基于K-最近邻算法构建红酒分类模型
描述
Wine红酒数据集是机器学习中一个经典的分类数据集,它是意大利同一地区种植的葡萄酒化学分析的结果,这些葡萄酒来自三个不同的品种。数据集中含有178个样本,分别属于三个已知品种,每个样本含有13个特征(即13个化学成分值)。任务是根据已知的数据集建立分类模型,预测新的葡萄酒数据的类别。
任务内容包括:
1、 加载红酒数据并使用Matplotlib将数据可视化
2、 将数据集随机拆分为训练集和测试集
3、 构建K-最近邻算法分类模型并评估其准确性
源码下载链接
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
matplotlib 3.3.4 numpy 1.19.5 pandas 1.1.5 scikit-learn 0.24.2 mglearn 0.1.9
任务分析
红酒数据集包括178条红酒样本数据,每个样本有13个特征值(13个化学成分测量值),同时还给出了这178条红酒样本对应的品种(共三个种类——class0、class1、class2)。我们需要根据这些数据建立红酒分类模型,并能够预测新的样本数据的品种。因为样本数据中已经包含了对应的红酒品种(即数据的标签),所以这是一个监督学习中的分类(Classification)问题。
本任务涉及以下几个环节:
a)加载、查看红酒数据集
b)数据可视化
c)将数据拆分为训练集与测试集
d)构建模型并评估、预测
任务实施
1、 加载、查看红酒数据集
红酒数据集是Scikit-learn自带的数据集,我们通过load_wine ()函数来加载。
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 加载wine数据集
wine = load_wine()
print(wine.keys()) # 查看数据集构成
print('shape of data:', wine.data.shape) # 查看样本数据的形状
print('shape of target:', wine.target.shape) # 查看标签数据的形状
print('target_names:', wine.target_names) # 查看红酒类别名称
print('feature_names:', wine.feature_names) # 样本的十三个特征名称
输出结果:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
shape of data: (178, 13)
shape of target: (178,)
target_names: ['class_0' 'class_1' 'class_2']
feature_names: ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
通过keys()函数可以查看数据集中有哪些Keys(即数据项),依次查看其数据项。
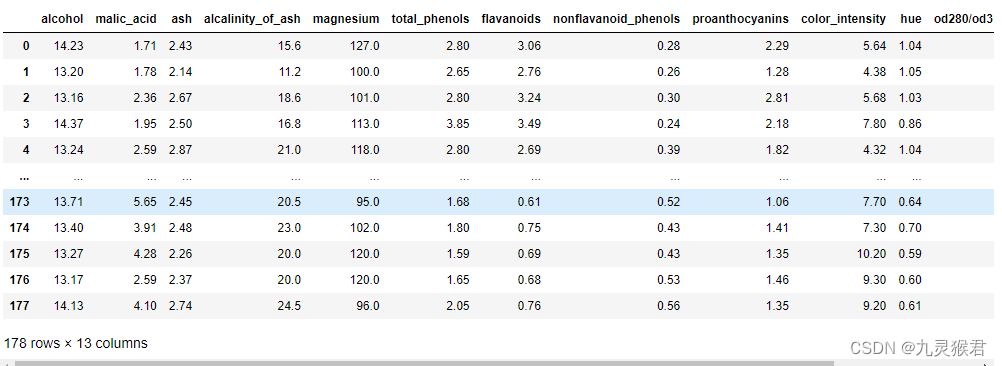
使用pandas查看数据:
# 使用pandas查看样本数据
df = pd.DataFrame(wine.data, columns=wine.feature_names)
df
输出结果:
2、 数据集可视化
红酒数据样本有13个特征,任意2个都可以形成1幅散点图,这里我们随机选2个特征,生成10幅散点图,查看数据分布情况。
import random
