换了新的环境后,一直在适应(其实是一直被推着走),所以停更了笔记好久啦。这一周周末终于有点得空,当然也是因为疫情,哪里都不能去,哈哈,所以来冒个泡~
整理了最近pre的作业,分享一下双重差分法的一些笔记,望共勉及有用~
这篇博客是之前一篇博客 双重差分法学习笔记的补充,主要补充了一篇经典论文的介绍以及解决在执行DID过程,平行趋势违背的一些方式处理
这里写目录标题
- 经典DID论文介绍和复现
- 论文内容
- 论文复现
- 论文变量的解释
- 基准回归
- 平行趋势检验
- 政策的动态处理效应
- 三重差分控制干扰因素
- 稳健性检验(部分)
- 平行趋势违背的处理
- 解决方式
- 三重差分法
- 介绍
- 实现
- 合成控制法
- 介绍
- 实现
- 倾向得分匹配法
- 介绍
- 实现
- 总结
经典DID论文介绍和复现
Moser and Voena 2012年在AER上发表基于经典DID方式检验知识产权限制对创新影响的论文,非常经典(题目是 : Compulsory Licensing - Evidence from the Trading with the Enemy Act ),所以也着重介绍了一下这一篇和复现,着重在复现上。
虽然作者发布了数据和程序,但是其实一些图都是通过office实现,所以在这一版上,我通过stata程序实现。通过这个复现,对stata绘图的害怕也减少了一些。。
论文内容
【计量经济圈】公众号也介绍了这篇论文,从AER学习DID方法的最经典文献, 当时没有之一
如果大家没空学习论文正文,也可以快速通过浏览它,知道个大概研究思路,不过还是强烈推荐大家去学习一下滴,因为论文写作思路和逻辑都很流畅和严谨~
摘要:
强制许可允许发展中国家的公司在没有外国专利所有者同意的情况下生产外国拥有的发明(论文背景)。本文利用一战后根据《与敌贸易法》规定的强制许可这一外生事件来考察强制许可对国内发明的影响(研究方法)。对近13万项化学发明的差异分析表明,强制许可使国内发明增加了20%(研究发现)。

结论:
本文利用TWEA作为一个自然实验,研究强制许可是否鼓励国民在新兴产业中进行发明。
TWEA之后美国发明家的化学专利数据表明,强制许可对国内发明具有强大且持续的积极影响。在USPTO子类中,至少有一项敌方拥有的专利根据TWEA授权给国内公司,在TWEA之后,国内专利增加了约20%(与未受影响的子类相比)。
这些结果对于控制授予的许可证数量以及考虑许可专利的新颖性是稳健的。结果也适用于各种替代测试,包括三重差异(将美国发明家在TWEA前后的专利数量变化与其他非德国发明家的专利数量的变化进行比较)、亚类和治疗特定时间趋势的对照,以及其他非德国发明家的安慰剂测试。
ITT和工具变量回归进一步表明,该分析可能低估而不是高估了许可的真实影响。
数据的历史性质也使我们能够检查这些影响的时间。对年度治疗效果的估计表明许可始于1929年左右(以专利申请量衡量),并持续到20世纪30年代。强制许可证赋予美国公司生产德国发明的权利,但即使有权获得被没收的专利,在某些情况下还有实物资本,美国公司也需要几年时间才能获得在国内生产这些发明所需的知识和技能。我们的数据表明,美国的发明在经过这段长时间的学习后开始了。这些发现反映在不断变化的科学引用模式中,这表明美国化学工业在20世纪30年代作为知识的鼻祖而获得了突出地位。美国公司在TWEA之后经历的艰难学习过程表明,人力资本和隐性知识对于促进各国之间的快速技术转让至关重要。
论文复现
论文复现数据是可以从这个网址下载的(可能需要注册一个账户)
https://www.openicpsr.org/openicpsr/project/112497/version/V1/view
论文变量的解释
*-变量解释
use chem_patents_maindataset,replace
**年份定义
label var grntyr "发生年份"
**专利分类定义
label var uspto_class "7248个专利子类"
label var main "19个专利主类"
label var subcl "7248个专利子类"
label var class_id "7248个专利子类的编码"
label var licensed_class "是被没收的专利许可类别,是则为1"
//label var confiscated_class "有被没收的专利类别,是则为1"
**没收的专利许可
label var count_cl "该子类被没收的专利许可数量,最多为15个"
label var count_cl_2 "该子类被没收的专利许可数量的平方,最多为15个"
label var year_conf "该子类被没收的专利许可的总剩余时间"
label var year_conf_2 "该子类被没收的专利许可的总剩余时间的平方"
label var treat "处理组,该子类中至少有1个没收的专利许可,则为1"
**专利授予数量
label var count_usa "该年美国人专利授予的数量"
label var count_france "该年法国人专利授予的数量"
label var count_germany "该年德国人专利授予的数量"
label var count "该年所有国家专利授予年份的数量"
label var count_for "该年所有外国国家专利授予的数量(区间1875-1939)"
label var count_for_2 "该年(1877-)所有外国国家专利授予的数量(区间1877-1939)"
label var count_for_noger "该年所有外国非德国国家专利授予年份的数量"
save chem_patents_maindataset,replace
基准回归
*-Table 2: 基准回归
use chem_patents_maindataset,replace
**变量
// 因变量:count_usa "该年美国人专利授予的数量"
// 处理变量1:treat "处理组,该子类中至少有1个没收的专利许可,则为1"
// 处理变量2:count_cl "该子类被没收的专利许可数量,最多为15个"
// 处理变量3:year_conf "该子类被没收的专利许可的总剩余时间"
