目录
第八章 函数
1.模块化程序设计(模块化---封装、复用、可替代)
2.定义函数
3.函数调用
4.return语句
5.函数参数
6.变量作用域
7.函数的递归调用
8.匿名函数
9.迭代器
10.生成器
11.装饰器
第八章 函数
1.模块化程序设计(模块化---封装、复用、可替代)
(1)基本思想:一个大型程序按照功能分隔成若干个小型模块
(2)特点:
- 模块相对独立、功能单一、结构清晰、接口简单(内聚、耦合)
- 减少程序复杂性
- 提高元器件的可靠性
- 缩短软件开发周期
- 避免程序开发的重复劳动
2.定义函数
(1)格式:(函数首部+函数体)
def 函数名(形参列表)
内部功能代码
return 表达式
(2)函数名:函数名有区分其它函数的作用,本质就是该函数在内存所占空间的首地址,是常量,该命令要求见名知意。
(3)形式参数(形参):
- 作用:函数接受数据的变量空间
- 原则:调用函数时,形参变量会分配空间,调用结束后会释放空间
- 设计:形参名称、个数(一一对应)、多个参数使用逗号分割
(4)函数体:编写程序实现函数功能
def summer(lis):
'''这里写函数的说明文档.doc的位置
:param lis:参数列表说明
:return:返回值说明
'''
t = 0
for i in lis:
t += i
return t3.函数调用
(1)作用:使函数功能,传递参数
(2)格式:函数名(实参列表)
(3)调用方式
fun(m) # 调用fun函数,将实参m传递给形参
n = fun(m) # 调用fun函数,将返回值复制给n变量
# n=:接受调用fun函数的返回值
s = s * fun(m) # 调用fun函数,返回值参与后续运算
fun() # 无返回值、无参,只是执行一次(4)例:计算c(m,n)=m!/(n!*(m-n)!)
def fac(x):
facx = 1
for i in range(1, x + 1):
facx *= i
return facx
m = int(input('请输入m的值:'))
n = int(input('请输入n的值:'))
c = fac(m) / (fac(n) * fac(m - n))
print('结果:', c)
# 请输入m的值:6
# 请输入n的值:5
# 结果: 6.04.return语句
(1)作用:返回return后的对象,函数执行到此结束,若无返回值,省略return语句,会返回None。
(2)注意:一但函数执行过程中遇到return语句,之后的函数体代码都不会执行,会跳出循环体。
def func():
pass
return # 此时后面的都不会执行
print()
pass(3)return可以返回任意python对象
5.函数参数
(1)位置参数(必须/必备参数)---必须按照正确顺序传到函数函数中,实参和形参的位置对齐,个数相同
def fun(str1,str2):
print(str1,str2)
fun('hello','world') # 按位置对齐(2)关键字参数:使用形参名字来确定输入的参数值,实参不在需要与形参的位置完全一致
def fun(str1,str2):
print(str1,str2)
fun(str2='world',str1='hello')(3)默认参数:调用函数时,如果没有传递参数,会默认使用参数
def fun(str1, str2='world'):
print(str1, str2)
fun('helo')PS:默认参数必须写在形参列表的最右边,否则报错。默认参数尽量不要指向不变的对象。
面试题:
def func(a=[]):
a.append('A')
return a
print(func()) # 1
print(func()) # 2
print(func()) # 3
# ['A']
# ['A', 'A']
# ['A', 'A', 'A']分析:函数体装入内存后,a列表会被创建,内存中有a列表内容,都不会清空回收。会继续使用直到程序结束。
def func(a=[]):
print('函数内部a的地址为:%s' % id(a))
a.append('A')
return a
b = print(func()) # 1
print('b的地址:%s' % id(b))
print(b)
c = print(func()) # 2
print('c的地址:%s' % id(c))
print(c)
d = print(func()) # 3
print('d的地址:%s' % id(d))
print(d)若想输出内容不改变,此处需要a不变原则:使用不变类型作为默认值,修改为---
def func(a=None):
if a is None:
a=[]
a.append('A')
return a
print(func()) # ['A']
print(func()) # ['A']
print(func()) # ['A'](4)不定长参数(可变参数):传入的参数可以是任意多个(个数任意)
- 格式1:*形参。增加一个星号,可以接受多个参数并存储到元组中
def fun(str1,*str2):
print(str1,str2)
fun('hello','world','china','12345')