# wine数据集可视化
fig = plt.figure(figsize=(16,25)) # 定义画板尺寸
data = wine.data # 样本数据
target = wine.target # 数据标签
target_names = wine.target_names # 标签名称
feature_names = wine.feature_names # 特征名称
# 任选2个特征生成散点图,共生成10个子图
for i in range(10):
random_feature = random.sample(range(13), 2) # 任选2个特征
ax = fig.add_subplot(5, 2, i+1) # 添加子图(5行2列,第i+1个子图)
for j in range(3): # 依次显示每个种类(共3类)的数据
ax.scatter(data[:,random_feature[0]][target==j], data[:,random_feature[1]][target==j], label=target_names[0])
ax.set_xlabel(feature_names[random_feature[0]], fontsize=15)
ax.set_ylabel(feature_names[random_feature[1]], fontsize=15)
ax.legend()
plt.show()
显示结果:
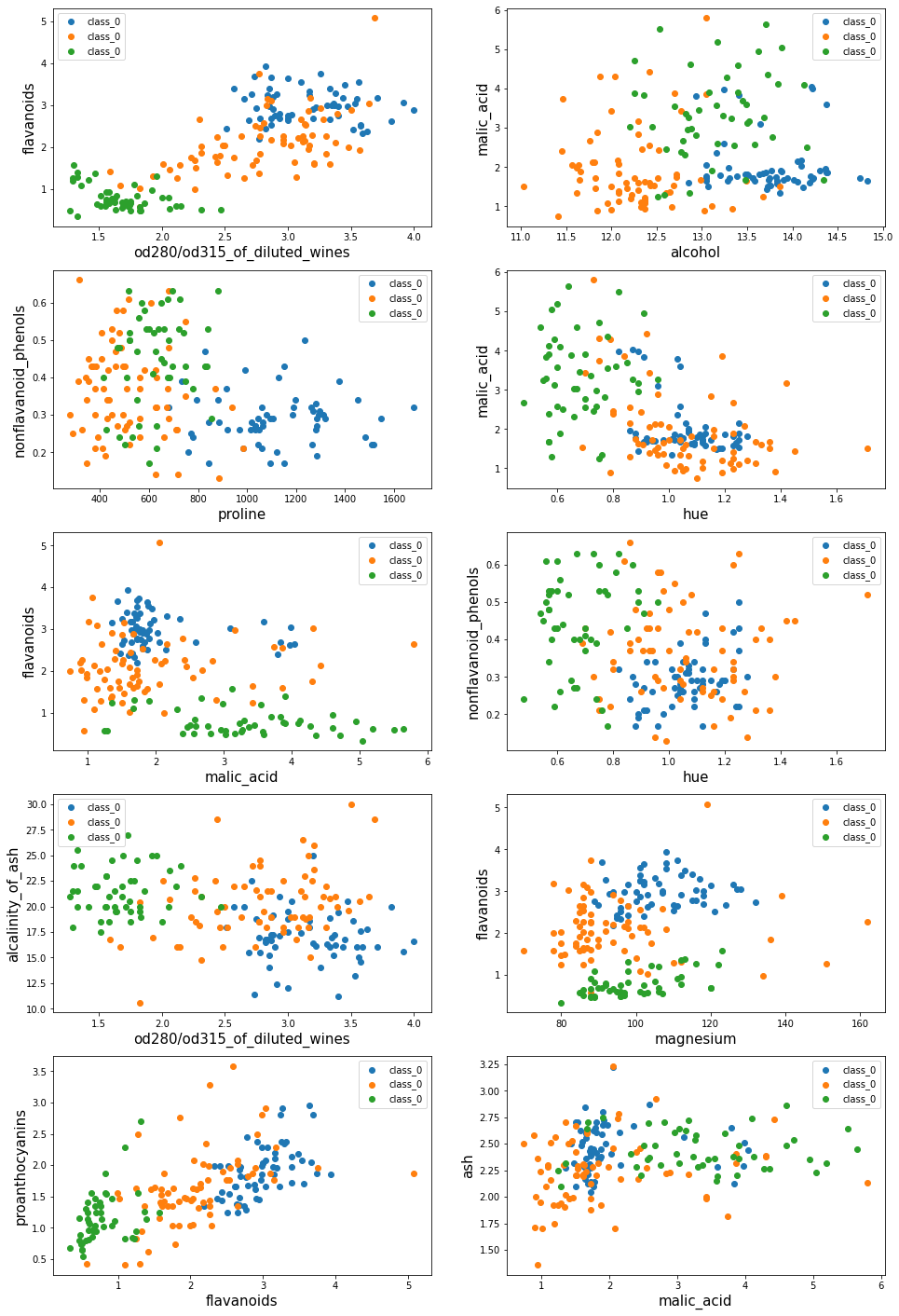
红酒数据集有13个特征,可以形成一个13维的空间,为了方便显示,我们只是在2维空间里(每次随机选2个特征作为X轴和y轴)对数据进行简单可视化。
可视化的目的是更好地了解数据。从随机生成的散点图中可以发现,有些特征组合在2维空间上就已经比较容易分类(如图2和图4),有些特征组合在二维空间上的重叠度较高,不容易分类,需要考虑更多维度。
3、 将数据集拆分为训练集和测试集
Scikit-learn提供了train_test_split函数将红酒数据集(形状为(178, 13))随机拆分为训练集和测试集,参数除了样本数据和数据标签外,还包括:
- test_size参数:测试集比例(默认为0.25)。
- random_state参数:随机数种子(为了固定随机结果,便于数据重现。如果不指定,每次拆分结果都不同)。
# 拆分数据集
# test_size=0.25(25%作为测试集,75%作为训练集)
# random_state=0(随机数种子,固定随机结果,便于数据重现)
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.25, random_state=0)
print(X_train.shape, X_test.shape)
输出结果:
(133, 13) (45, 13)
4、 构建K-NN模型,评估并预测
# 构建模型
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train) # 拟合训练数据
# 评估模型
score = model.score(X_test, y_test)
print('Score:{:.2f}'.format(score))
# 预测红酒种类
y_pred = model.predict(X_test[:5]) # 预测测试集前五个样本的品种
print(y_pred) # 打印预测结果
print(y_test[:5]) # 打印实际品种
输出结果:
Score:0.73
[0 1 1 0 1]
[0 2 1 0 1]