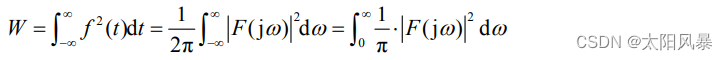目录
一.引言
二.LR 多分类分析
三.LR 多分类实战
1.数据准备 Comment -> RDD -> DF
2.数据处理 JieBaTokenizer -> HashingVector
3.模型训练 LR
4.模型评估 Metrics
5.人工校验 DIY
四.总结
一.引言
Spark 3.0 - 5.ML Pipeline 实战之电影影评情感分析 通过 LR 二分类实现了影评的情感分析,我们主观的将 <= 🌟🌟🌟 的影评标记为 Label=0 即负向评论,>= 🌟🌟🌟🌟 的标记为 Label=1 即正向评论,有失偏颇,本文通过 LR 实现多分类预测影评对应的真实评论分数。
二.LR 多分类分析
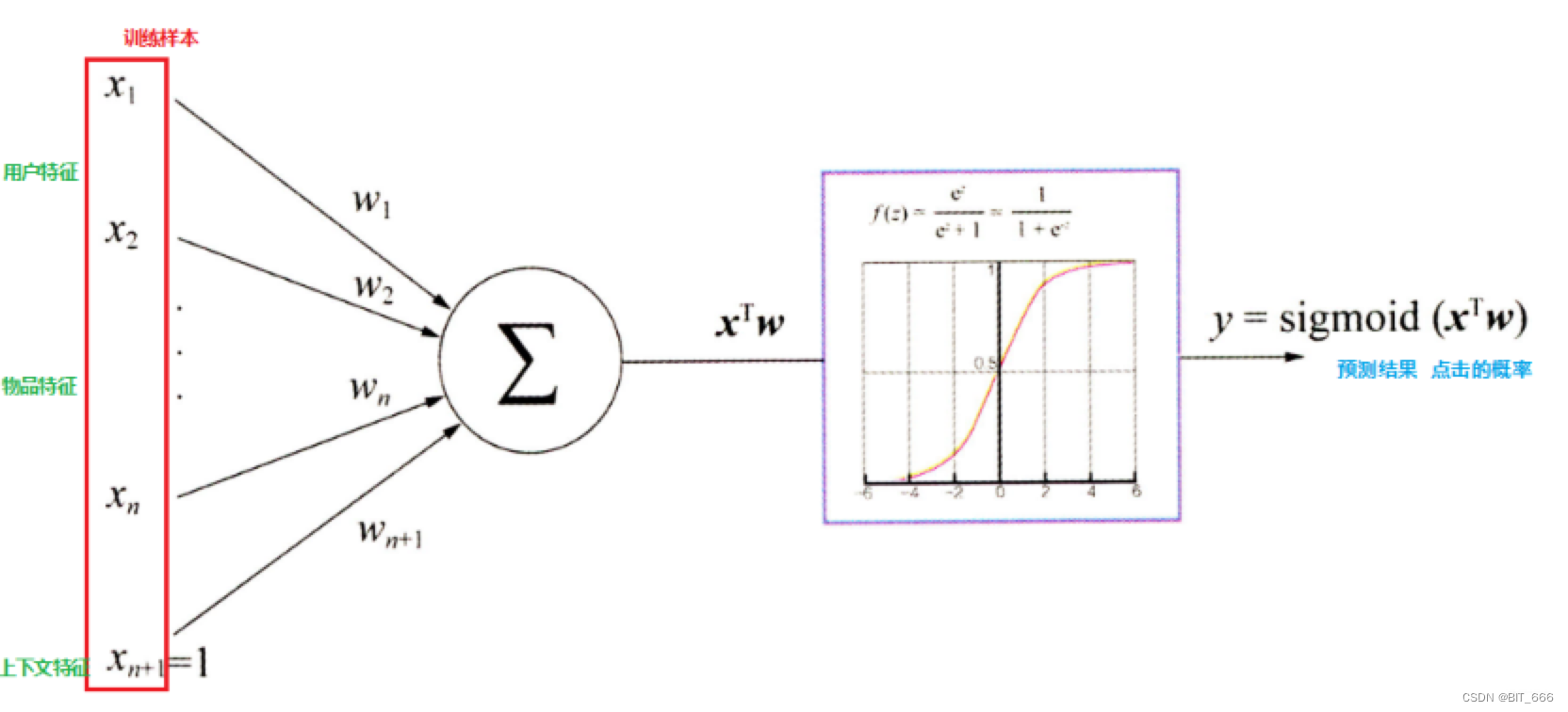
LR 二分类问题主要通过样本训练 weights 与 bias,最终将 xTw + b 送到 sigmoid 得到概率值,再通过阈值决定该样本为哪一类,LR 多分类可以看作是多个二分类 LR 的合并:
- 针对每个类别训练得到一个 weight 参数与 bias 参数
- 每个类别对应的 LR 模型分别预测当前样本的概率值
- 取概率值最大的 LR 模型对应的类别作为当前预测样本的类别
整个过程可以看到集成学习、投票法的一些影子,以电影影评预测电影评分为例,我们共有 6个类别分别对应 0 x 🌟 到 🌟🌟🌟🌟🌟,按词库 20000 计算,则训练生成一个 20000 x 6 的参数矩阵以及 1 x 6 的 bias 偏置,通过 Matrix 与 Bias 即可预测新的样本。
其中 1 代表 1 x Bias,前面 wTx 即可。
三.LR 多分类实战
通过 Comment -> RDD -> DF -> JieBaTokenizer -> HashingVector -> LR 的流程实现数据的预处理与训练,再通过得到的 LrModel 实现 Predict。
1.数据准备 Comment -> RDD -> DF
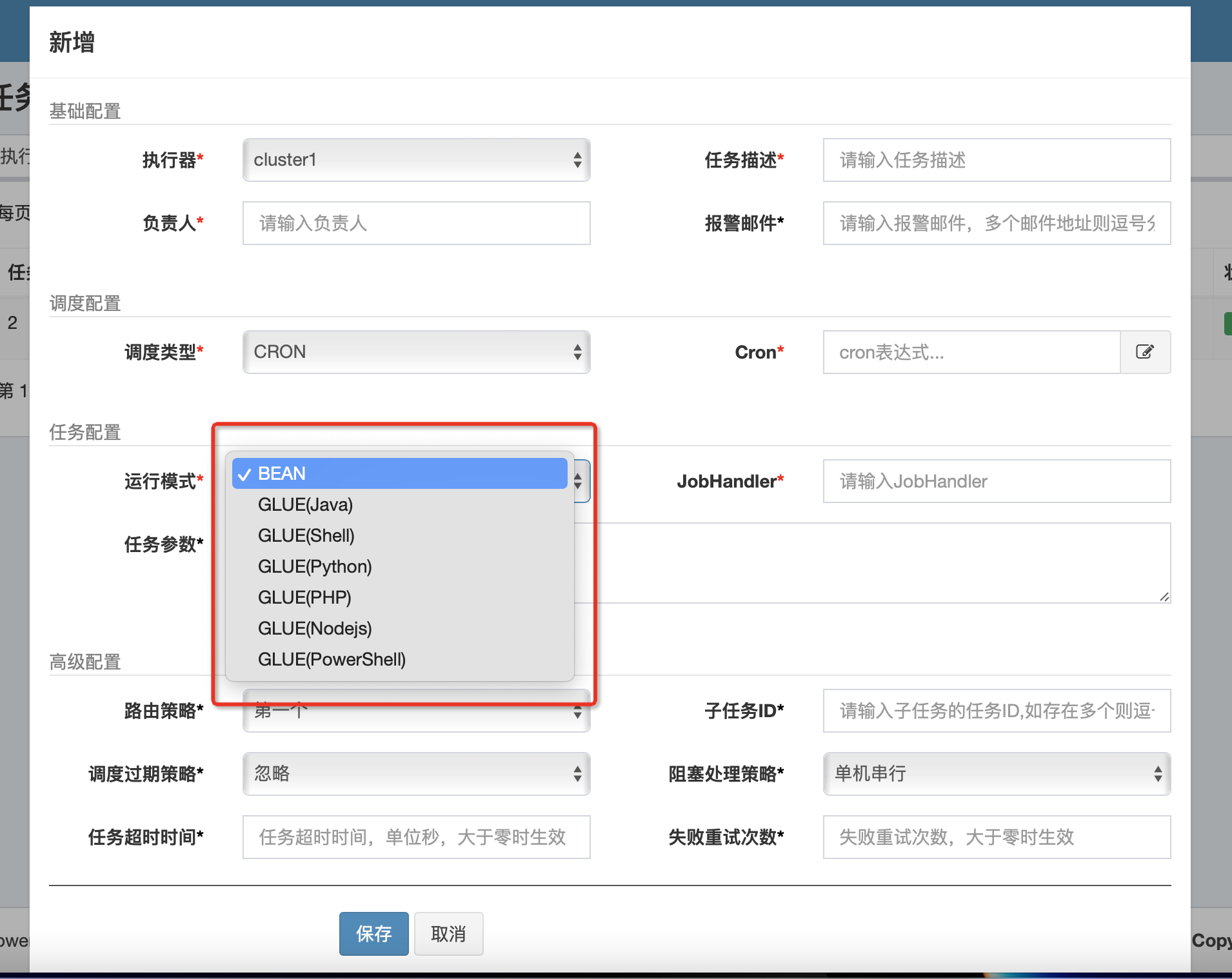
原始数据样式为:

通过 spark 读取该数据得到 movie、score 与 comment 三个字段的 DF,由于 Model.fit 需要 label 列,所以 score 列采用 label 为列名:
val spark = SparkSession
.builder //创建spark会话
.master("local") //设置本地模式
.appName("MultiClassify") //设置名称
.getOrCreate() //创建会话变量
spark.sparkContext.setLogLevel("error")
val inputPath = "./DouBanComment"
val commentAndLabel = spark.sparkContext.textFile(inputPath).mapPartitions(partition => {
partition.map(line => {
try {
val info = line.split("##")
val movieName = info(0)