// 控制变量1:count_for "该年所有外国国家专利授予的数量(区间1875-1939)"
// 控制变量2:count_cl_2 "该子类被没收的专利许可数量的平方,最多为15个"
// 控制变量3:year_conf_2 "该子类被没收的专利许可的总剩余时间的平方"
// 固定效应:年度固定效应(grntyr)、专利子类固定效应(class_id)
**变量标签
label var count_usa "Patents by US inventors"
label var treat "Subclass has at least one license"
label var count_cl "Number of licenses"
label var count_cl_2 "Number of licenses squared"
label var year_conf "Remaining lifetime of licensed patents"
label var year_conf_2 "Remaining lifetime of licensed patents squared(×100)"
label var count_for "Number of patents by foreign inventors"
**回归检验
*** 处理变量1:treat
reghdfe count_usa treat count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m1
reghdfe count_usa treat, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m2
***处理变量2:count_cl
reghdfe count_usa count_cl count_cl_2 count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m3
reghdfe count_usa count_cl count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m4
reghdfe count_usa count_cl, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m5
***处理变量3:year_conf
reghdfe count_usa year_conf year_conf_2 count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m6
reghdfe count_usa year_conf count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m7
reghdfe count_usa year_conf, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m8
**输出结果
outreg2 [m1 m2 m3 m4 m5 m6 m7 m8] using Table2.xls, ///
tstat adjr2 nocons dec(3) label replace ///
keep(treat count_cl count_cl_2 year_conf year_conf_2 count_for) ///
sortvar(treat count_cl count_cl_2 year_conf year_conf_2 count_for) ///
title("Table2") ctitle(" ") ///
addtext(Subclass fixed effects,Yes,Year fixed effects,Yes, ///
Number of subclasses,7248)
平行趋势检验
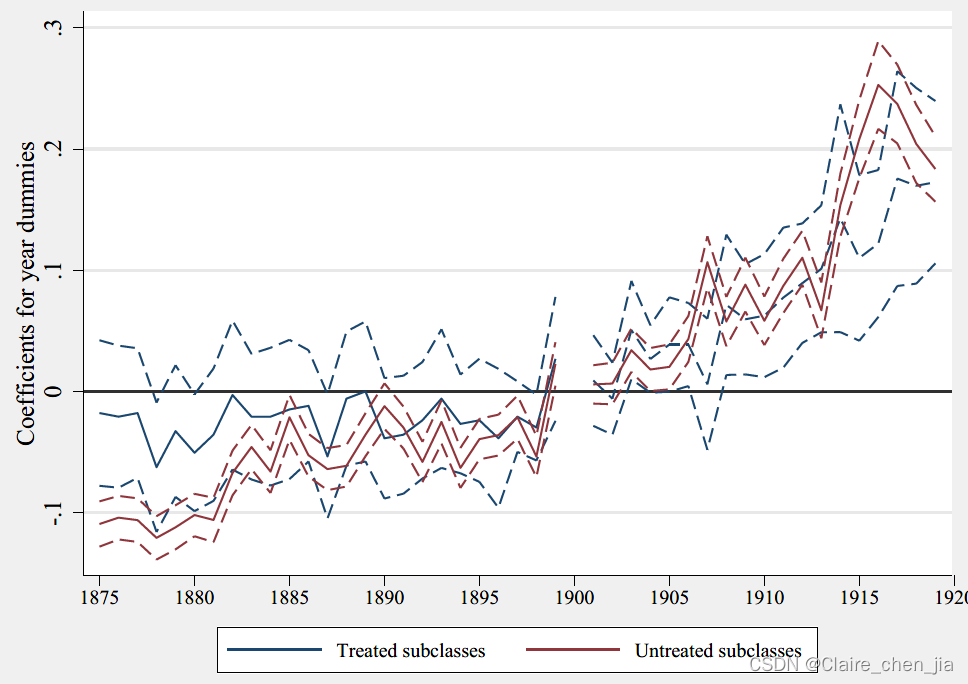
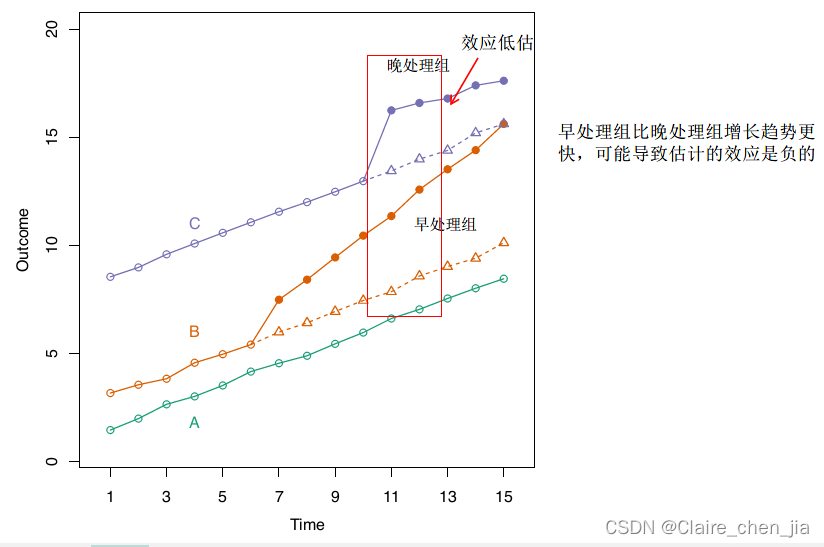
其实这里,我是有点不明白作者检验平行趋势的方式。这里的方法好像跟传统加入时间与政策的动态交乘项不同,作者是分别看处理组和控制组的事前时间趋势变化(影响系数),通过看他们的影响趋势差不多,来判断他们满足平行趋势假设
*-Figure 4 比较处理和控制组的预处理趋势
use chem_patents_maindataset,replace
**生成处理组和控制组变量
forvalues x=1875/1939 {
gen untreat_`x'=1 if licensed==0 & grn==`x' // 控制组
replace untreat_`x'=0 if untreat_`x'==.
gen treat_`x'=1 if licensed==1 & grn==`x' // 处理组
replace treat_`x'=0 if treat_`x'==.
}
**回归
drop *treat_1900
xtreg count_usa treat_* untreat_*, fe i(class_id) robust cluster(class_id)
**存储处理组系数
sort uspto_class grntyr
gen coef_treat = .
gen se_treat = .
***存储回归系数和标准误
local j = 1
foreach var of var treat_* {
replace coef_treat = _b[`var'] in `j'
replace se_treat = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci_treat = coef_treat + 1.96* se_treat
gen low_ci_treat = coef_treat - 1.96*se_treat
**存储控制组系数
sort uspto_class grntyr
gen coef_control = .
gen se_control = .
