆盖整个物体框的候选框,物体框和候选框的交集的面积都为物体框的面积,从而不能区分出优劣。同理也不能直接使用物体框和候选框的并集的面积,否则无法区分小于物体框的候选框的优劣,而同时考虑两者,就能得到比较好的标准。

非极大值抑制
非极大值抑制(NMS),就是对交并比进行抑制,也就是对交并比不是极大值的值进行抑制。举个例子,对于同一个物体,模型检测出三个候选框,交并比分别为0.9,0.8,0.7,那么我们只需要保留交并比为0.9的框,而忽略其他几个。
当然,非极大值抑制并不是这么的简单,比如第一个物体被检测出的交并比为0.9,0.8,0.7,留下0.9的框,第二个物体检测出0.7,0.6,保留0.7的框,这个时候就会出现一个问题,那就是两次处理后得到的候选框都是第一个物体的,会删除第二个物体的候选框,所以一般我们会进行设置阈值(一般为0.3~0.5),只要两个候选框IOU值大于阈值时,认为他们属于同一个物体,对他们进行非极大值抑制即可。
具体流程:
(1)、在候选框列表中选出IOU最大的候选框1;
(2)、将其余候选框与候选框1计算IOU';
(3)、如果IOU'>阈值,则次候选框删除;
(4)、将候选框1输出,然后从候选框列表中删除。
(5)、重复流程(1)~(4)。
传统目标检测基本流程
我们在学习深度学习方法前,先来了解一下传统的目标检测流程,
第一步,提取候选框,最初的时候,我们采用的是滑动窗口的策略,使用一个窗口在整幅图上进行滑动,每次滑动就生成一个候选框,而且对于滑动窗口设置不同的尺寸。这种暴力的策略虽然包含了目标所有可能出现的位置,但是由于冗余窗口太多,导致时间复杂度太高。
第二步就是提取特征值,常用SIFT,SURF,HOG等特征检测算法。
第三步就是训练分类器,主要有SVM,Adaboost等常用的分类器,对提取的物体特征进行分类 ,从而识别物体。
最后一步就是进行非极大值抑制,删除多余的候选框。
目标检测效果评估
对于评估检测准确率,我们使用准确率和精准率,对于评估模型是否将图像中所有的图像都是别出来,我们称之为召回率。
准确率=
精准率=
召回率=
这些参数代表什么意思喃?
我们来看看二分类:
| 标签 | 预测为1(预测有物体) | 预测为0(预测无物体) |
| 1(存在物体) | 真正(TP) | 假负(FN) |
| 0(不存在物体) | 假正(FP) | 真负(TN) |
当我们的二分类器设定的阈值发生变化时,准确率和召回率也会跟着变化。所以我们不能简单地使用单一的召回率或准确率来评价整个模型,而需要考虑在不同召回率阈值下模型的效果。
我们将在不同召回率阈值下模型能够达到的最大精准率看成一个点,然后将这些点连接起来,我们称之为Precision-Recall曲线。

显然,曲线下面的面积越大,模型效果越好,于是我们将此面积作为二分类器的评价标准,称为平均精度(AP)。需要注意的是,PR曲线和我们常用的另一个概念ROC曲线是不同的,ROC曲线显示的是真正率和假正率的关系,而PR曲线显示的是精确率和召回率的关系,PR曲线更适合评估目标检测这类样本不平衡的问题。
对于目标检测这种多分类问题,我们如何评价模型喃?我们剋将其看成很多二分类器的叠加,其对每个物体分类就是一个二分类器,我们先算出每个物体分类的平均精度,之后再对所有的分类取平均(或加权平均),即可得到平均精度均值(mAP),这也是我们常用的目标检测分类问题的评价指标。
对于模型速度的评价就要简单许多,一般用处理一张图片要多少时间,或者说单位时间能处理多少图片,学名叫做帧/秒(fps)。
| 框架名称 | mAP(VOC2007数据集) | 速度/(帧/秒) | 速率/(秒/帧) |
| DPMv5 | 33.7 | 0.07 | 14 |
| R-CNN | 66.0 | 0 | 20 |
| Fast R-CNN | 70.0 | 0.5 | 2 |
| Faster R-CNN | 73.2 | 7 | 0.14 |
| YOLO | 63.4 | 45 | 0.022 |
| YOLOv2 | 78.6 | 40 | 0.025 |
| SSD | 76.8 | 19 | 0.053 |
好了,本节内容介绍就到此结束了,拜拜了你嘞!