val label = info(1).toDouble
val comment = info(2)
(movieName, label, comment)
} catch {
case _: Throwable =>
null
}
})
}).filter(_ != null)
val data = spark.createDataFrame(commentAndLabel)
.toDF("movie", "label", "comment")2.数据处理 JieBaTokenizer -> HashingVector
通过 JiebaTokenizer 将影评进行分词,通过 HashingTF 实现向量化,最后将 hashData 通过 randomSplit 方法划分为训练集与数据集,为了每次输出结果相同,这里使用了固定的 seed。
val jiebaTonkenizer = new JiebaTokenizer()
.setInputCol("comment")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(20000)
.setInputCol("words")
.setOutputCol("features")
val hashData = hashingTF.transform(jiebaTonkenizer.transform(data))
hashData.limit(10).show()
// 划分训练集、测试集
val trainAndTestRatio = Array(0.95, 0.05)
val pipelineData = hashData.randomSplit(trainAndTestRatio, 99)
val trainData = pipelineData(0)
val testData = pipelineData(1)可以看到原始 comment 通过 Tokenizer 实现了分词,再通过 Hashing 实现了向量化,向量的长度由 HashingTF 的 NumFeatures 决定:

3.模型训练 LR
由于整体训练样本不多且词库相对稀疏,这里也没有设置正则化系数。
val lr = new LogisticRegression()
.setMaxIter(10)
.setElasticNetParam(0.8)
val lrModel = lr.fit(trainData)获取参数矩阵与截距:
// 打印逻辑回归的系数和截距
println(s"Coefficients: \n${lrModel.coefficientMatrix}")
println(s"Intercepts: \n${lrModel.interceptVector}")
Coefficnents 稀疏矩阵维度为 20000 x 6,Intercepts 截距项为 1 x 6。
4.模型评估 Metrics
val trainingSummary = lrModel.summary
通过 Model.summary 可以获取训练中的相关信息。
// 获取每次的迭代对象
val objectiveHistory = trainingSummary.objectiveHistory
println("objectiveHistory:")