***存储回归系数和标准误
local j = 1
foreach var of var untreat_* {
replace coef_control = _b[`var'] in `j'
replace se_control = _se[`var'] in `j'
local ++j
}
***生成置信区间上下界
gen up_ci_control = coef_control + 1.96* se_control
gen low_ci_control = coef_control - 1.96*se_control
**输出预处理趋势图
keep in 1/45 // 保留前45行数据(1875-1919)
rename grntyr Year
replace Year = Year+1 if Year>=1900
drop if Year == 1920
insobs 1
replace Year == 1900 if Year==.
tsset Year
tw (line coef_treat Year if Year<1900, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Coefficients for year dummies") xtitle("")) ///
(line coef_treat Year if Year>1900, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Coefficients for year dummies") xtitle("")) ///
(line up_ci_treat Year, lwidth(medthin) lcolor(navy) lp(dash) cmissing(n)) ///
(line low_ci_treat Year, lwidth(medthin) lcolor(navy) lp(dash) cmissing(n)) ///
(line coef_control Year if Year<1900, yline(0) lwidth(medthin) lp(solid) lcolor(maroon)) ///
(line coef_control Year if Year>1900, yline(0) lwidth(medthin) lp(solid) lcolor(maroon)) ///
(line up_ci_control Year, lwidth(medthin) lcolor(maroon) lp(dash) cmissing(n)) ///
(line low_ci_control Year, lwidth(medthin) lcolor(maroon) lp(dash) cmissing(n) ///
legend(order(1 "Treated subclasses" 5 "Untreated subclasses") ///
pos(6) col(2) size(small))) , ///
yline(0, lwidth(vthin) lpattern(dash)) ///
xlabel(1875(5)1919, labsize(small))
gr export "Figure4.pdf",replace
政策的动态处理效应
*-Figure 6、7、8 处理组的年度处理效应
use chem_patents_maindataset,replace
**生出处理变量
// 因变量:count_usa "该年美国人专利授予的数量"
// 处理变量1:treat "处理组,该子类中至少有1个没收的专利许可,则为1"
// 处理变量2:count_cl "该子类被没收的专利许可数量,最多为15个"
// 处理变量3:year_conf "该子类被没收的专利许可的总剩余时间"
// 控制变量1:count_for "该年所有外国国家专利授予的数量(区间1875-1939)"
forvalues x=1876/1939 {
gen td_`x'=0
qui replace td_`x'=1 if grn==`x'
}
foreach var in treat count_cl year_conf {
forvalues x=1919/1939 {
cap gen `var'_`x'=`var' if grn==`x'
qui replace `var'_`x'=0 if grn!=`x'
}
}
**Figure 6: 处理变量1 treat
preserve
***回归
xtreg count_usa treat_* count_for td*, fe i(class_id) robust cluster(class_id)
***生成存储系数
sort uspto_class grntyr
gen coef = .
gen se = .
***存储回归系数和标准误
local j = 1
foreach var of var treat_* {
replace coef = _b[`var'] in `j'
replace se = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci = coef + 1.96* se
gen low_ci = coef - 1.96*se
**输出效应图
keep in 1/21 // 保留前21行数据(1919-1939)
rename grntyr Year
replace Year = Year+44
tw (line coef Year, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Annual treatment effect") xtitle("") ///
title("Treat: Subclass has at least one license")) ///
(line up_ci Year, lwidth(medthin) lcolor(navy) lp(dash)) ///
(line low_ci Year, lwidth(medthin) lcolor(navy) lp(dash) ///
legend(off)), yline(0, lwidth(vthin) lpattern(dash)) ///
xlabel(1919(5)1939, labsize(small))
gr export "Figure6.pdf",replace
restore
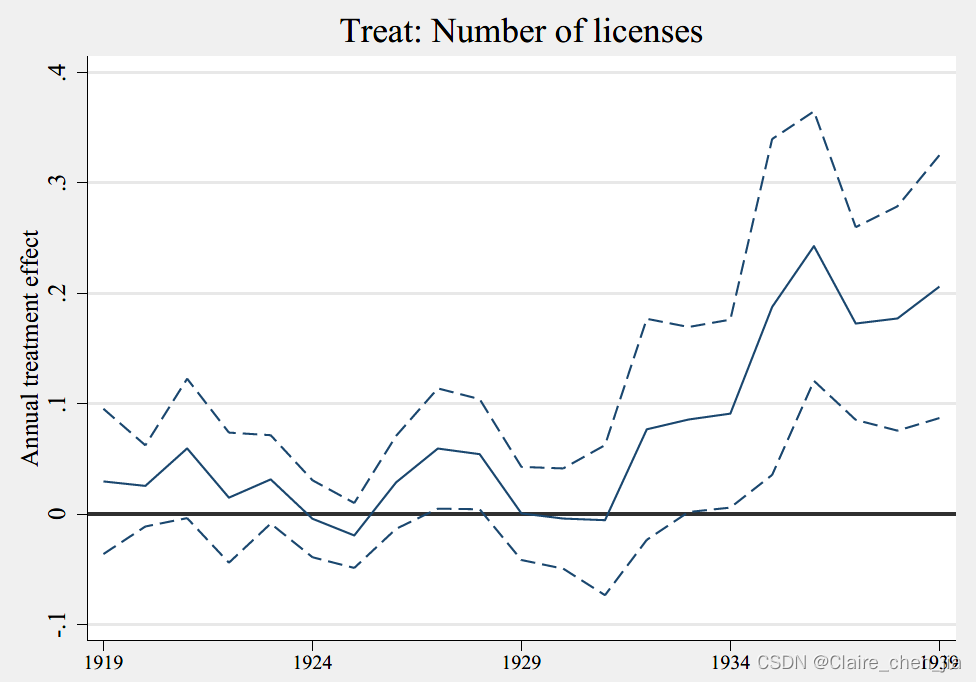
**Figure 7: 处理变量2 count_cl
preserve
***回归
xtreg count_usa count_cl_1919-count_cl_1939 count_for td*, fe i(class_id) robust cluster(class_id)
***生成存储系数
sort uspto_class grntyr
gen coef = .
gen se = .