# hello ('world', 'china', '12345')-
格式2:**形参,增加2个星号,以关键字参数形式传递,以字典形式存储
def func(str1,**str2):
print(str1,str2)
func('hello',a='world',b='china',c='12345')
# hello {'a': 'world', 'b': 'china', 'c': '12345'}PS:若形参列表中只有单独的星号,则对实参必须以关键字参数形式传入
def func(str1,*,str2):
print(str1,str2)
func('hello',str2='world')
# hello world6.变量作用域
(1)作用域:作用域指变量的有效范围,决定访问权限
(2)编程语言中,变量的作用域代码从代码结构形式来说,分成:块级、函数、类、模块、包(由小到大)。python中没有块级,等同于普通语句
(3)python的作用域共分为四层
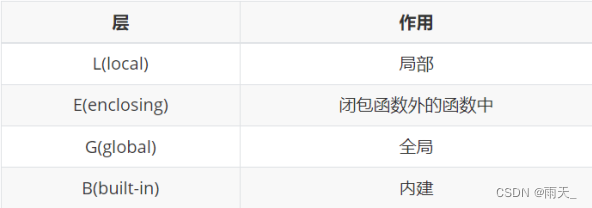
x = int(2.9) # 内建作用域
global_var = 0 # 全局作用域
def outer():
out_var = 1 # 闭包函数外的函数中
def inner():
inner_var = 2 # 局部作用域(4)python查找规则:L->E->G->B的顺序查找变量,即在局部找不到变量则回到局部外的局部去找,再找不到则到全局去找,最后到内建去找变量,若找不到则报错(提示变量不存在)
(5)全局变量和局部变量
-
定义在函数内部的变量称为局部变量。定义在函数外的变量一般拥有全局的作用域,称为全局变量
a = 1 # 全局变量
def func():
b = 2 # 局部变量
print(a)
def inner():
c = 3 # 更局部的变量
print(a)
print(b)
print(c)
func()-
global和nonlocal关键字
total = 0 # 全局变量
def plus(arg1, arg2):
total = arg1 + arg2
print('函数内局部变量total=', total)
print('函数内局部变量total的地址:', id(total))
return total
plus(10, 20)
print('函数外全局变量total=', total)
print('函数外的全局变量total:', id(total))
# 函数内局部变量total= 30
# 函数内局部变量total的地址: 1960342940880
# 函数外部的全局变量total= 0
# 函数外的全局变量total: 2209407920400-
global:指定当前变量强制使用外部的全局变量
total = 0 # 全局变量
def plus(arg1, arg2):
global total # 使用global什么此处total引用外部的total
total = arg1 + arg2
print('函数内局部变量total=', total)
print('函数内局部变量total的地址:', id(total))
return total
plus(10, 20)
print('函数外全局变量total=', total)
print('函数外的全局变量total:', id(total))
# 函数内局部变量total= 30
# 函数内局部变量total的地址: 2226970062032
# 函数外全局变量total= 30
# 函数外的全局变量total: 2226970062032面试题:
a=10
def test():
a+=1
print(a)
test()
# 函数内部未定义,也没有在内部使用global声明,所以报错
a = 10
def test():
global a # 声明使用外部变量
a += 1
print(a)
# 执行会报错,a+=1相当于a=a+1,python中规定如果函数内部需要修改一个变量,那么该变量必须为内部变量,除非使用global声明
test() # 11-
nonlocal:修改嵌套作用域中的变量
a=1
print('全局变量a的地址为:',id(a))
def outer():
a=2
print('函数outer内部闭包外部a的地址为:',id(a))
def inner():
nonlocal a
a=3
print('函数inner调用后闭包内部变量a的地址为:',id(a))
inner()
print('函数inner调用后,闭包外部的变量a的地址为:',id(a))
# 此处应输出的是函数闭包外部,outer内部的a的地址,但是引用nonlocal,导致闭包内部不在引用闭包外部的a的空间,所以inner调用后闭包外部地址和闭包内部地址相同
outer()
# 全局变量a的地址为: 2921487493424
# 函数outer内部闭包外部变量a的地址: 2921487493456
# 函数inner调用后闭包内部变量a的地址: 2921487493488
# 函数inner调用后,闭包外部的变量a的地址: 29214874934887.函数的递归调用
(1)作用:一个函数在它的函数内部调用本身称为递归调用
(2)例:递归算法来计算n!