objectiveHistory.foreach(println)
// 对于多分类问题,我们可以基于每个标签观察矩阵,并打印一些汇总信息
println("False positive rate by label:")
trainingSummary.falsePositiveRateByLabel.zipWithIndex.foreach { case (rate, label) =>
println(s"label $label: $rate")
}
println("True positive rate by label:")
trainingSummary.truePositiveRateByLabel.zipWithIndex.foreach { case (rate, label) =>
println(s"label $label: $rate")
}
println("Precision by label:")
trainingSummary.precisionByLabel.zipWithIndex.foreach { case (prec, label) =>
println(s"label $label: $prec")
}
println("Recall by label:")
trainingSummary.recallByLabel.zipWithIndex.foreach { case (rec, label) =>
println(s"label $label: $rec")
}
println("F-measure by label:")
trainingSummary.fMeasureByLabel.zipWithIndex.foreach { case (f, label) =>
println(s"label $label: $f")
}
val accuracy = trainingSummary.accuracy
val falsePositiveRate = trainingSummary.weightedFalsePositiveRate
val truePositiveRate = trainingSummary.weightedTruePositiveRate
val fMeasure = trainingSummary.weightedFMeasure
val precision = trainingSummary.weightedPrecision
val recall = trainingSummary.weightedRecall
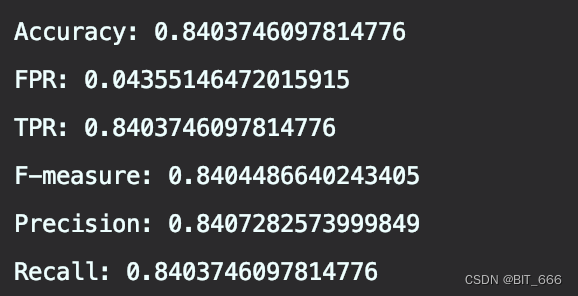
println(s"Accuracy: $accuracy\nFPR: $falsePositiveRate\nTPR: $truePositiveRate\n" +
s"F-measure: $fMeasure\nPrecision: $precision\nRecall: $recall")objectiveHistory 是一个双精度数组,它指定了在每个训练迭代中目标函数的优化过程,可以基于该参数评估模型是否需要进一步迭代或者调整训练参数。
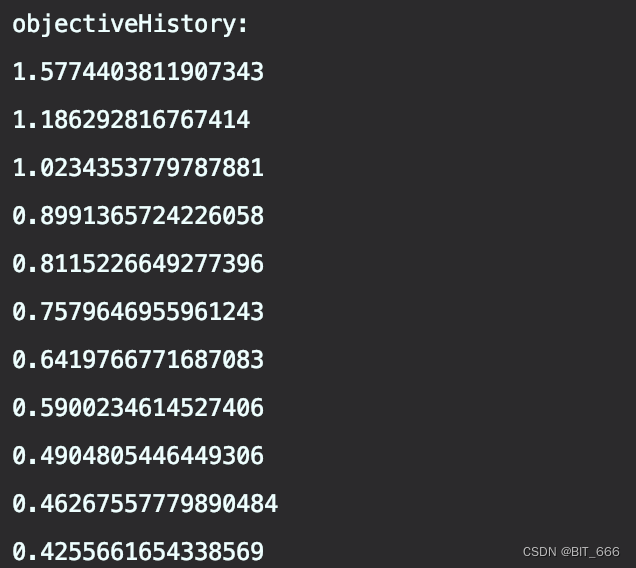
