一.Nginx 缓存管理
在 Nginx 中自带将后端应用中图片、CSS、JS 等静态资源缓存功能,
我们只需在 Nginx 的核心配置 nginx.conf 中增加下面的片段,
便可对后端的静态资源进行缓存,关键配置我已做好注释,
可以直接使用;
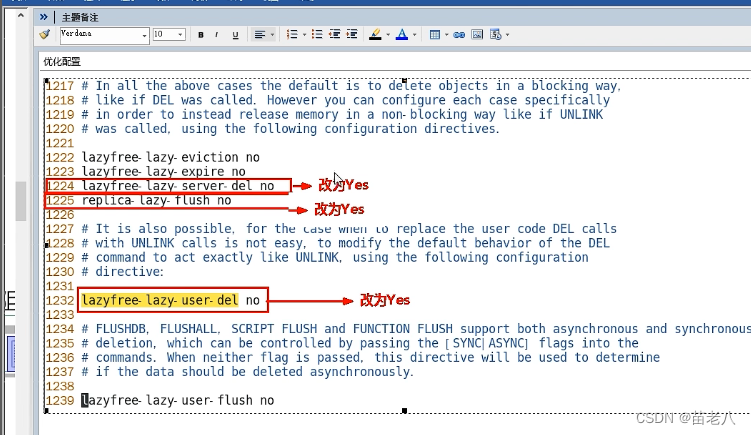
# 设置缓存目录
# levels代表采用1:2也就是两级目录的形式保存缓存文件(静态资源css、js)
# keys_zone定义缓存的名称及内存的使用,名称为babytun-cache ,在内存中开始100m交换空间
# inactive=7d 如果某个缓存文件超过7天没有被访问,则删除
# max_size=20g;代表设置文件夹最大不能超过20g,超过后会自动将访问频度(命中率)最低的缓存文件删除
proxy_cache_path d:/nginx-cache levels=1:2 keys_zone=babytun-cache:100m inactive=7d max_size=20g;
#配置xmall后端服务器的权重负载均衡策略
upstream xmall {
server 192.168.31.181 weight=5 max_fails=1 fail_timeout=3s;
server 192.168.31.182 weight=2;
server 192.168.31.183 weight=1;
server 192.168.31.184 weight=2;
}
server {
#nginx通过80端口提供Web服务
listen 80;
# 开启静态资源缓存
# 利用正则表达式匹配URL,匹配成功的则执行内部逻辑
# ~* 代表URL匹配不区分大小写
location ~* \.(gif|jpg|css|png|js|woff|html)(.*){
# 配置代理转发规则
proxy_pass http://xmall;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_cache xmall-cache;
#如果静态资源响应状态码为200(成功) 302(暂时性重定向)时 缓存文件有效期1天
proxy_cache_valid 200 302 24h;
#301(永久性重定向)缓存保存5天
proxy_cache_valid 301 5d;
#其他情况
proxy_cache_valid any 5m;
#设置浏览器端缓存过期时间90天
expires 90d;
}
#使用xmall服务器池进行后端处理
location /{
proxy_pass http://xmall;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
增加上面配置后,每一次通过 Nginx 访问应用中新的静态文件时,
在 Nginx 服务的缓存目录便会生成缓存文件,在缓存有效期内该静态资源的请求便不再送到后端服务器,而直接由 Nginx 读取本地缓存并返回。
二.分布式缓存服务
在架构设计时,很多新架构师一听到缓存,
下意识认为增加 Redis 分布式缓存服务器就够了,其实这是片面的做法。在缓存架构设计时,
一定要按照由近到远、由快到慢的顺序进行逐级访问。假设在电商进行商品秒杀活动时,
如果没有本地缓存,所有商品、订单、物流的热点数据都保存在 Redis 服务器中,
每完成一笔订单,都要额外增加若干次网络通信,
网络通信本身就可能由于各种原因存在通信失败的问题。
即便是你能保证网络 100% 可用,
但 Redis 集群承担了来自所有外部应用的访问压力,
一旦突发流量超过 Redis 的负载上限,整体架构便面临崩溃的风险。
因此在 Java 的应用端也要设计多级缓存,我们将进程内缓存与分布式缓存服务结合,
有效分摊应用压力。在 Java 应用层面,
只有 EhCache 的缓存不存在时,再去 Redis 分布式缓存获取,
如果 Redis 也没有此数据再去数据库查询,
数据查询成功后对 Redis 与 EhCahce 同时进行双写更新。
这样 Java 应用下一次再查询相同数据时便直接从本地 EhCache 缓存提取,
不再产生新的网络通信,应用查询性能得到显著提高。

保障缓存一致性
但事无完美,当引入多级缓存后,我们又会遇到缓存数据一致性的挑战,以下图为例:

我们都知道作为数据库写操作,是不通过缓存的。
假设商品服务实例1将1号商品价格调整为80元,
这会衍生一个新问题:如何主动向应用程序推送数据变更的消息来保证它们也能同步更新缓存呢?
相信此时你已经有了答案。
没错,我们需要在当前架构中引入 MQ 消息队列,
利用 RocketMQ 的主动推送功能来向其他服务实例以及 Redis 缓存服务发起变更通知。

如上图所示,在商品服务实例 1 对商品调价后,
主动向 RocketMQ Broker 发送变更消息,Broker 将变更信息推送至其他实例与 Redis 集群,
这些服务实例在收到变更消息后,在缓存中先删除过期缓存,再创建新的数据,以此保证各实例数据一致。
在我看来,有三种情况特别适合引入多级缓存。
第一种情况
缓存的数据是稳定的。例如邮政编码、地域区块、
归档的历史数据这些信息适合通过多级缓存减小 Redis 与数据库的压力。
第二种情况
瞬时可能会产生极高并发的场景。例如春运购票、双 11 零点秒杀、股市开盘交易等,
瞬间的流量洪峰可能击穿 Redis 缓存,产生流量雪崩。这时利用预热的进程内缓存分摊流量,减少后端压力是非常有必要的。
第三种情况
一定程度上允许数据不一致。例如某博客平台中你修改了自我介绍这样的非关键信息,
此时在应用集群中其他节点缓存不一致也并不会带来严重影响,
对于这种情况我们采用 T+1 的方式在日终处理时保证缓存最终一致就可以了。