***存储回归系数和标准误
local j = 1
foreach var of var count_cl_1919-count_cl_1939 {
replace coef = _b[`var'] in `j'
replace se = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci = coef + 1.96* se
gen low_ci = coef - 1.96*se
**输出效应图
keep in 1/21 // 保留前21行数据(1919-1939)
rename grntyr Year
replace Year = Year+44
tw (line coef Year, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Annual treatment effect") xtitle("") ///
title("Treat: Number of licenses")) ///
(line up_ci Year, lwidth(medthin) lcolor(navy) lp(dash)) ///
(line low_ci Year, lwidth(medthin) lcolor(navy) lp(dash) ///
legend(off)), yline(0, lwidth(vthin) lpattern(dash)) ///
xlabel(1919(5)1939, labsize(small))
gr export "Figure7.pdf",replace
restore
**Figure 8 - 处理变量3 year_conf
preserve
***回归
xtreg count_usa year_conf_1919-year_conf_1939 count_for td*, fe i(class_id) robust cluster(class_id)
***生成存储系数
sort uspto_class grntyr
gen coef = .
gen se = .
***存储回归系数和标准误
local j = 1
foreach var of var year_conf_1919-year_conf_1939 {
replace coef = _b[`var'] in `j'
replace se = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci = coef + 1.96* se
gen low_ci = coef - 1.96*se
**输出效应图
keep in 1/21 // 保留前21行数据(1919-1939)
rename grntyr Year
replace Year = Year+44
tw (line coef Year, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Annual treatment effect") xtitle("") ///
title("Treat: Remaining lifetime of licensed patents")) ///
(line up_ci Year, lwidth(medthin) lcolor(navy) lp(dash)) ///
(line low_ci Year, lwidth(medthin) lcolor(navy) lp(dash) ///
legend(off)), yline(0, lwidth(vthin) lpattern(dash)) ///
xlabel(1919(5)1939, labsize(small))
gr export "Figure8.pdf",replace
restore
三重差分控制干扰因素
*- Figure9: 三重差分检验
use "fig10.dta", clear
**回归
xtreg y usa_treat_td1919-usa_treat_td1939 usa_td* usa_treat treat_td* usa td_*, fe i(class_id) robust cluster(class_id)
**生成存储系数
gen year = _n in 1/21
replace year = year+1918
gen coef = .
gen se = .
***存储回归系数和标准误
local j = 1
foreach var of var usa_treat_td* {
replace coef = _b[`var'] in `j'
replace se = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci = coef + 1.96* se
gen low_ci = coef - 1.96*se
**输出效应图
keep in 1/21 // 保留前21行数据(1919-1939)
tw (line coef year, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Annual treatment effect: Trriple difference") xtitle("")) ///
(line up_ci year, lwidth(medthin) lcolor(navy) lp(dash)) ///
(line low_ci year, lwidth(medthin) lcolor(navy) lp(dash) ///
legend(off)), yline(0, lwidth(vthin) lpattern(dash)) ///
xlabel(1919(5)1939, labsize(small))
gr export "Figure9.pdf",replace
稳健性检验(部分)
- 安慰剂检验:构造假处理样本
*- Figure10: 安慰剂检验(稳健性检验)
use chem_patents_maindataset, clear
**生成变量
forvalues x=1876/1939 {
gen td_`x'=0
qui replace td_`x'=1 if grn==`x'
}
foreach var in treat {
forvalues x=1919/1939 {
cap gen `var'_`x'=`var' if grn==`x'
qui replace `var'_`x'=0 if grn!=`x'
}
}
forvalues x=1919/1939 {
cap gen untreat_`x'= 1 if licensed==0 & grn==`x'
qui replace untreat_`x'=0 if untreat_`x'==.
}
**处理组回归
xtreg count_france treat_* td*, fe i(class_id) robust cluster(class_id)
**生成存储系数变量
gen year = _n in 1/21
replace year = year+1918
gen coef_treat = .
gen se_treat = .
***存储回归系数和标准误
local j = 1
foreach var of var treat_* {
replace coef = _b[`var'] in `j'
replace se = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci_treat = coef_treat + 1.96* se_treat
gen low_ci_treat = coef_treat - 1.96*se_treat
**控制组回归
xtreg count_france untreat_* td*, fe i(class_id) robust cluster(class_id)
**生成存储系数变量
gen coef_control = .
gen se_control = .
***存储回归系数和标准误
local j = 1
foreach var of var untreat_* {
replace coef_control = _b[`var'] in `j'
replace se_control = _se[`var'] in `j'
local ++j // 第二个样本、第三个样本......
