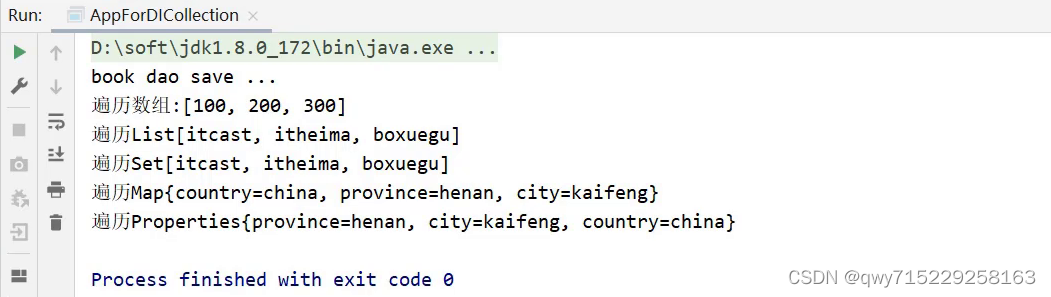
数据集中的Usenet公告板包括新汽车,体育和密码学等主题。最近我们被客户要求撰写关于主题建模的研究报告,包括一些图形和统计输出。我们对20个Usenet公告板的20,000条消息进行分析。
相关视频:文本挖掘:主题模型(LDA)及R语言实现分析游记数据
文本挖掘:主题模型(LDA)及R语言实现分析游记数据
时长12:59
预处理
我们首先阅读20news-bydate文件夹中的所有消息,这些消息组织在子文件夹中,每个消息都有一个文件。
raw_text## # A tibble: 511,655 x 3
## newsgroup id text
## <chr> <chr> <chr>
## 1 alt.atheism 49960 From: mathew <mathew@mantis.co.uk>
## 2 alt.atheism 49960 Subject: Alt.Atheism FAQ: Atheist Resources
## 3 alt.atheism 49960 Summary: Books, addresses, music -- anything related to atheism
## 4 alt.atheism 49960 Keywords: FAQ, atheism, books, music, fiction, addres
## # … with 511,645 more rows请注意该newsgroup列描述了每条消息来自哪20个新闻组,以及id列,用于标识该新闻组中的消息。
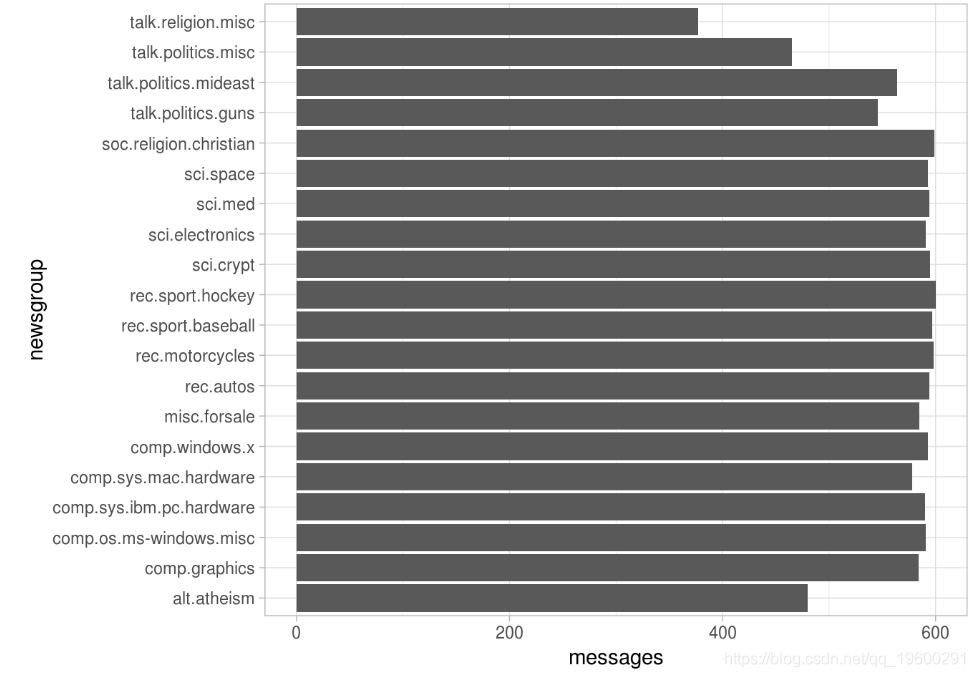
tf-idf
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。我们希望新闻组在主题和内容方面有所不同,因此,它们之间的词语频率也不同。
newsgroup_cors## # A tibble: 380 x 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 talk.religion.misc soc.religion.christian 0.835
## 2 soc.religion.christian talk.religion.misc 0.835
## 3 alt.atheism talk.religion.misc 0.779
## 4 talk.religion.misc alt.atheism 0.779
## 5 alt.atheism soc.religion.christian 0.751
## 6 soc.religion.christian alt.atheism 0.751
## 7 comp.sys.mac.hardware comp.sys.ibm.pc.hardware 0.680
## 8 comp.sys.ibm.pc.hardware comp.sys.mac.hardware 0.680
## 9 rec.sport.baseball rec.sport.hockey 0.577
## 10 rec.sport.hockey rec.sport.baseball 0.577
## # … with 370 more rows

主题建模
LDA可以整理来自不同新闻组的Usenet消息吗?