上面我们制定了 Iter 迭代次数为 10,可以看到每次优化的目标函数 Loss 在前两轮训练中下降最快,除此之外,还有基于各个 Label 的参数指标,例如正负样本率、召回率等等,最后打印模型整体评估指标:
5.人工校验 DIY

下面我们通过参数矩阵 Weights 与截距 Bias 手动实现预测并分析测试数据预测结果,套用上面提到的公式计算 fx 结果即可:
def calcTop(vector: Vector, real: Double): Unit = {
val multiply = lrModel.coefficientMatrix.multiply(vector).values
val result = multiply.zip(lrModel.interceptVector.toArray).map{ case (wx, b) => {
val fx = 1 / (1 + math.exp(-1 * (wx + b)))
fx
}}
val rank = result.zipWithIndex.maxBy(_._1)._2
println(s"Pre: ${lrModel.predict(vector)} DiyPre: $rank Real: $real ${result.mkString(",")}")
}下面我们以测试集中的 《肖申克的救赎》影评为例看一下评分:
testData.filter("movie == '肖申克的救赎'")
.select("movie", "label", "comment", "features")
.take(10).foreach{
case Row(movie: String, label: Double, comment: String, feature: Vector) => {
println(movie + "\t" + label + "\t" + comment + "\t" + feature)
calcTop(feature, label)
}}
由于训练样本中该电影评分大部分为 4-5,所以模型训练后也会相应得到较高的分数,第二个预测中,虽然将 5 分预测为 4 分,但是可以通过最终 1x6 的结果数组中看到 4 分与 5 分对应的预测分数相当接近,只相差 0.00008 左右。
四.总结
不论是二分类还是多分类,均使用了 LR 实现,相对比较简单,如果想要更复杂的实现,Python 更适合,我们在前面讲过通过循环神经网络并实现多输出模型的案例 Keras 多输出模型:

这里社交媒体发帖可以类比为电影评论,目标函数 Loss 由 3 个预测目标构成,收入分10类,使用 categorical_crossentropy 损失函数、年龄是 0-100 岁,采用 mse 损失函数、性别是二值,采用 binary_crossentropy 损失函数。这里电影类别可以看做是分为 6 个类别的收入,因此采用 categorical_crossentropy 作为损失函数,删掉另外两个输出类年龄和性别,就实现了相对复杂版的循环神经网络 NLP 语言情感分析。将训练生成的模型保存为 pb 文件,再配合 java tensorflow API 即可使用 Scala / Java 实现复杂深度模型的使用。