}
***生成置信区间上下界
gen up_ci_control = coef_control + 1.96* se_control
gen low_ci_control = coef_control - 1.96*se_control
**输出效应图
keep in 1/21 // 保留前21行数据(1919-1939)
tw (line coef_treat year, yline(0) lwidth(medthin) lcolor(navy) ///
ytitle("Coefficients for year dummies") xtitle("")) ///
(line up_ci_treat year, lwidth(medthin) lcolor(navy) lp(dash)) ///
(line low_ci_treat year, lwidth(medthin) lcolor(navy) lp(dash)) ///
(line coef_control year, yline(0) lwidth(medthin) lp(solid) lcolor(maroon)) ///
(line up_ci_control year, lwidth(medthin) lcolor(maroon) lp(dash)) ///
(line low_ci_control year, lwidth(medthin) lcolor(maroon) lp(dash) ///
legend(order(1 "Treated subclasses" 4 "Untreated subclasses") ///
pos(6) col(2) size(small))) , ///
yline(0, lwidth(vthin) lpattern(dash)) ///
xlabel(1919(5)1939, labsize(small))
gr export "Figure10.pdf",replace
- 删除干扰样本
*-Table 6: 删除新创建的子类(稳健性检验)
use chem_patents_maindataset,replace
**删除样本
sort uspto_class grn
bys uspto: gen ccc=sum(count)
foreach var in count_usa count {
qui replace `var'=. if ccc==0
}
gen aaa=1 if ccc==0 & grn==1919
bys uspto: egen bbb=max(aaa)
drop if bbb==1
drop if ccc==0
drop aaa bbb ccc
**变量标签
label var count_usa "Patents by US inventors"
label var treat "Subclass has at least one license"
label var count_cl "Number of licenses"
label var count_cl_2 "Number of licenses squared"
label var year_conf "Remaining lifetime of licensed patents"
label var year_conf_2 "Remaining lifetime of licensed patents squared(×100)"
label var count_for "Number of patents by foreign inventors"
**回归检验
*** 处理变量1:treat
reghdfe count_usa treat count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m1
reghdfe count_usa treat, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m2
***处理变量2:count_cl
reghdfe count_usa count_cl count_cl_2 count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m3
reghdfe count_usa count_cl count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m4
reghdfe count_usa count_cl, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m5
***处理变量3:year_conf
reghdfe count_usa year_conf year_conf_2 count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m6