def fun(n):
if n == 0:
return 0
else:
if n > 1:
x = fun(n - 1) * n
else:
x = 1
return x
m = int(input('请输入一个正整数:'))
print('阶乘结果为:', fun(m))
# 请输入一个正整数:5
# 阶乘结果为: 120(3)注意:
- 每一次递归,整体问题的值都要比原来要小,并且递归到一定层次后,必须给出结果。
- 为了防止递归的无休止调用,必须在函数内部有终止递归的手段,一般配合if-else使用。
- 递归需要防止递归深度溢出。在python使用栈这种数据结构实现的,默认的深度为1000层,超出该深度会抛出异常。每当进入下一个递归时,栈会增加一层;当函数每返回一层,栈会减少一层。
- 递归可以使程序变的简洁,增加程序可读性,每一次递归都要重新开辟内存空间,这是以牺牲空间为代价的算法,所以递归会增加程序执行的事件开销。
8.匿名函数
(1)当创建函数时,有时不需要显式的定义函数,直接省略函数名,传入参数计算即可。省略了函数的命名,通过水平不发生表达式生成函数
(2)创建匿名函数:lambda
- 所谓匿名即不再使用def关键字来创建函数
- lambda只是一个表达式,不是一个代码块,函数体比def定义的函数简单
- lambda仅仅能封装有限的逻辑语句
(3)格式:lambd 参数 :表达式
lambda x: x * x
# 相当于
def fun(x):
return x * x- lambda是匿名函数的关键字
- lambda之后的x为函数参数,相当于原先的形参
- x*x为执行代码
(4)匿名函数只能有一个表达式,有自己的命名空间,不用写return语句,表达式结果就是其返回值
9.迭代器
(1)迭代:通过for循环遍历对象的每一个元素的过程
(2)迭代器:是一种可以被遍历的对象,可以用做next()函数,迭代器对象从第一个元素开始向后进行访问,直至最后一个元素,只能向后遍历,不能向前回溯。---与列表最大区别:列表遍历方向任意。
(3)迭代器的常用方法:iter();next()
list1 = [1, 2, 3, 4, 5, 6, 7, 8]
l1 = iter(list1) # 创建迭代器对象l1
for i in l1:
print(i, end=' ')
# 1 2 3 4 5 6 7 8 (4)迭代器(iterator)和可迭代(iterable)的区别
- 凡是可作用于for循环的对象都是可迭代类型
- 凡是可作用于next()函数的对象都是迭代器类型。
- list、dict、str等都是可迭代的但不是迭代器,因为next()函数无法调用它们
- for循环本质上是通过调用next()函数实现下一个访问的
10.生成器
(1)产生原因:由于序列或集合内的元素个数非常巨大,如果全部生成制造,再一次性放入内存会对计算机造成非常大的存储压力。如果元素结果可以按照某些算法推算出来,需要计算哪一个就生成哪一个,不必完整的创建元素集合,从而节省大量内存空间。所以在python中一边循环一边计算的机制称为生成器(generator)
(2)在python使用关键字:yield可以返回函数,使其变成一个生成器。
(3)运行机制:调用函数生成器过程中,每次遇到yield时,函数会暂停执行,并保存当前所有的运行信息,向主调函数处返回结果,并在下一次执行next()方法时,从当前位置继续执行。
# 斐波那契数列
def fib(n):
a, b, c = 0, 1, 0
while 1:
if c > n:
return # 返回停止函数调用
yield a # 暂停函数执行,并返回当前结果,还可继续下一次函数的执行
a, b = b, a + b
c = c + 1
f1 = fib(10)
for i in f1:
print(i, end=' ')
print(type(f1))
# 0 1 1 2 3 5 8 13 21 34 55 <class 'generator'>11.装饰器
(1)从函数开始:
def hello():
print('hello world')
hello()
# hello world(2)上例定义了一个hello函数,现在需要增加一个功能
# 第一种:
def hello():
print('====strat====')
print('hello world')
print('====end====')
hello()
# 第二种:
def hello():
print('hello world')
print('====strat====')
hello()
print('====end====')问题:
第一种方法会改变函数的执行代码
第二种方法如果多次调用,每一次都需要增加开始和结束的特效,将会消耗机器性能,较为麻烦
提出解决方法:
则能不能在不改变函数内部的原始代码和参数及调用方式等信息,又想给该函数增加新功能?