主题1当然代表sci.space新闻组(因此最常见的词是“空间”),主题2可能来自密码学,使用诸如“密钥”和“加密”之类的术语。
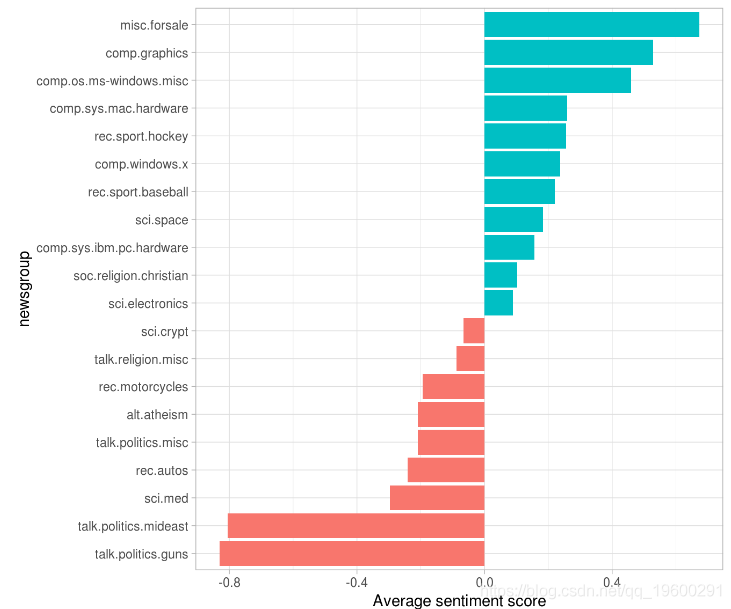
情绪分析
我们可以使用我们 探讨的情绪分析技术来检查这些Usenet帖子中出现的正面和负面词的频率。哪些新闻组总体上最积极或最消极?
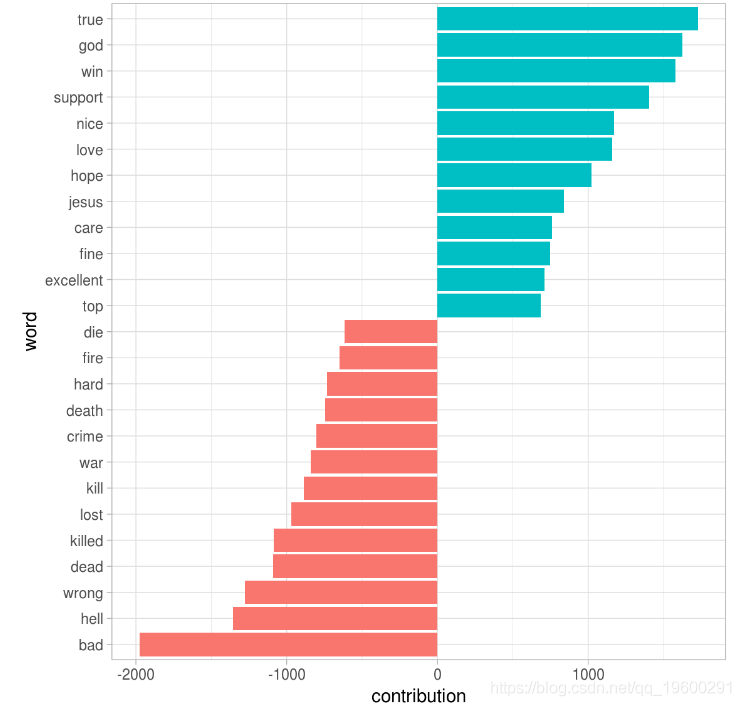
在这个例子中,我们将使用AFINN情感词典,它为每个单词提供积极性分数,并用条形图可视化
用语言分析情绪
值得深入了解为什么有些新闻组比其他新闻组更积极或更消极。为此,我们可以检查每个单词的总积极和消极贡献度。
N-gram分析
Usenet数据集是一个现代文本语料库,因此我们会对本文中的情绪分析感兴趣.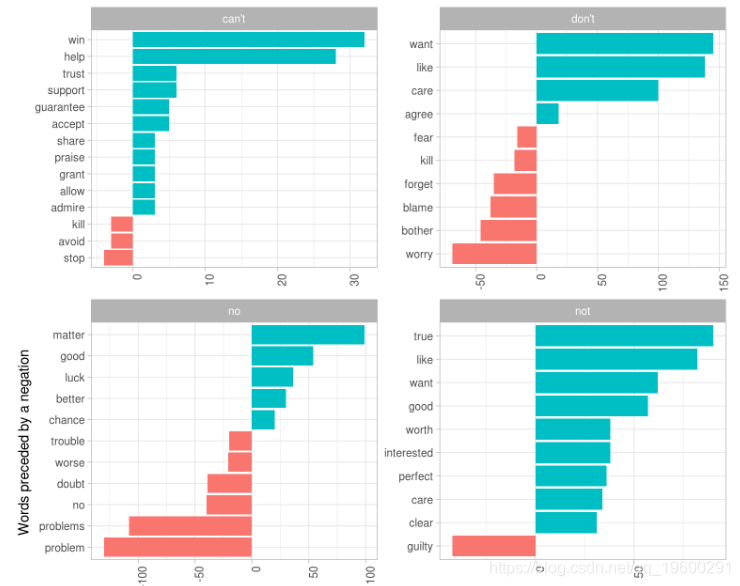






![24. [Python GUI] PyQt5中的模型与视图框架-表格部件QTableWidget](https://img-blog.csdnimg.cn/img_convert/c7c8786bf7c4316a7ba9d65b6d02d828.png)