reghdfe count_usa year_conf count_for, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m7
reghdfe count_usa year_conf, absorb(grntyr class_id) vce(cluster class_id) keepsingletons
est store m8
**输出结果
outreg2 [m1 m2 m3 m4 m5 m6 m7 m8] using Table6.xls, ///
tstat adjr2 nocons dec(3) label replace ///
keep(treat count_cl count_cl_2 year_conf year_conf_2 count_for) ///
sortvar(treat count_cl count_cl_2 year_conf year_conf_2 count_for) ///
title("Table6") ctitle(" ") ///
addtext(Subclass fixed effects,Yes,Year fixed effects,Yes, ///
Number of subclasses,7248)
平行趋势违背的处理
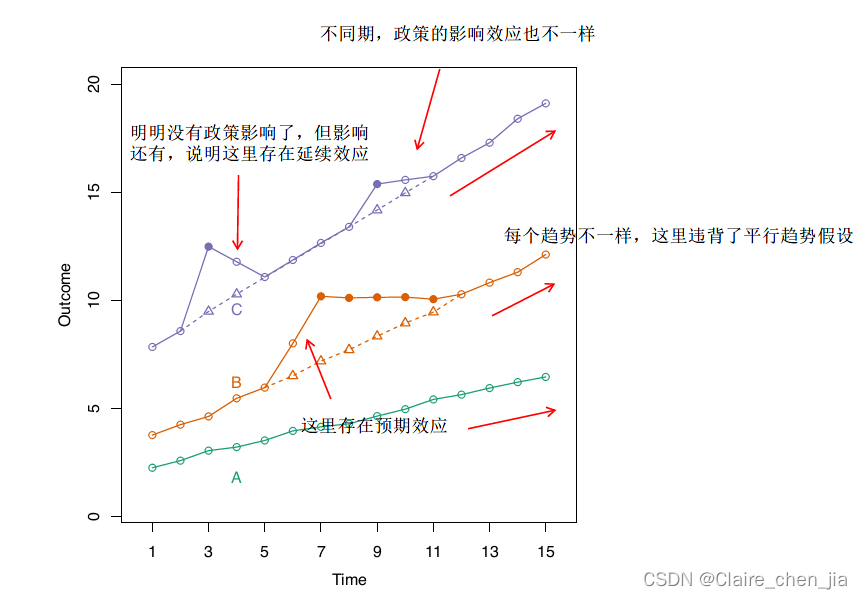
平行趋势假设:处理组和控制组在政策未发生的情况下,前后变化的差异是一致的。我们通过处理组和控制组在政策实施之前必须具有共同的变化趋势来检验。
违背原因:控制组和处理组在选择进入组时,不是随机的
解决方式
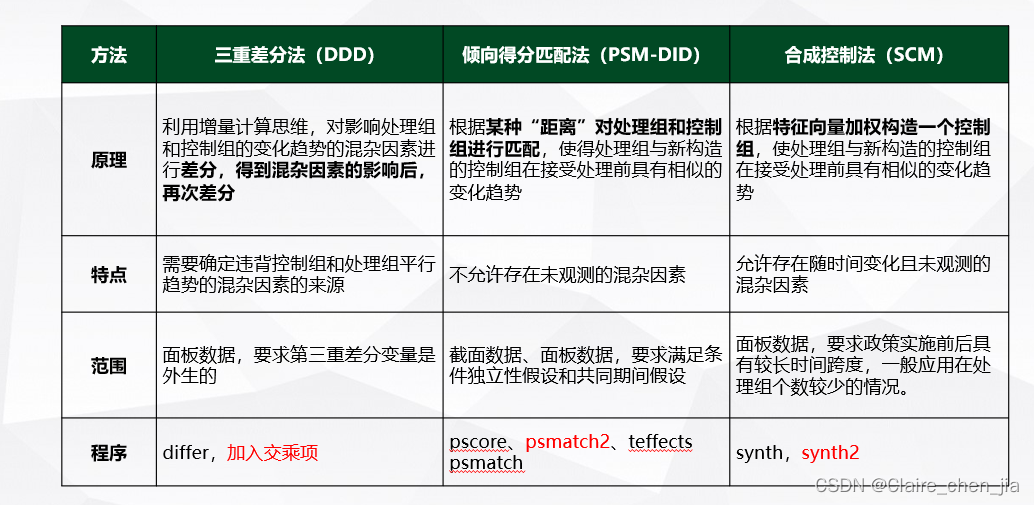
三重差分法
介绍

实现
*变量定义
// y:结果变量
// treat: 二元处理变量(1:被处理;0:被控制、未处理)
// time: 二元实验期变量(1:实验之后;0:实验之前)
// trend:三重差分变量(1:受干扰因素影响;0:不受干扰因素影响)
// $z:协变量,影响结果变量y,但不影响处理变量treat
*-diff命令
//help diff
**【没有协变量】的三重差分法
diff y, t(treat) p(time) ddd(trend) // 常规
diff y, t(treat) p(time) ddd(trend) robust // 稳健性标准误
diff y, t(treat) p(time) ddd(trend) cluster(id) // 聚类标准误
diff y, t(treat) p(time) ddd(trend) bs reps(200) // 参数和标准误采用bootstrap估计
**【有协变量】的三重差分法
diff y, t(treat) p(time) ddd(trend) cov($z) // 常规
diff y, t(treat) p(time) ddd(trend) cov($z) robust // 稳健性标准误
diff y, t(treat) p(time) ddd(trend) cov($z) cluster(id) // 聚类标准误
diff y, t(treat) p(time) ddd(trend) cov($z) bs reps(200) // 参数和标准误采用bootstrap估计
*-OLS命令 (加入交乘项)
//help reghdfe or help reg or help xtreg
reg y treat time trend c.treat#c.time c.treat#c.trend ///
c.time#c.trend c.treat#c.time#c.trend // 常规
reg y treat time trend c.treat#c.time c.treat#c.trend ///
c.time#c.trend c.treat#c.time#c.trend, robust // 稳健性标准误
reg y treat time trend c.treat#c.time c.treat#c.trend ///
c.time#c.trend c.treat#c.time#c.trend, cluster(id) // 聚类标准误
reg y treat time trend c.treat#c.time c.treat#c.trend ///
c.time#c.trend c.treat#c.time#c.trend $z, cluster(id) // 聚类标准误+控制协变量
合成控制法
介绍
虽然合成控制法只适用于处理组很少的情况,但是最近学者把SCM和DID结合起来,可以应用于处理组较多的情况下。连玉君老师在连享会上也进行了介绍