可以使用装饰器,装饰该函数,在不改变原函数的情况下,增加功能。
(3)函数的高阶使用
- 定义一个函数
def add(a, b):
return a + b- 调用:
def add(a, b):
return a + b
print(add(2, 3)) # 5- add函数是有返回值的,若输出add不加括号
def add(a, b):
return a + b
print(add(2, 3)) # 5
print(add)
print(type(add))
# <function add at 0x0000026C6D07EF70>
# <class 'function'>结论:一个函数名称加上括号就会被执行,函数也和整数、字符串、浮点数一样都是一个对象。
基于上述理论:
a = print
a('hello world') # hello world
# 解释:将print赋值给a,a('hello world ')等价于print('hello world')
# 改进:
def output():
return print
output()('hello world') # hello world
# 解释:任何返回值都可以在调用时直接替换这个函数
# 改进:
def output():
print('hello world')
def act(func):
func()
act(output)
# 定义一个output函数可以输出hello world
# 未直接调用,直接写了act函数,act函数的参数是一个函数名,作用:调用act函数时,会间接调用output函数,从而输出hello world结论:一个函数名称作为一个函数的参数传递给另一个函数时(实参高阶函数),返回值中包含函数名(返回值高阶函数),这里说的函数名本质为函数首地址。若把函数名当做一个参数传递给另一个函数,然后在另一个函数内部做一些操作,则可以实现不修改源代码的情况下从而变更函数功能。
(4)基于上述演变,得出如下示例:
def deco(func):
def inner():
print('====start====')
func()
print('====end====')
return inner
def hello():
print('hello world')
hello = deco(hello)
hello()
# ====start====
# hello world
# ====end====执行过程:函数deco即hello会被装入内存,等待被执行;执行hello = deco(hello),调用deco函数,将hello函数名作为实参传递过去;执行deco(func)函数,其中func等价于hello函数,inner函数装入内存等待被执行,最后返回inner函数名并到hello=deco(hello)函数调用处,hello会被inner覆盖,此时hello就是inner函数;执行hello()函数,由于hello已被inner覆盖则相当于执行inner()函数;执行inner函数输出修饰语句,输出func()函数结果,由于func指向最早的hello函数则输出hello world。
结论:本段代码本质上修改了调用函数,但实际上未修改函数调用方式,实现了附加功能。通俗一点来说就是把函数当做一个大盒子,deco是大盒子、inner是中盒子、hello是小盒子。程序中将小盒子hello传递给大盒子deco中的中盒子inner,再把中盒子inner执行一次,这就是装饰器。
(若需要多次修改,可以装饰多次)
def deco(func):
def inner():
print('==== start ====')
func()
print('==== end ====')
return inner
def hello():
print('hello world')
def nihao():
print('nihao')
hello = deco(hello)
hello()
nihao = deco(nihao)
nihao()(5)装饰器:
- 器:工具,可以定义成函数
- 装饰:指的是为其他事物添加的额外点缀
- 装饰器:定义一个函数,该函数是用来为其他函数添加额外功能的。
- 应用场景:应用于有切面操作的场景。如:插入日志,性能测试,事务处理,缓存,权限校验等
- 语法塘:装饰器的语法简化写法。如:
def deco(func):
def inner():
print('==== start ====')
func()
print('==== end ====')
return inner
@deco # 等价于 hello = deco(hello)
# @deco写在被装饰的del hello()之前
def hello():
print('hello world')
hello()
# ====start====
# hello world
# ====end====



![24. [Python GUI] PyQt5中的模型与视图框架-表格部件QTableWidget](https://img-blog.csdnimg.cn/img_convert/c7c8786bf7c4316a7ba9d65b6d02d828.png)