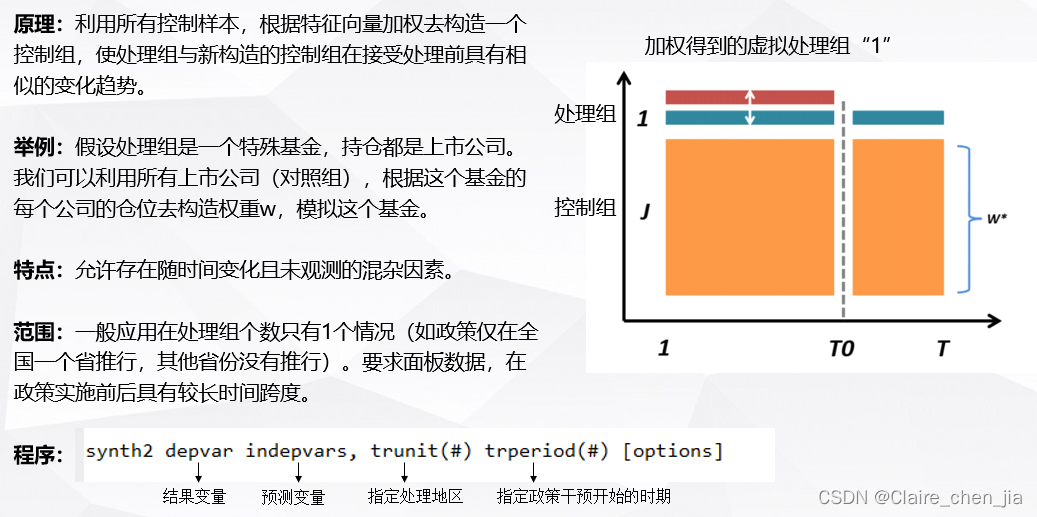
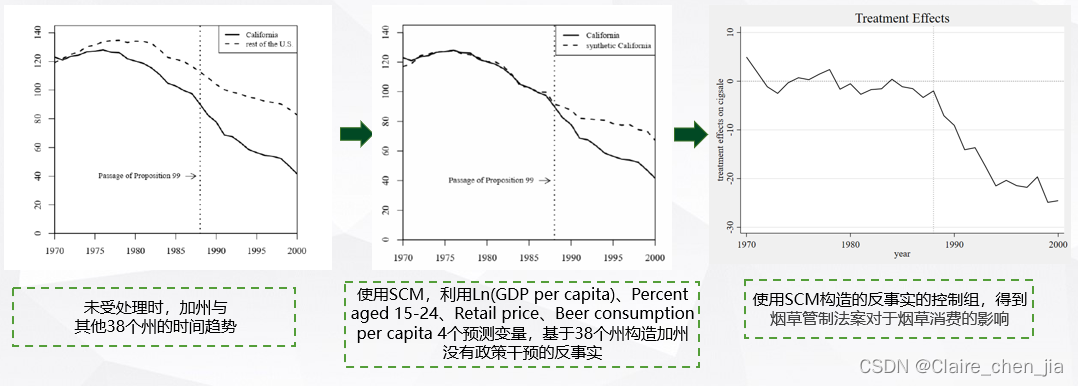
应用SCM方法的经典论文是Abadie(2010)基于加州烟草法案通过的论文,大家也可以学习一下,他发布了数据和程序
Abadie-2010-Synthetic Control Methods for Comparative Case Studies
实现
以Abadie(2010)的论文为例
*变量定义
// y:结果变量
// treat: 二元处理变量(1:被处理;0:被控制、未处理)
// time: 二元实验期变量(1:实验之后;0:实验之前)
// $z:协变量,影响结果变量y,但不影响处理变量treat
*命令安装
ssc install synth
ssc install synth2 // 更加常用且成熟
*-synth2语法
synth2 depvar indepvars, trunit(#) trperiod(#) [options]
**必选项
// depvar: 结果变量
// indepvars: 预测变量
// trunit(#): 表示 treated unit,用于指定处理地区
// trperiod(#):表示 treated period,用于指定政策干预开始的时期
**选择项
// ctrlunit(numlist)用于捐助池的Ctrlunit (numlist)控制单元
// preperiod(numlist) 干预发生前的预处理阶段
// postperiod(numlist) 干预发生时及之后的治疗后时期
// Xperiod (numlist) indepvar中指定的预测器的平均周期
// mspeperiod(numlist)均方预测误差(MSPE)应最小化的周期
// customV(numlist)提供自定义V-Weights,确定变量在预处理期间对结果的预测能力
// nested 在所有(对角)正半定v矩阵和w权集之间进行搜索的嵌套全嵌套优化过程
// allopt 如果指定了嵌套,将获得完全健壮的结果
// placebo([{unit|unit(numlist)} period(numlist) cutoff(#_c)]) 使用假治疗单位的空间安慰剂试验和/或使用假治疗时间的时间安慰剂试验
*-案例介绍(California smoking)
global path = ""
cd $path
use "california", clear
xtset state year
**生成加州在政策实施后的变量
gen treat=0
replace treat=1 if year > 1989 & state==3 // 加州编号为3,在1989实施控烟法案
**可视化样本的分布
panelview cigsale treat, i(state) t(year) type(treat)
panelview cigsale treat, i(state) t(year) type(outcome) prepost
**合成控制法实现
// 4个预测变量:lnincome age15to24 retprice beer
// 3个预测香烟销售时间点:cigsale(1988) cigsale(1980) cigsale(1975),
*分别表示人均香烟消费在1975、1980与1988年的取值
// trunit(3): 指定处理地区加州(编号为3)
// trperiod(1989): 指定政策干预开始的时期,为1989
// xperiod(1980(1)1988): 预测政策处理前的周期
// placebo:使用假处理单位的空间安慰剂试验,删除该样本后对模型进行拟合,然后检验该时段内的 ATT 是否显著不为零,原假设是为0。
synth2 cigsale lnincome age15to24 retprice beer ///
cigsale(1988) cigsale(1980) cigsale(1975), ///
trunit(3) trperiod(1989) xperiod(1980(1)1988) placebo(unit cut(2))
graph display eff_pboUnit // 展示图像
倾向得分匹配法
介绍
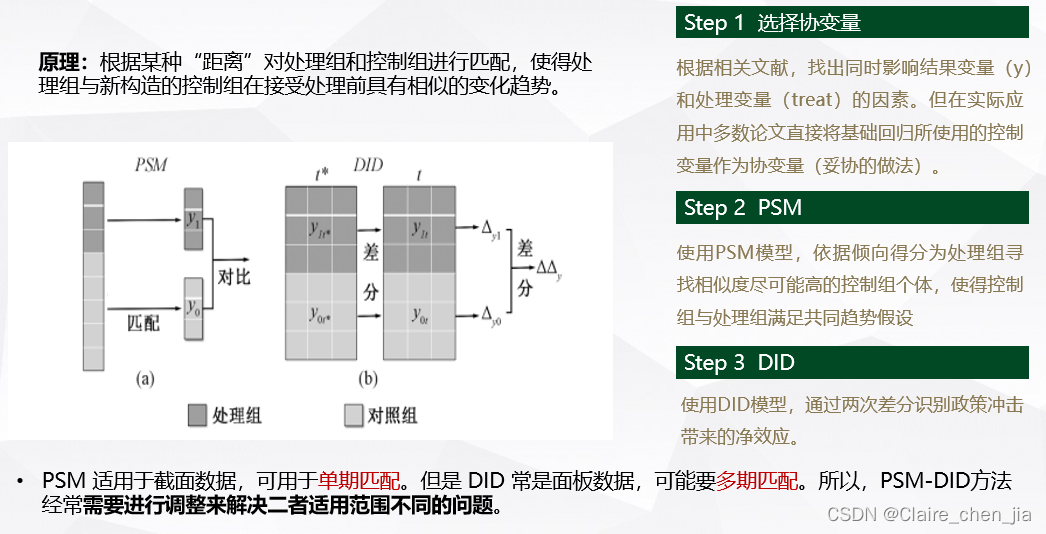
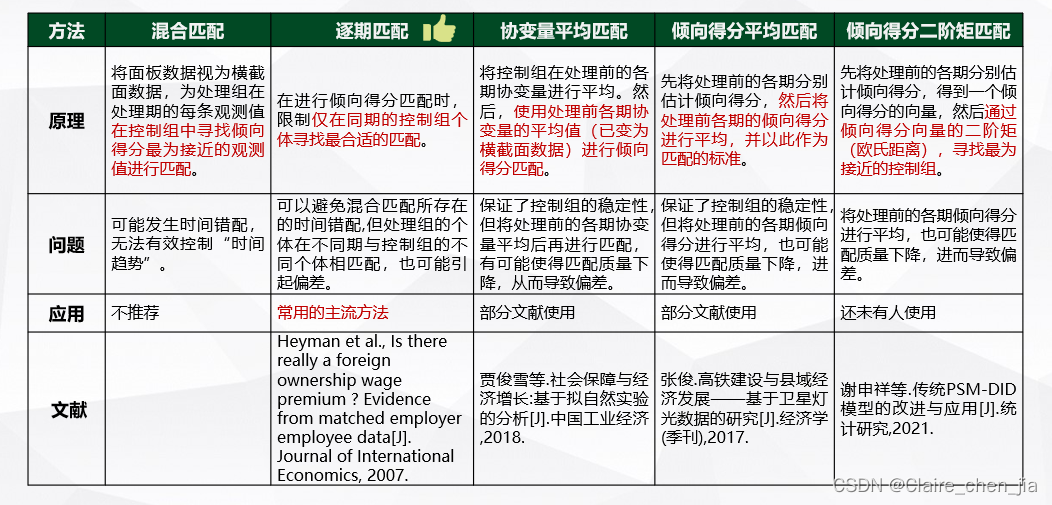
倾向得分匹配法最近几年一直在跟DID一起联用,也是解决平行趋势假设违背的一个方法。但在使用上也存在一些注意的地方

实现
以余明桂老师发表在中国工业经济的论文为例
余明桂等.中国产业政策与企业技术创新[J].中国工业经济,2016(12).
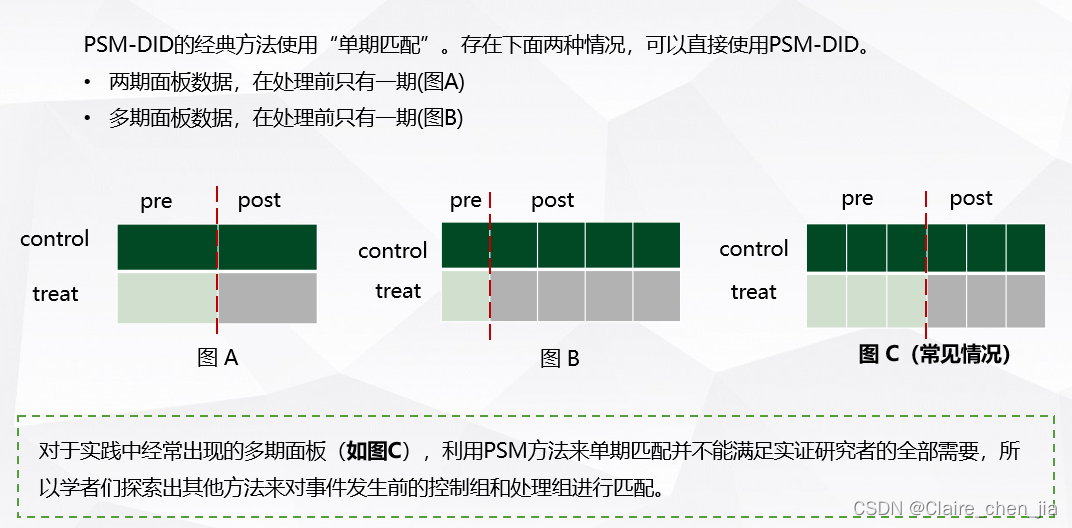
## 单期匹配
*-数据处理
use 余明桂-2018,replace
**变量定义
keep if ingroup !=.
rename flnpat110 lnPatent
keep lnPatent ingroup inyear Size Lev Roa PPE Capital Cash Age Gdpr year indc
***协变量
global xlist Size Lev Roa PPE Capital Cash Age Gdpr // 定义协变量
label var Size "企业规模"
label var Lev "资产负债率"
label var Roa "资产收益率"
label var Capital "企业资本性支出"
label var PPE "企业固定资产规模"
label var Age "企业年龄"
label var Cash "企业现金量"
label var Gdpr "所在地区GDP增长率"
***主要变量
label var lnPatent "专利产出" //结果变量
label var ingroup "被十五和十一五鼓励的产业" // 处理变量
label var inyear "十一五政策实施" // 时间变量
save psmdata,replace
*回归检验
use psmdata,replace
**ps-score计算-采用卡尺最近邻匹配(1:2)
psmatch2 ingroup $xlist, outcome(lnPatent) logit ///
neighbor(1) ties common ate caliper(0.05)
**有效性检验
***平衡性检验
pstest, both graph saving(balancing_assumption, replace)
graph export "balancing_assumption.emf", replace
***共同支撑假设
psgraph, saving(common_support, replace)
graph export "common_support.emf", replace
**倾向得分值的核密度图
sum _pscore if ingroup == 1, detail
***匹配前
sum _pscore if ingroup == 0, detail
twoway(kdensity _pscore if ingroup == 1, lpattern(solid) ///
lcolor(black) lwidth(thin) scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配前的倾向得分值}", ///
size(medlarge)) ///
xline(0.6777 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_cs_before, replace)) ///
(kdensity _pscore if ingroup == 0, lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)4, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_cs_before.emf", replace
discard
***匹配后
sum _pscore if ingroup == 0 & _weight != ., detail
twoway(kdensity _pscore if ingroup == 1, lpattern(solid) ///
lcolor(black) lwidth(thin) scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配后的倾向得分值}", ///
size(medlarge)) ///
xline(0.6777, lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_cs_after, replace)) ///
(kdensity _pscore if ingroup == 0 & _weight !=., lpattern(dash)), ///
xlabel(, labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)4, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_cs_after.emf", replace
**回归结果对比
***DID
reghdfe lnPatent c.ingroup##c.inyear $var, absorb(year indc) vce(robust)
est store m1
***PSM-DID
reghdfe lnPatent c.ingroup##c.inyear $var if _weight!=., absorb(year indc) vce(robust)
est store m2
***结果输出
local mlist_1 "m1 m2"
reg2docx `mlist_1' using 回归结果对比1.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_a(%6.4f)) noconstant replace ///
mtitles("DID" "PSM-DID") title("DID及截面PSM-DID结果")
# 多期匹配
*-逐年psm-did
**事前描述性统计和ps-score计算
***采用卡尺最近邻匹配(1:2)
use psmdata,replace
forvalue i = 2001/2010{
preserve
capture {
keep if year == `i'
set seed 0000
gen norvar_2 = rnormal()
sort norvar_2
psmatch2 ingroup $xlist, outcome(lnPatent) logit neighbor(2) ///
ties common ate caliper(0.05)
save `i'.dta, replace
}
restore
}
clear all
use 2001.dta, clear
forvalue k =2002/2009 {
capture {
append using `k'.dta
}
}
save yby_psmdata.dta, replace
**回归结果对比
use yby_psmdata,replace
***DID
reghdfe lnPatent c.ingroup##c.inyear $var, absorb(year indc) vce(robust)
est store m1
***逐年PSM-DID
reghdfe lnPatent c.ingroup##c.inyear $var if _weight!=., absorb(year indc) vce(robust)
est store m2
***结果输出
local mlist_1 "m1 m2"
reg2docx `mlist_1' using 回归结果对比2.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_a(%6.4f)) noconstant replace ///
mtitles("DID" "PSM-DID") title("DID及逐年PSM-DID结果")
总结
一个非常简陋的总结。这篇论文只讲了经典DID的处理,但是现在论文更多的是使用stagger DID,而在用双重固定效应方法在估计stagger DID时,其实是会因为处理效应异质性问题,导致估计系数有偏,所以近年来学者们也提供了一些方法去克服它。在这篇博客没有多加介绍,希望以后有空可以聊一聊(太懒了,现在不想写)~
最后,立一个最近不能出去的小flag,希望年底可以出去旅游放松(回家也算。。。),看看祖国的大好河山~ 因为见过光和彩虹,所以才要更加努力保持拨云见日的信心,哈哈~

![C语言程序设计 复习总结[持续更新ing]](https://img-blog.csdnimg.cn/76f61baaf082431a9afff75a3faa3e81.png)